#!/usr/bin/env python
# coding: utf-8
#  # # Optimization
#
#
#
# $$
# \newcommand{\eg}{{\it e.g.}}
# \newcommand{\ie}{{\it i.e.}}
# \newcommand{\argmin}{\operatornamewithlimits{argmin}}
# \newcommand{\mc}{\mathcal}
# \newcommand{\mb}{\mathbb}
# \newcommand{\mf}{\mathbf}
# \newcommand{\minimize}{{\text{minimize}}}
# \newcommand{\diag}{{\text{diag}}}
# \newcommand{\cond}{{\text{cond}}}
# \newcommand{\rank}{{\text{rank }}}
# \newcommand{\range}{{\mathcal{R}}}
# \newcommand{\null}{{\mathcal{N}}}
# \newcommand{\tr}{{\text{trace}}}
# \newcommand{\dom}{{\text{dom}}}
# \newcommand{\dist}{{\text{dist}}}
# \newcommand{\R}{\mathbf{R}}
# \newcommand{\SM}{\mathbf{S}}
# \newcommand{\ball}{\mathcal{B}}
# \newcommand{\bmat}[1]{\begin{bmatrix}#1\end{bmatrix}}
# \newcommand{\loss}{\ell}
# \newcommand{\eloss}{\mc{L}}
# \newcommand{\abs}[1]{| #1 |}
# \newcommand{\norm}[1]{\| #1 \|}
# \newcommand{\tp}{T}
# $$
# __
# # Optimization
#
#
#
# $$
# \newcommand{\eg}{{\it e.g.}}
# \newcommand{\ie}{{\it i.e.}}
# \newcommand{\argmin}{\operatornamewithlimits{argmin}}
# \newcommand{\mc}{\mathcal}
# \newcommand{\mb}{\mathbb}
# \newcommand{\mf}{\mathbf}
# \newcommand{\minimize}{{\text{minimize}}}
# \newcommand{\diag}{{\text{diag}}}
# \newcommand{\cond}{{\text{cond}}}
# \newcommand{\rank}{{\text{rank }}}
# \newcommand{\range}{{\mathcal{R}}}
# \newcommand{\null}{{\mathcal{N}}}
# \newcommand{\tr}{{\text{trace}}}
# \newcommand{\dom}{{\text{dom}}}
# \newcommand{\dist}{{\text{dist}}}
# \newcommand{\R}{\mathbf{R}}
# \newcommand{\SM}{\mathbf{S}}
# \newcommand{\ball}{\mathcal{B}}
# \newcommand{\bmat}[1]{\begin{bmatrix}#1\end{bmatrix}}
# \newcommand{\loss}{\ell}
# \newcommand{\eloss}{\mc{L}}
# \newcommand{\abs}[1]{| #1 |}
# \newcommand{\norm}[1]{\| #1 \|}
# \newcommand{\tp}{T}
# $$
# __ ASE3001: Computational Experiments for Aerospace Engineering, Inha University.
__
# _ Jong-Han Kim (jonghank@inha.ac.kr)
_
# _ Jiwoo Choi (jiwoochoi@inha.edu)
_
#
#
#
# ___
#
#
#
# Mathematical optimization, also known simply as optimization or mathematical programming, is the process of selecting the best element, with regard to some criteria, from a set of available alternatives. Optimization problems arise in all quantitative disciplines, from computer science and engineering to operations research and economics, and the development of solution methods has been of interest to mathematicians for centuries.
#
# Recently, due to advancements in artificial intelligence technology, optimization techniques have been receiving increased attention from a wider audience, because the learning processes of AI models are formulated and solved as optimization problems.
