#!/usr/bin/env python
# coding: utf-8
# # Link to the lab
#
# https://tinyurl.com/inlplab5
# # Setup
#
# We'll use fasttext wiki embeddings in our embedding layer, and pytorch-crf to add a CRF to our BiLSTM.
# In[4]:
get_ipython().system('pip install fasttext')
get_ipython().system('pip install pytorch-crf')
get_ipython().system('pip install datasets')
get_ipython().system('pip install sklearn')
# In[2]:
get_ipython().run_line_magic('reload_ext', 'autoreload')
get_ipython().run_line_magic('autoreload', '2')
get_ipython().run_line_magic('matplotlib', 'inline')
# In[26]:
import io
from math import log
from numpy import array
from numpy import argmax
import torch
import random
from math import log
from numpy import array
from numpy import argmax
import numpy as np
from torch.utils.data import Dataset, DataLoader
from torch import nn
from torch.optim import Adam
from torchcrf import CRF
from torch.optim.lr_scheduler import ExponentialLR, CyclicLR
from typing import List, Tuple, AnyStr
from tqdm.notebook import tqdm
from sklearn.metrics import precision_recall_fscore_support
import matplotlib.pyplot as plt
from copy import deepcopy
from datasets import load_dataset, load_metric
from sklearn.metrics import confusion_matrix
import torch.nn.functional as F
import heapq
# In[6]:
def enforce_reproducibility(seed=42):
# Sets seed manually for both CPU and CUDA
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
# For atomic operations there is currently
# no simple way to enforce determinism, as
# the order of parallel operations is not known.
# CUDNN
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
# System based
random.seed(seed)
np.random.seed(seed)
enforce_reproducibility()
# # Sequence Classification - recap
#
#
# Sequence classification is the task of
# - predicting a class (e.g., POS tag) for each separate token in a textual input
# - label tokens as beginning (B), inside (I), or outside (O)
# - predicting which tokens from the input belong to a span, e.g.:
# - which tokens from a document answer a given question (extractive QA)
# 
# - which tokens in a news article contain propagandistic techniques
# 
# - the spans can be of different types, e.g. type of a Named Entity (NE) -- Person, Location, Organisation
# - ([More datasets for structured prediction](https://huggingface.co/datasets?languages=languages:en&task_categories=task_categories:structure-prediction&sort=downloads))
# ## Named entity recognition
#
#
# - identify the **entities** that appear in a document and their types
# - e.g., extract from the following sentence all names of the people, locations, and organizations:
#
#
#
#
#
# | Sundar |
# Pichai |
# is |
# the |
# CEO |
# of |
# Alphabet |
# , |
# located |
# in |
# Mountain |
# View |
# , |
# CA |
#
#
# | PER |
# PER |
# O |
# O |
# O |
# O |
# ORG |
# O |
# O |
# O |
# LOC |
# LOC |
# LOC |
# LOC |
#
#
#
#
# - we have labelled all of the tokens associate with their classes as the given type (PER: Person, ORG: Organization, LOC: Location, O: Outside). **Question: What are some issues that could arise as a result of this tagging?
# In practice, we will also want to denote which tokens are the beginning of an entity, and which tokens are inside the full entity span, giving the following tagging:
#
#
#
#
#
# | Sundar |
# Pichai |
# is |
# the |
# CEO |
# of |
# Alphabet |
# , |
# located |
# in |
# Mountain |
# View |
# , |
# CA |
#
#
# | B-PER |
# I-PER |
# O |
# O |
# O |
# O |
# B-ORG |
# O |
# O |
# O |
# B-LOC |
# I-LOC |
# I-LOC |
# I-LOC |
#
#
#
#
# **Question: What are some other tagging schemes that you think could be good?**
#
# Modeling the dependencies between the predictions can be useful: for example knowing that the previous tag was `B-PER` influences whether or not the current tag will be `I-PER` or `O` or `I-LOC`.
# ## Download and prepare the data
#
# We'll use a small set of Wikipedia data labelled with people, locations, organizations, and "miscellaneous" entities.
# In[7]:
datasets = load_dataset("conll2003")
datasets
# In[8]:
print(datasets['train'])
print(datasets['train'][0])
print(datasets["train"].features[f"ner_tags"])
print(datasets["train"].features[f"ner_tags"].feature.names)
# We'll create the word embedding space:
# - with FastText pretrained embeddings
# - using all of the *vocabulary from the train and dev splits*, plus the most frequent tokens from the trained word embeddings. This will reduce the embeddings size!
# In[9]:
get_ipython().system('wget https://dl.fbaipublicfiles.com/fasttext/vectors-english/wiki-news-300d-1M.vec.zip')
get_ipython().system('unzip wiki-news-300d-1M.vec.zip')
# In[10]:
# Reduce down to our vocabulary and word embeddings
def load_vectors(fname, vocabulary):
fin = io.open(fname, 'r', encoding='utf-8', newline='\n', errors='ignore')
n, d = map(int, fin.readline().split())
tag_names = datasets["train"].features[f"ner_tags"].feature.names
final_vocab = tag_names + ['[PAD]', '[UNK]', '[BOS]', '[EOS]']
final_vectors = [np.random.normal(size=(300,)) for _ in range(len(final_vocab))]
for j,line in enumerate(fin):
tokens = line.rstrip().split(' ')
if tokens[0] in vocabulary or len(final_vocab) < 30000:
final_vocab.append(tokens[0])
final_vectors.append(np.array(list(map(float, tokens[1:]))))
return final_vocab, np.vstack(final_vectors)
class FasttextTokenizer:
def __init__(self, vocabulary):
self.vocab = {}
for j,l in enumerate(vocabulary):
self.vocab[l.strip()] = j
def encode(self, text):
# Text is assumed to be tokenized
return [self.vocab[t] if t in self.vocab else self.vocab['[UNK]'] for t in text]
# In[11]:
vocabulary = (set([t for s in datasets['train'] for t in s['tokens']]) | set([t for s in datasets['validation'] for t in s['tokens']]))
vocabulary, pretrained_embeddings = load_vectors('wiki-news-300d-1M.vec', vocabulary)
print('size of vocabulary: ', len(vocabulary))
tokenizer = FasttextTokenizer(vocabulary)
# The main difference in the dataset reading and collation functions is that we now return a sequence of labels instead of a single label as in text classification.
