#!/usr/bin/env python
# coding: utf-8
#  # # Predicting Remaining Life of NASA Turbofan Engines
#
#
#
# $$
# \newcommand{\eg}{{\it e.g.}}
# \newcommand{\ie}{{\it i.e.}}
# \newcommand{\argmin}{\operatornamewithlimits{argmin}}
# \newcommand{\mc}{\mathcal}
# \newcommand{\mb}{\mathbb}
# \newcommand{\mf}{\mathbf}
# \newcommand{\minimize}{{\text{minimize}}}
# \newcommand{\diag}{{\text{diag}}}
# \newcommand{\cond}{{\text{cond}}}
# \newcommand{\rank}{{\text{rank }}}
# \newcommand{\range}{{\mathcal{R}}}
# \newcommand{\null}{{\mathcal{N}}}
# \newcommand{\tr}{{\text{trace}}}
# \newcommand{\dom}{{\text{dom}}}
# \newcommand{\dist}{{\text{dist}}}
# \newcommand{\R}{\mathbf{R}}
# \newcommand{\SM}{\mathbf{S}}
# \newcommand{\ball}{\mathcal{B}}
# \newcommand{\bmat}[1]{\begin{bmatrix}#1\end{bmatrix}}
# \newcommand{\loss}{\ell}
# \newcommand{\eloss}{\mc{L}}
# \newcommand{\abs}[1]{| #1 |}
# \newcommand{\norm}[1]{\| #1 \|}
# \newcommand{\tp}{T}
# $$
#
# __
# # Predicting Remaining Life of NASA Turbofan Engines
#
#
#
# $$
# \newcommand{\eg}{{\it e.g.}}
# \newcommand{\ie}{{\it i.e.}}
# \newcommand{\argmin}{\operatornamewithlimits{argmin}}
# \newcommand{\mc}{\mathcal}
# \newcommand{\mb}{\mathbb}
# \newcommand{\mf}{\mathbf}
# \newcommand{\minimize}{{\text{minimize}}}
# \newcommand{\diag}{{\text{diag}}}
# \newcommand{\cond}{{\text{cond}}}
# \newcommand{\rank}{{\text{rank }}}
# \newcommand{\range}{{\mathcal{R}}}
# \newcommand{\null}{{\mathcal{N}}}
# \newcommand{\tr}{{\text{trace}}}
# \newcommand{\dom}{{\text{dom}}}
# \newcommand{\dist}{{\text{dist}}}
# \newcommand{\R}{\mathbf{R}}
# \newcommand{\SM}{\mathbf{S}}
# \newcommand{\ball}{\mathcal{B}}
# \newcommand{\bmat}[1]{\begin{bmatrix}#1\end{bmatrix}}
# \newcommand{\loss}{\ell}
# \newcommand{\eloss}{\mc{L}}
# \newcommand{\abs}[1]{| #1 |}
# \newcommand{\norm}[1]{\| #1 \|}
# \newcommand{\tp}{T}
# $$
#
# __ LEO6006: Data Science and Machine Learning for Aerospace Systems, Inha University.
__
# _ Jong-Han Kim (jonghank@inha.ac.kr)
_
