#!/usr/bin/env python
# coding: utf-8
# ***
# # 数据抓取:
#
# > # 使用Python编写网络爬虫
# ***
#
# 王成军
#
# wangchengjun@nju.edu.cn
#
# 计算传播网 http://computational-communication.com
# # 需要解决的问题
#
# - 页面解析
# - 获取Javascript隐藏源数据
# - 自动翻页
# - 自动登录
# - 连接API接口
#
# In[1]:
import requests
from bs4 import BeautifulSoup
# - 一般的数据抓取,使用urllib2和beautifulsoup配合就可以了。
# - 尤其是对于翻页时url出现规则变化的网页,只需要处理规则化的url就可以了。
# - 以简单的例子是抓取天涯论坛上关于某一个关键词的帖子。
# - 在天涯论坛,关于雾霾的帖子的第一页是:
# http://bbs.tianya.cn/list.jsp?item=free&nextid=0&order=8&k=雾霾
# - 第二页是:
# http://bbs.tianya.cn/list.jsp?item=free&nextid=1&order=8&k=雾霾
#
# ***
# # 数据抓取:
# > # 抓取天涯回帖网络
# ***
#
# 王成军
#
# wangchengjun@nju.edu.cn
#
# 计算传播网 http://computational-communication.com
# In[2]:
from IPython.display import display_html, HTML
HTML('')
# the webpage we would like to crawl
# In[3]:
page_num = 0
url = "http://bbs.tianya.cn/list.jsp?item=free&nextid=%d&order=8&k=PX"% page_num
content = requests.get(url).text
soup = BeautifulSoup(content, "lxml")
articles = soup.find_all('tr')
#td[0].find('a', {'class', ""})
# In[4]:
articles[0]
# In[6]:
articles[1]
# In[7]:
len(articles[1:])
# 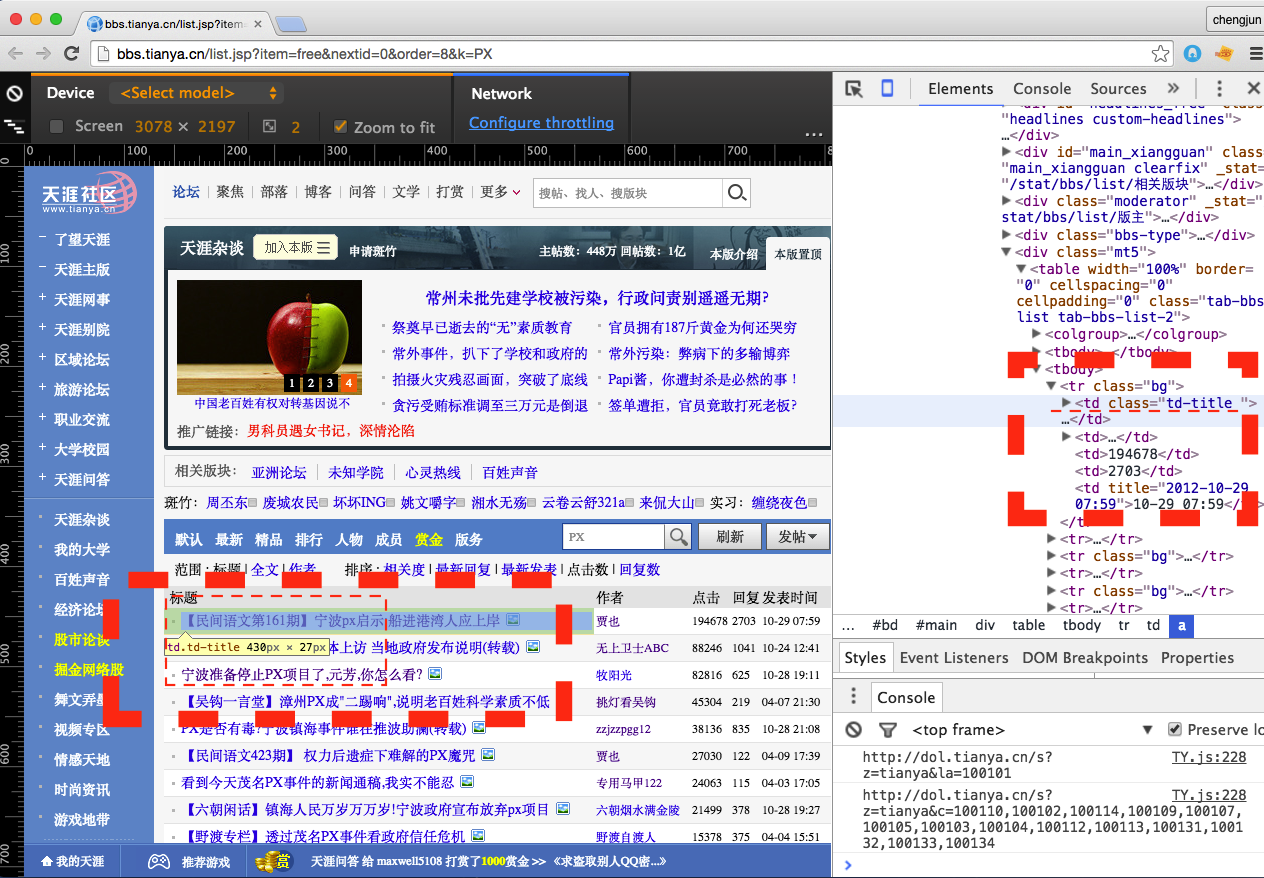
# http://bbs.tianya.cn/list.jsp?item=free&nextid=0&order=8&k=PX
#
# # 通过分析帖子列表的源代码,使用inspect方法,会发现所有要解析的内容都在‘td’这个层级下
#
# In[10]:
for t in articles[1].find_all('td'):
print(t)
# In[11]:
td = articles[1].find_all('td')
# In[27]:
td
# In[12]:
td[0]
# In[13]:
td[0].text
# In[14]:
td[0].text.strip()
# In[15]:
td[0].a['href']
