#!/usr/bin/env python
# coding: utf-8
# # [講義] HyperSpy入門
#
# ## HyperSpyの概要
# 「HyperSpy」は、Pythonで記述された多次元データ解析のためのライブラリです。次のような特徴があります。
#
# - 電子顕微鏡、X線回折、走査プローブ顕微鏡、ラマン分光法などの信号解析ができます。
# - フィルタリング、線形回帰の他、主成分分析、非負値行列分解などのクラスタリング機能があります。
# - 可視化ツールが含まれています。
# - 化学元素のデータベースが含まれています。
#
# HyperSpyは非常に強力なライブラリですが、日本語の情報は、書籍もWebサイトもまったく見つかりません。英語の公式ドキュメントを見るのが確実という状況です。
#
# [https://hyperspy.org/hyperspy-doc/current/index.html](https://hyperspy.org/hyperspy-doc/current/index.html)
#
# そこで本講義では、このHyperSpyについて入門レベルのご紹介をします。けっこう貴重な講義かも!?
#
# はじめに、本講義で使用するファイルを皆さんの環境にダウンロードするため、次のコードを実行してください。
# # 本講義で使用するファイルのダウンロード
# 次のソースコードを、実行してください。Google Colaboratoryでソースコードを実行するには、ソースコードの任意の場所をクリックした後、次のどちらかの操作を行います。
#
# * ソースコード左上の実行ボタンを押す
# * Ctrl+Enterを押す
# In[ ]:
get_ipython().system('curl -L -o Fei_HAADF-DE_location.dm3 https://github.com/tendo-sms/python_intermediate_2023/raw/main/file_2/Fei_HAADF-DE_location.dm3')
get_ipython().system('curl -L -o core_shell.hdf5 https://github.com/tendo-sms/python_intermediate_2023/raw/main/file_2/core_shell.hdf5')
# # HyperSpyのインストール
# HyperSpyの公式ページでは何種類かのインストール方法が紹介されていますが今回は、
# * 既存のpython環境(anacondaではなく)にHyperSpyを追加したい
# * 必要以上のモジュールをインストールしたくない
#
# という理由で、pipコマンドでのインストール方法を使用します。
#
#
# In[ ]:
get_ipython().system('pip install hyperspy')
# # HyperSpyによるインタラクティブなグラフ操作について
# pipコマンドの終了を待つ間に・・
#
# HyperSpyでは、マウス操作で操作できるインタラクティブなグラフを描画できます。
#
# Jupyter NotebookやJupyterLabを使用する場合、デフォルトではインタラクティブなグラフではなく、単なる画像に変換されて表示されます。
#
# 次のコマンドを実行することで、インタラクティブなグラフを描画できるようになります。
#
# ~~~
# %matplotlib nbagg
# ~~~
#
# しかし・・・実は、Google Colaboratoryでは、インタラクティブなグラフを描画する方法がありません。単なる画像の表示のみ対応しています。
#
# 本講義ではGoogle Colaboratoryを利用するため、皆さんのお手元でインタラクティブな操作を実感することはできません。そのため、講師のPCでJupyter Notebookを使ったインタラクティブな操作をご覧いただきます。
# ## HyperSpyによるGUI表示プログラムについて
# HyperSpyの機能によっては、GUI操作が求められるものがもあります。
#
# この講義でもGUIの表示が必要なサンプルプログラムがあるので、次のパッケージをpipコマンドでインストールします。
# In[ ]:
get_ipython().system('pip install hyperspy_gui_traitsui==1.5.3')
# 事前準備はここまでです。
#
# いよいよ、HyperSpyを使ってプログラムを記述していきます。
# # HyperSpyのimport
# * 代表的なモジュールとして、「**hyperspy.api**」をimportするのが一般的です。
# * 慣例として、asを使って「**hs**」でimportします。
# ~~~
# import hyperspy.api as hs
# ~~~
# # とりあえずグラフを描画してみる
# HyperSpyにはいくつかのサンプルデータが元から用意されています。とりあえず、次の2つのサンプルデータをプロットしてみましょう。
#
# * SEMによるエネルギー分散型X線分析(EDS)データ
# * 鉄針のホログラムデータ
#
# グラフのプロットは、次の構文です。
#
# ~~~
# オブジェクト.plot()
# ~~~
#
# 次のコードを実行してください。
# In[ ]:
import hyperspy.api as hs
# SEMによるエネルギー分散型X線分析(EDS)データ
hs.datasets.example_signals.EDS_SEM_Spectrum().plot()
# 鉄針のホログラムデータ
hs.datasets.example_signals.object_hologram().plot()
