#!/usr/bin/env python
# coding: utf-8
# # Modeling Probabilities & Non-Linearities: Activation Functions
#
# In this chapter, we will:
#
# - Learn what is an activation function.
# - Learn about the standard hidden activation functions
# - Sigmoid
# - Tanh
# - Learn about the standard output activation functions
# - Softmax
#
# > [George Gordon Byron] "I Know that 2 and 2 make 4 –– & should be glad to prove it too if I could –– though I must say if by any sort of process I could convert 2 & 2 into 5 it would give me much greater pleasure"
# ## What is an Activation Function?
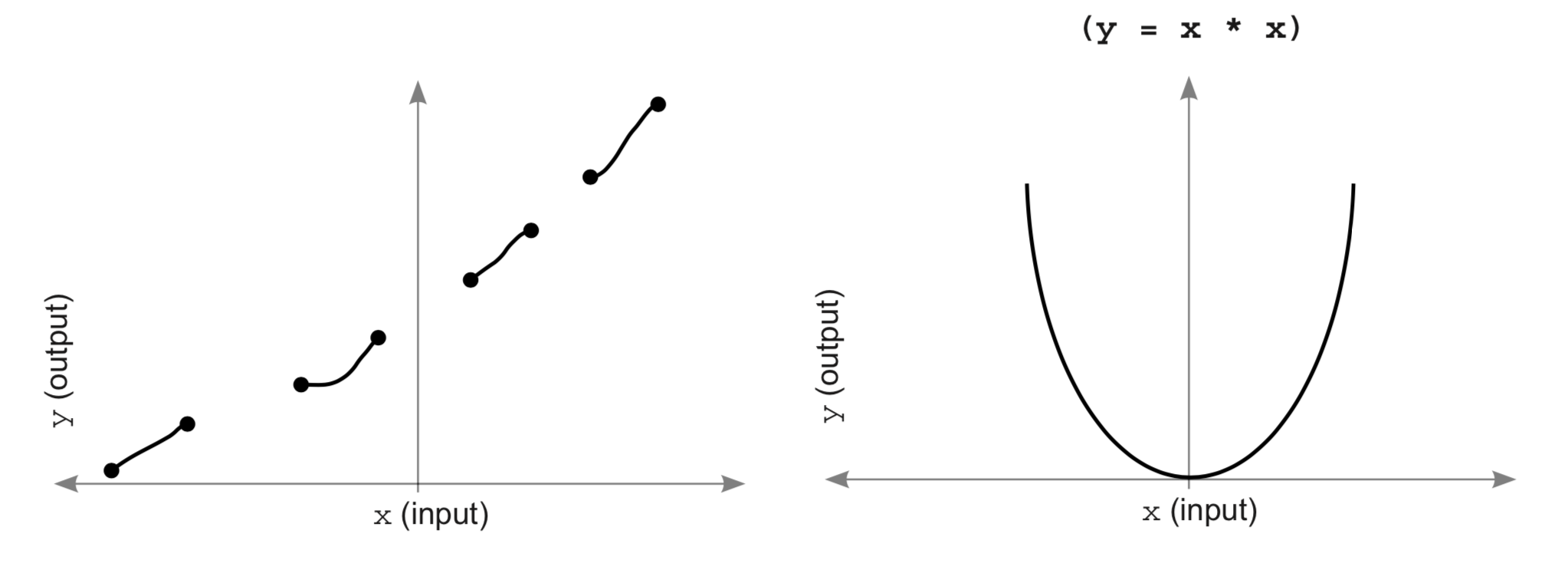
# An activation function is a function applied to the neurons in a layer during prediction. In that sense, an activation function is any function that can take one number and return another number. There are, however, an infinite number of functions in the universe, and not all of them are useful as activation functions.
#
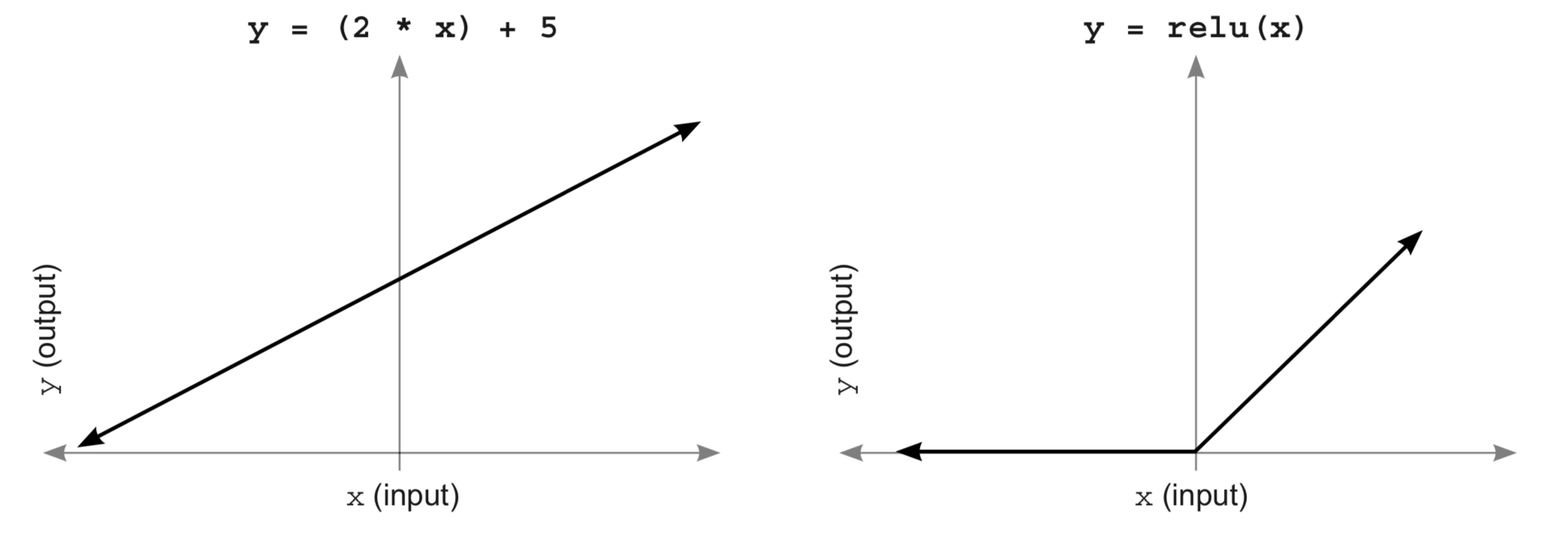
# We've already used an activation function called `ReLU`. The `ReLU` function had the effect of turning all negative numbers to zero.