# In[21]:
td[1]
# In[23]:
td[1].find('a', {'class', "author"})['href']
# In[28]:
td[2]
# In[29]:
td[3]
# In[30]:
td[4]
# In[32]:
records = []
for k, i in enumerate(articles[1:]):
td = i.find_all('td')
title = td[0].text.strip()
try:
title_url = td[0].find('a', {'class', "author"})['href']
except:
title_url = td[0].a['href']
author = td[1].text
author_url = td[1].a['href']
views = td[2].text
replies = td[3].text
date = td[4]['title']
record = '\t'.join([title, title_url, author, author_url, views, replies, date])
# record = title + '\t' + title_url+ '\t' + author +
# '\t'+ author_url + '\t' + views+ '\t' + replies+ '\t'+ date
records.append(record)
# In[34]:
records[:3]
# In[35]:
print(records[2])
# # 抓取天涯论坛PX帖子列表
#
# 回帖网络(Thread network)的结构
# - 列表
# - 主帖
# - 回帖
# In[45]:
articles[2]
# In[36]:
def crawler(page_num, file_name):
try:
# open the browser
url = "http://bbs.tianya.cn/list.jsp?item=free&nextid=%d&order=8&k=PX" % page_num
content = requests.get(url).text #获取网页的html文本
soup = BeautifulSoup(content, "lxml")
articles = soup.find_all('tr')
# write down info
for i in articles[1:]:
td = i.find_all('td')
title = td[0].text.strip()
title_url = td[0].a['href']
author = td[1].text
author_url = td[1].a['href']
views = td[2].text
replies = td[3].text
date = td[4]['title']
record = title + '\t' + title_url+ '\t' + author + '\t'+ \
author_url + '\t' + views+ '\t' + replies+ '\t'+ date
with open(file_name,'a') as p: # '''Note''':Append mode, run only once!
