#!/usr/bin/env python
# coding: utf-8
# Table of Contents
#
# # Model Training with Aerospike Feature Store
# This notebook is the second in the series of notebooks that show how Aerospike can be used as a feature store.
#
# This notebook requires the Aerospike Database and Spark running locally with Aerospike Spark Connector. To create a Docker container that satisfies the requirements and holds a copy of Aerospike notebooks, visit the [Aerospike Notebooks Repo](https://github.com/aerospike-examples/interactive-notebooks).
# ## Introduction
# This notebook shows how Aerospike can be used as a Feature Store for Machine Learning applications on Spark using Aerospike Spark Connector. It is Part 2 of the Feature Store series of notebooks, and focuses on Model Training aspects concerning a Feature Store. The [first notebook](feature-store-feature-eng.ipynb) in the series discusses Feature Engineering, and [the next one](feature-store-model-serving.ipynb) describes Model Serving.
# 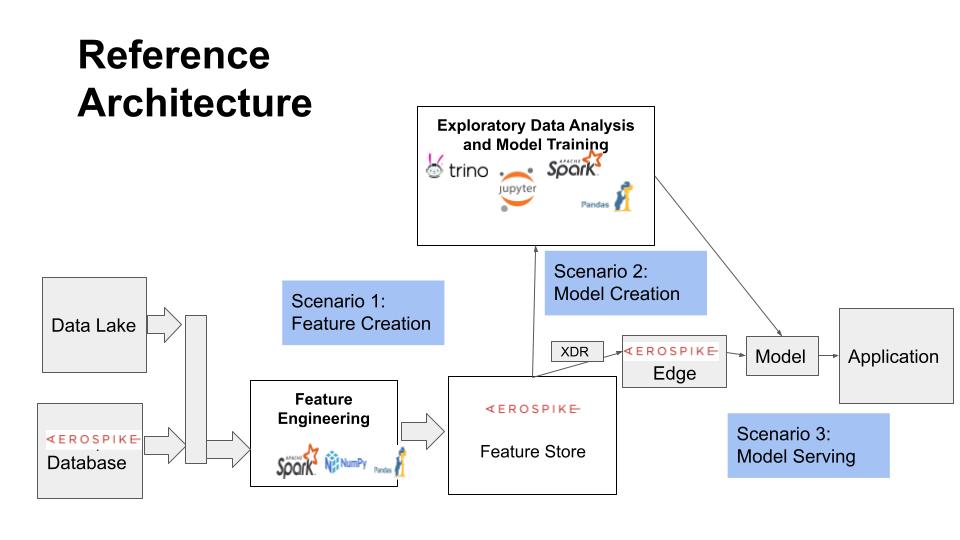
# This notebook is organized as follows:
# - Summary of the prior (Data Engineering) notebook
# - Exploring features and datasets
# - Defining and saving a dataset
# - Training and saving an AI/ML model
# ## Prerequisites
# This tutorial assumes familiarity with the following topics:
#
# - [Aerospike Notebooks - Readme and Tips](../readme_tips.ipynb)
# - [Hello World](../python/hello_world.ipynb)
# - [Aerospike Connect for Spark Tutorial for Python](AerospikeSparkPython.ipynb)
# ## Setup
# Set up Aerospike Server. Spark Server, and Spark Connector.
# ### Ensure Database Is Running
# This notebook requires that Aerospike datbase is running.
# In[1]:
get_ipython().system('asd >& /dev/null')
get_ipython().system('pgrep -x asd >/dev/null && echo "Aerospike database is running!" || echo "**Aerospike database is not running!**"')
# ### Initialize Spark
# We will be using Spark functionality in this notebook.
# #### Initialize Paths and Env Variables
# In[2]:
# directory where spark notebook requisites are installed
SPARK_NB_DIR = '/opt/spark-nb'
SPARK_DIR = 'spark-dir-link'
SPARK_HOME = SPARK_NB_DIR + '/' + SPARK_DIR
AEROSPIKE_JAR = 'aerospike-jar-link'
AEROSPIKE_JAR_PATH = SPARK_NB_DIR + '/' + AEROSPIKE_JAR
# In[3]:
# IP Address or DNS name for one host in your Aerospike cluster
AS_HOST ="localhost"
# Name of one of your namespaces. Type 'show namespaces' at the aql prompt if you are not sure
AS_NAMESPACE = "test"
AS_PORT = 3000 # Usually 3000, but change here if not
AS_CONNECTION_STRING = AS_HOST + ":"+ str(AS_PORT)
# In[4]:
# Locate the Spark installation using the SPARK_HOME parameter.
import findspark
findspark.init(SPARK_HOME)
# In[5]:
# Specify the Aerospike Spark Connector jar in the command used to interact with Aerospike.
import os
os.environ["PYSPARK_SUBMIT_ARGS"] = '--jars ' + AEROSPIKE_JAR_PATH + ' pyspark-shell'
# #### Configure Spark Session
# Please visit [Configuring Aerospike Connect for Spark](https://docs.aerospike.com/docs/connect/processing/spark/configuration.html) for more information about the properties used on this page.