# * Matplotlibでグラフを書く場合と異なり、グラフ種類やタイトル、軸ラベルなどをソースコード上で指定しなくても、装飾されていることが分かります。
# * HyperSpyが扱うオブジェクトには単にプロットする値が入っているのではなく、タイトルや軸の情報など、関連するメタデータも含まれています。
# * plotメソッドを呼び出すだけで、このような装飾付きのグラフとなります。
#
# メタデータの確認方法などは、このあと別の例でご説明します。
# # HyperSpyが対応するファイルフォーマット
# HyperSpyは、大別すると以下のフォーマットに対応しています。
#
# - バイナリファイル (Gatan’s dm3/dm4、EDAX spc and spd、MRCなど)
# - テキストファイル (ASCII、CSV、TSV、等間隔行列など)
# - HDF5形式ファイル
#
# 【ご参考】全ての対応フォーマットは公式ドキュメントの以下に記載があります。
#
# https://hyperspy.org/hyperspy-doc/current/user_guide/io.html#supported-formats
#
# Hyperspyは入力ファイルの拡張子やその内容から、ファイルの種類を推定し、適切なIOプラグインを選択してくれます。
#
# 今回の講義では、Gatanのdm3ファイルと、HDF5ファイルを題材としてご紹介します。
#
# 【ご参考】
# * dm3 (Digital Micrograph 3 )
# * Gatanの電子顕微鏡データを記録するファイル形式です。
# * HDF5 (Hierarchical Data Format 5)
# * データを階層構造で記録できる汎用的なファイル形式です。
# # ファイルの読み込み
# ## 形式自動判定の読み込み
# * HyperSpyは基本的に、データの形式を推測してオブジェクトのクラスを決定します。
# * 次のとおり「**load関数**」を使用します。
# * 変数には、読み込んだ結果のオブジェクトが格納されます。
#
# ~~~
# 変数 = hs.load(ファイル名)
# ~~~
# ## 形式明示指定の読み込み
# * データ形式を明示指定することもできます。
# * 「**signal_typeオプション**」を指定します。
#
# ~~~
# 変数 = hs.load(ファイル名, signal_type=形式)
# ~~~
# なおsignal_typeに指定できる形式は、次の関数を実行して一覧表示することができます。
# In[ ]:
hs.print_known_signal_types()
# ## dm3ファイルの読み込み例
# 最初にダウンロードしたファイルの中に、STEMで計測された16 x 4の2次元データ「Fei_HAADF-DE_location.dm3」があります。
#
# これを読み込んでプロットしてみましょう。
#
# In[ ]:
import hyperspy.api as hs
s = hs.load("Fei_HAADF-DE_location.dm3")
s.plot()
# ### 元ファイルのメタデータ
# 元の入力ファイル(HyperSpyの形式に変換される前のもの)に含まれていたメタデータは、次の変数に格納されています。
#
# ~~~
# オブジェクト.original_metadata
# ~~~
#
# 先ほど読み込んだファイルに元から含まれていたメタデータを確認してみます。
# In[ ]:
import hyperspy.api as hs
s = hs.load("Fei_HAADF-DE_location.dm3")
s.original_metadata
# 【ワンポイント】
#
# データを画面表示するにはprint関数を使うのが基本ですが、ここではGoogle Colaboratoryの独自機能を活用して、print関数を使わずにデータを画面表示しました。この独自機能は、単に変数名を記述するだけで、データを見やすく画面表示することができます。他にもJupyter Notebook等、Pythonが「対話モード」で動作している環境はこのような機能を持ち、処理方法を試行錯誤する際には非常に便利です。
#
# 一方で、処理方法確定時に作ることが多い、拡張子が.pyとなっている「普通のPythonプログラム」は「スクリプトモード」で動作し、変数名だけでは画面表示をしません。
#
# Python初級者セミナーでは、「対話モード」特有機能を多用して変なクセを付けてしまわないように、データの画面表示は一貫してprint関数を使ってご説明しました。中級者編にご参加されている皆様は心配ないと思いますので、便利さ重視でソースコードを記述しています。
# ## HyperSpyが自動的に付与したメタデータ
# HyperSpyが元の入力ファイルから判断して自動的に付与したメタデータは、次の変数に格納されています。
#
# ~~~
# オブジェクト.metadata
# ~~~
#
# 先ほど読み込んだファイルに対して、HyperSpyが自動的に付与したメタデータを確認してみます。
# In[ ]:
import hyperspy.api as hs
s = hs.load("Fei_HAADF-DE_location.dm3")
s.metadata
# これらのメタデータを更新したり、新たに追加したりすることもできます。
# In[ ]:
import hyperspy.api as hs
s = hs.load("Fei_HAADF-DE_location.dm3")
# メタデータの更新
s.metadata.General.title = "Update title"
# メタデータの追加
s.metadata.New_value = "New value"
s.metadata
# ## プロットされる実データ
# プロットされる実データは、次の変数に格納されています。
#
# ~~~
# オブジェクト.data
# ~~~
#
# 次のコードを実行してください。
# In[ ]:
import hyperspy.api as hs
s = hs.load("Fei_HAADF-DE_location.dm3")
s.data
# プロットされる実データは、NumPy配列です。
#
# そのため、データに対してNumPyの様々な機能を使うことができます。
# In[ ]:
import numpy as np
import hyperspy.api as hs
s = hs.load("Fei_HAADF-DE_location.dm3")
# 配列形状の取得
print(s.data.shape)