# In[21]:
def collate_batch_bilstm(input_data: Tuple) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
input_ids = [tokenizer.encode(i['tokens']) for i in input_data]
seq_lens = [len(i) for i in input_ids]
labels = [i['ner_tags'] for i in input_data]
max_length = max([len(i) for i in input_ids])
input_ids = [(i + [0] * (max_length - len(i))) for i in input_ids]
labels = [(i + [0] * (max_length - len(i))) for i in labels] # 0 is the id of the O tag
assert (all(len(i) == max_length for i in input_ids))
assert (all(len(i) == max_length for i in labels))
return torch.tensor(input_ids), torch.tensor(seq_lens), torch.tensor(labels)
# In[23]:
dev_dl = DataLoader(datasets['validation'], batch_size=1, shuffle=False, collate_fn=collate_batch_bilstm, num_workers=0)
next(iter(dev_dl))
# In[14]:
print(datasets['validation'][0])
print(collate_batch_bilstm([datasets['validation'][0]]))
# # Creating the model
# ## LSTM model for sequence classification
#
# You'll notice that the BiLSTM model is mostly the same from the text classification and language modeling labs.
# In[16]:
# Define the model
class BiLSTM(nn.Module):
"""
Basic BiLSTM-CRF network
"""
def __init__(
self,
pretrained_embeddings: torch.tensor,
lstm_dim: int,
dropout_prob: float = 0.1,
n_classes: int = 2
):
"""
Initializer for basic BiLSTM network
:param pretrained_embeddings: A tensor containing the pretrained BPE embeddings
:param lstm_dim: The dimensionality of the BiLSTM network
:param dropout_prob: Dropout probability
:param n_classes: The number of output classes
"""
# First thing is to call the superclass initializer
super(BiLSTM, self).__init__()
# We'll define the network in a ModuleDict, which makes organizing the model a bit nicer
# The components are an embedding layer, a 2 layer BiLSTM, and a feed-forward output layer
self.model = nn.ModuleDict({
'embeddings': nn.Embedding.from_pretrained(pretrained_embeddings, padding_idx=pretrained_embeddings.shape[0] - 1),
'bilstm': nn.LSTM(
pretrained_embeddings.shape[1], # input size
lstm_dim, # hidden size
2, # number of layers
batch_first=True,
dropout=dropout_prob,
bidirectional=True),
'ff': nn.Linear(2*lstm_dim, n_classes),
})
self.n_classes = n_classes
self.loss = nn.CrossEntropyLoss()
# Initialize the weights of the model
self._init_weights()
def _init_weights(self):
all_params = list(self.model['bilstm'].named_parameters()) + \
list(self.model['ff'].named_parameters())
for n,p in all_params:
if 'weight' in n:
nn.init.xavier_normal_(p)
elif 'bias' in n:
nn.init.zeros_(p)
def forward(self, inputs, input_lens, hidden_states = None, labels = None):
"""
Defines how tensors flow through the model
:param inputs: (b x sl) The IDs into the vocabulary of the input samples
:param input_lens: (b) The length of each input sequence
:param labels: (b) The label of each sample
:return: (loss, logits) if `labels` is not None, otherwise just (logits,)
"""
# Get embeddings (b x sl x edim)
embeds = self.model['embeddings'](inputs)
# Pack padded: This is necessary for padded batches input to an RNN - https://stackoverflow.com/questions/51030782/why-do-we-pack-the-sequences-in-pytorch
lstm_in = nn.utils.rnn.pack_padded_sequence(
embeds,
input_lens.cpu(),
batch_first=True,
enforce_sorted=False
)
# Pass the packed sequence through the BiLSTM
if hidden_states:
lstm_out, hidden = self.model['bilstm'](lstm_in, hidden_states)
else:
lstm_out, hidden = self.model['bilstm'](lstm_in)
# Unpack the packed sequence --> (b x sl x 2*lstm_dim)
lstm_out, lengths = nn.utils.rnn.pad_packed_sequence(lstm_out, batch_first=True)
# Get logits (b x seq_len x n_classes)
logits = self.model['ff'](lstm_out)
outputs = (logits, lengths)
if labels is not None:
loss = self.loss(logits.reshape(-1, self.n_classes), labels.reshape(-1))
outputs = outputs + (loss,)
return outputs
# In[75]:
def train(
model: nn.Module,
train_dl: DataLoader,
valid_dl: DataLoader,
optimizer: torch.optim.Optimizer,
n_epochs: int,
device: torch.device,
scheduler=None,
):
"""
The main training loop which will optimize a given model on a given dataset
:param model: The model being optimized
:param train_dl: The training dataset
:param valid_dl: A validation dataset
:param optimizer: The optimizer used to update the model parameters
:param n_epochs: Number of epochs to train for
:param device: The device to train on
:return: (model, losses) The best model and the losses per iteration
"""
# Keep track of the loss and best accuracy
losses = []
learning_rates = []
best_f1 = 0.0
# Iterate through epochs
for ep in range(n_epochs):
loss_epoch = []
#Iterate through each batch in the dataloader
for batch in tqdm(train_dl):
# VERY IMPORTANT: Make sure the model is in training mode, which turns on
# things like dropout and layer normalization
model.train()
# VERY IMPORTANT: zero out all of the gradients on each iteration -- PyTorch
# keeps track of these dynamically in its computation graph so you need to explicitly
# zero them out
optimizer.zero_grad()
# Place each tensor on the GPU
batch = tuple(t.to(device) for t in batch)
input_ids = batch[0]
seq_lens = batch[1]
