#!/usr/bin/env python
# coding: utf-8
# 
#
# ---
# # Workshop 1.2: Acquiring Data
#
# * **Contributors**:
# * Roberto Rodriguez (@Cyb3rWard0g)
# * Jose Rodriguez (@Cyb3rPandah)
# * Ian Hellen (@ianhellen, gh:@ianhelle)
#
# * **Agenda**:
# * [Reading data from SIEMs and Databases](#reading)
# * [OTR Security Datasets - (aka Mordor)](#mordor)
#
# * **Notebook**: [https://aka.ms/Jupyterthon-ws-1-2](https://aka.ms/Jupyterthon-ws-1-2)
# * **License**: [Creative Commons Attribution-ShareAlike 4.0 International](https://creativecommons.org/licenses/by-sa/4.0/)
#
# * **Q&A** - OTR Discord **#Jupyterthon #WORKSHOP DAY 1 - ACQUIRING DATA**
# ---
# # Reading from SIEMs and Databases
#
# ## Elasticsearch
#
# [https://elasticsearch-py.readthedocs.io/](https://elasticsearch-py.readthedocs.io/)
#
# ```
# python -m pip install elasticsearch
# ```
#
# - Importing libraries:
# In[ ]:
# Elasticsearch connector
from elasticsearch import Elasticsearch
from elasticsearch_dsl import Search
# Data manipulation
import pandas as pd
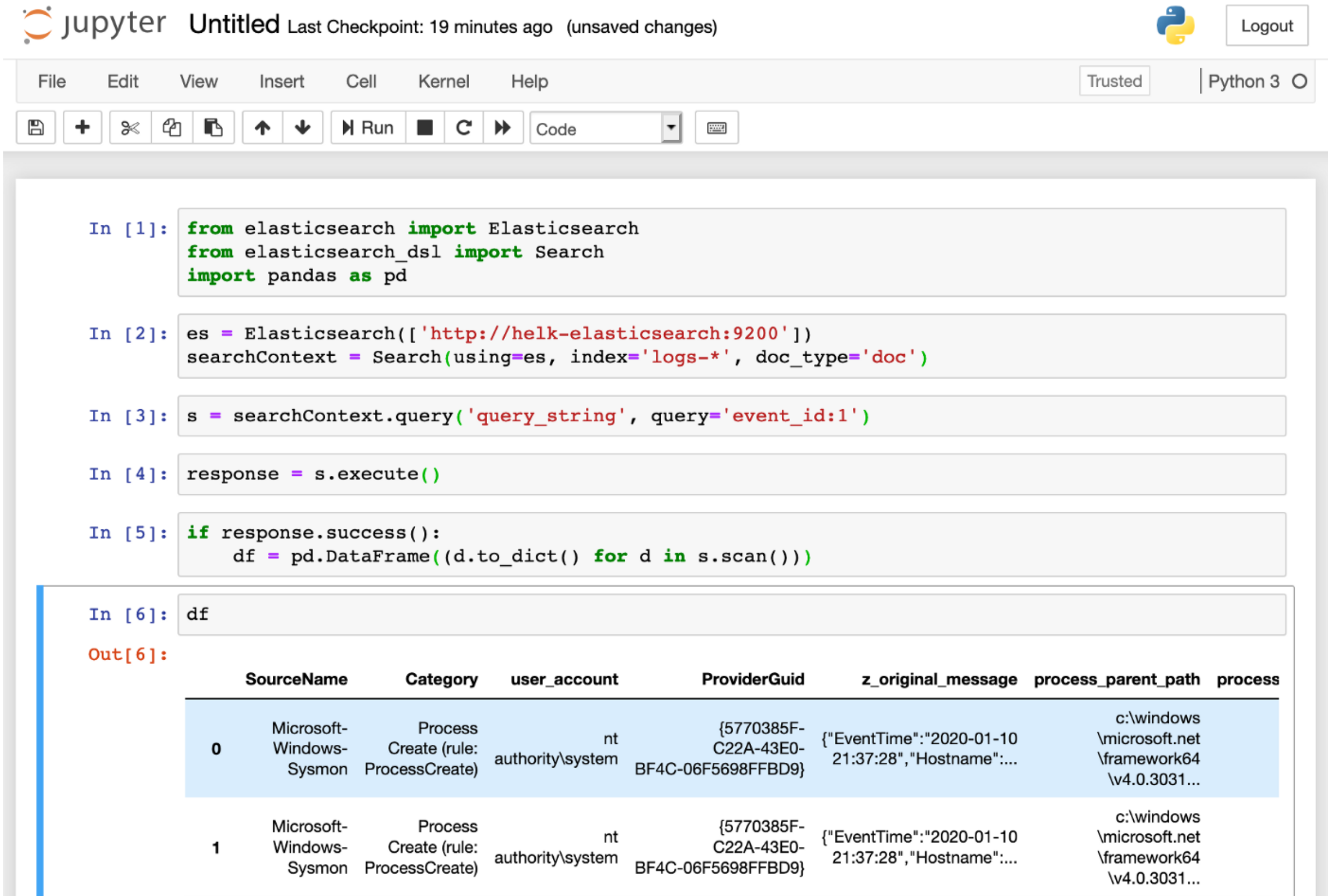
# - Initializing an Elasticsearch client:
#
# Initialize an Elasticsearch client using a specific Elasticsearch URL. Next, you can pass the client to the Search object that we will use to represent the search request in a little bit.
# In[ ]:
es = Elasticsearch(['http://:9200'])
searchContext = Search(using=es, index='logs-*', doc_type='doc')
# - Setting the query search context:
#
# In addition, we will need to use the query class to pass an Elasticsearch query_string . For example, what if I want to query event_id 1 events?.
# In[ ]:
s = searchContext.query('query_string', query='event_id:1')