# In[6]:
# imports
import pyspark
from pyspark.context import SparkContext
from pyspark.sql.context import SQLContext
from pyspark.sql.session import SparkSession
from pyspark.sql.types import StringType, StructField, StructType, ArrayType, IntegerType, MapType, LongType, DoubleType
# In[7]:
sc = SparkContext.getOrCreate()
conf=sc._conf.setAll([("aerospike.namespace",AS_NAMESPACE),("aerospike.seedhost",AS_CONNECTION_STRING)])
sc.stop()
sc = pyspark.SparkContext(conf=conf)
spark = SparkSession(sc)
sqlContext = SQLContext(sc)
# ### Access Shell Commands
# You may execute shell commands including Aerospike tools like [aql](https://docs.aerospike.com/docs/tools/aql/index.html) and [asadm](https://docs.aerospike.com/docs/tools/asadm/index.html) in the terminal tab throughout this tutorial. Open a terminal tab by selecting File->Open from the notebook menu, and then New->Terminal.
# # Context from Part 1 (Feature Engineering Notebook)
#
# In the [previous notebook](feature-store-feature-eng.ipynb) in the Feature Store series, we showed how features engineered using the Spark platform can be efficiently stored in Aerospike feature store. We implemented a simple example feature store interface that leverages the Aerospike Spark connector capabilities for this purpose. We implementd a simple object model to save and query features, and illustrated its use with two examples.
#
# You are encouraged to review the Feature Engineering notebook as we will use the same object model, implementation (with some extensions), and data in this notebook.
#
# The code from Part 1 is replicated below as we will be using it later.
# ## Code: Feature Group, Feature, and Entity
# Below, we have copied over the code for Feature Group, Feature, and Entity classes for use in the following sections. Please review the object model described in the Feature Engineering notebook.
# In[8]:
import copy
# Feature Group
class FeatureGroup:
schema = StructType([StructField("name", StringType(), False),
StructField("description", StringType(), True),
StructField("source", StringType(), True),
StructField("attrs", MapType(StringType(), StringType()), True),
StructField("tags", ArrayType(StringType()), True)])
def __init__(self, name, description, source, attrs, tags):
self.name = name
self.description = description
self.source = source
self.attrs = attrs
self.tags = tags
return
def __str__(self):
return str(self.__class__) + ": " + str(self.__dict__)
def save(self):
inputBuf = [(self.name, self.description, self.source, self.attrs, self.tags)]
inputRDD = spark.sparkContext.parallelize(inputBuf)
inputDF = spark.createDataFrame(inputRDD, FeatureGroup.schema)
#Write the data frame to Aerospike, the name field is used as the primary key
inputDF.write \
.mode('overwrite') \
.format("aerospike") \
.option("aerospike.writeset", "fg-metadata")\
.option("aerospike.updateByKey", "name") \
.save()
return
def load(name):
fg = None
schema = copy.deepcopy(FeatureGroup.schema)
schema.add("__key", StringType(), False)
fgdf = spark.read \
.format("aerospike") \
.option("aerospike.set", "fg-metadata") \
.schema(schema) \
.load().where("__key = \"" + name + "\"")
if fgdf.count() > 0:
fgtuple = fgdf.collect()[0]
fg = FeatureGroup(*fgtuple[:-1])
return fg
def query(predicate): #returns a dataframe
fg_df = spark.read \
.format("aerospike") \
.schema(FeatureGroup.schema) \
.option("aerospike.set", "fg-metadata") \
.load().where(predicate)
return fg_df
# Feature
class Feature:
schema = StructType([StructField("fid", StringType(), False),
StructField("fgname", StringType(), False),
StructField("name", StringType(), False),
StructField("type", StringType(), False),
StructField("description", StringType(), True),
StructField("attrs", MapType(StringType(), StringType()), True),
StructField("tags", ArrayType(StringType()), True)])
def __init__(self, fgname, name, ftype, description, attrs, tags):
self.fid = fgname + '_' + name
self.fgname = fgname
self.name = name
self.ftype = ftype
self.description = description
self.attrs = attrs
self.tags = tags
return
def __str__(self):
return str(self.__class__) + ": " + str(self.__dict__)
def save(self):
inputBuf = [(self.fid, self.fgname, self.name, self.ftype, self.description, self.attrs, self.tags)]
inputRDD = spark.sparkContext.parallelize(inputBuf)
inputDF = spark.createDataFrame(inputRDD, Feature.schema)