labels = batch[2]
# Pass the inputs through the model, get the current loss and logits
logits, lengths, loss = model(input_ids, seq_lens, labels=labels)
losses.append(loss.item())
loss_epoch.append(loss.item())
# Calculate all of the gradients and weight updates for the model
loss.backward()
# Optional: clip gradients
#torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# Finally, update the weights of the model
optimizer.step()
if scheduler != None:
scheduler.step()
learning_rates.append(scheduler.get_last_lr()[0])
# Perform inline evaluation at the end of the epoch
f1 = evaluate(model, valid_dl)
print(f'Validation F1: {f1}, train loss: {sum(loss_epoch) / len(loss_epoch)}')
# Keep track of the best model based on the accuracy
if f1 > best_f1:
torch.save(model.state_dict(), 'best_model')
best_f1 = f1
return losses, learning_rates
# In[76]:
def evaluate(model: nn.Module, valid_dl: DataLoader):
"""
Evaluates the model on the given dataset
:param model: The model under evaluation
:param valid_dl: A `DataLoader` reading validation data
:return: The accuracy of the model on the dataset
"""
# VERY IMPORTANT: Put your model in "eval" mode -- this disables things like
# layer normalization and dropout
model.eval()
labels_all = []
preds_all = []
# ALSO IMPORTANT: Don't accumulate gradients during this process
with torch.no_grad():
for batch in tqdm(valid_dl, desc='Evaluation'):
batch = tuple(t.to(device) for t in batch)
input_ids = batch[0]
seq_lens = batch[1]
labels = batch[2]
hidden_states = None
logits, _, _ = model(input_ids, seq_lens, hidden_states=hidden_states, labels=labels)
preds_all.extend(torch.argmax(logits, dim=-1).reshape(-1).detach().cpu().numpy())
labels_all.extend(labels.reshape(-1).detach().cpu().numpy())
P, R, F1, _ = precision_recall_fscore_support(labels_all, preds_all, average='macro')
print(confusion_matrix(labels_all, preds_all))
return F1
# In[77]:
lstm_dim = 128
dropout_prob = 0.1
batch_size = 8
lr = 1e-2
n_epochs = 10
n_workers = 0 # set to a larger number if you run your code in colab
device = torch.device("cpu")
if torch.cuda.is_available():
device = torch.device("cuda")
# Create the model
model = BiLSTM(
pretrained_embeddings=torch.FloatTensor(pretrained_embeddings),
lstm_dim=lstm_dim,
dropout_prob=dropout_prob,
n_classes=len(datasets["train"].features[f"ner_tags"].feature.names)
).to(device)
# In[78]:
train_dl = DataLoader(datasets['train'], batch_size=batch_size, shuffle=True, collate_fn=collate_batch_bilstm, num_workers=n_workers)
valid_dl = DataLoader(datasets['validation'], batch_size=len(datasets['validation']), collate_fn=collate_batch_bilstm, num_workers=n_workers)
# Create the optimizer
optimizer = Adam(model.parameters(), lr=lr)
scheduler = CyclicLR(optimizer, base_lr=0., max_lr=lr, step_size_up=1, step_size_down=len(train_dl)*n_epochs, cycle_momentum=False)
# Train
losses, learning_rates = train(model, train_dl, valid_dl, optimizer, n_epochs, device, scheduler)
model.load_state_dict(torch.load('best_model'))
# In[29]:
test_dl = DataLoader(datasets['test'], batch_size=len(datasets['test']), collate_fn=collate_batch_bilstm, num_workers=n_workers)
evaluate(model, test_dl)
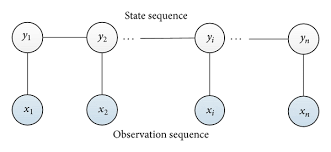
# # Conditional Random Field (CRF)
#
# 
#
# - learn from and perform inference on data whose predictions depend on each other
# - a type of graphical model
# - **nodes** are the individual observations you wish to make predictions on
# - **edges** are dependencies between the nodes
# - the prediction you make for one token can change your belief about the other tokens
# - after determiners (DT), adjectives and nouns are much more likely than verbs
# - unfortunately, trying to model the dependencies between each node in an arbitrarily sized graph is combinatorial and thus intractable, so we have to make some simplifying assumptions.
#
# Assumptions for a **linear chain CRF**:
# - assume that your data is structured as a sequence
# - assume that your prediction at time $t$ is only dependent on your prediction at time $t - 1$
# - you make predictions by modeling two things:
# - the **probability of a label given your input** ($p(y_{t}|X)$)
# - the **probability of a label given the previous label** ($p(y_t|y_{t-1})$).
#
# In the **BiLSTM-CRF**
# - input probabilities $p(y_t|X)$ are modeled using the BiLSTM (as usual)
# - the probabilities $p(y_t|y_{t-1})$ are modeled using a transition matrix $V$ of size $n \times n$ where $n$ is the number of tags (i.e., one transition probability for each possible transition).
# - in practice - add a CRF on top of your BiLSTM output logits instead of using a softmax and cross-entropy on the BiLSTM logits.
#
# 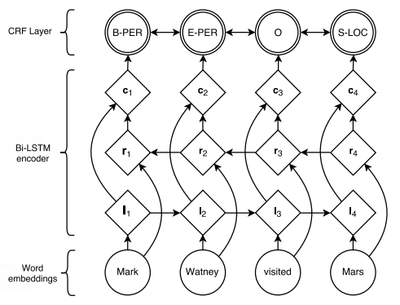
# [Source](https://www.aclweb.org/anthology/N16-1030.pdf)
#
# The model is then trained by maximizing the log-likelihood (i.e. minimizing the negative log-likelihood) of the entire sequence. For more in depth explanation of how this is performed, see the lectures from Hugo Larochelle [here](https://www.youtube.com/watch?v=PGBlyKtfB74&ab_channel=HugoLarochelle).