#
#
# ## Standard form optimization problem
#
# In general, optimization problems are expressed in the following form.
#
# $$
# \begin{aligned}
# \underset{x}{\minimize} \quad & f_0(x) \\
# \text{subject to} \quad & f_i(x) \le 0, &i=1,\dots,m \\
# & h_i(x) = 0, &
# i=1,\dots,p
# \end{aligned}
# $$
#
# - $x\in\R^n$: _optimization variable_, _decision variable_, or simply the _variable_
# - $f_0(x): \R^n \rightarrow \R$: _objective function_, or _cost function_
# - $f_i(x): \R^n \rightarrow \R, \quad i=1,\dots,m$: _inequality constraint functions_
# - $h_i(x): \R^n \rightarrow \R, \quad i=1,\dots,p$: _equality constraint functions_
# - The problem is _feasible_ if there exists $x$ that satisfies the constraint functions
#
#
#
# ### Examples
#
# _Data fitting_
# - variables: model parameters
# - constraints: prior information, parameter limits
# - objective: measure of misfit or prediction error, plus regularization terms
#
# _Missile guidance_
# - variables: future control inputs
# - constraints: actuator limits, stealthiness, target acquisition, and so on
# - objective: miss distance
#
# _Target tracking_
# - variables: target position, velocity
# - constraints: target dynamics, radar performance
# - objective: likelihood of probabilistic model
#
# _Portfolio optimization_
# - variables: amounts invested in different assets
# - constraints: budget, per-asset investment, minimum return
# - objective: overall risk or return variance
#
# _In-painting_
# - variables: pixel values on corrupted pixels
# - constraints: pixel values on uncorrupted pixels
# - objective: overall naturalness of the image
#
#
#
#
# ___
#
#
#
# ## Least squares problem
#
#
# Today we focus on one of the simplest optimization problems, the **least squares problem**. The problem itself is not just the simplest but also the most important and most widely used in a wide variety of engineering disciplines.
#
# For example, given a set of $N$ data points $ (a_i, b_i)$, where $ i \in \{0, 1, \dots, N-1\} $ and $ a_i \in \R^k, b_i \in\R $, the variable $ x\in\R^{k+1} $ that best approximates the relations between $a_i$ and $b_i$ as a linear function of $x$, $ b_i \approx x_1 + a_i^Tx_{2:k+1}$, in terms of minimizing the residual is defined as,
#
# $$
# x^* = \arg \min \left( \|Ax - b\|^2 \right)
# $$
#
# where
#
# $$
# A =
# \begin{bmatrix}
# 1 & {a}_0^T \\
# 1 & {a}_1^T \\
# \vdots \\
# 1 & {a}_{N-1}^T
# \end{bmatrix},
# \quad
# b =
# \begin{bmatrix}
# b_0 \\
# b_1 \\
# \vdots \\
# b_{N-1}
# \end{bmatrix}.
# $$
#
# The problem of finding the best variable $x$ is known as the least squares problem.
#
# In this case, the optimal solution $x^* $ is obtained by finding the point where the gradient of the sum squares of the residual is zero:
#
# $$\nabla_x \|Ax - b\|^2 = 2A^T(Ax - b) = 0 $$
#
# yielding the closed-form solution:
#
# $$
# x^* = \left( A^T A \right)^{-1} A^T b
# $$
#
# More theoretical details and a comprehensive understanding of the applications of least squares problems can be found on the webpage of [ASE2010: Applied linear algebra](https://jonghank.github.io/ase2010.html).
#
#
# ___
#
#
#
# ## Gradient descent method
#
# On the other hand, iterative methods such as the gradient descent method can also be used to minimize the sum of the squares of the residuals.
#
# Gradient descent is an algorithm that iteratively moves the estimate in the direction of the negative gradient to progressively approach the optimal value, thus finding the point where the loss function is minimized.
#
# The pseudo code of the gradient descent algorithm for finding a (locally) optimal solution minimizing $f(x)$ is as follows,
# $$
# \begin{array}{l}
# \textbf{initialize } x, \textbf{and set } \eta>0, \epsilon>0.\\
# \textbf{for } i \leftarrow 1 \textbf{ to } N \textbf{ do} \\
# \quad x \leftarrow x - \eta \nabla f(x); \\
# \quad \textbf{if } \left\|f(x) \right\|^2 < \epsilon\ \textbf{then} \\
# \quad \quad \text{break}\\
# \textbf{end}
# \end{array}
# $$
# where, $\eta$ is a learning rate, or step size, that determines how much the variables are updated at each iteration.
#
# Note that this can be used for solving a general unconstrained optimization problems, not just the least squares problem, at least locally as long as the gradient information is available.
# In[1]:
import numpy as np
import numpy.linalg as lg
import matplotlib.pyplot as plt
import matplotlib.colors as colors
from matplotlib.lines import Line2D
#
#
# Consider a simple one-dimensional example where $a\in \R$, which tries to find a straight line that best approximates the data.