#
#
#
# ---
#
#
#
# 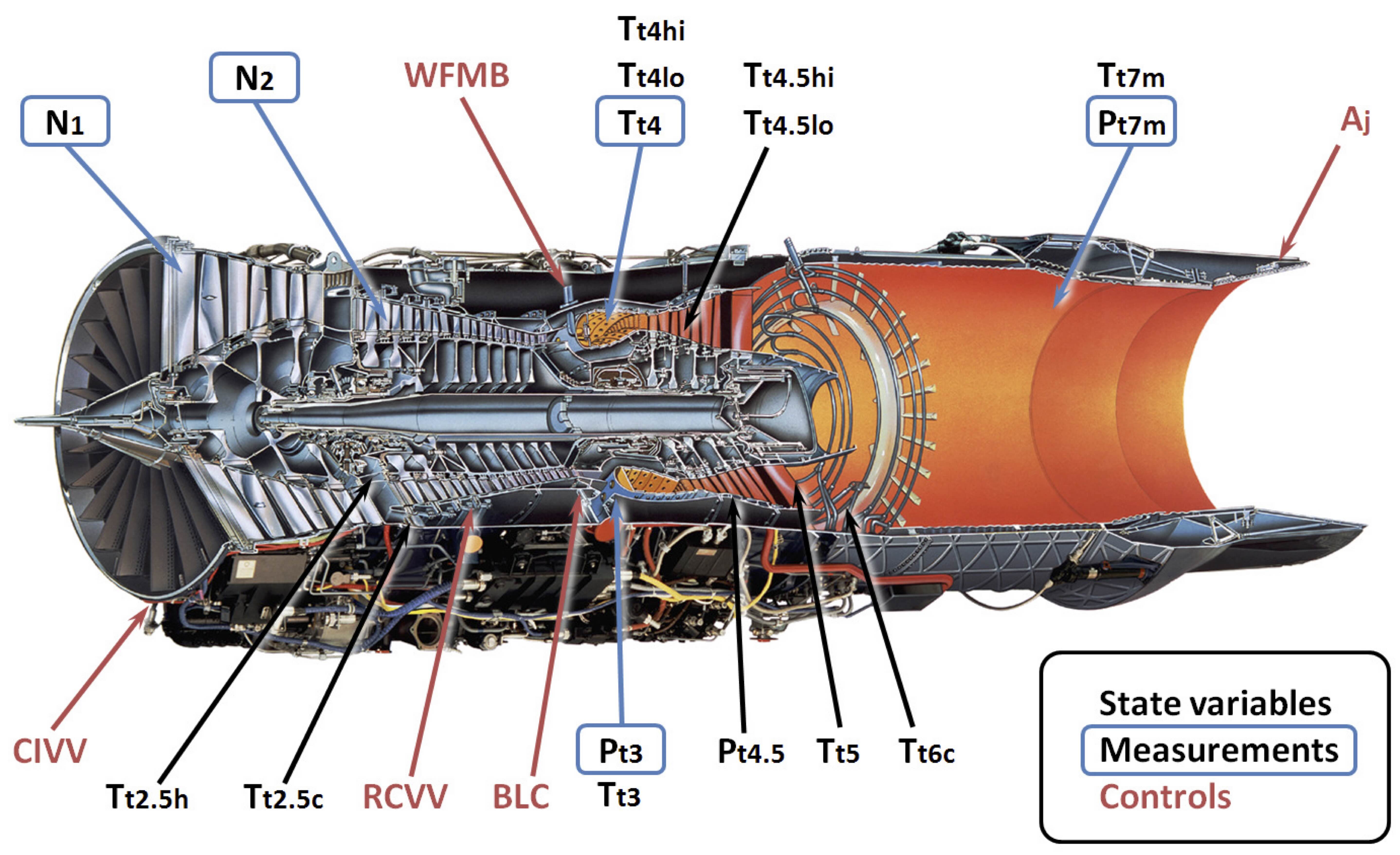 #
#
#
#
#
#
#
# **Description**
#
# Prognostics and health management is an important topic in industry for predicting state of assets to avoid downtime and failures. This data set is the Kaggle version of the very well known public data set for asset degradation modeling from NASA. It includes Run-to-Failure simulated data from turbo fan jet engines.
#
# Engine degradation simulation was carried out using C-MAPSS. Four different were sets simulated under different combinations of operational conditions and fault modes. Records several sensor channels to characterize fault evolution. The data set was provided by the Prognostics CoE at NASA Ames.
#
#
#
# **Prediction Goal**
#
# In this dataset the goal is to predict the remaining useful life (RUL) of each engine in the test dataset. RUL is equivalent of number of flights remained for the engine after the last datapoint in the test dataset.
#
#
#
# **Experimental Scenario**
#
# Data sets consists of multiple multivariate time series. Each data set is further divided into training and test subsets. Each time series is from a different engine i.e., the data can be considered to be from a fleet of engines of the same type. Each engine starts with different degrees of initial wear and manufacturing variation which is unknown to the user. This wear and variation is considered normal, i.e., it is not considered a fault condition. There are three operational settings that have a substantial effect on engine performance. These settings are also included in the data. The data is contaminated with sensor noise.