#
#
# Only a few lines of code to add a CRF using this third party library: [pytorch-crf](https://pytorch-crf.readthedocs.io/en/stable/). For a more advanced implementation, check [AllenNLP CRF module](https://github.com/allenai/allennlp/blob/master/allennlp/modules/conditional_random_field.py)
#
# The differences are:
#
# - Instead of taking a softmax/cross-entropy loss using the logits from the BiLSTM, we pass the logits to the pytorch-crf CRF module. The output of this model is the **log-likelihood of the entire sequence** (for each sequence in the batch). Since our objective is to minimize the loss, we take the **negative** of the log likelihood as our loss.
# - There is now a **decode** function, which passes logits through the CRF to get the most likely tag sequences.
#
# In[30]:
# Define the model
class BiLSTM_CRF(nn.Module):
"""
Basic BiLSTM-CRF network
"""
def __init__(
self,
pretrained_embeddings: torch.tensor,
lstm_dim: int,
dropout_prob: float = 0.1,
n_classes: int = 2
):
"""
Initializer for basic BiLSTM network
:param pretrained_embeddings: A tensor containing the pretrained BPE embeddings
:param lstm_dim: The dimensionality of the BiLSTM network
:param dropout_prob: Dropout probability
:param n_classes: The number of output classes
"""
# First thing is to call the superclass initializer
super(BiLSTM_CRF, self).__init__()
# We'll define the network in a ModuleDict, which makes organizing the model a bit nicer
# The components are an embedding layer, a 2 layer BiLSTM, and a feed-forward output layer
self.model = nn.ModuleDict({
'embeddings': nn.Embedding.from_pretrained(pretrained_embeddings, padding_idx=pretrained_embeddings.shape[0] - 1),
'bilstm': nn.LSTM(
pretrained_embeddings.shape[1],
lstm_dim,
2,
batch_first=True,
dropout=dropout_prob,
bidirectional=True),
'ff': nn.Linear(2*lstm_dim, n_classes),
'CRF': CRF(n_classes, batch_first=True)
})
self.n_classes = n_classes
# Initialize the weights of the model
self._init_weights()
def _init_weights(self):
all_params = list(self.model['bilstm'].named_parameters()) + \
list(self.model['ff'].named_parameters())
for n,p in all_params:
if 'weight' in n:
nn.init.xavier_normal_(p)
elif 'bias' in n:
nn.init.zeros_(p)
def forward(self, inputs, input_lens, labels = None):
"""
Defines how tensors flow through the model
:param inputs: (b x sl) The IDs into the vocabulary of the input samples
:param input_lens: (b) The length of each input sequence
:param labels: (b) The label of each sample
:return: (loss, logits) if `labels` is not None, otherwise just (logits,)
"""
# Get embeddings (b x sl x edim)
embeds = self.model['embeddings'](inputs)
# Pack padded: This is necessary for padded batches input to an RNN
lstm_in = nn.utils.rnn.pack_padded_sequence(
embeds,
input_lens.cpu(),
batch_first=True,
enforce_sorted=False
)
# Pass the packed sequence through the BiLSTM
lstm_out, hidden = self.model['bilstm'](lstm_in)
# Unpack the packed sequence --> (b x sl x 2*lstm_dim)
lstm_out,_ = nn.utils.rnn.pad_packed_sequence(lstm_out, batch_first=True)
# Get emissions (b x seq_len x n_classes)
emissions = self.model['ff'](lstm_out)
outputs = (emissions,)
if labels is not None:
mask = (inputs != 0)
# log-likelihood from the CRF
log_likelihood = self.model['CRF'](emissions, labels, mask=mask, reduction='token_mean')
outputs = (-log_likelihood,) + outputs
return outputs
def decode(self, emissions, mask):
"""
Given a set of emissions and a mask, decode the sequence
"""
return self.model['CRF'].decode(emissions, mask=mask)
# ## Traning the model
# The evaluation function is also slightly different -- we evaluate perfomance based on the decoded sequence from the CRF as opposed to the output of the BiLSTM. We use macro-F1 score for this.