# Write the data frame to Aerospike, the fid field is used as the primary key
inputDF.write \
.mode('overwrite') \
.format("aerospike") \
.option("aerospike.writeset", "feature-metadata")\
.option("aerospike.updateByKey", "fid") \
.save()
return
def load(fgname, name):
f = None
schema = copy.deepcopy(Feature.schema)
schema.add("__key", StringType(), False)
f_df = spark.read \
.format("aerospike") \
.schema(schema) \
.option("aerospike.set", "feature-metadata") \
.load().where("__key = \"" + fgname+'_'+name + "\"")
if f_df.count() > 0:
f_tuple = f_df.collect()[0]
f = Feature(*f_tuple[1:-1])
return f
def query(predicate, pushdown_expr=None): #returns a dataframe
f_df = spark.read \
.format("aerospike") \
.schema(Feature.schema) \
.option("aerospike.set", "feature-metadata")
# see the section on pushdown expressions
if pushdown_expr:
f_df = f_df.option("aerospike.pushdown.expressions", pushdown_expr) \
.load()
else:
f_df = f_df.load().where(predicate)
return f_df
# Entity
class Entity:
def __init__(self, etype, record, id_col):
# record is an array of triples (name, type, value)
self.etype = etype
self.record = record
self.id_col = id_col
return
def __str__(self):
return str(self.__class__) + ": " + str(self.__dict__)
def get_schema(record):
schema = StructType()
for f in record:
schema.add(f[0], f[1], True)
return schema
def get_id_type(schema, id_col):
return schema[id_col].dataType.typeName()
def save(self, schema):
fvalues = [f[2] for f in self.record]
inputBuf = [tuple(fvalues)]
inputRDD = spark.sparkContext.parallelize(inputBuf)
inputDF = spark.createDataFrame(inputRDD, schema)
#Write the data frame to Aerospike, the id_col field is used as the primary key
inputDF.write \
.mode('overwrite') \
.format("aerospike") \
.option("aerospike.writeset", self.etype+'-features')\
.option("aerospike.updateByKey", self.id_col) \
.save()
return
def load(etype, eid, schema, id_col):
ent = None
schema = copy.deepcopy(schema)
schema.add("__key", StringType(), False)
ent_df = spark.read \
.format("aerospike") \
.schema(schema) \
.option("aerospike.set", etype+'-features') \
.load().where("__key = \"" + eid + "\"")
if ent_df.count() > 0:
ent_tuple = ent_df.collect()[0]
record = [(schema[i].name, schema[i].dataType.typeName(), fv) for i, fv in enumerate(ent_tuple[:-1])]
ent = Entity(etype, record, id_col)
return ent
def saveDF(df, etype, id_col): # save a dataframe
# df: dataframe consisting of entiry records
# etype: entity type (such as user or sensor)
# id_col: column name that holds the primary key
#Write the data frame to Aerospike, the column in id_col is used as the key bin
df.write \
.mode('overwrite') \
.format("aerospike") \
.option("aerospike.writeset", etype+'-features')\
.option("aerospike.updateByKey", id_col) \
.save()
return
def query(etype, predicate, schema, id_col): #returns a dataframe
ent_df = spark.read \
.format("aerospike") \
.schema(schema) \
.option("aerospike.set", etype+'-features') \
.load().where(predicate)
return ent_df
def get_feature_vector(etype, eid, feature_list): # elements in feature_list are in "fgname_name" form
# deferred to Model Serving tutorial
pass
# In[9]:
# clear the database by truncating the namespace test
get_ipython().system('aql -c "truncate test"')
# Create set indexes on all sets.
# In[10]:
get_ipython().system('asinfo -v "set-config:context=namespace;id=test;set=fg-metadata;enable-index=true"')
get_ipython().system('asinfo -v "set-config:context=namespace;id=test;set=feature-metadata;enable-index=true"')
get_ipython().system('asinfo -v "set-config:context=namespace;id=test;set=dataset-metadata;enable-index=true"')
#!asinfo -v "set-config:context=namespace;id=test;set=cctxn-features;enable-index=true"
# In[11]:
# test feature group
# test save and load
# save
fg1 = FeatureGroup("fg_name1", "fg_desc1", "fg_source1", {"etype":"etype1", "key":"feature1"}, ["tag1", "tag2"])
fg1.save()
# load
fg2 = FeatureGroup.load("fg_name1")
print("Feature group with name fg_name1:")
print(fg2, '\n')
# test query
fg2 = FeatureGroup("fg_name2", "fg_desc2", "fg_source2", {"etype":"etype1", "key":"fname1"}, ["tag1", "tag3"])
fg2.save()
fg3 = FeatureGroup("fg_name3", "fg_desc3", "fg_source3", {"etype":"etype2", "key":"fname3"}, ["tag4", "tag5"])
fg3.save()
# query 1
print("Feature groups with a description containing 'desc':")