# - Running query & Exploring response:
#
# Finally, you can run the query and get the results back as a DataFrame.
# In[ ]:
response = s.execute()
if response.success():
df = pd.DataFrame((d.to_dict() for d in s.scan()))
df
# # Connect to Elasticsearch (Elasticsearch DSL Libraries)
#
# 
#
# Reference: https://medium.com/threat-hunters-forge/jupyter-notebooks-from-sigma-rules-%EF%B8%8F-to-query-elasticsearch-31a74cc59b99
# ## Splunk
#
# [Huntlib - https://github.com/target/huntlib](https://github.com/target/huntlib)
#
# Also
#
# [SplunkSDK - https://github.com/splunk/splunk-sdk-python](https://github.com/splunk/splunk-sdk-python)
#
# - Importing libraries:
# In[ ]:
from huntlib.splunk import SplunkDF
# - Running query & Exploring response
# In[ ]:
df = s.search_df(
spl="search index=win_events EventCode=4688",
start_time="-2d@d",
end_time="@d"
)
# ## Sqlite
#
# - Importing libraries:
# In[ ]:
get_ipython().system('pip install ipython-sql')
# - Loading library
# In[1]:
get_ipython().run_cell_magic('capture', '', '%load_ext sql\n')
# - Connecting to database
# In[2]:
get_ipython().run_line_magic('sql', 'sqlite:///../data/browser2.db')
# - Executing queries
# In[3]:
get_ipython().run_cell_magic('sql', '', "SELECT\n name\nFROM\n sqlite_master\nWHERE\n type='table';\n")
# In[4]:
get_ipython().run_cell_magic('sql', '', 'SELECT * FROM history;\n')
# - Save query results in a Pandas DataFrame
# In[5]:
df = _.DataFrame()