# In[31]:
def train(
model: nn.Module,
train_dl: DataLoader,
valid_dl: DataLoader,
optimizer: torch.optim.Optimizer,
n_epochs: int,
device: torch.device,
scheduler=None,
):
"""
The main training loop which will optimize a given model on a given dataset
:param model: The model being optimized
:param train_dl: The training dataset
:param valid_dl: A validation dataset
:param optimizer: The optimizer used to update the model parameters
:param n_epochs: Number of epochs to train for
:param device: The device to train on
:return: (model, losses) The best model and the losses per iteration
"""
# Keep track of the loss and best accuracy
losses = []
learning_rates = []
best_f1 = 0.0
# Iterate through epochs
for ep in range(n_epochs):
loss_epoch = []
#Iterate through each batch in the dataloader
for batch in tqdm(train_dl):
# VERY IMPORTANT: Make sure the model is in training mode, which turns on
# things like dropout and layer normalization
model.train()
# VERY IMPORTANT: zero out all of the gradients on each iteration -- PyTorch
# keeps track of these dynamically in its computation graph so you need to explicitly
# zero them out
optimizer.zero_grad()
# Place each tensor on the GPU
batch = tuple(t.to(device) for t in batch)
input_ids = batch[0]
seq_lens = batch[1]
labels = batch[2]
# Pass the inputs through the model, get the current loss and logits
loss, logits = model(input_ids, seq_lens, labels=labels)
losses.append(loss.item())
loss_epoch.append(loss.item())
# Calculate all of the gradients and weight updates for the model
loss.backward()
# Optional: clip gradients
#torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# Finally, update the weights of the model
optimizer.step()
if scheduler != None:
scheduler.step()
learning_rates.append(scheduler.get_last_lr()[0])
#gc.collect()
# Perform inline evaluation at the end of the epoch
f1 = evaluate(model, valid_dl)
print(f'Validation F1: {f1}, train loss: {sum(loss_epoch) / len(loss_epoch)}')
# Keep track of the best model based on the accuracy
if f1 > best_f1:
torch.save(model.state_dict(), 'best_model')
best_f1 = f1
#gc.collect()
return losses, learning_rates
# In[33]:
def evaluate(model: nn.Module, valid_dl: DataLoader):
"""
Evaluates the model on the given dataset
:param model: The model under evaluation
:param valid_dl: A `DataLoader` reading validation data
:return: The accuracy of the model on the dataset
"""
# VERY IMPORTANT: Put your model in "eval" mode -- this disables things like
# layer normalization and dropout
model.eval()
labels_all = []
logits_all = []
tags_all = []
# ALSO IMPORTANT: Don't accumulate gradients during this process
with torch.no_grad():
for batch in tqdm(valid_dl, desc='Evaluation'):
batch = tuple(t.to(device) for t in batch)
input_ids = batch[0]
seq_lens = batch[1]
labels = batch[2]
logits = model(input_ids, seq_lens, labels=labels)[-1]
mask = (input_ids != 0)
labels_all.extend([l for seq,samp in zip(list(labels.detach().cpu().numpy()), input_ids) for l,i in zip(seq,samp) if i != 0])
logits_all.extend(list(logits.detach().cpu().numpy()))
tags = model.decode(logits, mask)
tags_all.extend([t for seq in tags for t in seq])
P, R, F1, _ = precision_recall_fscore_support(labels_all, tags_all, average='macro')
print(confusion_matrix(labels_all, tags_all))
return F1
# In[34]:
lstm_dim = 128
dropout_prob = 0.1
batch_size = 8
lr = 1e-2
n_epochs = 10
n_workers = 0
device = torch.device("cpu")
if torch.cuda.is_available():
device = torch.device("cuda")
# Create the model
model = BiLSTM_CRF(
pretrained_embeddings=torch.FloatTensor(pretrained_embeddings),
lstm_dim=lstm_dim,
dropout_prob=dropout_prob,
n_classes=len(datasets["train"].features[f"ner_tags"].feature.names)
).to(device)
# In[35]:
train_dl = DataLoader(datasets['train'], batch_size=batch_size, shuffle=True, collate_fn=collate_batch_bilstm, num_workers=n_workers)
valid_dl = DataLoader(datasets['validation'], batch_size=len(datasets['validation']), collate_fn=collate_batch_bilstm, num_workers=n_workers)
# Create the optimizer
optimizer = Adam(model.parameters(), lr=lr)
scheduler = CyclicLR(optimizer, base_lr=0., max_lr=lr, step_size_up=1, step_size_down=len(train_dl)*n_epochs, cycle_momentum=False)
# Train
losses, learning_rates = train(model, train_dl, valid_dl, optimizer, n_epochs, device, scheduler)
model.load_state_dict(torch.load('best_model'))
# In[37]:
test_dl = DataLoader(datasets['test'], batch_size=len(datasets['test']), collate_fn=collate_batch_bilstm, num_workers=n_workers)
evaluate(model, test_dl)
# In[38]:
model.eval()
examples = [0, 2]
for ex in examples:
samples = [b.to(device) for b in next(iter(test_dl))]
# Get the emissions. These are basically p(y|x) for each token x,
# which will be input to the CRF a decoded with the help of p(y_t|y_{t-1})
(emissions,) = model(samples[0], samples[1])
mask = (samples[0] != 0)
tags = model.decode(emissions, mask)
print([(tok, datasets["train"].features[f"ner_tags"].feature.names[tag], datasets["train"].features[f"ner_tags"].feature.names[gold_tag])
for tok,tag, gold_tag in zip(datasets['test'][ex]['tokens'], tags[ex], datasets['test'][ex]['ner_tags'])])
# After training the model, we can inspect the CRF layer and check the learned transition matrix $V = p(y_t|y_{t-1})$. For example, we can see that the most probable transition from B-PER is I-PER, as expected.
# In[71]:
b_per_id = datasets["train"].features[f"ner_tags"].feature.names.index("B-PER")
transitions = model.model["CRF"].transitions[b_per_id].detach().to("cpu")
transitions = torch.softmax(transitions, 0).numpy()
for idx, tag in enumerate(datasets["train"].features[f"ner_tags"].feature.names):
print(f"{tag}: {transitions[idx]}")
# **Question:** How would you implement a Transformer-CRF?
# # Beam Search
#  [(source)](https://towardsdatascience.com/foundations-of-nlp-explained-visually-beam-search-how-it-works-1586b9849a24)
#
# In[79]:
# source https://machinelearningmastery.com/beam-search-decoder-natural-language-processing/
def beam_search_decoder(data, k):
sequences = [[list(), 0.0]]
# walk over each step in sequence
for row in data:
all_candidates = list()
# expand each current candidate
for i in range(len(sequences)):
seq, score = sequences[i]
for j in range(len(row)):
candidate = [seq + [j], score - log(row[j])]
all_candidates.append(candidate)
# order all candidates by score
ordered = sorted(all_candidates, key=lambda tup:tup[1])
# select k best
sequences = ordered[:k]
return sequences
# define a sequence of 10 words over a vocab of 5 words
data = [[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1],
[0.1, 0.2, 0.3, 0.4, 0.5],
[0.5, 0.4, 0.3, 0.2, 0.1]]
data = array(data)
# decode sequence
result = beam_search_decoder(data, 3)
# print result
for seq in result:
print(seq)
# - **Question: Can you find what is the problem with the above?**
#
#
# - In the above, when generating text, the probability distribution for the next step does not depend on the previous step's choice.