fg_df = FeatureGroup.query("description like '%desc%'")
fg_df.show()
# query 2
print("Feature groups with the source 'fg_source2':")
fg_df = FeatureGroup.query("source = 'fg_source2'")
fg_df.show()
# query 3
print("Feature groups with the attribute 'etype'='etype2':")
fg_df = FeatureGroup.query("attrs.etype = 'etype2'")
fg_df.show()
# query 4
print("Feature groups with a tag 'tag1':")
fg_df = FeatureGroup.query("array_contains(tags, 'tag1')")
fg_df.show()
# In[12]:
# test feature
# test save and load
# save
feature1 = Feature("fgname1", "f_name1", "integer", "f_desc1", {"etype":"etype1", "f_attr1":"v1"},
["f_tag1", "f_tag2"])
feature1.save()
# load
f1 = Feature.load("fgname1", "f_name1")
print("Feature with group 'fgname1' and name 'f_name1:")
print(f1, '\n')
# test query
feature2 = Feature("fgname1", "f_name2", "double", "f_desc2", {"etype":"etype1", "f_attr1":"v2"},
["f_tag1", "f_tag3"])
feature2.save()
feature3 = Feature("fgname2", "f_name3", "double", "f_desc3", {"etype":"etype2", "f_attr2":"v3"},
["f_tag2", "f_tag4"])
feature3.save()
# query 1
print("Features in feature group 'fg_name1':")
f_df = Feature.query("fgname = 'fgname1'")
f_df.show()
# query 2
print("Features of type 'integer':")
f_df = Feature.query("type = 'integer'")
f_df.show()
# query 3
print("Features with the attribute 'etype'='etype1':")
f_df = Feature.query("attrs.etype = 'etype1'")
f_df.show()
# query 3
print("Features with the tag 'f_tag2':")
f_df = Feature.query("array_contains(tags, 'f_tag2')")
f_df.show()
# In[13]:
# test Entity
# test save and load
# save
features1 = [('fg1_f_name1', IntegerType(), 1), ('fg1_f_name2', DoubleType(), 2.0), ('fg1_f_name3', StringType(), 'three')]
record1 = [('eid', StringType(), 'eid1')] + features1
ent1 = Entity('entity_type1', record1, 'eid')
schema = Entity.get_schema(record1)
ent1.save(schema);
# load
e1 = Entity.load('entity_type1', 'eid1', schema, 'eid')
print("Entity of type 'entity_type1' and id 'eid1':")
print(e1, '\n')
# test query
features2 = [('fg1_f_name1', IntegerType(), 10), ('fg1_f_name2', DoubleType(), 20.0), ('fg1_f_name3', StringType(), 'thirty')]
record2 = [('eid', StringType(), 'eid2')] + features2
ent2 = Entity('entity_type2', record2, 'eid')
ent2.save(schema);
# query 1
print("Instances of entity type entity_type1 with id ending in 1:")
instances = Entity.query('entity_type1', 'eid like "%1"', schema, 'eid')
instances.show()
# query 2
print("Instances of entity type entity_type2 meeting the specified condition:")
instances = Entity.query('entity_type2', 'eid in ("eid2")', schema, 'eid')
instances.show()
# ## Feature Data: Credit Card Transactions
# The following cell populates the data from Part 1 in the database for use below.
# ### Read and Transform Data
# In[14]:
# read and transform the sample credit card transactions data from a csv file
from pyspark.sql.functions import expr
df = spark.read.options(header="True", inferSchema="True") \
.csv("resources/creditcard_small.csv") \
. orderBy(['_c0'], ascending=[True])
new_col_names = ['CC1_' + (c if c != '_c0' else 'OldIdx') for c in df.columns]
df = df.toDF(*new_col_names) \
.withColumn('TxnId', expr('CC1_OldIdx+1').cast(StringType())) \
.select(['TxnId','CC1_Class','CC1_Amount']+['CC1_V'+str(i) for i in range(1,29)])
df.toPandas().head()
# ### Save Features
# Insert the credit card transaction features in the feature store.
# In[15]:
# 1. Create a feature group.
FG_NAME = 'CC1'
FG_DESCRIPTION = 'Credit card transaction data'
FG_SOURCE = 'European cardholder dataset from Kaggle'
fg = FeatureGroup(FG_NAME, FG_DESCRIPTION, FG_SOURCE,
attrs={'entity':'cctxn', 'class':'fraud'}, tags=['kaggle', 'demo'])
fg.save()
# 2. Create feature metadata
FEATURE_AMOUNT = 'Amount'
f = Feature(FG_NAME, FEATURE_AMOUNT, 'double', "Transaction amount",
attrs={'entity':'cctxn'}, tags=['usd'])
f.save()
FEATURE_CLASS = 'Class'
f = Feature(FG_NAME, FEATURE_CLASS, 'integer', "Label indicating fraud or not",
attrs={'entity':'cctxn'}, tags=['label'])
f.save()
FEATURE_PCA_XFORM = "V"
for i in range(1,29):
f = Feature(FG_NAME, FEATURE_PCA_XFORM+str(i), 'double', "Transformed version of PCA",
attrs={'entity':'cctxn'}, tags=['pca'])
f.save()
# 3. Save feature values in entity records
ENTITY_TYPE = 'cctxn'
ID_COLUMN = 'TxnId'
Entity.saveDF(df, ENTITY_TYPE, ID_COLUMN)
print('Features stored to Feature Store.')