p.write(record+"\n") ##!!encode here to utf-8 to avoid encoding
except Exception as e:
print(e)
pass
# In[37]:
# crawl all pages
for page_num in range(10):
print(page_num)
crawler(page_num, '../data/tianya_bbs_threads_list2018.txt')
# In[38]:
import pandas as pd
df = pd.read_csv('../data/tianya_bbs_threads_list2018.txt',
sep = "\t", names = ['title', 'link', 'author', \
'author_page', 'click', 'reply', 'time'])
df[:3]
# In[39]:
len(df)
# In[40]:
len(df.link)
# # 抓取作者信息
# In[41]:
df.author_page[:5]
# http://www.tianya.cn/62237033
#
# http://www.tianya.cn/67896263
#
# In[42]:
# user_info
# In[43]:
url = df.author_page[10]
content = requests.get(url).text #获取网页的html文本
soup = BeautifulSoup(content, "lxml")
# In[44]:
soup
# In[49]:
print(url)
# In[47]:
# In[45]:
user_info = soup.find('div', {'class', 'userinfo'})('p')
score, reg_time = [i.get_text()[4:] for i in user_info]
print(score, reg_time )
link_info = soup.find_all('div', {'class', 'link-box'})
followed_num, fans_num = [i.a.text for i in link_info]
print(followed_num, fans_num)
# In[51]:
#activity = soup.find_all('span', {'class', 'subtitle'})
#post_num, reply_num = [j.text[2:] for i in activity[:1] for j in i('a')]
#print(post_num, reply_num)
#activity
# In[53]:
#activity[0]
# In[54]:
link_info = soup.find_all('div', {'class', 'link-box'})
followed_num, fans_num = [i.a.text for i in link_info]
print(followed_num, fans_num)
# In[55]:
link_info[0].a.text
# In[56]:
# user_info = soup.find('div', {'class', 'userinfo'})('p')
# user_infos = [i.get_text()[4:] for i in user_info]
def author_crawler(url, file_name):
try:
content = requests.get(url).text #获取网页的html文本
soup = BeautifulSoup(content, "lxml")
link_info = soup.find_all('div', {'class', 'link-box'})
followed_num, fans_num = [i.a.text for i in link_info]
try:
activity = soup.find_all('span', {'class', 'subtitle'})
post_num, reply_num = [j.text[2:] for i in activity[:1] for j in i('a')]
except:
post_num, reply_num = '1', '0'
record = '\t'.join([url, followed_num, fans_num, post_num, reply_num])
with open(file_name,'a') as p: # '''Note''':Append mode, run only once!
p.write(record+"\n") ##!!encode here to utf-8 to avoid encoding
except Exception as e:
print(e, url)
record = '\t'.join([url, 'na', 'na', 'na', 'na'])
with open(file_name,'a') as p: # '''Note''':Append mode, run only once!
p.write(record+"\n") ##!!encode here to utf-8 to avoid encoding
pass
# In[58]:
#soup
# In[137]:
url = df.author_page[10]
content = requests.get(url).text #获取网页的html文本
soup = BeautifulSoup(content, "lxml")
link_info = soup.find_all('div', {'class', 'link-box'})
followed_num, fans_num = [i.a.text for i in link_info]
try:
activity = soup.find_all('span', {'class', 'subtitle'})
post_num, reply_num = [j.text[2:] for i in activity[:1] for j in i('a')]
except:
post_num, reply_num = '1', '0'
record = '\t'.join([url, followed_num, fans_num, post_num, reply_num])
# In[74]:
import sys
def flushPrint(s):
sys.stdout.write('\r')
sys.stdout.write('%s' % s)
sys.stdout.flush()
# In[61]:
import time, random
for k, url in enumerate(df.author_page[:15]):
time.sleep(random.random()) # 天涯存在反抓取机制,需要降低抓取速度!