# - Beam search is usually employed with encoder-decoder architectures:
# 
# - At each step, the decoder receives as input the prediction of the previous step and the hidden state of the previous step.
# - During training : at each step provide either the prediction at the previous step with highest probability or the gold label for the next step (teacher forcing).
# - During testing: build a beam of top-k generated sequences and re-run the decoder with each of them.
#
# Resources:
# - Implementing an encoder-decoder model [example 1](https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html), [example 2](https://bastings.github.io/annotated_encoder_decoder/)
# - Implementing beam search [example](https://github.com/budzianowski/PyTorch-Beam-Search-Decoding/blob/master/decode_beam.py)
#
# In[80]:
class EncoderRNN(nn.Module):
"""
RNN Encoder model.
"""
def __init__(self,
pretrained_embeddings: torch.tensor,
lstm_dim: int,
dropout_prob: float = 0.1):
"""
Initializer for EncoderRNN network
:param pretrained_embeddings: A tensor containing the pretrained embeddings
:param lstm_dim: The dimensionality of the LSTM network
:param dropout_prob: Dropout probability
"""
# First thing is to call the superclass initializer
super(EncoderRNN, self).__init__()
# We'll define the network in a ModuleDict, which makes organizing the model a bit nicer
# The components are an embedding layer, and an LSTM layer.
self.model = nn.ModuleDict({
'embeddings': nn.Embedding.from_pretrained(pretrained_embeddings, padding_idx=pretrained_embeddings.shape[0] - 1),
'lstm': nn.LSTM(pretrained_embeddings.shape[1], lstm_dim, 2, batch_first=True, bidirectional=True),
})
# Initialize the weights of the model
self._init_weights()
def _init_weights(self):
all_params = list(self.model['lstm'].named_parameters())
for n, p in all_params:
if 'weight' in n:
nn.init.xavier_normal_(p)
elif 'bias' in n:
nn.init.zeros_(p)
def forward(self, inputs, input_lens):
"""
Defines how tensors flow through the model
:param inputs: (b x sl) The IDs into the vocabulary of the input samples
:param input_lens: (b) The length of each input sequence
:return: (lstm output state, lstm hidden state)
"""
embeds = self.model['embeddings'](inputs)
lstm_in = nn.utils.rnn.pack_padded_sequence(
embeds,
input_lens.cpu(),
batch_first=True,
enforce_sorted=False
)
lstm_out, hidden_states = self.model['lstm'](lstm_in)
lstm_out, _ = nn.utils.rnn.pad_packed_sequence(lstm_out, batch_first=True)
return lstm_out, hidden_states
class DecoderRNN(nn.Module):
"""
RNN Decoder model.
"""
def __init__(self, pretrained_embeddings: torch.tensor,
lstm_dim: int,
dropout_prob: float = 0.1,
n_classes: int = 2):
"""
Initializer for DecoderRNN network
:param pretrained_embeddings: A tensor containing the pretrained embeddings
:param lstm_dim: The dimensionality of the LSTM network
:param dropout_prob: Dropout probability
:param n_classes: Number of prediction classes
"""
# First thing is to call the superclass initializer
super(DecoderRNN, self).__init__()
# We'll define the network in a ModuleDict, which makes organizing the model a bit nicer
# The components are an embedding layer, a LSTM layer, and a feed-forward output layer
self.model = nn.ModuleDict({
'embeddings': nn.Embedding.from_pretrained(pretrained_embeddings, padding_idx=pretrained_embeddings.shape[0] - 1),
'lstm': nn.LSTM(pretrained_embeddings.shape[1], lstm_dim, 2, bidirectional=True, batch_first=True),
'nn': nn.Linear(lstm_dim*2, n_classes),
})
# Initialize the weights of the model
self._init_weights()
def forward(self, inputs, hidden, input_lens):
"""
Defines how tensors flow through the model
:param inputs: (b x sl) The IDs into the vocabulary of the input samples
:param hidden: (b) The hidden state of the previous step
:param input_lens: (b) The length of each input sequence
:return: (output predictions, lstm hidden states) the hidden states will be used as input at the next step
"""
embeds = self.model['embeddings'](inputs)
lstm_in = nn.utils.rnn.pack_padded_sequence(
embeds,
input_lens.cpu(),
batch_first=True,
enforce_sorted=False
)
lstm_out, hidden_states = self.model['lstm'](lstm_in, hidden)
lstm_out, _ = nn.utils.rnn.pad_packed_sequence(lstm_out, batch_first=True)
output = self.model['nn'](lstm_out)
return output, hidden_states
def _init_weights(self):
all_params = list(self.model['lstm'].named_parameters()) + list(self.model['nn'].named_parameters())
for n, p in all_params:
if 'weight' in n:
nn.init.xavier_normal_(p)
elif 'bias' in n:
nn.init.zeros_(p)
# Define the model
class Seq2Seq(nn.Module):
"""
Basic Seq2Seq network
"""
def __init__(
self,
pretrained_embeddings: torch.tensor,
lstm_dim: int,
dropout_prob: float = 0.1,
n_classes: int = 2
):
"""
Initializer for basic Seq2Seq network
:param pretrained_embeddings: A tensor containing the pretrained embeddings
:param lstm_dim: The dimensionality of the LSTM network
:param dropout_prob: Dropout probability
:param n_classes: The number of output classes
"""
# First thing is to call the superclass initializer
super(Seq2Seq, self).__init__()
# We'll define the network in a ModuleDict, which consists of an encoder and a decoder
self.model = nn.ModuleDict({
'encoder': EncoderRNN(pretrained_embeddings, lstm_dim, dropout_prob),
'decoder': DecoderRNN(pretrained_embeddings, lstm_dim, dropout_prob, n_classes),
})
self.loss = nn.CrossEntropyLoss(weight=torch.FloatTensor([0.5]+[1]*(len(datasets["train"].features[f"ner_tags"].feature.names)-1)).to(device))
def forward(self, inputs, input_lens, labels=None):
"""
Defines how tensors flow through the model.
