# \begin{align}
# \\
# \\
# \\
# \\
# \\
# \\
# \overleftarrow{\mathbf{h}}_t &= f_{\overleftarrow{\theta}}(\mathbf{x}_t, \overleftarrow{\mathbf{h}}_{t-1})\\
# \overrightarrow{\mathbf{h}}_t &= f_{\overrightarrow{\theta}}(\mathbf{x}_t, \overrightarrow{\mathbf{h}}_{t+1})\\
# \hat{\mathbf{y}}_t & = g(\overleftarrow{\mathbf{h}}_t, \overrightarrow{\mathbf{h}}_t)
# \end{align}
#
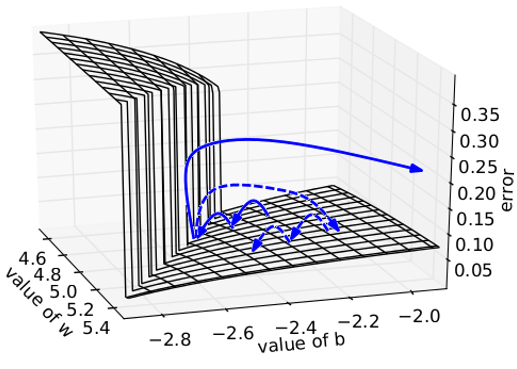 #
#  # # Implementing LSTM (TensorFlow)
# ```python
# lstm = rnn_cell.BasicLSTMCell(lstm_size)
# # Initial state of the LSTM memory.
# state = tf.zeros([batch_size, lstm.state_size])
# probabilities = []
# loss_val = 0.0
# for batch_of_words in words_in_dataset:
# # State is updated after processing each batch
# output, state = lstm(batch_of_words, state)
# # Output is used to make next word predictions
# scores = tf.matmul(output, out_w) + out_b
# probabilities.append(tf.nn.softmax(scores))
# loss_val += loss(probabilities, target_words)
# ```
# - Pay attention to **batching**, **bucketization** and **padding**
# # Levels of Granularity
#
# Char-Level Language Models: Char-RNN - see e.g. [Karpathy, 2015]
#
#
# # Implementing LSTM (TensorFlow)
# ```python
# lstm = rnn_cell.BasicLSTMCell(lstm_size)
# # Initial state of the LSTM memory.
# state = tf.zeros([batch_size, lstm.state_size])
# probabilities = []
# loss_val = 0.0
# for batch_of_words in words_in_dataset:
# # State is updated after processing each batch
# output, state = lstm(batch_of_words, state)
# # Output is used to make next word predictions
# scores = tf.matmul(output, out_w) + out_b
# probabilities.append(tf.nn.softmax(scores))
# loss_val += loss(probabilities, target_words)
# ```
# - Pay attention to **batching**, **bucketization** and **padding**
# # Levels of Granularity
#
# Char-Level Language Models: Char-RNN - see e.g. [Karpathy, 2015]
#
#  #
#  #
#  #
#