#
# In[2]:
np.random.seed(1)
A = np.random.randn(20,2)
A[:,0] = 1
sort = np.argsort(A[:,1])
b = A[:,1] * 10 + 3
b += np.random.randn(*b.shape)* 3
plt.figure(figsize=(8,6), dpi=100)
plt.plot( A[:,1],b, '*', label='Data Points')
plt.grid()
plt.xlabel(r'$a$')
plt.ylabel(r'$b$')
plt.legend()
plt.show()
#
#
# Implementing the gradient descent method on the above problem, we obtain the following.
# In[3]:
x_init = np.random.randn(2)
lr = 1e-3
eps_crt = 1e-5
# In[4]:
def func_grad(x, A, b):
grad = 2 * A.T @ (A@x - b)
return grad
epochs = 3000
x = x_init
grads = []
x_hist = []
for i in range(epochs):
grad = func_grad(x, A, b)
grads.append(grad)
x_hist.append(x)
if lg.norm(grad) <= eps_crt:
break
x_new = x - lr * grad
x = x_new
x_gd = x
print(f"Optimal x via gradient descent method: {x_gd}")
#
#
# Note that the obtained solution is identical up to the numerical precision to the closed-form solution obtained from the `numpy.linalg.lstsq` function.
# In[5]:
x_opt = lg.lstsq(A, b, rcond=-1)[0]
diff = x_gd - x_opt
print(f"Optimal x via numpy.linalg.lstsq: {x_opt}")
print(f"Optimal x via gradient descent method: {x_gd}")
print(f"Norm of the difference: {lg.norm(diff)}")
#
#
# Using the least squares method, we get a pretty good approximation of the data lines.
# In[6]:
plt.figure(figsize=(8,6), dpi=100)
plt.plot( A[:,1],b, '*', label='Data Points')
_in = np.linspace(-3,3)
line = _in * x_opt[1] + x_opt[0]
plt.plot(_in,line, label='Linear approximation')
plt.grid()
plt.xlabel(r'$a$')
plt.ylabel(r'$b$')
plt.legend()
plt.show()
#
#
# ___
#
#
#
#
# ## Automatic differentiation via JAX
#
# [JAX](https://jax.readthedocs.io/en/latest/index.html) is an open source library developed by Google that enables high-performance numerical computing and machine learning. Specifically, JAX provides automatic differentiation, which computes gradients by applying a chain rule to break down complex functions into simpler parts. For your information, the code and diagram is presented below for you to grab the simple idea of automatic differentiation.
#
#
#
# 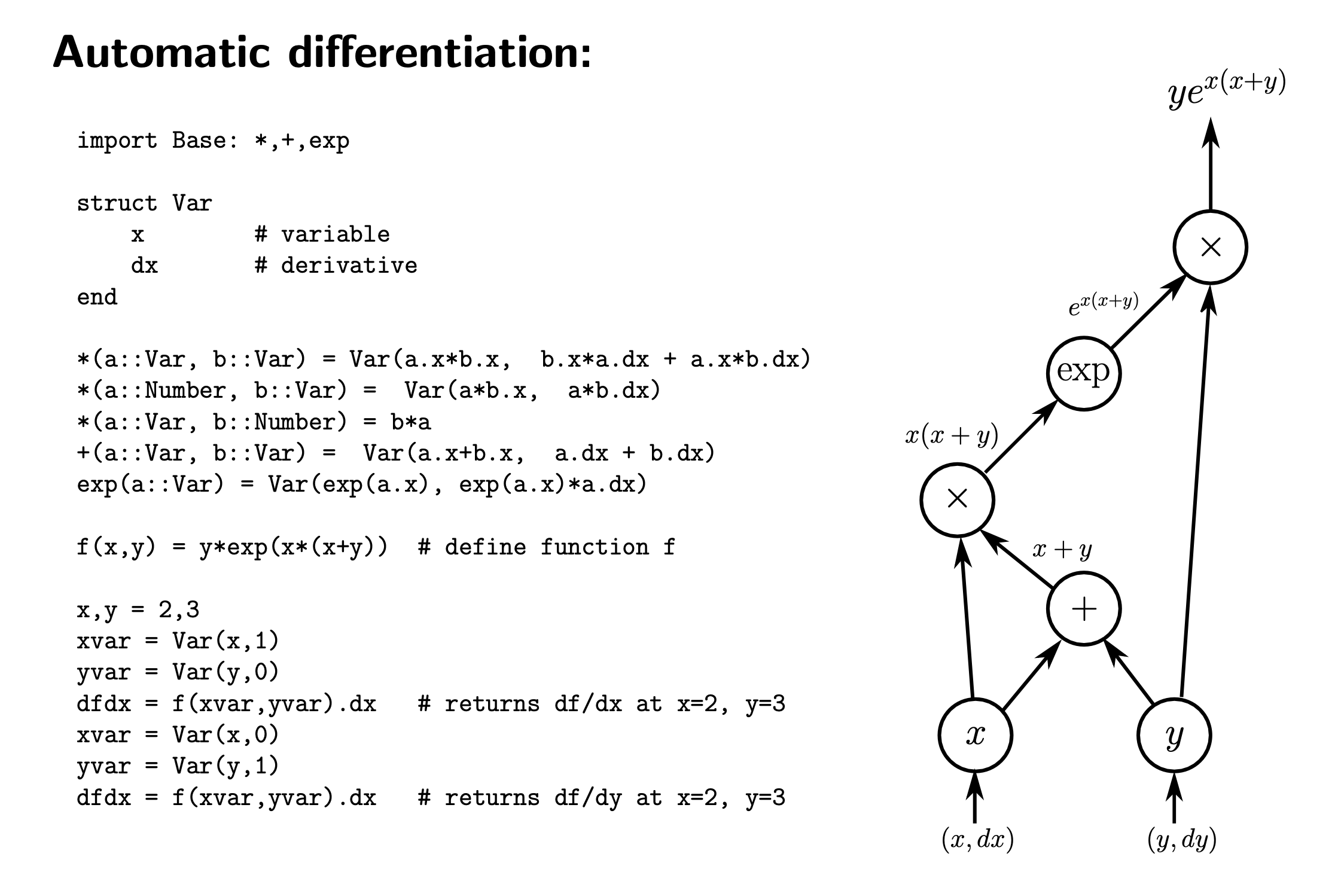 #
#
#
#
#
#
#
# The implementation of the gradient descent algorithm with `jax` is as follows.
# In[7]:
import os