# # Implementing Dataset
# We created example implementations of Feature Group, Feature, and Entity objects as above. Let us now create a similar implementation of Dataset.
#
# ## Object Model
# A dataset is a subset of features and entities selected for an ML model. A Dataset object holds the selected features and entity instances. The actual (materialized) copy of entity records is stored outside the feature store (for instance, in a file system).
#
# ### Attributes
# A dataset record has the following attributes.
#
# - name: name of the data set, serves as the primary key for the record
# - description: human readable description
# - features: a list of the dataset features
# - predicate: query predicate to enumerate the entity instances in the dataset
# - location: external location where the dataset is stored
# - attrs: other metadata
# - tags: associated tags
#
# Datasets are stored in the set "dataset-metadata".
#
# ### Operations
# Dataset is used during Model Training. The following operations are needed.
#
# - create
# - load (get)
# - query (returns dataset metadata records)
# - materialize (returns entity records as defined by a dataset)
# ## Dataset Implementation
# Below is an example implementation of Dataset as described above.
# In[16]:
# Dataset
class Dataset:
schema = StructType([StructField("name", StringType(), False),
StructField("description", StringType(), True),
StructField("entity", StringType(), False),
StructField("id_col", StringType(), False),
StructField("id_type", StringType(), False),
StructField("features", ArrayType(StringType()), True),
StructField("query", StringType(), True),
StructField("location", StringType(), True),
StructField("attrs", MapType(StringType(), StringType()), True),
StructField("tags", ArrayType(StringType()), True)])
def __init__(self, name, description, entity, id_col, id_type,
features, query, location, attrs, tags):
self.name = name
self.description = description
self.entity = entity
self.id_col = id_col
self.id_type = id_type
self.features = features
self.query = query
self.location = location
self.attrs = attrs
self.tags = tags
return
def __str__(self):
return str(self.__class__) + ": " + str(self.__dict__)
def save(self):
inputBuf = [(self.name, self.description, self.entity, self.id_col, self.id_type,
self.features, self.query, self.location, self.attrs, self.tags)]
inputRDD = spark.sparkContext.parallelize(inputBuf)
inputDF = spark.createDataFrame(inputRDD, Dataset.schema)
#Write the data frame to Aerospike, the name field is used as the primary key
inputDF.write \
.mode('overwrite') \
.format("aerospike") \
.option("aerospike.writeset", "dataset-metadata")\
.option("aerospike.updateByKey", "name") \
.save()
return
def load(name):
dataset = None
ds_df = spark.read \
.format("aerospike") \
.option("aerospike.set", "dataset-metadata") \
.schema(Dataset.schema) \
.option("aerospike.updateByKey", "name") \
.load().where("name = \"" + name + "\"")
if ds_df.count() > 0:
dstuple = ds_df.collect()[0]
dataset = Dataset(*dstuple)
return dataset
def query(predicate): #returns a dataframe
ds_df = spark.read \
.format("aerospike") \
.schema(Dataset.schema) \
.option("aerospike.set", "dataset-metadata") \
.load().where(predicate)
return ds_df
def features_to_schema(entity, id_col, id_type, features):
def convert_field_type(ftype):
return DoubleType() if ftype == 'double' \
else (IntegerType() if ftype in ['integer','long'] \
else StringType())
schema = StructType()
schema.add(id_col, convert_field_type(id_type), False)
for fid in features:
sep = fid.find('_')
f = Feature.load(fid[:sep] if sep != -1 else "", fid[sep+1:])
if f:
schema.add(f.fid, convert_field_type(f.ftype), True)
return schema
def materialize_to_df(self):
df = Entity.query(self.entity, self.query,
Dataset.features_to_schema(self.entity, self.id_col, self.id_type,
self.features), self.id_col)
return df
# In[17]:
# test Dataset
# test save and load
# save
features = ["CC1_Amount", "CC1_Class", "CC1_V1"]
ds = Dataset("ds_test1", "Test dataset", "cctxn", "TxnId", "string",
features, "CC1_Amount > 1500", "", {"risk":"high"}, ["test", "dataset"])
ds.save()
# load
ds = Dataset.load("ds_test1")
print("Dataset named 'ds_test1':")
print(ds, '\n')
# test query
print("Datasets with attribute 'risk'='high' and tag 'test':")
dsq_df = Dataset.query("attrs.risk == 'high' and array_contains(tags, 'test')")
dsq_df.show()
# test materialize_to_df
print("Materialize dataset ds_test1 as defined above:")
ds_df = ds.materialize_to_df()
print("Records in the dataset: ", ds_df.count())
ds_df.show(5)
# # Using Pushdown Expressions
# In order to get best performance from the Aerospike feature store, one important optimization is to "push down" processing to the database and minimize the amount of data retrieved to Spark. This is especially important for querying from large amounts of underlying data, such as when creating a dataset. This is achieved by "pushing down" filters or processing filters in the database.