# 平均値の取得
print(np.mean(s.data))
# ## その他の情報表示
# その他にも、様々な情報を取得できます。色々と試してみてください。
#
# ~~~
# オブジェクト.axes_manager
# オブジェクト.print_summary_statistics()
# ~~~
# In[ ]:
import hyperspy.api as hs
s = hs.load("Fei_HAADF-DE_location.dm3")
# 色々と試してみましょう
# ## ファイルの保存
# 作成・編集したデータを保存するには、「**saveメソッド**」を使用します。
#
# * 引数にファイル名を指定し、ファイル名の拡張子を参照しファイルフォーマットを決定します。
#
# * 保存できるフォーマットは、下記のWriteがYesのものです。
#
# [https://hyperspy.org/hyperspy-doc/current/user_guide/io.html#supported-formats](https://hyperspy.org/hyperspy-doc/current/user_guide/io.html#supported-formats)
#
# * 拡張子を指定しない場合は、デフォルトではhspy(HyperSpy標準のHDF5形式)で保存します。
# In[ ]:
import hyperspy.api as hs
s = hs.load("Fei_HAADF-DE_location.dm3")
# メタデータの更新
s.metadata.General.title = "Update title"
# 拡張子を省略してhspy形式で保存
s.save("output")
# 保存したファイルを開いて、タイトルの変更が反映されていることを確認してみます。
# In[ ]:
import hyperspy.api as hs
s = hs.load("output.hspy")
s.metadata
# # HyperSpyで取り扱うデータの詳細
# ここからは、HyperSpyで取り扱うデータについて、さらに深堀りしていきます。
# ## シグナルとナビゲーション
# HyperSpyのデータには、「**シグナル**」と「**ナビゲーション**」という概念があります。
#
# まずは、これらの概念についてご説明します。
#
# * シグナル
# * HyperSpyでは、データセットを信号配列として扱います。これを「シグナル」と呼びます。
#
# * ナビゲーション
# * 3Dデータの場合は、シグナルに「ナビゲーション」が加わります。
# * ナビゲーションは、複数のシグナルを管理し、3Dデータのスライスや視覚化の設定を扱います。
#
# ## シグナルのサブクラス
# hs.load()を利用してロードしたデータは、全て「**BaseSigalクラス**」を継承したサブクラスに保管されます。
#
# BaseSignalクラスには、様々なサブクラスがあります。
#
# サブクラスは、階層構造になっています。
#
# * Signal1D
# * EDSSpectrum
# * EDSTEMSpetrum
# * EDSSEMSpetrum
# * EELSSpectrum
# * Signal2D
# * HologramImage
# * ...など
#
# 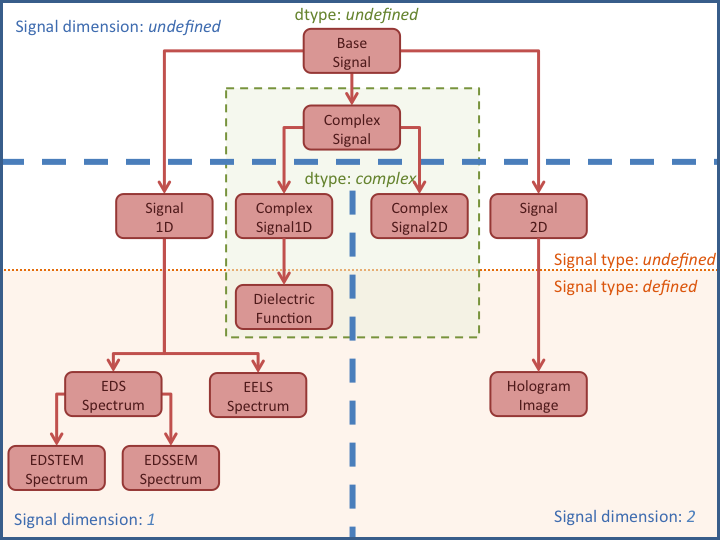 #
#
# 図出展:
# [https://hyperspy.org/hyperspy-doc/current/user_guide/signal.html#transforming-between-signal-subclasses](https://hyperspy.org/hyperspy-doc/current/user_guide/signal.html#transforming-between-signal-subclasses)
#
# サブクラスは、データの持つ以下の要素によって**自動的**に選択されます。
# * Signalの次元数
# * signal_type
# * dtype (real/complex) ※complex: 複素数/振幅/位相など
# ## データの形式確認
# HyperSpyのデータをprint関数で出力すると、シグナルやナビゲーションの情報が分かります。
#
# 次のコードは、データ「core_shell.hdf5」の情報を表示します。まずは実行してみてください。
#
# (非推奨のメタデータを使っていることを示すWarningが出ることもありますが、ここでは無視します。)
# In[ ]:
import hyperspy.api as hs
s = hs.load("core_shell.hdf5")
print(s)
# 出力結果は、次の意味となります。
#
# ~~~
# <シグナルクラス, title: データタイトル, dimensions: (ナビゲーションの次元数|シグナルの次元数)>
# ~~~
#
# シグナルクラスは、次の情報から「EDSTEMSpectrum」と判定されています。
# * シグナルの次元数: 1
# * dtype: uint32(real)
# * signal_type: EDS_SEM
# * BaseSignalのサブクラスと、自動判定の条件となるmetadataの属性の一覧は以下のとおりです。
#
# | BaseSignal subclass | signal_dimension | signal_type | dtype |
# | ---- | ---- | ---- | ---- |
# | BaseSignal | - | - | real |
# | Signal1D | 1 | - | real |
# | EELSSpectrum | 1 | EELS | real |
# | EDSSEMSpectrum | 1 | EDS_SEM | real |
# | EDSTEM | 1 | EDS_TEM | real |
# | Signal2D | 2 | - | real |
# | HologramImage | 2 | hologram | real |
# | DielecticFuntion | 1 | - | complex |
# | ComplexSignal | - | - | complex |
# | ComplexSignal1D | 1 | - | complex |
# | Complex2D | 2 | - | complex| |
#
# ナビゲーションの次元数は2次元であることが分かります。
#
# 使用可能なサブクラスは、hs.print_known_signal_types()で確認できます。
# In[ ]:
import hyperspy.api as hs
