# | arc-standard |
# create arc from stack top to second stack item,
pop second stack item |
# stack contains root,
buffer contains words |
# stack contains root,
buffer is empty |
#
#
# | arc-hybrid |
# create arc from buffer top to stack top,
pop stack top |
# stack is empty,
buffer contains words and root |
# stack is empty,
buffer contains root |
#
# 
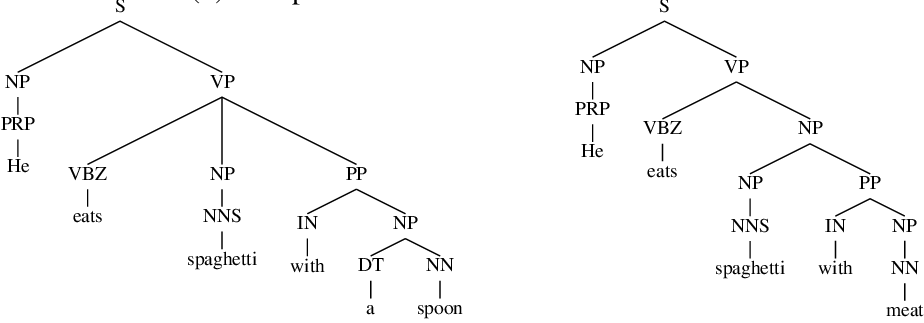 #
# 

 #
# 
 #
#