#
# Currently the Spark Connector allows two mutually exclusive ways of specifying filters in a dataframe load:
# 1. The `where` clause
# 2. The `pushdown expressions` option
#
# Only one may be specified because the underlying Aerospike database mechanisms used to process them are different and exclusive. The latter takes prcedence if both are specified.
#
# The `where` clause filter may be pushed down in part or fully depending on the parts in the filter (that is, if the database supports them and the Spark Connector takes advantage of it). The `pushdown expression` filter however is fully processed in the database, which ensures best performance.
#
# Aerospike expressions provide some filtering capabilities that are either not available on Spark (such as record metadata based filtering). Also, expression based filtering will be processed more efficiently in the database. On the other hand, the `where` clause also has many capabilities that are not available in Aerospike expressions. So it may be necessary to use both, in which case it is best to use pushdown expressions to retrieve a dataframe, and then process it using the Spark dataframe capabilities.
# ## Creating Pushdown Expressions
# The Spark Connector currently requires the base64 encoding of the expression. Exporting the base64 encoded expression currently requires the Java client, which can be run in a parallel notebook) and entails the following steps:
# 1. Write the expression in Java.
# 2. Test the expression with the desired data.
# 3. Obtain the base64 encoding.
# 4. Use the base64 representation in this notebook as shown below.
#
# You can run the adjunct notebook [Pushdown Expressions for Spark Connector](resources/pushdown-expressions.ipynb) to follow the above recipe and obtain the base64 representation of an expression for use in the following examples.
# ## Examples
# We illustrate pushdown expressions with `Feature` class queries, but the `query` method implementation can be adopted in other objects.
#
# The examples below illustrate the capabilities and process of working with pushdown expressions. More details on expressions are explained in [Understanding Expressions in Aerospike](../java/expressions.ipynb) notebook.
#
# ### Records with Specific Tags
# Examine the expression in Java:
# ```
# Exp.gt(
# ListExp.getByValueList(ListReturnType.COUNT,
# Exp.val(new ArrayList(Arrays.asList("label","f_tag1"))),
# Exp.listBin("tags")),
# Exp.val(0))
# ```
# The outer expression compares for the value returned from the first argument to be greater than 0. The first argument is the count of matching tags from the specified tags in the list bin `tags`.
#
# Obtain the base64 representation from [Understanding Expressions in Aerospike](../java/expressions.ipynb) notebook. It is "kwOVfwIAkxcFkn6SpgNsYWJlbKcDZl90YWcxk1EEpHRhZ3MA"
# In[18]:
base64_expr = "kwOVfwIAkxcFkn6SpgNsYWJlbKcDZl90YWcxk1EEpHRhZ3MA"
f_df = Feature.query(None, pushdown_expr=base64_expr)
f_df.toPandas()
# ### Records with Specific Attribute Value
# Examine the expression in Java:
# ```
# MapExp.getByKey(MapReturnType.VALUE,
# Exp.Type.STRING, Exp.val("f_attr1"), Exp.mapBin("attrs")),
# Exp.val("v1"))
# ```
# It would filter records having a key "f_attr1" with value "v1" from the map bin `attrs`.
#
# Obtain the base64 representation from [Understanding Expressions in Aerospike](../java/expressions.ipynb) notebook. It is "kwGVfwMAk2EHqANmX2F0dHIxk1EFpWF0dHJzowN2MQ==".
# In[19]:
base64_expr = "kwGVfwMAk2EHqANmX2F0dHIxk1EFpWF0dHJzowN2MQ=="
f_df = Feature.query(None, pushdown_expr=base64_expr)
f_df.toPandas()
# ### Records with String Matching Pattern
# Examine the expression in Java:
# ```
# Exp.regexCompare("^c.*2$", RegexFlag.ICASE, Exp.stringBin("fid"))
# ```
# It would filter records with fid starting with "c" and ending in "2" (case insensitive).
#
# Obtain the base64 representation from [Understanding Expressions in Aerospike](../java/expressions.ipynb) notebook. It is "lAcCpl5DLioyJJNRA6NmaWQ=".
# In[20]:
base64_expr = "lAcCpl5DLioyJJNRA6NmaWQ="
f_df = Feature.query(None, pushdown_expr=base64_expr)
f_df.toPandas()
# # Exploring Features in Feature Store
# Now let's explore the features available in the Feature Store prior to using them to train a model. We will illustrate this with the querying functions on the metadata objects we have implemented above, as well as Spark functions.
## Exploring Datasets
As we are interested in building a fraud detection model, let's see if there are any existing datasets that have "fraud' in their description. At present there should be no datasets in the database until we create and save one in later sections.
# In[21]:
ds_df = Dataset.query("description like '%fraud%'")
ds_df.show()
# ## Exploring Feature Groups
# Let's identify feature groups for the entity type "cctxn" (credit card transactions) that have an attribute "class"="fraud"
#
# In[22]:
fg_df = FeatureGroup.query("attrs.entity == 'cctxn' and attrs.class == 'fraud'")
fg_df.toPandas().transpose().head()
# In[23]:
# View all available features in this feature group
f_df = Feature.query("fgname == 'CC1'")
f_df.toPandas()
# The features look promising for a fraud prediction model. Let's look at the actual feature data and its characteristics by querying the entity records.