hs.print_known_signal_types()
# なお、HyperSpyの拡張パッケージをインストールすることで、サブクラスを追加することもできます。
#
# * 拡張パッケージ: [https://github.com/hyperspy/hyperspy-extensions-list](https://github.com/hyperspy/hyperspy-extensions-list)
# ## インタラクティブなグラフ表示
# ### 2次元のナビゲーション
# 先ほど情報を確認したEDS TEMのスペクトルデータを、plotでグラフ表示してみます。
# In[ ]:
import hyperspy.api as hs
s = hs.load("core_shell.hdf5")
s.plot()
# * 上半分の図が、64 x 64のナビゲーションです。
# * 下半分の図が、992のシグナルデータです。
#
# ナビゲーションの右上をよく見てください。赤い四角があるのが分かるでしょうか。
#
# この赤い四角は、マウスでドラッグすることで場所を変更できます。赤い四角がある場所に対応するシグナルデータが、下半分にグラフで描画されます。
#
#
# ・・・なのですが、最初にご説明したとおり、残念ながらGoogle Colaboratoryではこのようなインタラクティブな操作はできません。
#
# 講師の画面でお見せしますので、そちらをご覧ください。
#
#
# ### 1次元のナビゲーション
# 今度は、1次元のナビゲーションを持つデータを見てみたいと思います。
#
# HyperSpyの公式サンプルには該当するデータがないため、ここでは、適当なデータをNumPy配列から作成してみます。
#
# 次の構文でNumPy配列からシグナルクラスののオブジェクトを作成することができます。
#
# ~~~
# hs.signals.クラス名(NumPy配列)
# ~~~
#
# 次のコードは、ランダムな値で作成したNumPy配列から、Signal1Dサブクラスのオブジェクトを作成します。
# In[ ]:
import numpy as np
import hyperspy.api as hs
s = hs.signals.Signal2D(np.random.random_sample((10, 20, 100)))
print(s)
# ナビゲーションが1次元、シグナルが2次元のデータが作成できました。
#
# これをプロットしてみましょう。
# In[ ]:
import numpy as np
import hyperspy.api as hs
s = hs.signals.Signal2D(np.random.random_sample((10, 20, 100)))
print(s)
s.plot()
# * 上半分の図が、データ数10のナビゲーションです。
# * 下半分の図が、20 x 100のシグナルデータです。
#
# ナビゲーションの左端に、赤い線があるのが分かるでしょうか。
#
# この赤い線をマウスでドラッグすることで、その場所に対応するシグナルデータが、下半分に描画されます。
#
# こちらも残念ながらGoogle Colaboratoryでは操作できませんので、講師の画面でお見せします。
# # HyperSpyによるデータの活用
# ここまでは、単にグラフを表示・保存するだけでした。
#
# ここからは応用として、スムージングやモデルフィッティングなどの、データの活用例をご紹介します。
#
# ここからのご説明は、ソースコードを上から順番に実行する必要があるので、動かしてみる際はご注意ください。
#
# 最初に、必要なモジュールとしてHyperSpyとMatplotlibをimportします。
# In[ ]:
import hyperspy.api as hs
import matplotlib.pyplot as plt
# サンプルデータとして、HyperSpyライブラリから提供されているEDS-TEM(エネルギー分散型X線分光法-透過型電子顕微鏡)を使ってみます。
#
#
# In[ ]:
# テスト用のEDS-TEMデータを読み込み
s = hs.datasets.example_signals.EDS_TEM_Spectrum()
# プロット
s.plot()
# # Signal1Dのツール
#
# HyperSpyでは、スペクトルなどの1次元データの処理ツールが充実しています。
#
# 別のツールと組み合わせて、自分で実装しなくてもHyperSpyだけで色々と調査・解析することができます。
# ## バックグラウンドの除去
#
# バックグラウンド(本来の信号以外に計測されるノイズや不要な信号)の除去モデルとして、HyperSpyでは以下の形状をサポートしています。
#
# - Doniach
# - Exponential
# - Gaussian
# - Lorentzian
# - Polynomial
# - Power law (デフォルト)
# - Offset
# - Skew normal
# - Split Voigt
# - Voigt
#
#
# GUIがあれば、範囲を指定できますがGoogle Colaboratoryでは利用できないのでCUIモードで実行します。
#
#
# In[ ]:
# バックグラウンドを除去
sb = s.remove_background(signal_range=(0, 10), zero_fill=False, background_type="PowerLaw")
# 同時に描画したいときはSignal1Dのリストにする
hs.plot.plot_spectra([s, sb], legend=["org", "background remove"])