#
# The engine is operating normally at the start of each time series, and develops a fault at some point during the series. In the training set, the fault grows in magnitude until system failure. In the test set, the time series ends some time prior to system failure. The objective of the competition is to predict the number of remaining operational cycles before failure in the test set, i.e., the number of operational cycles after the last cycle that the engine will continue to operate. Also provided a vector of true Remaining Useful Life (RUL) values for the test data.
#
# The data are provided as a zip-compressed text file with 26 columns of numbers, separated by spaces. Each row is a snapshot of data taken during a single operational cycle, each column is a different variable. The columns correspond to:
#
#
#
# 1) unit number
#
# 2) time, in cycles
#
# 3) operational setting 1
#
# 4) operational setting 2
#
# 5) operational setting 3
#
# 6) sensor measurement 1
#
# 7) sensor measurement 2
#
# …
#
# 26) sensor measurement 26
#
#
#
# **Data Set Organization**
#
# **Data Set: FD001**
# - Train trjectories: 100
# - Test trajectories: 100
# - Conditions: ONE (Sea Level)
# - Fault Modes: ONE (HPC Degradation)
#
# **Data Set: FD002**
# - Train trjectories: 260
# - Test trajectories: 259
# - Conditions: SIX
# - Fault Modes: ONE (HPC Degradation)
#
# **Data Set: FD003**
# - Train trjectories: 100
# - Test trajectories: 100
# - Conditions: ONE (Sea Level)
# - Fault Modes: TWO (HPC Degradation, Fan Degradation)
#
# **Data Set: FD004**
# - Train trjectories: 248
# - Test trajectories: 249
# - Conditions: SIX
# - Fault Modes: TWO (HPC Degradation, Fan Degradation)
#
#
#
# **Reference**
#
# A. Saxena, K. Goebel, D. Simon, and N. Eklund, Damage Propagation Modeling for Aircraft Engine Run-to-Failure Simulation, in the Proceedings of the 1st International Conference on Prognostics and Health Management (PHM08), Denver CO, Oct 2008.
#
#
# In[ ]:
import kagglehub
behrad3d_nasa_cmaps_path = kagglehub.dataset_download('behrad3d/nasa-cmaps')
print('Data source import complete.')
# In[ ]:
# Import the libraries required for exploration and preproccesing
import numpy as np
import pandas as pd
from IPython.display import display, HTML
import matplotlib.pyplot as plt
import seaborn as sns
# Configure Jupyter Notebook
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', 500)
pd.set_option('display.expand_frame_repr', False)
# pd.set_option('max_colwidth', -1)
display(HTML(""))
# In[ ]:
# Give names to the features
index_names = ['engine', 'cycle']
setting_names = ['setting_1', 'setting_2', 'setting_3']
sensor_names=[ "(Fan inlet temperature) (◦R)",
"(LPC outlet temperature) (◦R)",
"(HPC outlet temperature) (◦R)",
"(LPT outlet temperature) (◦R)",
"(Fan inlet Pressure) (psia)",
"(bypass-duct pressure) (psia)",
"(HPC outlet pressure) (psia)",
"(Physical fan speed) (rpm)",
"(Physical core speed) (rpm)",
"(Engine pressure ratio(P50/P2)",
"(HPC outlet Static pressure) (psia)",
"(Ratio of fuel flow to Ps30) (pps/psia)",
"(Corrected fan speed) (rpm)",
"(Corrected core speed) (rpm)",
"(Bypass Ratio) ",
"(Burner fuel-air ratio)",
"(Bleed Enthalpy)",
"(Required fan speed)",
"(Required fan conversion speed)",
"(High-pressure turbines Cool air flow)",
"(Low-pressure turbines Cool air flow)" ]
col_names = index_names + setting_names + sensor_names
df_train = pd.read_csv(('/kaggle/input/nasa-cmaps/CMaps/train_FD001.txt'), sep='\s+', header=None, names=col_names)
df_test = pd.read_csv(('/kaggle/input/nasa-cmaps/CMaps/test_FD001.txt'), sep='\s+', header=None, names=col_names)
df_test_RUL = pd.read_csv(('/kaggle/input/nasa-cmaps/CMaps/RUL_FD001.txt'), sep='\s+', header=None, names=['RUL'])
#
#
# First up is just to eyeball the data.
#
# The training data set has data up to the point of failure, therefore the maximum cycle for each engine was the life that was achieved by the engine.