# ## Exploring Feature Data
# We can further explore the feature data to determine what features should be part of the dataset. The feature data resides in Entity records and we can use the above info to form the schema and retrieve the records.
# ### Defining Schema
# In order to query using the Aerospike Spark Conntector, we must define the schema
# for the record.
# In[24]:
# define the schema for the record.
FG_NAME = 'CC1'
ENTITY_TYPE = 'cctxn'
ID_COLUMN = 'TxnId'
FEATURE_AMOUNT = 'Amount'
FEATURE_CLASS = 'Class'
FEATURE_PCA_XFORM = "V"
schema = StructType([StructField(ID_COLUMN, StringType(), False),
StructField(FG_NAME+'_'+FEATURE_CLASS, IntegerType(), False),
StructField(FG_NAME+'_'+FEATURE_AMOUNT, DoubleType(), False)])
for i in range(1,29):
schema.add(FG_NAME+'_'+FEATURE_PCA_XFORM+str(i), DoubleType(), True)
# ### Retrieving Data
# Here we get all records from the sample data in the database. A small subset of the data would suffice in practice.
# In[25]:
## let's get the entity records to assess the data
txn_df = Entity.query(ENTITY_TYPE, "TxnId like '%'", schema, "TxnId")
print("Records retrieved: ", txn_df.count())
txn_df.printSchema()
# ### Examining Data
# We will examine the statistical properties as well as null values of the feature columns. Note, the column CC1_Class is the label (fraud or not).
# In[26]:
# examine the statistical properties
txn_df.describe().toPandas().transpose()
# In[27]:
# check for null values
from pyspark.sql.functions import count, when, isnan
txn_df.select([count(when(isnan(c), c)).alias(c) for c in txn_df.columns]).toPandas().head()
# # Defining Dataset
# Based on the above exploration, we will choose features V1-V28 for our training dataset, which we will define below.
#
# In addition to the features, we also need to choose the data records for the dataset. We only have a small data from the original dataset, and therefore we will use all the available records by setting the dataset query predicate to "true".
#
# It is possible to create a random dataset of random records by performing an "aerolookup" of randomly selected key values.
# In[28]:
# Create a dataset with the V1-V28 features.
CC_FRAUD_DATASET = "CC_FRAUD_DETECTION"
features = ["CC1_V"+str(i) for i in range(1,29)]
features_and_label = ["CC1_Class"] + features
ds = Dataset(CC_FRAUD_DATASET, "Training dataset for fraud detection model", "cctxn", "TxnId", "string",
features_and_label, "true", "", {"class":"fraud"}, ["test", "2017"])
ds_df = ds.materialize_to_df()
print("Records in the dataset: ", ds_df.count())
# ## Save Dataset
# Save the dataset in Feature Store for future use.
# In[29]:
# save the materialized dataset externally in a file
DATASET_PATH = 'resources/fs_part2_dataset_cctxn.csv'
ds_df.write.csv(path=DATASET_PATH, header="true", mode="overwrite", sep="\t")
# save the dataset metadata in the feature store
ds.location = DATASET_PATH
ds.save()
# ## Query and Verify Dataset
# Verify the saved dataset is in the feature store for future exploration and use.
# In[30]:
dsq_df = Dataset.query("description like '%fraud%'")
dsq_df.toPandas().transpose()
# Verify the database through an AQL query on the set "dataset-metadata".
# In[31]:
get_ipython().system('aql -c "select * from test.dataset-metadata"')
# # Create AI/ML Model
# Below we will choose two algorithms to predict fraud in a credit card transcation: LogisticRegression and RandomForestClassifier.
# ## Create Training and Test Sets
# We first split the dataset into training and test sets to train and evaluate a model.
# In[32]:
from pyspark.ml.feature import VectorAssembler
# create a feature vector from features
assembler = VectorAssembler(inputCols=features, outputCol="fvector")
ds_df2 = assembler.transform(ds_df)
# split the dataset into randomly selected training and test sets
train, test = ds_df2.randomSplit([0.8,0.2], seed=2021)
print('Training dataset records:', train.count())
print('Test dataset records:', test.count())
# In[33]:
# examine the fraud cases in the training set
train.groupby('CC1_Class').count().show()
# ## Train Model
# We choose two models to train: LogisticRegression and RandomForestClassifier.
# In[34]:
from pyspark.ml.classification import LogisticRegression, RandomForestClassifier
lr_algo = LogisticRegression(featuresCol='fvector', labelCol='CC1_Class', maxIter=5)
lr_model = lr_algo.fit(train)
rf_algo = RandomForestClassifier(featuresCol='fvector', labelCol='CC1_Class')
rf_model = rf_algo.fit(train)