#
# There are many constraints on the nature of activation functions, we present them next.
# ### Constraint 1: The Function must be Continuous & Infinite in Domain
#
#
#
#
# Meaning that the function must have an output number for any input.
# ### Constraint 2: Good Activation Functions are Monotonic (Increasing/Decreasing)
#
#
#
# An activation function must never change direction (always increasing/decreasing). This particular constrraint is not technically a requirement but if we consider a function that map different input values to the same output, then that function may have multiple perfect configurations. As a result, we can't know the correct direction to go.
#
# For an advanced look into this subject, we should look more into convex versus non-convex optimization.
# ### Constraint 3: Good Activation Functions are Non-Linear
#
#
#
# Linear functions scale values, they do not effect how correlated a neuron is to various inputs. They just make the collective corrrelation that is represented louder or softer.
#
# What we want instead is **selective correlation**.
# ### Constraint 4: Good Activation Functions (& their derivatives) should be efficiently computable
#
# We will be using the chosen activation functions a lot. For this reason, we want them (and their derivatives) to be efficiently computable. As an example, `ReLU` has become very popular mostly because it's efficient to compute.
# ## Standard Hidden-Layer Activation Functions
# ### Which ones are most commonly used?
# ### Sigmoid is the bread & butter Activation
#
#
#
# Sigmoid is great because it smoothly squinshes the infinite amount of input to an output between $0$ and $1$. This lets us interpret the output of any neuron as a **probability**. We typically use this non-linearity both in hidden and outputs layers.
# ### Tanh is better than sigmoid for hidden layers
#
#
#
# `Tanh` is the same as sigmoid except it's between `-1` and `1`. This means it can also throw in some **negative** correlation. This aspect of negative correlation is powerful for hidden layers. On many problems, `tanh` will outperform sigmoid in the hidden layers.
# ## Standard output layer activation functions
#
# For output layer activation functions, choosing the best one depends on what we're trying to predict. Broadly speaking, there are 3 major types of output layers:
# ### Configuration 1: Predicting Raw Data Values (Regression) — No activation function
#
# One example might be predicting the average temperature in colorado given the average temperature in surrounding states.
# ### Configuration 2: Predicting Unrelated Yes/No Probabilities (Binary Classification) — Sigmoid
#
# It's best to use the sigmoid function, Because it models individual probabilities separately for each output node.
# ### Configuration 3: Predicting which-one probabilities (Categorical Classification) — Softmax
#
# This is by far the common use case in neural networks: predicting a single label out of many. In this case, it's better to have an activation function that models the idea that "The more likely it's one label, The less likely it's any of the other labels".
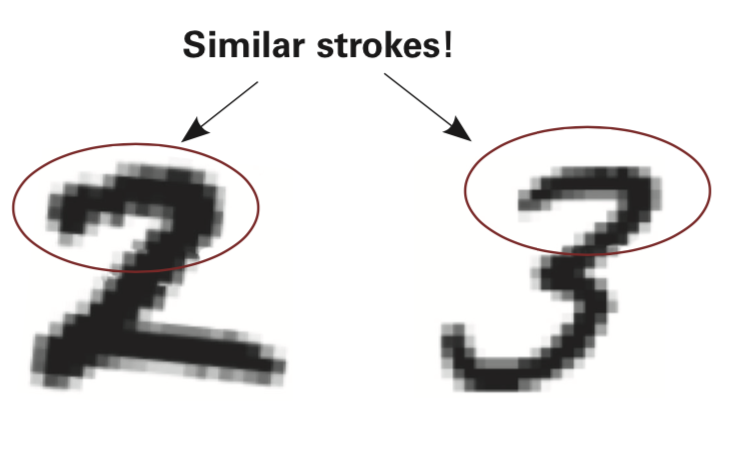
# ## The Core Issue: Inputs have similarity
# ### Different numbers share characteristics. It's good to let the network believe that
#
#
#
#
#
#
#
#

#
#

#