#!/usr/bin/env python
# coding: utf-8
# ### Introduction
#
# Controlling what a generative model produces is still a significant challenge. Diffusion models have introduced an unprecedented level of control compared to earlier approaches, but the process is far from perfect. You might generate an image, attempt a minor change, and find that the entire scene shifts just because you slightly adjusted the prompt.
#
# There has been considerable effort toward enabling more precise and user-friendly image editing methods that are more targeted and stable. In this post, I aim to tell the story of how these techniques have rapidly evolved over the last few years.
#
# ### Contents
#
# 1. [Prompt-to-Prompt Image Editing with Cross-Attention Control (ICLR 2023)](#prompt-to-prompt-image-editing-with-cross-attention-control-iclr-2023)
# 2. [InstructPix2Pix: Learning to Follow Image Editing Instructions (CVPR 2023)](#instructpix2pix-learning-to-follow-image-editing-instructions-cvpr-2023)
# 3. [Null-text Inversion for Editing Real Images using Guided Diffusion Models (CVPR 2023)](#null-text-inversion-for-editing-real-images-using-guided-diffusion-models-cvpr-2023)
#
# ### Prompt-to-Prompt Image Editing with Cross-Attention Control (ICLR 2023)
#
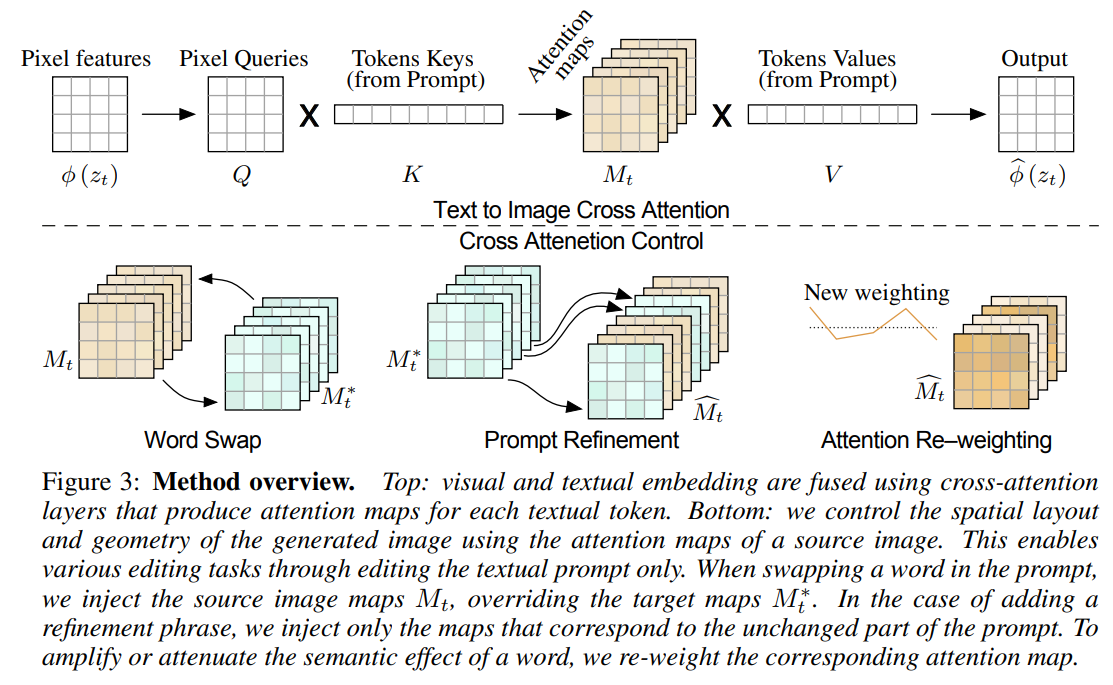
# It often happens that you generate an image but want to modify certain aspects without changing the entire scene. However, if you try to make that change by slightly adjusting the prompt in a text-to-image model (such as Stable Diffusion), you will likely end up with a completely different image.
#
# The goal of this paper is to provide more control during image editing, allowing you to make targeted changes to specific parts of the generated image while keeping the rest intact. Here is an example from the paper:
#
#

#
#
#
#

#
#

#
#

#
#

#
#

#