os.environ["JAX_PLATFORM_NAME"] = "cpu"
import jax
import jax.numpy as jnp
jax.config.update("jax_enable_x64", True)
# In[8]:
def loss_func(x, A, b):
res = A @ x - b
loss = np.sum(res**2)
return loss
grad_jax = jax.grad(loss_func)
x = x_init
grads = []
x_hist = []
for i in range(1000):
grad = grad_jax(x, A, b)
grads.append(grad)
x_hist.append(x)
if lg.norm(grad) <= eps_crt:
break
x_new = x - lr * grad
x = x_new
x_jax = x
diff = x_gd - x_opt
print(f"Optimal x via numpy.linalg.lstsq: {x_opt}")
print(f"Optimal x via gradient descent: {x_gd}")
print(f"Optimal x via automatic differentiation and JAX: {x_jax}")
print(f"Norm of the difference: {lg.norm(diff)}")
#
#
# The process of finding the solution via gradient descent is displayed in a contour plot as follows.
#
# As you can see in the figure below, the gradient is perpendicular to the contour, which is the direction that reduces the loss function the fastest.
# In[9]:
n_grid = 200
import matplotlib.colors as mcolors
tmp_x0 = np.linspace(-6,12, num=n_grid)
tmp_x1 = np.linspace(0,15, num=n_grid)
x0, x1 = np.meshgrid(tmp_x0, tmp_x1)
_in = np.vstack([x0.reshape(-1), x1.reshape(-1)])
res = A@_in - b[:,None]
res = np.sum(res**2, axis=0)
res = res.reshape(n_grid,n_grid)
Z = res**2
plt.figure(figsize=(9,6), dpi=100)
plt.contourf(x0, x1, Z, levels=100, cmap='viridis', alpha=0.8)
sol_opt, = plt.plot(*x_opt,'*', color='red', markersize=10)
line_opt, = plt.plot(*x_jax,'*', color='blue', markersize=8)
for idx, (_x, g) in enumerate(zip(x_hist[::2], grads[::2])):
line_p, = plt.plot(*_x, 'o', color='aqua', markersize=0.4 - 5e-3*idx)
line_v = plt.arrow(*_x, *g*1.3e-3*(-1), head_width=2e-2, head_length=0.1, color='black')
line_p = Line2D([0], [0], marker='o', color='aqua', markersize=8, linewidth=0)
plt.legend([sol_opt, line_opt, line_v], ['Optimal solution', 'Converged solution', 'Gradient direction'])
plt.colorbar(label='Loss Function')
plt.title('Contour Plot')
plt.xlabel(r'$x_0$')
plt.ylabel(r'$x_1$')
plt.axis('equal')
plt.show()