# In[6]:
df
# ## Log analytics workspace
#
# **Requirements**:
# * Azure AD application
# * Secret text (credentials)
# * API permissions granted:
# * Service: Log Analytics API
# * Permission: Data.Read
# * Type: AppRole
# * Add application with `Log Analytics Reader` role to Log Analytic Workspace Access Control list.
# **Get OAUTH Access Token**
# * Application ID
# * Scope: https://api.loganalytics.io/.default
# * TenantId
# * Application secret
#
# https://securitydatasets.com/create/azureloganalyticsapi.html
# In[ ]:
import requests
import time
appId = "AppId"
scope = "https://api.loganalytics.io/.default"
tenantId = "TenantID"
secret = 'ApplicationSecret'
endpoint = f'https://login.microsoftonline.com/{tenantId}/oauth2/v2.0/token'
http_headers = {'Accept': 'application/json','Content-Type': 'application/json'}
data = {"scope" : scope, 'grant_type' : 'client_credentials', 'client_id' : appId, 'client_secret' : secret}
results = requests.get(endpoint, json=data, headers=http_headers, stream=False).json()
access_token = results["access_token"]
# **Run Query**
# In[ ]:
workspaceId = 'Workspace ID'
apiUri = f'https://api.loganalytics.io/v1/workspaces/{workspaceId}/query'
query = 'query'
HttpHeaders = {"Authorization" : f'Bearer {access_token}', 'Accept': 'application/json','Content-Type': 'application/json'}
data = {'query' : query}
query_results = requests.get(apiUri, json=data, headers=http_headers, stream=False).json()
# ## M365 advanced hunting APIs
#
# **Requirements**:
# * Azure AD application
# * Secret text (credentials)
# * API permissions granted:
# * Service: Microsoft Threat Protection
# * Permission:
# * AdvancedHunting.Read.All
# * Incident.Read.All
# * Type: AppRole
# **Get OAUTH Access Token**
# * Application ID
# * Scope: https://api.security.microsoft.com/.default
# * TenantId
# * Application secret
#
# https://securitydatasets.com/create/m365defenderhuntapi.html
# ## MSTICPy Data Providers
#
# There's a later session devoted to MSTICPy
#
# ```ipython3
# %pip install msticpy
# ```
#
# MSTICPy isn't a data source - just wraps a bunch of data sources in common API.
#
# Currently supports:
# - MS Sentinel (aka Azure Sentinel, Log Analytics), MS Defender, MS Graph, Azure Resource Graph
# - Splunk
# - Sumologic
# - Local data (CSV or Pickle) - would be easy to add supported pandas formats (any requests?)
# - Experimental support for Kusto/Azure Data explorer
#
# Typical usage:
# - import QueryProvider class
# - instantiate a QueryProvider object with the required provider name.
# - run `query_provider.connect()` method - params vary (e.g. connection string)
# - pre-defined, parameterized queries appear as methods of the query_provider class
# - ad hoc queries via `.exec_query()` method
# - output returned as a pandas dataframe
#
# If you use the MSTICPy init (`init_notebook`), the QueryProvider is imported for you
#
# ```python
# import msticpy
# msticpy.init_notebook(globals())
# ```
#
# In[17]:
# To install
# %pip install msticpy
# Alternative import - init_notebook imports QueryProvider and a bunch of other stuff
# import msticpy
# msticpy.init_notebook(globals())
from msticpy.data import QueryProvider
sentinel_prov = QueryProvider("AzureSentinel")
local_prov = QueryProvider("LocalData", query_paths=["../data"], data_paths=["../data"])
# #### Accessing queries as functions
# (usually need to connect before running one)
# In[ ]:
sentinel_prov.
# In[3]:
sentinel_prov.browse()
# In[19]:
local_prov.Network.list_network_flows().head()
# In[42]:
sentinel_prov.connect(
"loganalytics://code().tenant('72f988bf-86f1-41af-91ab-2d7cd011db47').workspace('8ecf8077-cf51-4820-aadd-14040956f35d')"
)
# ---
# # OTR Security Datasets (aka Mordor)
#
# ## Reading OTR-SecurityDatasets from code
#
# The [Security Datasets project](https://securitydatasets.com/introduction.html) is an open-source initiatve that contributes pre-recorded datasets that describe malicious activity, from different platforms, to the infosec community to expedite data analysis and threat research.
#
# We will consider the following steps to access Security Datasets:
#
# - Importing required Python Libraries
# - Making a HTTP request to GitHub repository
# - Generating ZipFile (Compressed) object from Bytes data
# - Extracting JSON file from ZipFile object
# - Reading JSON file (Lines = True)
#
# - Let's start by importing the required Python libraries in order to access Security Datasets' content:
# In[1]:
# Generate HTTP request
import requests
# Zip file object manipulation
from zipfile import ZipFile
# Byte data manipulations
from io import BytesIO
# Read JSON file
from pandas.io import json
# - We will make a HTTP request to the [Security Datasets GitHub repo](https://github.com/OTRF/Security-Datasets) using the **[get](https://docs.python-requests.org/en/latest/user/quickstart/#make-a-request)** method, and we are storing the reponse content in the variable *zipFileRequest*.