# 簡易的にやってみたい場合はfastオプションを使うと速く結果をみることもできます。
#
# ## スムージング
#
# 以下3種のスムージングが可能です。
# 1. Lowess data smoothing
# 2. Total variation data smoothing
# 3. Savitzky-Golay filter
# In[ ]:
# Lowess data smoothing
sb.plot()
sb.smooth_lowess()
# In[ ]:
# Total variation data smoothing
sb.plot()
sb.smooth_tv()
# In[ ]:
# Savitzky-Golay filter
sb.plot()
sb.smooth_savitzky_golay()
# 【ワンポイント】
#
# スムージングのデータそのものを取得したいときは、次のように指定することで取得できます。
#
# ~~~
# snpm = sb.smooth_lowess(display=False)["traitsui"].get()["single_spectrum"]
# ~~~
# ## スパイクの除去
#
# GUIが使える環境だと、動的な操作でスパイクを確認しながら除去できます。
# Google Colaboratoryでは表示できないので紹介だけです。
#
# ただし、元の信号は失われてしまうのでコピーしてからスパイクの除去を実施します。
# In[ ]:
# スムーシングした信号をコピー
sbp = sb.deepcopy()
# スパイクノイズの除去
sbp.spikes_removal_tool(interactive=False, threshold=1)
hs.plot.plot_spectra([sb, sbp], legend=["before", "remove spike"])
# ## ピークの検出
#
# GUIが使える環境だと、動的な操作でスパイクを確認しながら除去できます。
#
# Google Colaboratoryでは動的操作は表示できないので紹介だけです。
# In[ ]:
# ピークの検出
peaks = sbp.find_peaks1D_ohaver()
print(peaks[0]["position"])
sbp.plot()
for p in peaks[0]["position"]:
plt.axvline(x=p, color="blue", linestyle="--")
# # モデルフィッティング
#
# モデルフィッティングによる信号処理も簡単に行うことができます。
#
# 例えば、これまで取り扱ったSignal1D(1次元シグナル)では事前に色んなモデル関数が提供されています。
#
# ## Components1D
#
# - components1D
# - Arctan
# - Bleasdale
# - Doniach
# - Erf
# - Exponential
# - Expression
# - Gaussian
# - GaussianHF
# - HeavisideStep
# - Logistic
# - Lorentzian
# - Offset
# - Polynomial
# - PowerLaw
# - SEE
# - ScalableFixedPattern
# - SkewNormal
# - Voigt
# - SplitVoigt
# - VolumePlasmonDrude
#
# - components1D(特定のシグナルタイプ対象)
# - EELSArctan
# - DoublePowerLaw
# - EELSCLEdge
# - PESCoreLineShape
# - PESVoigt
# - SEE
# - Vignetting
#
#
# まずは、モデルを定義してみましょう。
# In[ ]:
# モデルの作成
m = sbp.create_model()
# 中身を確認してみます。
# In[ ]:
# モデルの一覧
m.components
# 色々なモデルがすでに定義されているようですね。
#
# 実は、HyperSpyではEDS(エネルギー分散型X線分光)スペクトルに基づいて複数のモデルを自動的に作成してくれています。
#
# ここでは、わかりやすくするために全部のモデルを消去してから作り直してみましょう。
# In[ ]:
# モデルを全消去
m.clear()
m.components
# 全部消去されましたね。
#
# では、ガウシアンモデルをひとつ追加してみます。
# In[ ]:
# ガウシアンモデルを追加
m.append(hs.model.components1D.Gaussian())
m.components
# データとモデル結果を描画してみます。
#
# plot_componentsオプションは複数のモデルがある場合に、それぞれ表示させるかどうかを決めることができます。
# In[ ]:
# プロット
m.plot(plot_components=False)
# まだガウシアンモデルはパラメータをフィッティングできていないことがわかります。
#
# モデルのパラメータを確認してみましょう。
# In[ ]:
# パラメータの表示
m.print_current_values()
# では、フィッティングさせてみます。
# In[ ]:
# フィッティング
m.multifit()
m.print_current_values()
# パラメータが変化しました。うまくフィッティングできたか描画してみます。
# In[ ]:
# プロット
m.plot(plot_components=False)
# ひとつの山はフィッティングできたようですが、複数あるので不十分に感じます。
#
# ここからが、HyperSpyの見せ所です。
#
# モデルをどんどん追加していくことができます。
# In[ ]:
# ガウシアンモデルを2つ追加
for _ in range(2):
m.append(hs.model.components1D.Gaussian())
m.multifit()
m.plot(plot_components=False)
