#!/usr/bin/env python
# coding: utf-8
# # Guide to accessing and reviewing the bendit results
#
# Potentially, a lot of data can be generated when the demo pipeline is run, and steps were taken to make handling all that as easy as possible. However, accessing that collected data may not be obvious to the uninitiated. This notebook covers what the 'realistic' pipeline [here](index.ipynb) produces and how to access it. Furthermore, it touches on how to use Jupyter/Python to conveniently view and further process all the data.
#
# The hope is this covers what is necessary to use the generated output. Therefore, if you just plugged your sequences into the demo pipeline, you should be able to follow along to get the bendIt results for all you data. If you are looking to adapt the pipeline, this notebook will give you a flavor of the types of output you may wish to gather or not include your adapted bendIt pipeline.
#
# ### Navigating this Jupyter notebook page
#
# Because this notebook covers all the possible data types from the bendIt analysis run and various ways to access the information, it is rather long. To make it easier to navigate you can click on the 'Table of Contents' icon  on the left sidebar to bring up a table of contents in the left panel.
#
# You can get a sense of how to use the Table of Contents to navigate a notebook from the animation below, despite the fact the animation features another notebook.
#
#
#
#
# When you need to navigate the directory structure or access files in the file browser, switch back to the file browser by clicking on the 'folder' icon
# on the top of the left sidebar.
#
# ## Saving files or bundles of files from the session to local
#
# This notebook includes ways to make various files. You'll need to download those from this **temporary, remote session** to your local computer.
#
# To make this easier once you start to generate a lot of files, the ability to right-click on any directory in the file navigator and choose to save it as an archive has been added. It will resemble the following animation:
#
#
#
# For example, if you unpack the archive as instructed below you may end up making things in `unpack` and want that entire directory. Therefore in the file navigator panel on the left, you'd go to a point in the directory hierarchy above that `unpack` directory and right-click on it and choose `Download as an archive`. You can make a new directory any time using the 'New folder' icon above the left panel and then use drag and drop in the file navigator to move any files you want into it.
#
# The archive defaults to being `.gzip` format. You can alter that format if you'd prefer by going to the JupyterLab menu bar along the top of your browser window and selecting `Settings` > `Advanced Settings Editor`, and then selecting `Archive` in the `Settings` window that comes up in the main window. There you can edit the '
# `User Preferences` on the right to override the system default. For example maybe you'd prefer `tar.gz`, and so you'd edit the contents of `User Preferences` to be `{"format": "tar.gz"}`. Be sure to click on the disk icon in the upper right to save your new settings.
# ## Accessing the bendIt results: Starting up an active session
#
# If you already have an active Jupyter session going, you can skip this step.
#
# However, if you have a previously saved result from the demo pipeline and you are now returning to it and looking to access the contents of the archive, the best way to get started is to start a session by going [here](https://github.com/fomightez/bendit-binder) and clicking on the `launch bend.it` badge. When the session starts, select the `Accessing_and_reviewing_the_bendit_results.ipynb` notebook from the navigation panel at the right and work through the steps below this.
#
# The uncompressing step below should work on an unix-style command line. However, some of the advanced steps under the section entitled 'Using Python to review the data or customize the plots' involve modules/packages that aren't necessarily in a standard Python installation. By running in the recommended environment as directed above, the code is more likely to work without hiccups.
# ## Accessing the bendIt results: Uncompress the Archive
#
# This notebook assumes, you just ran the pipeline and are trying to access the results. There is then a number of files in the current directory beside the archive. To make things easier, I am going to suggest making a new directory with a simple name and then you could drag the archive into that folder and work there. To make things match witih the demo, I am going to write out those steps as commands, too. Feel free to run the cells or to do it by hand. If you make a different 'unpack' directory, you'll need to adjust things below accordingly.
#
# The exclamation marks in front of the shell commands, tells Jupyter to run those commands as shell commands and not Python.
# In[1]:
get_ipython().system('mkdir unpack')
get_ipython().system('mv bendit_analysis*.tar.gz unpack/')
# To make things in this notebook work, you'll need to switch the current working directory over to where we are going to unpack the archive. We'll use the Jupyter magic command `%cd` to change the working directory for all subsequent cells in the notebook. If we just used `!cd`, it would only change the directory for that cell.
# In[2]:
get_ipython().run_line_magic('cd', 'unpack')
# Note you can check anytime what is the current working directory with `pwd`. (Note most shell commands need an exclamation point but a few were added in to Jupyter so they work without it and `pwd` is one.) Also of note, is that this location is completely independent of where the file navigation pane on the left side of this window may be showing.
# In[3]:
pwd
# To **unpack the archive**, we'll run the command in the following cell.
# You need to edit the command so it will extract your file. In other words, the part after the `xzf` has to be changed to match the actual file name of the archive you are working with in particular. To make it easier you should be able to click after the default code in the cell below and hit `Tab` button on your keyboard and Jupyter will auto-complete the file name for you after a slight pause.
#
# (Note that I am keeping this untarring step as generic as possible so that it would work as written on any unix-style command line without the exclamation point.)
# In[4]:
get_ipython().system('tar xzf bendit_analysis')
# If you ran the above cell and saw anything like `tar (child): bendit_analysisZZZZZZZZZ.tar.gz: Cannot open: No such file or directory` (where `ZZZZZZZZZ` is used to represent the date time stamp), it simply means you had the file name wrong. You'll need to edit it and run the cell again.
#
# If things worked, you should just see the asterisk to the left of the cell turn to a number. If you changed the file navigation pane on the left-side of this browser window over to the 'unpack' directory, after a moment you should see more files show up in the file pane. Don't worry if you didn't switch. We are going to explore the contents using commands next anyways.
# ## Overview of the Unpacked Items
#
# If all is correct and you used the `%cd` command to previously switch to the 'unpack directory, running the next cell will show the contents of the current working directory so we can begin to explore the contents of the-now-unpacked archive.
# In[6]:
ls -lh
# That lists out the contents of the directory. The options added along with the `ls` command make the output more redable by showing. In particular, the `h` in `-lh` means the file sizes are human readable and the `l` in `-lh` says to list the details in long form and not just the names.
#
# You'll see there is much more than the compressed archive that was originally added when we made the directory just a few cells back. These are the results of the bendIt run. The following section will go through what these are and how to use them.
#
# ----
# ## About the Contents
# If you used your own data, your results will be different but the types will be the same. I am going describe the contents as if you ran the demo sequences; however, mostly you just need to pay attention to the file extensions, or sometimes the start of the name, to tell which file types correspond.
#
# After a brief overview, I am going to add some details about most of the types.
# Typical contents overview:
#
# - Log file
# - Image files for the plots
# - a Jupyter notebook for reviewing all the plots en masse
# - serialized (pickeled) bendIt data
# - bendIt data as tabular text
# - Nucleotide composition detail
# - serialized processing information and results on a per sample basis
# - input files
# - raw gnuplots
#
# ### Log file
#
# The Log file will look something like `LOG_baZZZZZZZZZ.txt` with the `` showing the abbreviation for the month and the `ZZZZZZZZ` portion being derived from a time date stamp.
#
# This contains much of what was shown as the demo pipeline ran with some additional details from the actualy bendIt job(s) for each sequence.
#
# At the end is a summary. *When `lightweight_archive` is true, only the summary is in the Log file.*
# ### Image files for the plots
#
# The plots have been saved a two forms of images. The first part of the name of each is derived from the sample_set name and the individual sample name. The two extensions delineate them:
#
# - `.png`
# Examples from the demo input `demo_A.png` and `demo_B.png`.
# This is a raster/bitmap file format made of pixels that you are probably familair with. While it is great for viewing easily as a lot of software, including JupyterLab, can handle it, please see the note below suggesting `.svg` for scaling up, or the Python section that discusess making individual plots larger and making new image files in `.png` format from that.
#
# - `.svg`
# Examples from the demo input `demo_A.svg` and `demo_B.svg`.
# This indicates SVG (scalable vector grpahics) file format. SVG is really the best choice for scaling up or adapting further as it offers the most control and no less of resolution. Sugggest using Adobe Illustrator or Inkscape for scaling and customizing. This is what you'll want to use if you don't want to remake the plot and are looking to customize it for publication. Any modern browser can view `.svg` files, and fortunately an SVG viewer is built right into JupyterLab.
#
# When `lightweight_archive` or `lightweight_with_images` is true, these image files are not saved as part of the archive. In that case, you'll want to see sections below to make the image files 'after-the-fact' from the tables of data for each sequence.
# ### Jupyter notebook for reviewing all the plots en masse
#
# The file name for this file will resemble `plots4review_from-baZZZZZZZZ.ipynb` with the time data stamp matching the arhive file name and log file name.
#
# The image files dsicussed above are nice but not that easy to view unless you bring them local and use your file browser. Alternatively, you can browser them right in the session by opening this notebook and then opening subsequent views of it. (**ADD MORE DETAILS ON HOW TO OPEN MULTIPLE VIEW AND ADD IMAGE EXAMPLE**)
#
# At the top of this notebook, I emphasized you'll want to be in an active notebook session for working with the output. One of the main reasons is that it offers a standard environment where the archive can be unpacked easily and Jupyter offers nice viewers for many of the data types. This is the case for the 'Review' notebook. The plots are already part of the notebook, and so nothing has be run again, but a Jupyter environment is useful for viewing it. Alternatively, nbviewer can be used to view a 'static' from of the notebook if you don't mind placing the notebook file somewhere [the online nbviewer](https://nbviewer.jupyter.org/) can be pointed at it. Note the static form will look much like it does in Jupyter but you cannot modify or run any cells, or modify the text content further.
#
# Keep in mind for sharing this notebook with anyone not fluent in Jupyter notebook use, you can use `File` > `Export Notebook As..` > `Export Notebook to PDF` to also generate a PDF and then download that file as well.
#
# Note that the sample names on the plots should look like the original input sample names but might not match sample names seen in the 'serialized processing information and results on a per sample basis' file, `seqs_dfs_and_plots_for_each_set.pkl`. This is because certain characters can an issue with the processing steps and were eliminated from the sample names for processing. In the plot representations, efforts were made to substitute back in names matching a pattern used by a user.
#
# When `lightweight_archive` or `lightweight_with_images` is true, the Jupyter notebook displaying all the plots is not saved as part of the archive. In case of that there are several options on how to access similar content. The one I suggested in the Jupyter notbeook running the demonstation pipeline was to save the notebook or export a PDF of the notebook to your local computer. However, using the contents of `seqs_dfs_and_plots_for_each_set.pkl` this notebook could be made after-the-fact. That is described in the section 'Making the review Jupyter notebook after-the-fact' as part 'Using Python to review the data or customize the plots' below.
# ### Serialized (pickled) bendIt data
#
# This will resemble files looking like `demo_A.pkl`.
#
# The data plotted from the bendIt analysis is stored in a compressed form that can easily be read back in as a Pandas dataframe for convenient use in the Jupyter environment or further analysis. Acessing these Pandas dataframes in the Jupter environment will be discussed below as part of the 'Using Python to review the data or customize the plots' section.
# ### bendIt data as tabular text
#
# This will resemble files looking like `demo_A.tsv`.
#
# The data plotted from tbe bendIt analysis is stored in a tab-delimited tabular text form that can easily be used in standard spreadsheets, such as Excel or Google sheets. Jupyter allows easy viewing of these as well. You can click on the 'frame' symbol next to the file name in the file navigto panel on the left, and they'll open as full-featured spreadsheet-like views. If you right click, and select `Open with ...` > `editor`, you can see the text form that underlies it.
#
# ### Nucleotide composition detail
#
# These files will look like sample set names followed by `_cassettesGC.pkl` and `_cassettesGC.tsv` for the cassette sequences and sample set names followed by `_mergedGC.pkl` and `_mergedGC.tsv for the sequences of the combined cassette sequences merged with the defined flanking sequences.
#
# The examples from the demonstration data are:
#
# - `demo_cassettesGC.pkl`
# - `demo_cassettesGC.tsv`
# - `demo_mergedGC.pkl`
# - `demo_mergedGC.tsv`
#
# These provide a breakdown of nucleotide composition and %G+C for every cassette sequence. In the serilaized (pickeled) data, it is dataframe with each sample as a row. In the tabular text data, it is a tab-separated file with each sample as a row. The rank of %G+C from lowest to highest is the final column.
#
# Similar data is provided for every merged sequence where cassette flanked by the defined sequences.
#
# Accessing the tabular text is similar to what is described under 'bendIt data as tabular text'.
#
# Accessing the serialized Pandas dataframes in the Jupter environemnt will be discussed below as part of the 'Using Python to review the data or customize the plots' section.
#
# The source dataframes are also included in the 'serialized processing information and results on a per sample basis' file, `seqs_dfs_and_plots_for_each_set.pkl`.
# ### Serialized processing information and results on a per sample basis
#
# This file will be named `seqs_dfs_and_plots_for_each_set.pkl`.
#
# This is almost all the input sequences and output stored on a per sample set and per sample basis using Pyton dictionaries. This is mainly meant for advanced use. It actually gets used in the top of the `Notebook for reviewing all the plots en masse` to render all the plots. It will be used to access the dataframes as well as an example below. Really beyond being used to easily render all the plots, it is really just there to have it in case something not collected here is necessary or needs to be checked.
#
# In the `seqs_dfs_and_plots_for_each_set.pkl`, there is a value for each sample set. That value is a list of dictionaries, or in two cases a dataframe. The order of the items for each sample set are as follows:
#
# - cassette sequences processed keyed on name
# - sequences of the cassette sequences merged to the defined flanking sequences processed keyed on name
# - breakdown of nucleotide composition and %G+C for every cassette sequence (dataframe with each sample as a row)
# - breakdown of nucleotide composition and %G+C for every merged sequence where cassette flanked by the defined sequences (dataframe with each sample as a row)
# - dataframes produced by bendIt analysis & used to make the plots keyed by sample
# - plots as Python objects produced from each dataframe keyed by sample (**not saved in 'lightweight' settings**)
#
# As the information is stored serialized (pickled), it has to be unpickled first. The following code can be used to do unpickle and bring it into an active Jupyter notebook namespace:
#
# ```python
# import pickle
# with open("seqs_dfs_and_plots_for_each_set.pkl", "rb") as f:
# seqs_dfs_and_plots_per_sample_set = pickle.load(f)
# ```
#
# You'll note that this code gets used in the notebook for reviewing the plots en masse as it is from this source that the plots were added to the review notebook.
#
# ### Input files
#
# The sequence files of the cassette sequences were stored in FASTA format in the archive as well in order to provide a more an intact artifact of all stages of the run.
#
# As they are in FASTA format, they'll most likely end in `.fa` or `.fasta`.
#
# The input files may also exist in sanitized and unsanitized form if the sample names included characters that would have caused issues in the processing steps.
#
# ### Raw gnuplots
#
# These files will look like sample names followed by `_output.png`.
#
# The raw gnuplots made by bendIt for each sample are saved depending on the setting of `include_gnuplots`, which is moot in case `lightweight_archive` is `True`. If `lightweight_archive` is set to true, or if `include_gnuplots` is `False` in the case where `lightweight_archive` is not true, these 'raw' gnuplots won't be included in the archive.
#
# Overall these should resemble the plots generated for each cassette merged into the flanking sequences analyzed and are only meant for verification of that and troubleshooting. Keep in mind that for short sequences, the right side of the gnuplot will not represent the correct form as extra sequences were added to avoid a segmentation fault when bendIt was run.
# ----
#
#
# ----
#
# ## Using Python to review the data or customize the plots
#
# A number of options readily exist for using and further processing the unpacked data. This section illustrates some of those. A good portion at the end focuses on accessing the data in the 'serialized processing information and results on a per sample basis' file, `seqs_dfs_and_plots_for_each_set.pkl`. That portion is probably best considered 'advanced' as it requires more understanding of Python syntax to fully understand what is going. Most of the other examples only require name changes to get to data.
#
# ----
#
# ### Viewing dataframes for the plotted data
#
# While JupyterLab adds big improvements for viewing the CSVs/TSVs derived from (or which can be the source of) such dataframes, viewing and handling the dataframes within Jupyter is going to come up. Jupyter is particularly good at rendering Pandas dataframes nicely.
#
# This section will describe accessing the serialized (pickled) bendIt data in files looking like `demo_A.pkl`. This is mainly to serves as an introduction to illustrate the process and handling dataframes.
#
# If you are looking to use the bendIt data that is actually plotted elsewhere, you'd probably want what is described above as 'bendIt data as tabular text' which is in the files looking like `demo_A.tsv`. Where there sample set and sample names are in te file. The dataframe form is nice if you are continuing on with using Python to examine.
#
# Let's illustrate viewing a dataframe in Jupyter by bringing the serialized form in.
#
# It would be fairly easy to bring in the TSV form to a dataframe as well, but the serialized just needs to be read in at this point.
#
# As the command shows in the next cell, we can just put the file name of the serialized dataframe in a command like `df = df.read_pickle('demo_A.pkl')` where you'd replace `demo_A.pkl` with your file name of interest.
# In[7]:
import pandas as pd
df = pd.read_pickle('demo_A.pkl')
# To view a representation of the dataframe, we can call it now since we defined it as `df` above:
# In[8]:
df
# We could just look at the top.
# In[17]:
df.head()
# Or look at the end:
# In[18]:
df.tail()
# Or easily view an overview of the data contents.
# In[19]:
df.describe()
# I include a more detailed introduction to dataframes [here](https://nbviewer.jupyter.org/github/fomightez/blast-binder/blob/master/notebooks/BLAST%20on%20Command%20Line%20and%20Integrating%20with%20Python.ipynb#Demonstrating-the-Utility-of-Having-the-BLAST-Results-in-Python) and [here](https://nbviewer.jupyter.org/github/fomightez/ptmbr-accompmatz/blob/master/notebooks/PatMatch%20with%20Python%20basics.ipynb#Demonstrating-the-Utility-of-Having-the-PatMatch-Data-in-Python).
# ----
#
# ### Understanding sample names and how serialized information keyed
#
# This section will introduce accessing the contents in the 'serialized processing information, `seqs_dfs_and_plots_for_each_set.pkl` on a per sample basis to get a sense of how the infromation is keyed.
#
# The next cell unpickles the `seqs_dfs_and_plots_for_each_set.pkl` as described under the 'Serialized processing information and results on a per sample basis' section.
# In[ ]:
import pickle
with open("seqs_dfs_and_plots_for_each_set.pkl", "rb") as f:
seqs_dfs_and_plots_per_sample_set = pickle.load(f)
# The sample set labels are the overarching keys in this collection.
# In[ ]:
seqs_dfs_and_plots_per_sample_set.keys()
# There is only one sample set in the demonstration set as there is only one sequence file. The name of that sample set is `demo` for the demonstration sequence file.
#
# As described under the section 'Serialized processing information and results on a per sample basis', there are several items for each sample and for all except two, those items are further keyed on a per sample basis. (The '%G+C brekadown' dataframes don't have further 'keyed' contents per se, but they have each sample as a row.) For example, the first listed item is 'cassette sequences processed keyed on name'. And so to access that item, we'd use the following:
# In[ ]:
seqs_dfs_and_plots_per_sample_set['demo'][0]
# The zero in the brackets at the end specifies the first item in Python since the language is zero-indexed. In other words, the first item in a list in Python is referenced by the index 'zero'; whereas, it is generally common to number the first item as 'one'.
#
# That first item is actually a dictionary of keys and corresponding values. The dictionary keys are the sample names as can be see by listing the keys using the folllwing code:
# In[ ]:
seqs_dfs_and_plots_per_sample_set['demo'][-1].keys()
# We see the labels for sample sequences 'A' and 'B' that were present in `demo_sample_set.fa`.
#
# If we want to see the corresponding value, which in the case of this dictinary is a nucleotide sequence, we can use a particular key to access it. For example:
# In[ ]:
seqs_dfs_and_plots_per_sample_set['demo'][-1]['B']
# Using that code, the output of that cell above shows the cassette sequence corresponding to sample sequence 'B'.
#
# Note when you see the sample names, there is a chance they may not correspond to the specific text you specified in your FASTA file. This is because certain characters, such as `|` along with parantheses and slashes don't play well with processing approach used here, and so if the text for the sample names contained those in the FASTA description, they have been sanitized to avoid issues. (Note for a certain pattern of labels, the names are corrected in the displayed plot titles.)
#
# We'll use similar approaches below to access some of the other items that are stored for each sample set. For example, in the sub-section 'Accessing the nucleotide composition/%G+C information via Python', we'll see `seqs_dfs_and_plots_per_sample_set['demo'][2]` used to access the third item in the serialized data, which is the dataframe with a breakdown of the nucleotide composition and the %G+C of the cassette sequences.
# ### Looking at specific plot and adjusting the plots via Python
#
# If you used the lightweight setting and want to generate image files for all the plots, see 'Generate image files for all plots via Python' below. This section is meant for when you are just interested in the image files for a few plots.
#
# If you are looking to scale or edit just a few of the plots, I suggest you use the `.svg` file with the images as scaleable vector graphics.
#
# However, maybe you used the `lightweight_archive` setting previously and want to generate images from the plots now or you want to make the plots larger. This section will illustrate accessing the contents in the 'serialized processing information and results on a per sample basis' file, `seqs_dfs_and_plots_for_each_set.pkl` to bring the plots back into the session here so image files can be saved or the image dimensions altered.
#
# The next cell unpickles the `seqs_dfs_and_plots_for_each_set.pkl` as described under the 'Serialized processing information and results on a per sample basis' section.
# In[5]:
import pickle
with open("seqs_dfs_and_plots_for_each_set.pkl", "rb") as f:
seqs_dfs_and_plots_per_sample_set = pickle.load(f)
# The sample set is the first key in this collection. That is `demo` for the demonstration sequence file.
#
# See the sub-section entitled 'Understanding sample names and how serialized information keyed' above. for more information on that
# As described under the section 'Serialized processing information and results on a per sample basis', the plots are the last item in the serialized collection. As the last item it can be accessed using a special shortcut to indicate the last item ,`-1`. And so to access the plot collection for the demo set the code is:
# In[6]:
seqs_dfs_and_plots_per_sample_set['demo'][-1]
# The cryptic code, ``, after each sample name identifies a Python object. In this case a figure of particular size.
#
# *Note: If instead of something that looks like that, you see the text 'saving serialized Python plot object scrubbed due to \`lightweight\` setting', it means one of the 'lightweight' settings was used, and so the individual plots as Python objects weren't stored in serial form. The plots can still be generated from contents of the archive; you'll want to to see the section below about generating the plot images from data.*
#
# Normally we could call one of them with the following to display it for sample sequence 'A':
# In[19]:
seqs_dfs_and_plots_per_sample_set['demo'][-1]['A']
# However, it it will be represented by Python object code and not a display of the plot. While it might some convoluted, the issue is that the canvas that Jupyter would display here was lost when the underlying data associated with it was serialized in the source notebook. We can make a 'dummy' canvas and swap in the underlying plot data, see [here](https://gist.github.com/demisjohn/883295cdba36acbb71e4#gistcomment-3177271).
# In[7]:
get_ipython().run_line_magic('matplotlib', 'inline')
import matplotlib.pyplot as plt
def make_manager(fig):
# create a dummy figure and use its
# manager to display "fig" ; based on https://stackoverflow.com/a/54579616/8508004
dummy = plt.figure()
new_manager = dummy.canvas.manager
new_manager.canvas.figure = fig
fig.set_canvas(new_manager.canvas)
plot_a = seqs_dfs_and_plots_per_sample_set['demo'][-1]['A']
make_manager(plot_a)
plot_a.show()
# We can now refer to it from this point on as `plot_a`.
# In[8]:
plot_a
# Using that reference we can now save it just as any matplotlib/seaborn plot.
# In[16]:
plot_a.savefig("znew_image_saved.svg")
# You can go to the file navigator at the left and double-click `znew_image_saved.svgznew_image_saved.svg` down at the bottom of the file list to view it.
#
# Or make a cell here using the `+` symbol on the menu toolbar above and run this code to see it here:
#
# ```python
# from IPython.core.display import SVG
# SVG(filename='znew_image_saved.svg')
# ```
# What if we wanted to adjust size. The next cell does this on a exaggerated scale just to illustrate.
# In[9]:
plot_a.set_size_inches((18, 10))
plot_a
# In fact, in JupyterLab it won't be readily apparent just how large it is. You'll need to double-click on it to open it at 100% scale.
#
# You'll note though that the lines didn't scale. The blue and the orange plots of the data are the same thickness as when the plot was smaller and now seem anemic. This is one of the reasons I suggest using a vector graphics handling-capable image editing software like Inkscape or Adobe Illustrator to scale up the `.svg` files if you need larger images of the plots. You can then easily scale all parts in proportion. To do this using Python is possible. For example, to make the blue and orane lines less anemic:
# In[10]:
#scale linewidth up based on https://stackoverflow.com/a/48547567/8508004
lines = plot_a.axes[0].lines #getting axes from a figure based on https://stackoverflow.com/a/24107230/8508004 ;
# note that it is a list of them and what we want is in the first
for line in lines:
line.set_linewidth(4)
plot_a
# However, then you would probably also want to scale the tick labels, the title, the legend, etc.. And at this point you'd probably have an easier time of going back to the data that is being plotted and plot the many you need at a larger size or dimension. Or scale the SVG [by using a command line tool](http://www.imagemagick.org/discourse-server/viewtopic.php?t=23979).
#
# I'll show how easy it is to go back to the original data that is being plotted and take advatange of the ease in [controlling seaborn aesthetics](https://seaborn.pydata.org/tutorial/aesthetics.html). The code for plotting is in the `bendit_standalone_results_to_df.py` code [here](https://github.com/fomightez/sequencework/blob/master/bendit_standalone-utilities/bendit_standalone_results_to_df.py) between where it says the following:
#
# ```
# # Plot the reported data
# #----------------------------------------------------------------------#
# ...
# # CLEAN UP:
# #----------------------------------------------------------------------#
# ````
#
# The three dots line is to reprsent the plotting code. Additionally, things can be boiled down further to the code in the next cell because we don't need the comments included in the full version and in this example `report_with_curvature == "bendability"` and `smooth_plot_curves == True`. The first two lines use code we discussed above under 'Viewing dataframes for the plotted data' to bring the demo_adataframe into memory.
#
# Note the addition of `sns.set_context("talk")` and altering of `fig, ax1 = plt.subplots(figsize=(8,4))` to `fig, ax1 = plt.subplots(figsize=(12,6))` to control the size and scaling of aspects. (Note that a good portion of this code is to handle a special case where want to accomodate `show_date_with_slashes_in_plot_title`.)
# In[12]:
import pandas as pd
df = pd.read_pickle('demo_A.pkl')
sample_name = "A"
import seaborn as sns
sns.set()
sns.set_context("talk")
sns.set_style("whitegrid")
import matplotlib.pyplot as plt
fig, ax1 = plt.subplots(figsize=(12,6))
import numpy as np
from scipy.interpolate import Akima1DInterpolator
akima1 = Akima1DInterpolator(df.Position, df.Predicted_curvature)
akima2 = Akima1DInterpolator(df.Position, df.Bendability)
x_4smooth = np.linspace(
min(df.Position), max(df.Position), round(len(df)*14.492753))
sns.lineplot(x=x_4smooth,
y=akima1(x_4smooth),
label="Curvature",
#linewidth=1.9, # turn these off so scales with content settings
color="xkcd:cerulean",
ax=ax1)
sns.lineplot(x=x_4smooth,
y=akima2(x_4smooth),
label="Bendability",
#linewidth=1.9, # turn these off so scales with content settings
color="xkcd:orange",
ax=ax1)
plt.legend()
plt.ylabel("");
right_side_buffer = 0
plt.xlim(0, max(df.Position) + min(df.Position))
show_date_with_slashes_in_plot_title = True
if show_date_with_slashes_in_plot_title and (
sample_name.count("_") == 2) and (
sample_name.split("_")[1].split("_")[0].count("-") == 2) and (
sample_name.split("_",2)[2].count("+") == 2) and (
sample_name.endswith("+")):
title_text = sample_name.split(
"_")[0]+"|" + sample_name.split("_")[1].replace(
"-","/") +"|" + sample_name.split("_",2)[2]
if title_text.endswith("+") and "+" in title_text[:-1]:
title_text = title_text[:-1] + ")"
title_text = title_text.replace("+","(")
else:
title_text = sample_name
plt.title(f"{title_text}",color="#333333",fontsize = 15,
fontweight='bold')
plt.show()
# (Note there is also at `sns.set_context("poster")` setting that results in even further emphasized labels. I found though with the dimesions I was usign here it that the legend overlapped and so I went with `talk`.)
# Now let's save that plot as an image file. Run the next two cells. The first saves a version with a high dpi and the second saves with default settings. I include `z` at the start of the name to improve the chance they are eaier to find in the listing in the file navigator bcause they should be towards the bottom.
# In[28]:
fig.savefig('zhigh_dpi.png', dpi=600)
# In[32]:
fig.savefig('zno_dpi.png')
# Now you can review the difference between the two by double-clicking on the files in the file navigator to the left. (Remember you have to navigate into the `unpack` directory if not already there.) When you open `zhigh_dpi.png` it actually **might appear at first it is blank**. In fact most likely it will because you need to click on it and scroll down and to the right to see the contents. By default it starts in the upper left which has no content. You'll note for `zhigh_dpi.png`, the content is huge on your screen. That won't be the case with `zno_dpi.png`. To make it easier to review `zhigh_dpi.png` overall, I suggest left-clicking in the image open in JupyterLab and select `Open Image in New Tab`. You then get a new tab next to your JupyterLab tab that you can click on and view. It will actually take a few seconds to open this image in the tab because it is so large. When you postion the cursor over the image, you'll get a magnifying lens icon. You can click to view at higher resolution. Again, here you'll need to scroll.
#
# By way of showing the effect of the dpi setting here, I'll list the files with the sizes shown using the next cell:
# In[33]:
ls -lh
# Note the contrast:
#
# ```
# -rw-r--r-- 1 jovyan root 725K Feb 22 21:49 zhigh_dpi.png
# -rw-r--r-- 1 jovyan root 61K Feb 22 21:57 zno_dpi.png
# ```
#
# The one with the dpi setting of `600` is over 10 times larger. While this type of file would be better suited for a talk or poster or publication, I am still going to suggest use of the `.svg` version for any scaling and printing use.
#
# If you wanted the current seaborn aestethic setting for editing later, you can save a scalable vector graphics version (`.svg`) with the following code:
# In[34]:
fig.savefig('zsvg_version.svg')
# -----
#
# ### Making the review Jupyter notebook after-the-fact
#
# In the case where the `lightweight_archive` setting was used when the generating notebook was run, the new notebook that is meant to be used for reviewing the plots en masse was not generated and this not saved as part of the archive. However, using the contents of `seqs_dfs_and_plots_for_each_set.pkl` this notebook can still be made after-the-fact.
#
# I'll detail two ways to do this. Both rely on the same underlying steps. However, in one you just run some code here and it is done. Alternatively, you run the steps in a new notebook yourself.
#
#
# First, I'll cover running code to generate the review notebook. **You need to be in the working directory where you unpacked the archive**. Running the next cell will list the contents of your current working directory. Mare sure it looks as exepected.
# In[ ]:
get_ipython().system('pwd|ls')
# If it doesn't contain the unpacked contents of the archive as expected, see the section at the top of this notebook entitled 'Accessing the bendIt results: Uncompress the Archive'.
#
# Now that you verified you are working in the right place, let's generate the review notebook my running part of the code from the analysis. The following code will do this:
# In[ ]:
# First let's make sure the analysis script is in the current working directory
import os
file_needed = "bendIt_analysis.ipy"
if not os.path.isfile(file_needed):
# note that in the curl command I refer to a specific version of the script
# to eliminate possibility line numbers drift slightly as script edited.
# However,this means if something about review notebook making changes in
# the script, I need to update the specified version here.
get_ipython().system('curl -OL https://raw.githubusercontent.com/fomightez/bendit-binder/0096dab481a267dea5640bfe4323c75148faabc7/{file_needed}')
# presently bendIt_analysis.ipy is an IPython script that doesn't seem able to
# be imported like a Python script, see
# https://stackoverflow.com/questions/1031659/ipython-modules . Let's make the
# necessary parts into a smaller script that can be called because we certainly
# don't want to run the entire `bendIt_analysis.ipy` script since already did.
get_ipython().system("sed -n '1,48p;49q' bendIt_analysis.ipy > review_nb_making.ipy")
get_ipython().system("sed -n '337,383p;384q' bendIt_analysis.ipy >> review_nb_making.ipy")
get_ipython().system("sed -n '269,289p;290q' bendIt_analysis.ipy >> review_nb_making.ipy")
get_ipython().system("sed -i '103s/.*/ #/' review_nb_making.ipy # remove line 103 b/c no log")
get_ipython().run_line_magic('run', 'review_nb_making.ipy')
now = datetime.datetime.now()
serial_fn = "seqs_dfs_and_plots_for_each_set.pkl"
plots4review_fn = make_and_run_review_nb(now,review_nb_stub, serial_fn)
get_ipython().system('rm {plots4review_fn[:-6]+".py"} #clean up')
get_ipython().system('rm review_nb_making.ipy #clean up')
sys.stderr.write("A Jupyter notebook listing the resulting plots for "
f"convenient reviewing\nhas been saved as `{plots4review_fn}`."
"Download it to your local computer for future use.")
# The second way to make the notebook for review is doing those steps manually:
# 1. Navigate the file browser to the directory where the archive contents were unpacked if it isn't already.
#
# 2. make a new notebook by clicking the  icon along the top of the right panel ot bring up the 'Launcher' in the right pane and then under 'Notebook' choose the 'Python 3' tile. Alternatively, a new notebook can be made from the main menu bar at the tip: `File` menu > 'New' > `Notebook`.
# 3. Paste the following code in a cell in the new notebook.
# ```python
# %matplotlib inline
# import pickle
# serial_fn = "seqs_dfs_and_plots_for_each_set.pkl"
# with open(serial_fn, "rb") as f:
# seqs_dfs_and_plots_per_sample_set = pickle.load(f)
# def make_manager(fig):
# # create a dummy figure and use its
# # manager to display "fig" ; based on https://stackoverflow.com/a/54579616/8508004
# dummy = plt.figure()
# new_manager = dummy.canvas.manager
# new_manager.canvas.figure = fig
# fig.set_canvas(new_manager.canvas)
# import seaborn as sns
# import matplotlib.pyplot as plt
# for ss,collected_dicts in seqs_dfs_and_plots_per_sample_set.items():
# for sample_name,the_plot in collected_dicts[-1].items():
# make_manager(the_plot)
# the_plot.show()
# ````
# Then press `shift-Enter` to run the cell. Save the notebook using `File` > `Save Notebook`. Download the notebook to your local machine.
# Keep in mind for sharing the produced notebook with anyone not fluent in Jupyter notebook use, you can use `File` > `Export Notebook As..` > `Export Notebook to PDF` to also generate a PDF and then download that file as well.
# ### Generate image files for all plots via Python
#
# In the case where the `lightweight_archive` setting was used when the generating notebook was run, the archive won't contain the image files. The subsection 'Looking at specific plot and adjusting the plots via Python' above covered how to access individual image files. If you want to generate image files for them all. You can run the following code. By placing a `#` at the start of the line, you can comment off the appropriate lines that begin `ea_plot.savefig` you can control if just want the `.svg` or `.png` versions. The current working directory has to contain the unpacked `seqs_dfs_and_plots_for_each_set.pkl`. (The `%%capture`on the first line simply blocks the plots from being output in Jupyter output here.)
# In[3]:
get_ipython().run_cell_magic('capture', '', 'import pickle\nimport os\nwith open("seqs_dfs_and_plots_for_each_set.pkl", "rb") as f:\n seqs_dfs_and_plots_per_sample_set = pickle.load(f)\nimport matplotlib.pyplot as plt\ndef make_manager(fig):\n # create a dummy figure and use its\n # manager to display "fig" ; based on https://stackoverflow.com/a/54579616/8508004\n dummy = plt.figure()\n new_manager = dummy.canvas.manager\n new_manager.canvas.figure = fig\n fig.set_canvas(new_manager.canvas)\n\nfor sample_set,dicts in seqs_dfs_and_plots_per_sample_set.items():\n for sample_id,ea_plot in dicts[-1].items():\n prefix_4_plot_file_saves = f"{sample_set}_{sample_id}"\n plot_png_nom = f"{prefix_4_plot_file_saves}.png"\n plot_svg_nom = f"{prefix_4_plot_file_saves}.svg"\n file_needed = plot_png_nom\n if not os.path.isfile(file_needed):\n if ea_plot == None:\n make_manager(ea_plot)\n ea_plot.savefig(plot_png_nom) #comment this line \'off\' to not make `.png` images\n file_needed = plot_svg_nom\n if not os.path.isfile(file_needed):\n if ea_plot == None:\n make_manager(ea_plot)\n ea_plot.savefig(plot_svg_nom) #comment this line \'off\' to not make `.svg` images\n ea_plot = None\n')
# ----
#
# ### Accessing the nucleotide composition/%G+C information via Python
#
# Run the unpickling process if not done already.
# In[ ]:
import pickle
with open("seqs_dfs_and_plots_for_each_set.pkl", "rb") as f:
seqs_dfs_and_plots_per_sample_set = pickle.load(f)
# Here is the third element in the serialized collection, which is a dataframe with the breakdown of nucleotide composition and %G+C for every cassette sequence. Each sample is a row.
# In[14]:
seqs_dfs_and_plots_per_sample_set['demo'][2]
# Here is the fourthelement in the serialized collection, which is a dataframe with the breakdown of nucleotide composition and %G+C for every sequence where the cassette sequence has been merged with the defined flanking sequenes. Each sample is a row.
# In[15]:
seqs_dfs_and_plots_per_sample_set['demo'][3]
# -----
#
# -----
#
# Enjoy.
 #
# When you need to navigate the directory structure or access files in the file browser, switch back to the file browser by clicking on the 'folder' icon
# on the top of the left sidebar.
#
# ## Saving files or bundles of files from the session to local
#
# This notebook includes ways to make various files. You'll need to download those from this **temporary, remote session** to your local computer.
#
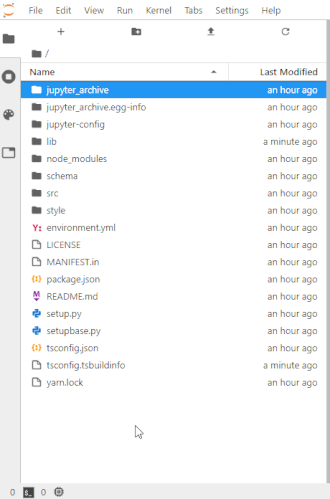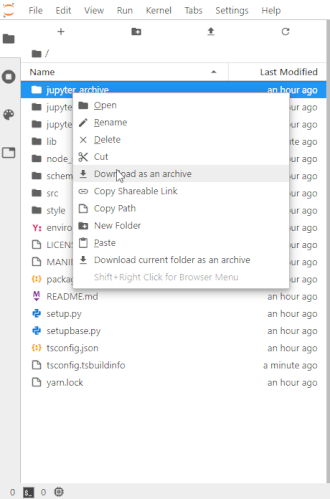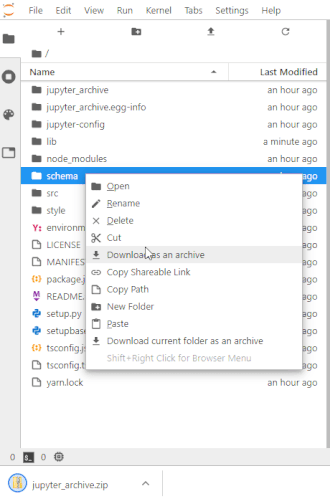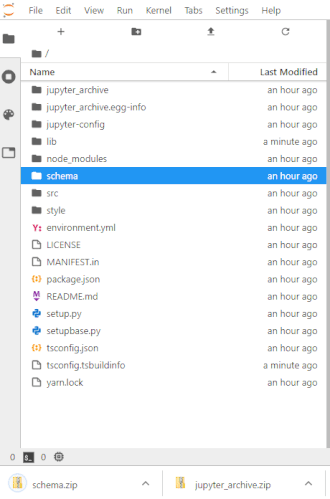
# To make this easier once you start to generate a lot of files, the ability to right-click on any directory in the file navigator and choose to save it as an archive has been added. It will resemble the following animation:
#
#
#
# When you need to navigate the directory structure or access files in the file browser, switch back to the file browser by clicking on the 'folder' icon
# on the top of the left sidebar.
#
# ## Saving files or bundles of files from the session to local
#
# This notebook includes ways to make various files. You'll need to download those from this **temporary, remote session** to your local computer.
#
# To make this easier once you start to generate a lot of files, the ability to right-click on any directory in the file navigator and choose to save it as an archive has been added. It will resemble the following animation:
#
#  #
# For example, if you unpack the archive as instructed below you may end up making things in `unpack` and want that entire directory. Therefore in the file navigator panel on the left, you'd go to a point in the directory hierarchy above that `unpack` directory and right-click on it and choose `Download as an archive`. You can make a new directory any time using the 'New folder' icon above the left panel and then use drag and drop in the file navigator to move any files you want into it.
#
# The archive defaults to being `.gzip` format. You can alter that format if you'd prefer by going to the JupyterLab menu bar along the top of your browser window and selecting `Settings` > `Advanced Settings Editor`, and then selecting `Archive` in the `Settings` window that comes up in the main window. There you can edit the '
# `User Preferences` on the right to override the system default. For example maybe you'd prefer `tar.gz`, and so you'd edit the contents of `User Preferences` to be `{"format": "tar.gz"}`. Be sure to click on the disk icon in the upper right to save your new settings.