For the Seq2Seq model this includes 1) encoding the whole input text,
and running *target_length* decoding steps to predict the tag of each token.
:param inputs: (b x sl) The IDs into the vocabulary of the input samples
:param input_lens: (b) The length of each input sequence
:param labels: (b) The label of each sample
:return: (loss, logits) if `labels` is not None, otherwise just (logits,)
"""
# Get embeddings (b x sl x embedding dim)
encoder_output, encoder_hidden = self.model['encoder'](inputs, input_lens)
decoder_hidden = encoder_hidden
decoder_input = torch.tensor([tokenizer.encode(['[BOS]'])]*inputs.shape[0], device=device)
target_length = labels.size(1)
loss = None
for di in range(target_length):
decoder_output, decoder_hidden = self.model['decoder'](
decoder_input, decoder_hidden, torch.tensor([1]*inputs.shape[0]))
if loss == None:
loss = self.loss(decoder_output.squeeze(1), labels[:, di])
else:
loss += self.loss(decoder_output.squeeze(1), labels[:, di])
# Teacher forcing: Feed the target as the next input
decoder_input = labels[:, di].unsqueeze(-1)
return loss / target_length
# In[82]:
def train(
model: nn.Module,
train_dl: DataLoader,
valid_dl: DataLoader,
optimizer: torch.optim.Optimizer,
n_epochs: int,
device: torch.device,
):
"""
The main training loop which will optimize a given model on a given dataset
:param model: The model being optimized
:param train_dl: The training dataset
:param valid_dl: A validation dataset
:param optimizer: The optimizer used to update the model parameters
:param n_epochs: Number of epochs to train for
:param device: The device to train on
:return: (model, losses) The best model and the losses per iteration
"""
# Keep track of the loss and best accuracy
losses = []
best_f1 = 0.0
# Iterate through epochs
for ep in range(n_epochs):
loss_epoch = []
#Iterate through each batch in the dataloader
for batch in tqdm(train_dl):
# VERY IMPORTANT: Make sure the model is in training mode, which turns on
# things like dropout and layer normalization
model.train()
# VERY IMPORTANT: zero out all of the gradients on each iteration -- PyTorch
# keeps track of these dynamically in its computation graph so you need to explicitly
# zero them out
optimizer.zero_grad()
# Place each tensor on the GPU
batch = tuple(t.to(device) for t in batch)
input_ids = batch[0]
labels = batch[2]
input_lens = batch[1]
# Pass the inputs through the model, get the current loss and logits
loss = model(input_ids, labels=labels, input_lens=input_lens)
losses.append(loss.item())
loss_epoch.append(loss.item())
# Calculate all of the gradients and weight updates for the model
loss.backward()
# Optional: clip gradients
#torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# Finally, update the weights of the model
optimizer.step()
# Perform inline evaluation at the end of the epoch
f1 = evaluate(model, valid_dl)
print(f'Validation F1: {f1}, train loss: {sum(loss_epoch) / len(loss_epoch)}')
# Keep track of the best model based on the accuracy
if f1 > best_f1:
torch.save(model.state_dict(), 'best_model')
best_f1 = f1
return losses
# In[84]:
softmax = nn.Softmax(dim=-1)
def decode(model, inputs, input_lens, labels=None, beam_size=2):
"""
Decoding/predicting the labels for an input text by running beam search.
:param inputs: (b x sl) The IDs into the vocabulary of the input samples
:param input_lens: (b) The length of each input sequence
:param labels: (b) The label of each sample
:param beam_size: the size of the beam
:return: predicted sequence of labels
"""
assert inputs.shape[0] == 1
# first, encode the input text
encoder_output, encoder_hidden = model.model['encoder'](inputs, input_lens)
decoder_hidden = encoder_hidden
# the decoder starts generating after the Begining of Sentence (BOS) token
decoder_input = torch.tensor([tokenizer.encode(['[BOS]',]),], device=device)
target_length = labels.shape[1]
# we will use heapq to keep top best sequences so far sorted in heap_queue
# these will be sorted by the first item in the tuple
heap_queue = []
heap_queue.append((torch.tensor(0), tokenizer.encode(['[BOS]']), decoder_input, decoder_hidden))
# Beam Decoding
for _ in range(target_length):
# print("next len")
new_items = []
# for each item on the beam
for j in range(len(heap_queue)):
# 1. remove from heap
score, tokens, decoder_input, decoder_hidden = heapq.heappop(heap_queue)
# 2. decode one more step
decoder_output, decoder_hidden = model.model['decoder'](
decoder_input, decoder_hidden, torch.tensor([1]))
decoder_output = softmax(decoder_output)
# 3. get top-k predictions
best_idx = torch.argsort(decoder_output[0], descending=True)[0]
# print(decoder_output)
# print(best_idx)
for i in range(beam_size):
decoder_input = torch.tensor([[best_idx[i]]], device=device)
new_items.append((score + decoder_output[0,0, best_idx[i]],
tokens + [best_idx[i].item()],
decoder_input,
decoder_hidden))
# add new sequences to the heap
for item in new_items:
# print(item)
heapq.heappush(heap_queue, item)
# remove sequences with lowest score (items are sorted in descending order)
while len(heap_queue) > beam_size:
heapq.heappop(heap_queue)
final_sequence = heapq.nlargest(1, heap_queue)[0]
assert labels.shape[1] == len(final_sequence[1][1:])
return final_sequence
# In[85]:
def evaluate(model: nn.Module, valid_dl: DataLoader, beam_size:int = 1):