#
# It is important to note that we are using the **raw data link** related to the dataset. This type of links usually starts with **https://raw.githubusercontent.com/** + Project reference.
# In[8]:
url = 'https://raw.githubusercontent.com/OTRF/Security-Datasets/master/datasets/atomic/windows/discovery/host/empire_shell_net_localgroup_administrators.zip'
zipFileRequest = requests.get(url)
type(zipFileRequest)
# - The type of data of the content of HTTP repsonse is **[Bytes](https://docs.python.org/3/library/stdtypes.html#bytes)**.
# In[4]:
type(zipFileRequest.content)
# - We will create a **[BytesIO](https://docs.python.org/3/library/io.html#io.BytesIO)** object to access the response content and store it in a **[ZipFile](https://docs.python.org/3/library/zipfile.html#zipfile-objects)** object. All the data manipulation is performed in memory.
# In[7]:
zipFile = ZipFile(BytesIO(zipFileRequest.content))
type(zipFile)
# - Any ZipFile object can contain more than one file. We can access the list of files' names using the **[namelist](https://docs.python.org/3/library/zipfile.html#zipfile.ZipFile.namelist)** method. Since the Security Datasets contains one file, we will reference the first element of the list when extracting the JSON file.
# In[9]:
zipFile.namelist()
# - We will extract the JSON file from the compressed folder using the **[extract](https://docs.python.org/3/library/zipfile.html#zipfile.ZipFile.extract)** method. After running the code below, we will download and store the file in the directory specified in the *path* parameter.
#
# It is important to note that this method returns the normalized path to the JSON file. We are storing the directory path in the *datasetJSONPAth* variable and use it when trying to read the file.
# In[10]:
datasetJSONPath = zipFile.extract(zipFile.namelist()[0], path = '../data')
print(datasetJSONPath)
# - Now that the file was downloaded and know its direcotry path, we can read the JSON file using the **[read_json](https://pandas.pydata.org/docs/reference/api/pandas.io.json.read_json.html)** method.
#
# It is important to note that, when recording Security Dataset, each line of the JSON file represents an event. Therefore, it is important to set the parameter **lines** to *True*.
# In[11]:
dataset = json.read_json(path_or_buf = datasetJSONPath, lines=True)
# - The **read_json** method returns a **DataFrame** object. We will share more details of what a dataframe is in the next section of this workshop.
# In[12]:
type(dataset)
# - Finally, we should be able to start exploring our dataset using different functions or method such as [head](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.head.html).
# In[13]:
dataset.head(n=1)
# ## Using MSTICPy to access Security Datasets
#
# In[21]:
#%pip install msticpy
import pandas as pd
from msticpy.data import QueryProvider
from msticpy.vis import mp_pandas_plot
qry_prov_sd = QueryProvider("Mordor")
# In[22]:
qry_prov_sd.connect()
# In[24]:
qry_prov_sd.list_queries()[:10]
# In[25]:
qry_prov_sd.search_queries("empire + localgroup")
#
# In[27]:
emp_df = qry_prov_sd.atomic.windows.discovery.host.empire_shell_net_localgroup_administrators()
emp_df.head()
# Make sure that timestamps actually are timestamps, not strings
# In[29]:
emp_df["EventTime"] = pd.to_datetime(emp_df["EventTime"])
# In[30]:
emp_df.mp_plot.timeline(time_column="EventTime", group_by="EventID")
# ### Security Datasets Browser
#
# - Browser properties
# - Filter by MITRE Tactic/Technique
# - Search across metadata, file names
# - Download selected datasets
# In[31]:
from msticpy.data.browsers.mordor_browser import MordorBrowser
m_browser = MordorBrowser()
# ### Downloaded data available in `browser.current_dataset`
# In[32]:
m_browser.current_dataset.head(3)
# ### Cached datasets available in `browser.datasets`
# In[33]:
m_browser.datasets
# ---
# # End of Session
# # Break: 5 Minutes
#
# 