#flushPrint(k)
author_crawler(url, '../data/tianya_bbs_threads_author_info2018.txt')
# http://www.tianya.cn/50499450/follow
#
# 还可抓取他们的关注列表和粉丝列表
# ***
# ***
# # 数据抓取:
# > # 使用Python抓取回帖
# ***
# ***
#
# 王成军
#
# wangchengjun@nju.edu.cn
#
# 计算传播网 http://computational-communication.com
# In[62]:
df.link[2]
# In[64]:
url = 'http://bbs.tianya.cn' + df.link[2]
print(url)
# In[65]:
from IPython.display import display_html, HTML
HTML('')
# the webpage we would like to crawl
# In[66]:
post = requests.get(url).text #获取网页的html文本
post_soup = BeautifulSoup(post, "lxml")
#articles = soup.find_all('tr')
# In[67]:
print (post_soup.prettify())[:5000]
# In[68]:
pa = post_soup.find_all('div', {'class', 'atl-item'})
len(pa)
# In[69]:
print(pa[0])
# In[70]:
pa[1]
# In[71]:
pa[70]
# 作者:柠檬在追逐 时间:2012-10-28 21:33:55
#
# @lice5 2012-10-28 20:37:17
#
# 作为宁波人 还是说一句:革命尚未成功 同志仍需努力
#
# -----------------------------
#
# 对 现在说成功还太乐观,就怕说一套做一套
# 作者:lice5 时间:2012-10-28 20:37:17
#
# 作为宁波人 还是说一句:革命尚未成功 同志仍需努力
# 4 /post-free-4242156-1.shtml 2014-04-09 15:55:35 61943225 野渡自渡人 @Y雷政府34楼2014-04-0422:30:34 野渡君雄文!支持是必须的。 ----------------------------- @清坪过客16楼2014-04-0804:09:48 绝对的权力导致绝对的腐败! ----------------------------- @T大漠鱼T35楼2014-04-0810:17:27 @周丕东@普欣@拾月霜寒2012@小摸包@姚文嚼字@四號@凌宸@乔志峰@野渡自渡人@曾兵2010@缠绕夜色@曾颖@风青扬请关注
# In[233]:
pa[0].find('div', {'class', 'bbs-content'}).text.strip()
# In[76]:
print(pa[0].text.strip())#.find('div', {'class', 'marg'}).text.strip()
# In[77]:
pa[67].find('div', {'class', 'bbs-content'}).text.strip()
# In[78]:
pa[1].a
# In[79]:
pa[0].find('a', class_ = 'reportme a-link')
# In[80]:
pa[0].find('a', class_ = 'reportme a-link')['replytime']
# In[81]:
pa[0].find('a', class_ = 'reportme a-link')['author']
# In[82]:
for i in pa[:10]:
p_info = i.find('a', class_ = 'reportme a-link')
p_time = p_info['replytime']
p_author_id = p_info['authorid']
p_author_name = p_info['author']
p_content = i.find('div', {'class', 'bbs-content'}).text.strip()
p_content = p_content.replace('\t', '')
print(p_time, '--->', p_author_id, '--->', p_author_name,'--->', p_content, '\n')
# # 如何翻页
#
# http://bbs.tianya.cn/post-free-2848797-1.shtml
#
# http://bbs.tianya.cn/post-free-2848797-2.shtml
#
# http://bbs.tianya.cn/post-free-2848797-3.shtml
# In[83]:
post_soup.find('div', {'class', 'atl-pages'})#.['onsubmit']
# In[84]:
post_pages = post_soup.find('div', {'class', 'atl-pages'})
post_pages = post_pages.form['onsubmit'].split(',')[-1].split(')')[0]
post_pages
#post_soup.select('.atl-pages')[0].select('form')[0].select('onsubmit')
# In[85]:
url = 'http://bbs.tianya.cn' + df.link[2]
url_base = ''.join(url.split('-')[:-1]) + '-%d.shtml'
url_base
# In[86]:
def parsePage(pa):
records = []
for i in pa:
p_info = i.find('a', class_ = 'reportme a-link')
p_time = p_info['replytime']
p_author_id = p_info['authorid']
p_author_name = p_info['author']
p_content = i.find('div', {'class', 'bbs-content'}).text.strip()
p_content = p_content.replace('\t', '').replace('\n', '')#.replace(' ', '')
record = p_time + '\t' + p_author_id+ '\t' + p_author_name + '\t'+ p_content
records.append(record)
return records
import sys
def flushPrint(s):