#
#
# ___
#
#
#
# ## More complicated function
#
# We present below a test function widely used for evaluating the performance of optimization algorithms.
#
# $$
# {\displaystyle f({\boldsymbol {x}})=\sum _{i=1}^{n-1}\left[20\left(x_{i+1}-x_{i}^{2}\right)^{2}+\left(1-x_{i}\right)^{2}\right]}
# $$
#
# The global minimum for this function is inside a long, narrow, parabolic-shaped flat valley. To find the valley is trivial and the global minimum can be easily identified as $x^*_i=1$ for all $i$'s. However to converge to the global minimum via iterative algorithm is difficult.
#
# We examine the case with $n=2$ below.
# In[24]:
def test_function(x):
x0, x1 = x
a0, a1 = 1, 20
loss = (a0-x0)**2 + a1*(x1-x0**2)**2
return loss
n_grid = 200
tmp_x0 = np.linspace(-2,2, num=n_grid)
tmp_x1 = np.linspace(-1,3, num=n_grid)
x0, x1 = np.meshgrid(tmp_x0, tmp_x1)
_in = np.vstack([x0.reshape(-1), x1.reshape(-1)])
res = test_function(_in)
res = res.reshape(n_grid,n_grid)
Z = res**2
plt.figure(dpi=100, figsize=(8,6))
plt.contourf(x0, x1, Z, levels=np.logspace(-7,7,10), alpha=0.8, \
norm=colors.LogNorm(vmin=Z.min(), vmax=Z.max()))
plt.title('Contour Plot')
plt.xlabel(r'$x_0$')
plt.ylabel(r'$x_1$')
plt.axis('square')
plt.grid()
plt.show()
# Applying the naive gradient descent algorithm on this function gives the following.
# In[25]:
grad_test_function = jax.grad(test_function)
x_opt_tf = np.array([1, 1])
x = np.array([-0.5,2.5])
grads = []
x_hist = []
for i in range(epochs):
grad = grad_test_function(x)
grads.append(grad)
x_hist.append(x)
if lg.norm(grad) <= eps_crt:
break
x_new = x - lr * grad
x = x_new
x_sol_tf = x
diff = x_sol_tf - x_opt_tf
print(f"Optimal solution: {x_opt_tf}")
print(f"Optimal x via automatic differentiation and JAX: {x_sol_tf}")
print(f"Norm of the difference: {lg.norm(diff)}")
# In[26]:
n_grid = 200
tmp_x0 = np.linspace(-2,2, num=n_grid)
tmp_x1 = np.linspace(-1,3, num=n_grid)
x0, x1 = np.meshgrid(tmp_x0, tmp_x1)
_in = np.vstack([x0.reshape(-1), x1.reshape(-1)])
res = test_function(_in)
res = res.reshape(n_grid,n_grid)
Z = res**2
plt.figure(dpi=100, figsize=(8,6))
plt.contourf(x0, x1, Z, levels=np.logspace(-7,7,10), alpha=0.8, \
norm=colors.LogNorm(vmin=Z.min(), vmax=Z.max()))
plt.plot(*x_opt_tf,'*', color='red', markersize=10)
plt.plot(*x_sol_tf,'*', color='blue', markersize=8)
for _x, g in zip(x_hist[::2], grads[::2]):
plt.arrow(*_x, *g*1e-4*(-1), head_width=2e-2, head_length=0.05, fc='blue')
plt.title('Contour Plot')
plt.xlabel(r'$x_0$')
plt.ylabel(r'$x_1$')
plt.axis('square')
plt.grid()
plt.show()
# Discuss whether your naive gradient descent algorithm is efficient for this test function.