# 思った通りになっているでしょうか。
#
# パラメータは直接、編集することもできますので、ある程度は自動的にしてあとは手動でも解析することもできます。
#
# これらの方法はあとから課題に挑戦してみてください。
#
# # 機械学習
#
# 今回は詳しくは説明できませんでしたが、HyperSpyには機械学習アルゴリズムも豊富に提供されています。
#
# - 特異値分解
# - SVD(デフォルト)
# - PCA
# - MLPCA
# - sklearn_pca
# - NMF
# - sparse_pca
# - mini_batch_sparse_pca
# - RPCA
# - ORPCA
# - ORNMF
# - ブラインド信号源分離
# - sklearn_fastica(デフォルト)
# - orthomax
# - FastICA
# - JADE
# - CuBICA
# - TDSEP
# - クラスター分析
# - scikit-learnのsklearn.clustering
# # まとめ
#
# HyperSpyのパワフルさはいかがでしたでしょうか?
#
# * 多種多様なマテリアルフォーマットのデータを読み込む。
# * データの特徴を可視化しながら確認する。
# * バックグラウンドやスパイクノイズを除去する。
# * スムーシングやカーブフィッティングして特徴量を確認する。
# * 機械学習にかけて分析を行う。
#
# これらの一連の作業が、HyperSpyだけで可能になります。
#
# 複数ライブラリを組み合わせずとも、HyperSpyだけでコードを完結させるとメンテナンス性も向上して、研究者間でのコード共有化もはかどるのではないでしょうか?
#
#
# 図出展:
# [https://hyperspy.org/hyperspy-doc/current/user_guide/signal.html#transforming-between-signal-subclasses](https://hyperspy.org/hyperspy-doc/current/user_guide/signal.html#transforming-between-signal-subclasses)
#
# サブクラスは、データの持つ以下の要素によって**自動的**に選択されます。
# * Signalの次元数
# * signal_type
# * dtype (real/complex) ※complex: 複素数/振幅/位相など
# ## データの形式確認
# HyperSpyのデータをprint関数で出力すると、シグナルやナビゲーションの情報が分かります。
#
# 次のコードは、データ「core_shell.hdf5」の情報を表示します。まずは実行してみてください。
#
# (非推奨のメタデータを使っていることを示すWarningが出ることもありますが、ここでは無視します。)
# In[ ]:
import hyperspy.api as hs
s = hs.load("core_shell.hdf5")
print(s)
# 出力結果は、次の意味となります。
#
# ~~~
# <シグナルクラス, title: データタイトル, dimensions: (ナビゲーションの次元数|シグナルの次元数)>
# ~~~
#
# シグナルクラスは、次の情報から「EDSTEMSpectrum」と判定されています。
# * シグナルの次元数: 1
# * dtype: uint32(real)
# * signal_type: EDS_SEM
# * BaseSignalのサブクラスと、自動判定の条件となるmetadataの属性の一覧は以下のとおりです。
#
# | BaseSignal subclass | signal_dimension | signal_type | dtype |
# | ---- | ---- | ---- | ---- |
# | BaseSignal | - | - | real |
# | Signal1D | 1 | - | real |
# | EELSSpectrum | 1 | EELS | real |
# | EDSSEMSpectrum | 1 | EDS_SEM | real |
# | EDSTEM | 1 | EDS_TEM | real |
# | Signal2D | 2 | - | real |
# | HologramImage | 2 | hologram | real |
# | DielecticFuntion | 1 | - | complex |
# | ComplexSignal | - | - | complex |
# | ComplexSignal1D | 1 | - | complex |
# | Complex2D | 2 | - | complex| |
#
# ナビゲーションの次元数は2次元であることが分かります。
#
# 使用可能なサブクラスは、hs.print_known_signal_types()で確認できます。
# In[ ]:
import hyperspy.api as hs
hs.print_known_signal_types()
# なお、HyperSpyの拡張パッケージをインストールすることで、サブクラスを追加することもできます。
#
# * 拡張パッケージ: [https://github.com/hyperspy/hyperspy-extensions-list](https://github.com/hyperspy/hyperspy-extensions-list)
# ## インタラクティブなグラフ表示
# ### 2次元のナビゲーション
# 先ほど情報を確認したEDS TEMのスペクトルデータを、plotでグラフ表示してみます。
# In[ ]:
import hyperspy.api as hs
s = hs.load("core_shell.hdf5")
s.plot()