sys.stdout.write('\r')
sys.stdout.write('%s' % s)
sys.stdout.flush()
# In[87]:
url_1 = 'http://bbs.tianya.cn' + df.link[10]
content = requests.get(url_1).text #获取网页的html文本
post_soup = BeautifulSoup(content, "lxml")
pa = post_soup.find_all('div', {'class', 'atl-item'})
b = post_soup.find('div', class_= 'atl-pages')
b
# In[88]:
url_0 = 'http://bbs.tianya.cn' + df.link[2]
content = requests.get(url_0).text #获取网页的html文本
post_soup = BeautifulSoup(content, "lxml")
pa = post_soup.find_all('div', {'class', 'atl-item'})
a = post_soup.find('div', class_= 'atl-pages')
a
# In[89]:
a.form
# In[90]:
if b.form:
print('true')
else:
print('false')
# In[91]:
import random
import time
def crawler(url, file_name):
try:
# open the browser
url_1 = 'http://bbs.tianya.cn' + url
content = requests.get(url_0).text #获取网页的html文本
post_soup = BeautifulSoup(content, "lxml")
# how many pages in a post
post_form = post_soup.find('div', {'class', 'atl-pages'})
if post_form.form:
post_pages = post_form.form['onsubmit'].split(',')[-1].split(')')[0]
post_pages = int(post_pages)
url_base = '-'.join(url_1.split('-')[:-1]) + '-%d.shtml'
else:
post_pages = 1
# for the first page
pa = post_soup.find_all('div', {'class', 'atl-item'})
records = parsePage(pa)
with open(file_name,'a') as p: # '''Note''':Append mode, run only once!
for record in records:
p.write('1'+ '\t' + url + '\t' + record+"\n")
# for the 2nd+ pages
if post_pages > 1:
for page_num in range(2, post_pages+1):
time.sleep(random.random())
flushPrint(page_num)
url2 =url_base % page_num
content = requests.get(url2).text #获取网页的html文本
post_soup = BeautifulSoup(content, "lxml")
pa = post_soup.find_all('div', {'class', 'atl-item'})
records = parsePage(pa)
with open(file_name,'a') as p: # '''Note''':Append mode, run only once!
for record in records:
p.write(str(page_num) + '\t' +url + '\t' + record+"\n")
else:
pass
except Exception as e:
print(e)
pass
# # 测试
# In[92]:
url = df.link[2]
file_name = '../data/tianya_bbs_threads_2018test.txt'
crawler(url, file_name)
# # 正式抓取!
# In[94]:
for k, link in enumerate(df.link):
flushPrint(link)
if k % 10== 0:
print('This it the post of : ' + str(k))
file_name = '../data/tianya_bbs_threads_network_2018.txt'
crawler(link, file_name)
# # 读取数据
# In[95]:
dtt = []
with open('../data/tianya_bbs_threads_network_2018.txt', 'r') as f:
for line in f:
pnum, link, time, author_id, author, content = line.replace('\n', '').split('\t')
dtt.append([pnum, link, time, author_id, author, content])
len(dtt)
# In[96]:
dt = pd.DataFrame(dtt)
dt[:5]
# In[97]:
dt=dt.rename(columns = {0:'page_num', 1:'link', 2:'time', 3:'author',4:'author_name', 5:'reply'})
dt[:5]
# In[98]:
dt.reply[:100]
# ## 总帖数是多少?
# http://search.tianya.cn/bbs?q=PX 共有18459 条内容
# In[93]:
18459/50
# 实际上到第10页就没有了 http://bbs.tianya.cn/list.jsp?item=free&order=1&nextid=9&k=PX, 原来那只是天涯论坛,还有其它各种版块,如天涯聚焦: http://focus.tianya.cn/ 等等。
#
# - 娱乐八卦 512
# - 股市论坛 187
# - 情感天地 242
# - 天涯杂谈 1768
# 在天涯杂谈搜索雾霾,有41页 http://bbs.tianya.cn/list.jsp?item=free&order=20&nextid=40&k=%E9%9B%BE%E9%9C%BE
# # 天涯SDK
# http://open.tianya.cn/wiki/index.php?title=SDK%E4%B8%8B%E8%BD%BD
# In[ ]: