#!/usr/bin/env python
# coding: utf-8
# # Abstract
#
# ## Titel: Einführung in Software Analytics
#
#
# ## Beschreibung
# In Unternehmen werden Datenanalysen intensiv genutzt, um aus Geschäftsdaten wertvolle Einsichten
# zu gewinnen. Warum nutzen wir als Softwareentwickler Datenanalysen dann nicht auch für unsere eigenen Daten?
#
# In diesem Workshop stelle ich Vorgehen und Best Practices von Software Analytics vor. Wir sehen uns die dazugehörigen Open-Source-Werkzeuge an, mit denen sich Probleme in der Softwareentwicklung zielgerichtet analysieren und kommunizieren lassen.
#
# Im Praxisteil mit Jupyter, pandas, jQAssistant, Neo4j & Co. erarbeiten wir gemeinsam wertvolle Einsichten aus Datenquellen wie Git-Repositories, Performancedaten, Qualitätsberichten oder auch direkt aus dem Programmcode. Wir suchen nach besonders fehleranfälligem Code, erschließen No-Go-Areas in Altanwendungen und priorisieren Aufräumarbeiten entlang wichtiger Programmteile.
#
# Gerne kann bei diesem interaktiven Workshop direkt mitgearbeitet werden. Ein Notebook mit Internetzugang reicht hierfür völlig aus.
# In[1]:
get_ipython().run_line_magic('matplotlib', 'inline')
import pandas as pd
#
# # Einführung in
Software Analytics
# Markus Harrer, Software Development Analyst
#
# `@feststelltaste`
#
#
# ML Summit 2019, 14. Oktober 2019
#
#  # ## Workshop-Aufbau (1/2)
#
# ### 1. Teil: Theorie & Hands-On
# * Einführung in das Thema "Software Analytics"
# * Vorgehen für Datenanalysen in der Softwareentwicklung
# * Werkzeuge für leichtgewichtiges Software Analytics
# ## Workshop-Aufbau (2/2)
#
# ### 2. Teil: Praxis
# * Gemeinsame Durchführung erster Analysen
# * Bearbeitung von Aufgaben in Kleingruppen
# * Fragen & Antworten
# ## Über mich
#
#
# ## Workshop-Aufbau (1/2)
#
# ### 1. Teil: Theorie & Hands-On
# * Einführung in das Thema "Software Analytics"
# * Vorgehen für Datenanalysen in der Softwareentwicklung
# * Werkzeuge für leichtgewichtiges Software Analytics
# ## Workshop-Aufbau (2/2)
#
# ### 2. Teil: Praxis
# * Gemeinsame Durchführung erster Analysen
# * Bearbeitung von Aufgaben in Kleingruppen
# * Fragen & Antworten
# ## Über mich
#
#  # ## Datenanalysen in der Softwareentwicklung?
# # ... ein typischer Projektverlauf
# ## ... ein typischer Projektverlauf
#
# ## Datenanalysen in der Softwareentwicklung?
# # ... ein typischer Projektverlauf
# ## ... ein typischer Projektverlauf
#  # ## ... ein typischer Projektverlauf
#
# ## ... ein typischer Projektverlauf
#  # ## ... ein typischer Projektverlauf
#
# ## ... ein typischer Projektverlauf
#  # ## ... ein typischer Projektverlauf
#
# ## ... ein typischer Projektverlauf
#  # ##
# ## "Die Definition von Wahnsinn ist, immer wieder das Gleiche zu tun und andere Ergebnisse zu erwarten."
#
#
# ##
# ## "Die Definition von Wahnsinn ist, immer wieder das Gleiche zu tun und andere Ergebnisse zu erwarten."
#
#
# – Albert Einstein
# ## Das (Tr|D)auerthema
# 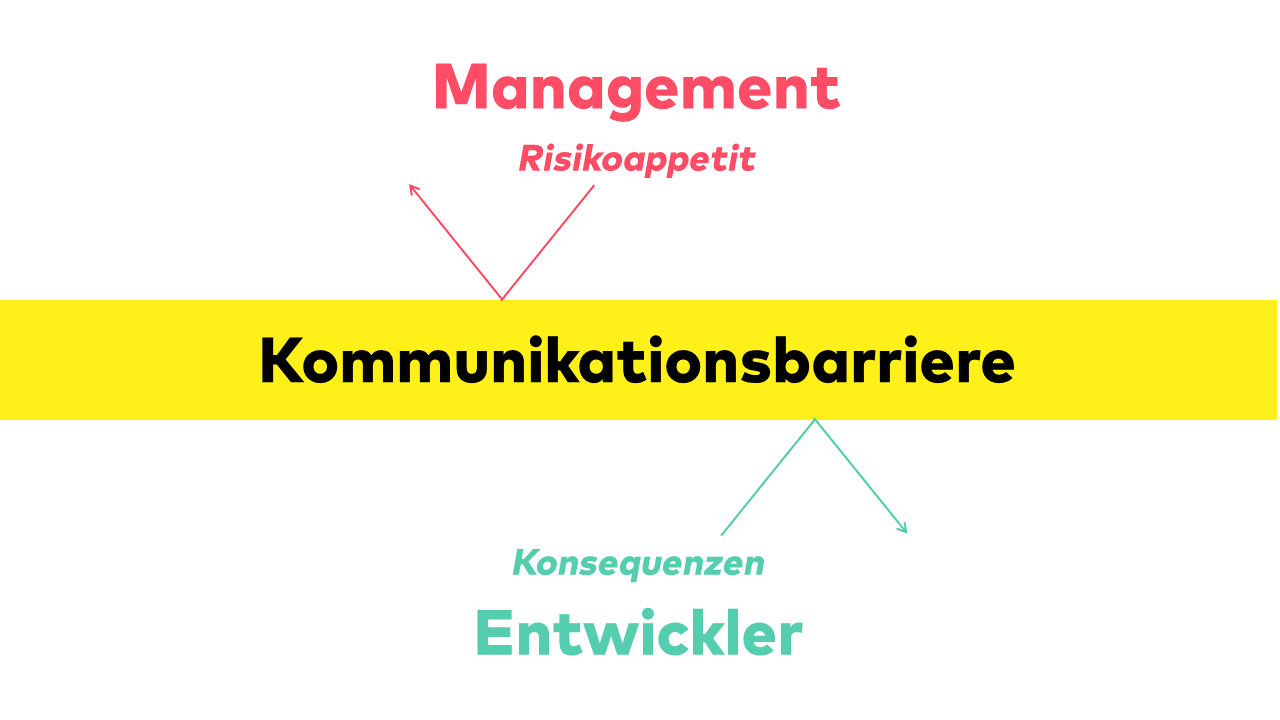 # ## Das (Tr|D)auerthema
#
# ## Das (Tr|D)auerthema
#  # ## "Software Analytics" als Retter?
# ### Definition "Software Analytics"
# "Software Analytics is analytics on software data for **managers** and software engineers with the aim of empowering software development individuals and teams to _gain and share insight from their data_ to make better decisions."
#
# ## "Software Analytics" als Retter?
# ### Definition "Software Analytics"
# "Software Analytics is analytics on software data for **managers** and software engineers with the aim of empowering software development individuals and teams to _gain and share insight from their data_ to make better decisions."
#
# Tim Menzies and Thomas Zimmermann
# ### Welche Arten von Softwaredaten?
#
# Alles was aus der Entwicklung und dem Betrieb der Softwaresysteme so anfällt:
# * Statische Daten
# * Laufzeitdaten
# * Chronologische Daten
# * Daten aus der Software-Community
# #### Welche Werkzeuge, Datenquellen und Daten?
#  # Sehr große Auswahl == sehr große Möglichkeiten?
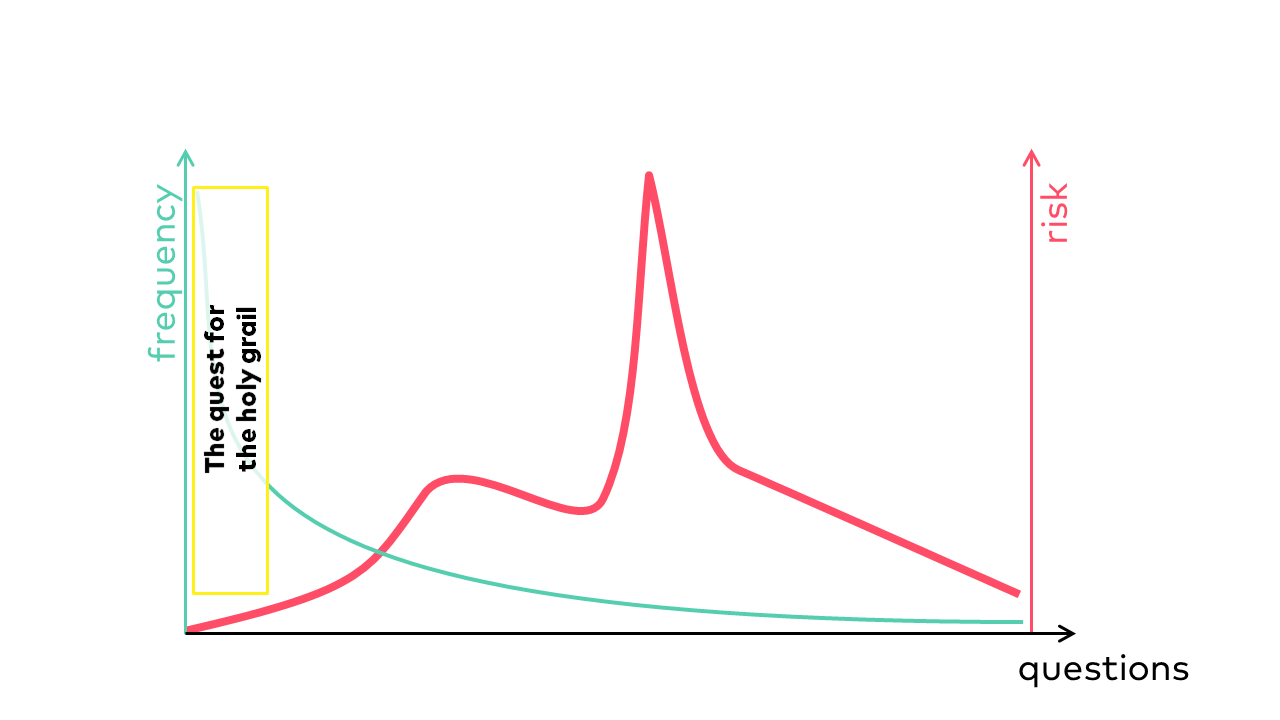
# ## (M)ein Problem mit (klassischem) Software Analytics
# ### (M)ein Problem mit Software Analytics
#
# Sehr große Auswahl == sehr große Möglichkeiten?
# ## (M)ein Problem mit (klassischem) Software Analytics
# ### (M)ein Problem mit Software Analytics
#  # ### (M)ein Problem mit Software Analytics
#
# ### (M)ein Problem mit Software Analytics
#
# ### (M)ein Problem mit Software Analytics
#
# ### (M)ein Problem mit Software Analytics
#  # ### (M)ein Problem mit Software Analytics
#
# ### (M)ein Problem mit Software Analytics
#  # ### (M)ein Problem mit Software Analytics
#
# ### (M)ein Problem mit Software Analytics
#  # ### (M)ein Problem mit Software Analytics
#
# ### (M)ein Problem mit Software Analytics
#  # ### Andere sehen dieses Problem auch!
#
# *Thomas Zimmermann in "One size does not fit all":*
#
# ### Andere sehen dieses Problem auch!
#
# *Thomas Zimmermann in "One size does not fit all":*
#
#
# "The main lesson: There is no one size fits all model. Even if you find models that work for most, they will not work for everyone. There is much academic research into general models. In contrast, industrial practitioners are often fine with models that just work for their data if the model provides some insight or allows them to work more efficiently."
#
# Aber: "... the methods typically are applicable on different datasets."
# => Analyseideen sind wiederverwendbar!
# ### "Es kommt drauf an!" aka Kontext
#
#
#

#
#
Data Science
#
# Eine leichtgewichtige Umsetzung von Software Analytics
#
# ## Data Science
# ### Was is Data Science?
# "**Statistics** on a Mac."
#
#
# https://twitter.com/cdixon/status/428914681911070720
# ### Meine Definition
# #### Was bedeutet "**data**"?
# "Without **data** you‘re just another person with an opinion."
#
# W. Edwards Deming
# => Belastbare Erkenntnisse mittels Fakten liefern
# #### Was bedeutet "**science**"?
#
#
# "The aim of **science** is to seek the simplest explanations of complex facts."
#
# Albert Einstein
# => Neue Erkenntnisse verständlich herausarbeiten
# ## Warum Data Science?
# ### Große (Online-)Community
# * Kostenlose Online-Kurse, -Videos und Tutorials (z. B. DataCamp mit über 4,6 Mio. Mitgliedern)
# * Direkte Hilfestellungen (z. B. Stack Overflow oder Blog-Artikel)
# * Lernen und lernen von anderen durch Online-Wettbewerbe (e. g. Kaggle, )
# ### Freie und einfach zu nutzende Werkzeuge!
#
#
#  #
# ### Data Science liegt immer noch im Trend!
# In[2]:
pd.read_csv("../datasets/google_trends_datascience.csv").plot();
# "100" == max. Beliebtheit!
# ### Mein "Bias"
# * Masterand: Schnelle Ergebnisse notwendig
# * Enterprise Java-Entwickler: Abends noch was Richtiges zu Stande bekommen
# * Allgemein: Weitere Standbeine "Data Science" und "Graphdatenbanken"
# # Wie weit weg sind SoftwareentwicklerInnen
#
# ### Data Science liegt immer noch im Trend!
# In[2]:
pd.read_csv("../datasets/google_trends_datascience.csv").plot();
# "100" == max. Beliebtheit!
# ### Mein "Bias"
# * Masterand: Schnelle Ergebnisse notwendig
# * Enterprise Java-Entwickler: Abends noch was Richtiges zu Stande bekommen
# * Allgemein: Weitere Standbeine "Data Science" und "Graphdatenbanken"
# # Wie weit weg sind SoftwareentwicklerInnen
von Data Science?
# ### Was ist ein Data Scientist?
# "A data scientist is someone who
# is better at **statistics**
# than any software engineer
# and better at software engineering
# than any **statistician**."
#
#
# From https://twitter.com/cdixon/status/428914681911070720
# Nicht so weit weg wie gedacht!
# # Wie Software Analytics mit Data Science beginnen?
# ### Bewährte Ansätze nutzen
# Roger Pengs "Stages of Data Analysis"
# I. Fragestellung
# II. Explorative Datenanalyse
# III. Formale Modellierung
# IV. Interpretation
# V. Kommunikation
#
#
#
# => von der Frage über die Daten zur Erkenntnis!
# ### "Seven principles...
# ...of inductive software engineering" (Tim Menzies)
#
#
#
# - Human before algorithms
# - Plan for Scale
# - Get Early Feedback
# - Be Open Minded
# - Be Smart with Your Learning
# - Live with the Data You Have
# - Develop a Broad Skill Set That Uses a Big Toolkit
#
#
#  #
# # Wie nachvollziehbar umsetzen?
# ### Verwende Literate Statistical Programming
#
# `(Intent + Code + Data + Results)`
#
# # Wie nachvollziehbar umsetzen?
# ### Verwende Literate Statistical Programming
#
# `(Intent + Code + Data + Results)`
# `* Logical Step`
# `+ Automation`
# `= Literate Statistical Programming`
# Vehikel: **Computational notebooks**
# #### Beispiel "Computational Notebook"
#
#
#
#
# ### Wende Best Practices in Notebooks an
#
#
#
#  |
# Pro Variable eine Spalte |
#
#  |
# Für jede Beobachtung eine Reihe |
#
#  |
# Für alle zusammengehörigen Variablen eine Tabelle |
#
#  |
# Für jede Tabelle einer Analyse eine verlinkende Spalte |
#
#
#
#
# Jeff Leek: The Elements of Data Analytic Style
#
#
# ### Nutze Data Science Standardwerkzeuge
#
# #### z. B. einen der populärsten Stacks
#
# * Jupyter Notebook
# * Python 3
# * pandas
# * matplotlib
# ### Jupyter Notebook
#
# **Interactive Notebook**
# * Dokumentenorientierte Analysen
# * Ausführbare Code-Blöcke
# * Ergebnisse direkt ersichtlich
# * Alles an einem Platz
# * Jeder Analyseschritt sichtbar
#
# => Neue Erkenntnisse verständlich herausarbeiten!
#
#
# ### Python 3
#
# **Eine beliebte Programmiersprache im Data Science**
# * Einfach
# * Effektiv
# * Schnell
# * Spaß
# * Automatisierung
#
# => Datenanalysen werden wiederholbar
# ### pandas
#
# **Pragmatisches Datenanalysewerkzeug**
# * Tabellenartige Datenstrukturen ("programmierbares Excel-Arbeitsblatt")
# * Sehr schnelle Berechnungen
# * Flexibel
# * Ausdrucksstarke API
#
# => Guter Integrationspunkt für Datenquellen!
# ### matplotlib
#
# **Progammierbare Visualisierungsbibliothek**
#
# * Pragmatische Erstellung von Grafiken
# * Diagramme wie Linien-, Balken-, XY-Diagramme und viele andere
# * Gut integriert mit pandas
#
# => Direkte Visualisierung der Diagramme / Ergebnisse!
# ### Das Python-Ökosystem
#
#
#
#
Data Analysis
#
# - NumPy
# - scikit-learn
# - TensorFlow
# - SciPy
# - PySpark
# - py2neo
#
#
#
#
Visualisierung und mehr
#
# - pygal
# - Bokeh
# - python-pptx
# - RISE
# - Requests, xmldataset, Selenium, Flask...
#
#
#
https://github.com/feststelltaste/software-analytics-workshop
# # Hands-On
# ### Einige Beispiele aus der Praxis
# * Vorhandenen Modularisierungsschnitt analysieren
# * Performance-Probleme in verteilten Systemen identifizieren
# * Potenzielle Wissensverluste ermitteln
# * Eingesetzte Open-Source-Projekte bewerten
# * ...
# ### Was sind Ihre Analysen aus der Praxis?
#  # ## Programmierbeispiel
# ### Fallbeispiel
#
# #### IntelliJ IDEA
#
# * IDE für Java-Entwickler
# * Fast komplett in Java geschrieben
# * Großes und lang aktives Projekt
# ### I. Fragestellung (1/3)
#
# * Schreibe die Frage explizit auf
# * Erkläre die Anayseidee verständlich
#
# ### I. Fragestellung (2/3)
#
# Frage
# * Welche Quellcodedateien sind besonders komplex und änderten sich in letzter Zeit häufig?
#
# ### I. Fragestellung (3/3)
# #### Umsetzungsideen
# * Werkzeuge: Jupyter, Python, pandas, matplotlib
# * Heuristiken:
# * "komplex": viele Quellcodezeilen
# * "ändert ... häufig": hohe Anzahl Commits
# * "in letzter Zeit": letzte 90 Tage
#
# **Meta-Ziel:** Grundmechaniken kennenlernen.
# ### II. Explorative Datenanalyse
# * Finde und lade mögliche Softwaredaten
# * Bereinige und filtere die Rohdaten
# *Wir laden einen Datenexport aus einem Git-Repository.*
# In[3]:
log = pd.read_csv("../datasets/git_log_intellij.csv.gz")
log.head()
# *Wir sehen uns Basisinfos über den Datensatz an.*
# In[4]:
log.info()
# 1 **DataFrame** (~ programmierbares Excel-Arbeitsblatt), 6 **Series** (= Spalten), 1128819 **entries** (= Reihen)
# *Wir wandeln die Zeitstempel von Texte in Objekte um.*
# In[5]:
log['timestamp'] = pd.to_datetime(log['timestamp'])
log.head()
# *Wir sehen uns nur die jüngsten Änderungen an.*
# In[6]:
# use log['timestamp'].max() instead of pd.Timedelta('today') to avoid outdated data in the future
recent = log[log['timestamp'] > log['timestamp'].max() - pd.Timedelta('90 days')]
recent.head()
# *Wir wollen nur Java-Code verwenden.*
# In[7]:
java = recent[recent['filename'].str.endswith(".java")].copy()
java.head()
# ### III. Formale Modellierung
#
# * Schaffe neue Sichten
# * Verschneide weitere Daten
# *Wir zählen die Anzahl der Änderungen je Datei.*
# In[8]:
changes = java.groupby('filename')[['sha']].count()
changes.head()
# *Wir holen Infos über die Code-Zeilen hinzu...*
# In[9]:
loc = pd.read_csv("../datasets/cloc_intellij.csv.gz", index_col=1)
loc.head()
# *...und verschneiden diese mit den vorhandenen Daten.*
# In[10]:
hotspots = changes.join(loc[['code']]).dropna(subset=['code'])
hotspots.head()
# ### VI. Interpretation
# * Erarbeite das Kernergebnis der Analyse heraus
# * Mache die zentrale Botschaft / neuen Erkenntnisse deutlich
# *Wir zeigen nur die TOP 10 Hotspots im Code an.*
# In[11]:
top10 = hotspots.sort_values(by="sha", ascending=False).head(10)
top10
# ### V. Kommunikation
# * Transformiere die Erkenntnisse in eine verständliche Visualisierung
# * Kommuniziere die nächsten Schritte nach der Analyse
# *Wir erzeugen ein XY-Diagramm aus der TOP 10 Liste.*
# In[12]:
ax = top10.plot.scatter('sha', 'code');
for k, v in top10.iterrows():
ax.annotate(k.split("/")[-1], v)
# ### Ende der Demo
# ## Weitere Analysebeispiele
#
# * Analyse der CPU-Auslastung mit Daten von `vmstat`
# * Abhängigkeitsanalyse mit Daten von `jdeps` und Visualisierung mit `D3`
# * Identifizierung von Modularisierungsoptionen basierend auf reinen Codeänderungen in `Git`
# * Analyse von Performance-Hotspots und Code-Smells mit `jQAssistant` / `Neo4j`
# ## Zusammenfassung
# **1.** Softwareanalysen mit Data-Science-Werkzeugen sind möglich
# **2.** Wer mehr will bekommt auch mehr!
# **3.** Es gibt unglaublich viele Quellen für Daten in der Softwareentwicklung
# => von der Frage über die Daten zur Erkenntnis!
# # Danke! Fragen?
#
# Markus Harrer
# ## Programmierbeispiel
# ### Fallbeispiel
#
# #### IntelliJ IDEA
#
# * IDE für Java-Entwickler
# * Fast komplett in Java geschrieben
# * Großes und lang aktives Projekt
# ### I. Fragestellung (1/3)
#
# * Schreibe die Frage explizit auf
# * Erkläre die Anayseidee verständlich
#
# ### I. Fragestellung (2/3)
#
# Frage
# * Welche Quellcodedateien sind besonders komplex und änderten sich in letzter Zeit häufig?
#
# ### I. Fragestellung (3/3)
# #### Umsetzungsideen
# * Werkzeuge: Jupyter, Python, pandas, matplotlib
# * Heuristiken:
# * "komplex": viele Quellcodezeilen
# * "ändert ... häufig": hohe Anzahl Commits
# * "in letzter Zeit": letzte 90 Tage
#
# **Meta-Ziel:** Grundmechaniken kennenlernen.
# ### II. Explorative Datenanalyse
# * Finde und lade mögliche Softwaredaten
# * Bereinige und filtere die Rohdaten
# *Wir laden einen Datenexport aus einem Git-Repository.*
# In[3]:
log = pd.read_csv("../datasets/git_log_intellij.csv.gz")
log.head()
# *Wir sehen uns Basisinfos über den Datensatz an.*
# In[4]:
log.info()
# 1 **DataFrame** (~ programmierbares Excel-Arbeitsblatt), 6 **Series** (= Spalten), 1128819 **entries** (= Reihen)
# *Wir wandeln die Zeitstempel von Texte in Objekte um.*
# In[5]:
log['timestamp'] = pd.to_datetime(log['timestamp'])
log.head()
# *Wir sehen uns nur die jüngsten Änderungen an.*
# In[6]:
# use log['timestamp'].max() instead of pd.Timedelta('today') to avoid outdated data in the future
recent = log[log['timestamp'] > log['timestamp'].max() - pd.Timedelta('90 days')]
recent.head()
# *Wir wollen nur Java-Code verwenden.*
# In[7]:
java = recent[recent['filename'].str.endswith(".java")].copy()
java.head()
# ### III. Formale Modellierung
#
# * Schaffe neue Sichten
# * Verschneide weitere Daten
# *Wir zählen die Anzahl der Änderungen je Datei.*
# In[8]:
changes = java.groupby('filename')[['sha']].count()
changes.head()
# *Wir holen Infos über die Code-Zeilen hinzu...*
# In[9]:
loc = pd.read_csv("../datasets/cloc_intellij.csv.gz", index_col=1)
loc.head()
# *...und verschneiden diese mit den vorhandenen Daten.*
# In[10]:
hotspots = changes.join(loc[['code']]).dropna(subset=['code'])
hotspots.head()
# ### VI. Interpretation
# * Erarbeite das Kernergebnis der Analyse heraus
# * Mache die zentrale Botschaft / neuen Erkenntnisse deutlich
# *Wir zeigen nur die TOP 10 Hotspots im Code an.*
# In[11]:
top10 = hotspots.sort_values(by="sha", ascending=False).head(10)
top10
# ### V. Kommunikation
# * Transformiere die Erkenntnisse in eine verständliche Visualisierung
# * Kommuniziere die nächsten Schritte nach der Analyse
# *Wir erzeugen ein XY-Diagramm aus der TOP 10 Liste.*
# In[12]:
ax = top10.plot.scatter('sha', 'code');
for k, v in top10.iterrows():
ax.annotate(k.split("/")[-1], v)
# ### Ende der Demo
# ## Weitere Analysebeispiele
#
# * Analyse der CPU-Auslastung mit Daten von `vmstat`
# * Abhängigkeitsanalyse mit Daten von `jdeps` und Visualisierung mit `D3`
# * Identifizierung von Modularisierungsoptionen basierend auf reinen Codeänderungen in `Git`
# * Analyse von Performance-Hotspots und Code-Smells mit `jQAssistant` / `Neo4j`
# ## Zusammenfassung
# **1.** Softwareanalysen mit Data-Science-Werkzeugen sind möglich
# **2.** Wer mehr will bekommt auch mehr!
# **3.** Es gibt unglaublich viele Quellen für Daten in der Softwareentwicklung
# => von der Frage über die Daten zur Erkenntnis!
# # Danke! Fragen?
#
# Markus Harrer
# innoQ Deutschland GmbH
#
# markus.harrer@innoq.com
#
# `@feststelltaste`
# # Weitere Ressourcen zum Workshop
# GitHub-Repository: https://git.io/Jelju
#
# Blog: https://feststelltaste.de