# * 上半分の図が、64 x 64のナビゲーションです。
# * 下半分の図が、992のシグナルデータです。
#
# ナビゲーションの右上をよく見てください。赤い四角があるのが分かるでしょうか。
#
# この赤い四角は、マウスでドラッグすることで場所を変更できます。赤い四角がある場所に対応するシグナルデータが、下半分にグラフで描画されます。
#
#
# ・・・なのですが、最初にご説明したとおり、残念ながらGoogle Colaboratoryではこのようなインタラクティブな操作はできません。
#
# 講師の画面でお見せしますので、そちらをご覧ください。
#
#
# ### 1次元のナビゲーション
# 今度は、1次元のナビゲーションを持つデータを見てみたいと思います。
#
# HyperSpyの公式サンプルには該当するデータがないため、ここでは、適当なデータをNumPy配列から作成してみます。
#
# 次の構文でNumPy配列からシグナルクラスののオブジェクトを作成することができます。
#
# ~~~
# hs.signals.クラス名(NumPy配列)
# ~~~
#
# 次のコードは、ランダムな値で作成したNumPy配列から、Signal1Dサブクラスのオブジェクトを作成します。
# In[ ]:
import numpy as np
import hyperspy.api as hs
s = hs.signals.Signal2D(np.random.random_sample((10, 20, 100)))
print(s)
# ナビゲーションが1次元、シグナルが2次元のデータが作成できました。
#
# これをプロットしてみましょう。
# In[ ]:
import numpy as np
import hyperspy.api as hs
s = hs.signals.Signal2D(np.random.random_sample((10, 20, 100)))
print(s)
s.plot()
# * 上半分の図が、データ数10のナビゲーションです。
# * 下半分の図が、20 x 100のシグナルデータです。
#
# ナビゲーションの左端に、赤い線があるのが分かるでしょうか。
#
# この赤い線をマウスでドラッグすることで、その場所に対応するシグナルデータが、下半分に描画されます。
#
# こちらも残念ながらGoogle Colaboratoryでは操作できませんので、講師の画面でお見せします。
# # HyperSpyによるデータの活用
# ここまでは、単にグラフを表示・保存するだけでした。
#
# ここからは応用として、スムージングやモデルフィッティングなどの、データの活用例をご紹介します。
#
# ここからのご説明は、ソースコードを上から順番に実行する必要があるので、動かしてみる際はご注意ください。
#
# 最初に、必要なモジュールとしてHyperSpyとMatplotlibをimportします。
# In[ ]:
import hyperspy.api as hs
import matplotlib.pyplot as plt
# サンプルデータとして、HyperSpyライブラリから提供されているEDS-TEM(エネルギー分散型X線分光法-透過型電子顕微鏡)を使ってみます。
#
#
# In[ ]:
# テスト用のEDS-TEMデータを読み込み
s = hs.datasets.example_signals.EDS_TEM_Spectrum()
# プロット
s.plot()
# # Signal1Dのツール
#
# HyperSpyでは、スペクトルなどの1次元データの処理ツールが充実しています。
#
# 別のツールと組み合わせて、自分で実装しなくてもHyperSpyだけで色々と調査・解析することができます。
# ## バックグラウンドの除去
#
# バックグラウンド(本来の信号以外に計測されるノイズや不要な信号)の除去モデルとして、HyperSpyでは以下の形状をサポートしています。
#
# - Doniach
# - Exponential
# - Gaussian
# - Lorentzian
# - Polynomial
# - Power law (デフォルト)
# - Offset
# - Skew normal
# - Split Voigt
# - Voigt
#
#
# GUIがあれば、範囲を指定できますがGoogle Colaboratoryでは利用できないのでCUIモードで実行します。
#
#
# In[ ]:
# バックグラウンドを除去
sb = s.remove_background(signal_range=(0, 10), zero_fill=False, background_type="PowerLaw")
# 同時に描画したいときはSignal1Dのリストにする
hs.plot.plot_spectra([s, sb], legend=["org", "background remove"])
# 簡易的にやってみたい場合はfastオプションを使うと速く結果をみることもできます。
#
# ## スムージング
#
# 以下3種のスムージングが可能です。
# 1. Lowess data smoothing
# 2. Total variation data smoothing
# 3. Savitzky-Golay filter
# In[ ]:
# Lowess data smoothing
sb.plot()
sb.smooth_lowess()
# In[ ]:
# Total variation data smoothing
sb.plot()
sb.smooth_tv()
# In[ ]:
# Savitzky-Golay filter
sb.plot()
sb.smooth_savitzky_golay()
# 【ワンポイント】
#
# スムージングのデータそのものを取得したいときは、次のように指定することで取得できます。
#
# ~~~
# snpm = sb.smooth_lowess(display=False)["traitsui"].get()["single_spectrum"]
# ~~~
# ## スパイクの除去
#
# GUIが使える環境だと、動的な操作でスパイクを確認しながら除去できます。
# Google Colaboratoryでは表示できないので紹介だけです。
#
# ただし、元の信号は失われてしまうのでコピーしてからスパイクの除去を実施します。
# In[ ]:
# スムーシングした信号をコピー
sbp = sb.deepcopy()