"""
Evaluates the model on the given dataset
:param model: The model under evaluation
:param valid_dl: A `DataLoader` reading validation data
:return: The accuracy of the model on the dataset
"""
# VERY IMPORTANT: Put your model in "eval" mode -- this disables things like
# layer normalization and dropout
model.eval()
labels_all = []
logits_all = []
tags_all = []
# ALSO IMPORTANT: Don't accumulate gradients during this process
with torch.no_grad():
for batch in tqdm(valid_dl, desc='Evaluation'):
batch = tuple(t.to(device) for t in batch)
input_ids = batch[0]
input_lens = batch[1]
labels = batch[2]
best_seq = decode(model, input_ids, input_lens, labels=labels, beam_size=beam_size)
mask = (input_ids != 0)
labels_all.extend([l for seq,samp in zip(list(labels.detach().cpu().numpy()), input_ids) for l,i in zip(seq,samp) if i != 0])
tags_all += best_seq[1][1:]
# print(best_seq[1][1:], labels)
P, R, F1, _ = precision_recall_fscore_support(labels_all, tags_all, average='macro')
print(confusion_matrix(labels_all, tags_all))
return F1
# In[88]:
lstm_dim = 300
dropout_prob = 0.1
batch_size = 64
lr = 1e-3
n_epochs = 20
n_workers = 0
device = torch.device("cpu")
if torch.cuda.is_available():
device = torch.device("cuda")
# Create the model
model = Seq2Seq(
pretrained_embeddings=torch.FloatTensor(pretrained_embeddings),
lstm_dim=lstm_dim,
dropout_prob=dropout_prob,
n_classes=len(datasets["train"].features[f"ner_tags"].feature.names)
).to(device)
# In[90]:
train_dl = DataLoader(datasets['train'], batch_size=batch_size, shuffle=True, collate_fn=collate_batch_bilstm, num_workers=n_workers)
valid_dl = DataLoader(datasets['validation'], batch_size=1, collate_fn=collate_batch_bilstm, num_workers=n_workers)
# Create the optimizer
optimizer = Adam(model.parameters(), lr=lr)
# Train
losses = train(model, train_dl, valid_dl, optimizer, n_epochs, device)
model.load_state_dict(torch.load('best_model'))
# **Question: Do you have ideas how to improve the model?**
# How about adding attention mechanism for the decoder to attend to the separate hidden states of the separate token steps in the encoder? (see the resources)
#
# In[68]:
test_dl = DataLoader(datasets['test'], batch_size=1, collate_fn=collate_batch_bilstm, num_workers=n_workers)
evaluate(model, test_dl, beam_size=1)
# In[69]:
evaluate(model, test_dl, beam_size=2)
# # Learning rate schedules
# Motivation:
# - speed up training
# - to train a better model
#
# With Pytorch:
# - choose a learning rate schedulers form `torch.optim.lr_schedule`
# - add a line in your training loop which calls the `step()` function of your scheduler
# - this will automatically change your learning rate!
# - **Note**: be aware of when to call `step()`; some schedulers change the learning rate after every epoch, and some change after every training step (batch). The one we will use here changes the learning rate after every training step. We'll define the scheduler in the cell that calls the `train()` function.
# Set up hyperparameters and create the model. Note the high learning rate -- this is partially due to the learning rate scheduler we will use.
# In[ ]:
lstm_dim = 128
dropout_prob = 0.1
batch_size = 8
lr = 1e-2
n_epochs = 10
n_workers = 0
device = torch.device("cpu")
if torch.cuda.is_available():
device = torch.device("cuda")
# Create the model
model = BiLSTM_CRF(
pretrained_embeddings=torch.FloatTensor(pretrained_embeddings),
lstm_dim=lstm_dim,
dropout_prob=dropout_prob,
n_classes=len(label_map)
).to(device)
# In[ ]:
train_dl = DataLoader(datasets['train'], batch_size=batch_size, shuffle=True, collate_fn=collate_batch_bilstm, num_workers=n_workers)
valid_dl = DataLoader(datasets['validation'], batch_size=len(datasets['validation']), collate_fn=collate_batch_bilstm, num_workers=n_workers)
# Create the optimizer
optimizer = Adam(model.parameters(), lr=lr)
scheduler = CyclicLR(optimizer, base_lr=0., max_lr=lr, step_size_up=1, step_size_down=len(train_dl)*n_epochs, cycle_momentum=False)
# Train
losses, learning_rates = train(model, train_dl, valid_dl, optimizer, n_epochs, device, scheduler)
model.load_state_dict(torch.load('best_model'))
# Above we have used the `CyclicLR` scheduler. The cyclic learning rate schedule in general looks like this:
#
# 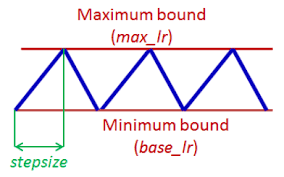 [Source](https://arxiv.org/pdf/1506.01186.pdf)
#
# We are using it here to linearly decay the learning rate from a starting max learning rate (here 1e-2) down to 0 over the entire course of training (essentially one cycle that starts at the max and ends at 0).
#
# " Allowing the learning rate to rise and fall is beneficial overall
# even though it might temporarily harm the network’s performance"
# In[ ]:
plt.plot(losses)
# In[ ]:
plt.plot(learning_rates)
# # Transformers for sequence classification
#
# - have to adjust the vocabulary where a word is split into multiple word piesces
# - [Tutorial on NER](https://github.com/huggingface/notebooks/blob/master/examples/token_classification.ipynb)
# - Some generative transformers now perform the same as token classification transformers [e.g. T5 can extract the span of a tweet that contains a sentiment](https://github.com/enzoampil/t5-intro/blob/master/t5_qa_training_pytorch_span_extraction.ipynb)