#
# In the training set, the data has not yet reached the point of failure, therefore the RUL file will tell us how much time still remained until failure. We'll form our predictions against this value
# In[ ]:
df_train
# In[ ]:
df_test
# In[ ]:
df_train.info()
# In[ ]:
df_train.describe(include='all').T
# In[ ]:
df_test_RUL.T
#
#
# We find the correlations for the features
# In[ ]:
plt.figure(figsize=(10,10))
threshold = 0.8
sns.set_style("whitegrid", {"axes.facecolor": ".0"})
df_cluster2 = df_train.corr()
mask = df_cluster2.where((abs(df_cluster2) >= threshold)).isna()
plot_kws={"s": 1}
sns.heatmap(df_cluster2,
cmap='RdYlBu',
annot=True,
mask=mask,
linewidths=0.2,
linecolor='lightgrey').set_facecolor('white')
# Sensors with constant values can be dropped as they have no predictive power
# In[ ]:
# drop the sensors wiith constant values
sens_const_values = []
for feature in list(setting_names + sensor_names):
try:
if df_train[feature].min()==df_train[feature].max():
sens_const_values.append(feature)
except:
pass
print(sens_const_values)
df_train.drop(sens_const_values,axis=1,inplace=True)
df_test.drop(sens_const_values,axis=1,inplace=True)
# Drop one of the highly correlated features and keep the other. The threshold for correlation is set at 0.95
# In[ ]:
# drop all but one of the highly correlated features
cor_matrix = df_train.corr().abs()
upper_tri = cor_matrix.where(np.triu(np.ones(cor_matrix.shape),k=1).astype(np.bool))
corr_features = [column for column in upper_tri.columns if any(upper_tri[column] > 0.95)]
print(corr_features)
df_train.drop(corr_features,axis=1,inplace=True)
df_test.drop(corr_features,axis=1,inplace=True)
# The remaining features
# In[ ]:
list(df_train)
# In[ ]:
df_train
# In[ ]:
features = list(df_train.columns)
# In[ ]:
# check for missing data
for feature in features:
print(feature + " - " + str(len(df_train[df_train[feature].isna()])))
# Add the RUL as a target feature to the data
# In[ ]:
# define the maximum life of each engine, as this could be used to obtain the RUL at each point in time of the engine's life
df_train_RUL = df_train.groupby(['engine']).agg({'cycle':'max'})
df_train_RUL.rename(columns={'cycle':'life'},inplace=True)
df_train_RUL.T
# In[ ]:
df_test_life = df_test.groupby(['engine']).agg({'cycle':'max'})
df_test_life.rename(columns={'cycle':'life'},inplace=True)
df_test_life['life'] = df_test_life['life'].values + df_test_RUL.values.flatten()
df_test_RUL = df_test_life.copy()
df_test_RUL.T
# In[ ]:
df_train=df_train.merge(df_train_RUL,how='left',on=['engine'])
df_train
# In[ ]:
df_test=df_test.merge(df_test_RUL,how='left',on=['engine'])
df_test
# In[ ]:
df_train['RUL']=df_train['life']-df_train['cycle']
df_train.drop(['life'],axis=1,inplace=True)
df_test['RUL']=df_test['life']-df_test['cycle']
df_test.drop(['life'],axis=1,inplace=True)
# the RUL prediction is only useful nearer to the end of the engine's life, therefore we put an upper limit on the RUL
# this is a bit sneaky, since it supposes that the test set has RULs of less than this value, the closer you are
# to the true value, the more accurate the model will be
#df_train['RUL'][df_train['RUL']>125]=125
# In[ ]:
df_train
# In[ ]:
df_test
# In[ ]:
X_train = df_train.iloc[:,2:-1]
y_train = df_train.iloc[:,-1]
X_test = df_test.iloc[:,2:-1]
y_test = df_test.iloc[:,-1]
#
#
# ---
#
#
#
# _**(Problem 1)**_ Design a linear predictor (with appropriate feature engineering), and a deep learning predictor. Explain the structures and the design procedures of your predictors in details, and report your train MSE and test MSE for each predictor.
# In[ ]:
# your code here
# ---
#
#
# Contents partially reproduced from "Predictive Maintenance NASA Turbofan Regression" by Carl Kirstein..
#
#