# スパイクノイズの除去
sbp.spikes_removal_tool(interactive=False, threshold=1)
hs.plot.plot_spectra([sb, sbp], legend=["before", "remove spike"])
# ## ピークの検出
#
# GUIが使える環境だと、動的な操作でスパイクを確認しながら除去できます。
#
# Google Colaboratoryでは動的操作は表示できないので紹介だけです。
# In[ ]:
# ピークの検出
peaks = sbp.find_peaks1D_ohaver()
print(peaks[0]["position"])
sbp.plot()
for p in peaks[0]["position"]:
plt.axvline(x=p, color="blue", linestyle="--")
# # モデルフィッティング
#
# モデルフィッティングによる信号処理も簡単に行うことができます。
#
# 例えば、これまで取り扱ったSignal1D(1次元シグナル)では事前に色んなモデル関数が提供されています。
#
# ## Components1D
#
# - components1D
# - Arctan
# - Bleasdale
# - Doniach
# - Erf
# - Exponential
# - Expression
# - Gaussian
# - GaussianHF
# - HeavisideStep
# - Logistic
# - Lorentzian
# - Offset
# - Polynomial
# - PowerLaw
# - SEE
# - ScalableFixedPattern
# - SkewNormal
# - Voigt
# - SplitVoigt
# - VolumePlasmonDrude
#
# - components1D(特定のシグナルタイプ対象)
# - EELSArctan
# - DoublePowerLaw
# - EELSCLEdge
# - PESCoreLineShape
# - PESVoigt
# - SEE
# - Vignetting
#
#
# まずは、モデルを定義してみましょう。
# In[ ]:
# モデルの作成
m = sbp.create_model()
# 中身を確認してみます。
# In[ ]:
# モデルの一覧
m.components
# 色々なモデルがすでに定義されているようですね。
#
# 実は、HyperSpyではEDS(エネルギー分散型X線分光)スペクトルに基づいて複数のモデルを自動的に作成してくれています。
#
# ここでは、わかりやすくするために全部のモデルを消去してから作り直してみましょう。
# In[ ]:
# モデルを全消去
m.clear()
m.components
# 全部消去されましたね。
#
# では、ガウシアンモデルをひとつ追加してみます。
# In[ ]:
# ガウシアンモデルを追加
m.append(hs.model.components1D.Gaussian())
m.components
# データとモデル結果を描画してみます。
#
# plot_componentsオプションは複数のモデルがある場合に、それぞれ表示させるかどうかを決めることができます。
# In[ ]:
# プロット
m.plot(plot_components=False)
# まだガウシアンモデルはパラメータをフィッティングできていないことがわかります。
#
# モデルのパラメータを確認してみましょう。
# In[ ]:
# パラメータの表示
m.print_current_values()
# では、フィッティングさせてみます。
# In[ ]:
# フィッティング
m.multifit()
m.print_current_values()
# パラメータが変化しました。うまくフィッティングできたか描画してみます。
# In[ ]:
# プロット
m.plot(plot_components=False)
# ひとつの山はフィッティングできたようですが、複数あるので不十分に感じます。
#
# ここからが、HyperSpyの見せ所です。
#
# モデルをどんどん追加していくことができます。
# In[ ]:
# ガウシアンモデルを2つ追加
for _ in range(2):
m.append(hs.model.components1D.Gaussian())
m.multifit()
m.plot(plot_components=False)
# 思った通りになっているでしょうか。
#
# パラメータは直接、編集することもできますので、ある程度は自動的にしてあとは手動でも解析することもできます。
#
# これらの方法はあとから課題に挑戦してみてください。
#
# # 機械学習
#
# 今回は詳しくは説明できませんでしたが、HyperSpyには機械学習アルゴリズムも豊富に提供されています。
#
# - 特異値分解
# - SVD(デフォルト)
# - PCA
# - MLPCA
# - sklearn_pca
# - NMF
# - sparse_pca
# - mini_batch_sparse_pca
# - RPCA
# - ORPCA
# - ORNMF
# - ブラインド信号源分離
# - sklearn_fastica(デフォルト)
# - orthomax
# - FastICA
# - JADE
# - CuBICA
# - TDSEP
# - クラスター分析
# - scikit-learnのsklearn.clustering
# # まとめ
#
# HyperSpyのパワフルさはいかがでしたでしょうか?
#
# * 多種多様なマテリアルフォーマットのデータを読み込む。
# * データの特徴を可視化しながら確認する。
# * バックグラウンドやスパイクノイズを除去する。
# * スムーシングやカーブフィッティングして特徴量を確認する。
# * 機械学習にかけて分析を行う。
#
# これらの一連の作業が、HyperSpyだけで可能になります。
#
# 複数ライブラリを組み合わせずとも、HyperSpyだけでコードを完結させるとメンテナンス性も向上して、研究者間でのコード共有化もはかどるのではないでしょうか?