# ## Evaluate Model
# Run the trained models on the test set and evaluate their performacne metrics.
# In[35]:
from pyspark.mllib.evaluation import BinaryClassificationMetrics
from pyspark.ml.evaluation import BinaryClassificationEvaluator
# rename label column
test = test.withColumnRenamed('CC1_Class', 'label')
# use the logistic regression model to predict test cases
lr_predictions = lr_model.transform(test)
# instantiate evaluator
evaluator = BinaryClassificationEvaluator()
# Logistic Regression performance metrics
print("Logistic Regression: Accuracy = {}".format(evaluator.evaluate(lr_predictions)))
lr_labels_and_predictions = test.rdd.map(lambda x: float(x.label)).zip(lr_predictions.rdd.map(lambda x: x.prediction))
lr_metrics = BinaryClassificationMetrics(lr_labels_and_predictions)
print("Logistic Regression: Area under ROC = %s" % lr_metrics.areaUnderROC)
print("Logistic Regression: Area under PR = %s" % lr_metrics.areaUnderPR)
# In[36]:
# use the random forest model to predict test cases
rf_predictions = rf_model.transform(test)
# RandonForestClassifer performance metrics
print("Random Forest Classifier: Accuracy = {}".format(evaluator.evaluate(rf_predictions)))
rf_labels_and_predictions = test.rdd.map(lambda x: float(x.label)).zip(rf_predictions.rdd.map(lambda x: x.prediction))
rf_metrics = BinaryClassificationMetrics(rf_labels_and_predictions)
print("Random Forest Classifier: Area under ROC = %s" % rf_metrics.areaUnderROC)
print("Random Forest Classifier: Area under PR = %s" % rf_metrics.areaUnderPR)
# ## Save Model
# Save the model.
# In[37]:
# Save each model
lr_model.write().overwrite().save("resources/fs_model_lr")
rf_model.write().overwrite().save("resources/fs_model_rf")
# ### Load and Test Model
# Load the saved model and test it by predicting a test instance.
# In[38]:
from pyspark.ml.classification import LogisticRegressionModel, RandomForestClassificationModel
lr_model2 = LogisticRegressionModel.load("resources/fs_model_lr")
print("Logistic Regression model save/load test:")
lr_predictions2 = lr_model2.transform(test.limit(5))
lr_predictions2['label', 'prediction'].show()
print("Random Forest model save/load test:")
rf_model2 = RandomForestClassificationModel.read().load("resources/fs_model_rf")
rf_predictions2 = rf_model2.transform(test.limit(5))
rf_predictions2['label', 'prediction'].show()
# # Takeaways and Conclusion
# In this notebook, we explored how Aerospike can be used as a Feature Store for ML applications. Specifically, we showed how features and datasets stored in the Aerospike can be explored and reused for model training. We implemented a simple example feature store interface that leverages the Aerospike Spark Connector capabilities for this purpose. We used the APIs to create, save, and query features and datasets for model training.
#
# This is the second notebook in the series of notebooks on how Aerospike can be used as a feature store. The [first notebook](feature-store-feature-eng.ipynb) discusses Feature Engineering aspects, whereas the [third notebook](feature-store-model-serving.ipynb) explores the use of Aerospike Feature Store for Model Serving.
# # Cleaning Up
# Close the spark session, and remove the tutorial data.
# In[39]:
try:
spark.stop()
except:
("# ignore")
# To remove all data in the namespace test, uncomment the following line and run:
#!aql -c "truncate test"
# # Further Exploration and Resources
# Here are some links for further exploration.
#
# ## Resources
# - Related notebooks
# - [Feature Store with Aerospike (Part 1)](feature-store-feature-eng.ipynb)
# - [Model Serving with Aerospike Feature Store (Part 3)](feature-store-model-serving.ipynb)
# - [Aerospike Connect for Spark Tutorial for Python](AerospikeSparkPython.ipynb)
# - [Pushdown Expressions for Spark Connector](resources/pushdown-expressions.ipynb)
# - Related blog posts
# - [Let AI/ML workloads take off with Aerospike and Spark 3.0](https://medium.com/aerospike-developer-blog/let-ai-ml-workloads-take-off-with-aerospike-and-spark-3-0-82de2d834b99)
# - [Using Aerospike Connect For Spark](https://medium.com/aerospike-developer-blog/aerospike-is-a-highly-scalable-key-value-database-offering-best-in-class-performance-5922450aaa78)
# - Aerospike Developer Hub
# - [Developer Hub](https://developer.aerospike.com/)
# - Github repos
# - [Spark Aerospike Example](https://github.com/aerospike-examples/spark-aerospike-example)
# ## Exploring Other Notebooks
#
# Visit [Aerospike notebooks repo](https://github.com/aerospike-examples/interactive-notebooks) to run additional Aerospike notebooks. To run a different notebook, download the notebook from the repo to your local machine, and then click on File->Open in the notebook menu, and select Upload.