# ## Accessing the bendIt results: Starting up an active session
#
# If you already have an active Jupyter session going, you can skip this step.
#
# However, if you have a previously saved result from the demo pipeline and you are now returning to it and looking to access the contents of the archive, the best way to get started is to start a session by going [here](https://github.com/fomightez/bendit-binder) and clicking on the `launch bend.it` badge. When the session starts, select the `Accessing_and_reviewing_the_bendit_results.ipynb` notebook from the navigation panel at the right and work through the steps below this.
#
# The uncompressing step below should work on an unix-style command line. However, some of the advanced steps under the section entitled 'Using Python to review the data or customize the plots' involve modules/packages that aren't necessarily in a standard Python installation. By running in the recommended environment as directed above, the code is more likely to work without hiccups.
# ## Accessing the bendIt results: Uncompress the Archive
#
# This notebook assumes, you just ran the pipeline and are trying to access the results. There is then a number of files in the current directory beside the archive. To make things easier, I am going to suggest making a new directory with a simple name and then you could drag the archive into that folder and work there. To make things match witih the demo, I am going to write out those steps as commands, too. Feel free to run the cells or to do it by hand. If you make a different 'unpack' directory, you'll need to adjust things below accordingly.
#
# The exclamation marks in front of the shell commands, tells Jupyter to run those commands as shell commands and not Python.
# In[1]:
get_ipython().system('mkdir unpack')
get_ipython().system('mv bendit_analysis*.tar.gz unpack/')
# To make things in this notebook work, you'll need to switch the current working directory over to where we are going to unpack the archive. We'll use the Jupyter magic command `%cd` to change the working directory for all subsequent cells in the notebook. If we just used `!cd`, it would only change the directory for that cell.
# In[2]:
get_ipython().run_line_magic('cd', 'unpack')
# Note you can check anytime what is the current working directory with `pwd`. (Note most shell commands need an exclamation point but a few were added in to Jupyter so they work without it and `pwd` is one.) Also of note, is that this location is completely independent of where the file navigation pane on the left side of this window may be showing.
# In[3]:
pwd
# To **unpack the archive**, we'll run the command in the following cell.
# You need to edit the command so it will extract your file. In other words, the part after the `xzf` has to be changed to match the actual file name of the archive you are working with in particular. To make it easier you should be able to click after the default code in the cell below and hit `Tab` button on your keyboard and Jupyter will auto-complete the file name for you after a slight pause.
#
# (Note that I am keeping this untarring step as generic as possible so that it would work as written on any unix-style command line without the exclamation point.)
# In[4]:
get_ipython().system('tar xzf bendit_analysis')
# If you ran the above cell and saw anything like `tar (child): bendit_analysisZZZZZZZZZ.tar.gz: Cannot open: No such file or directory` (where `ZZZZZZZZZ` is used to represent the date time stamp), it simply means you had the file name wrong. You'll need to edit it and run the cell again.
#
# If things worked, you should just see the asterisk to the left of the cell turn to a number. If you changed the file navigation pane on the left-side of this browser window over to the 'unpack' directory, after a moment you should see more files show up in the file pane. Don't worry if you didn't switch. We are going to explore the contents using commands next anyways.
# ## Overview of the Unpacked Items
#
# If all is correct and you used the `%cd` command to previously switch to the 'unpack directory, running the next cell will show the contents of the current working directory so we can begin to explore the contents of the-now-unpacked archive.
# In[6]:
ls -lh
# That lists out the contents of the directory. The options added along with the `ls` command make the output more redable by showing. In particular, the `h` in `-lh` means the file sizes are human readable and the `l` in `-lh` says to list the details in long form and not just the names.
#
# You'll see there is much more than the compressed archive that was originally added when we made the directory just a few cells back. These are the results of the bendIt run. The following section will go through what these are and how to use them.
#
# ----
# ## About the Contents
# If you used your own data, your results will be different but the types will be the same. I am going describe the contents as if you ran the demo sequences; however, mostly you just need to pay attention to the file extensions, or sometimes the start of the name, to tell which file types correspond.
#
# After a brief overview, I am going to add some details about most of the types.
# Typical contents overview:
#
# - Log file
# - Image files for the plots
# - a Jupyter notebook for reviewing all the plots en masse
# - serialized (pickeled) bendIt data
# - bendIt data as tabular text
# - Nucleotide composition detail
# - serialized processing information and results on a per sample basis
# - input files
# - raw gnuplots
#
# ### Log file
#
# The Log file will look something like `LOG_ba
#
# For example, if you unpack the archive as instructed below you may end up making things in `unpack` and want that entire directory. Therefore in the file navigator panel on the left, you'd go to a point in the directory hierarchy above that `unpack` directory and right-click on it and choose `Download as an archive`. You can make a new directory any time using the 'New folder' icon above the left panel and then use drag and drop in the file navigator to move any files you want into it.
#
# The archive defaults to being `.gzip` format. You can alter that format if you'd prefer by going to the JupyterLab menu bar along the top of your browser window and selecting `Settings` > `Advanced Settings Editor`, and then selecting `Archive` in the `Settings` window that comes up in the main window. There you can edit the '
# `User Preferences` on the right to override the system default. For example maybe you'd prefer `tar.gz`, and so you'd edit the contents of `User Preferences` to be `{"format": "tar.gz"}`. Be sure to click on the disk icon in the upper right to save your new settings.
# ## Accessing the bendIt results: Starting up an active session
#
# If you already have an active Jupyter session going, you can skip this step.
#
# However, if you have a previously saved result from the demo pipeline and you are now returning to it and looking to access the contents of the archive, the best way to get started is to start a session by going [here](https://github.com/fomightez/bendit-binder) and clicking on the `launch bend.it` badge. When the session starts, select the `Accessing_and_reviewing_the_bendit_results.ipynb` notebook from the navigation panel at the right and work through the steps below this.
#
# The uncompressing step below should work on an unix-style command line. However, some of the advanced steps under the section entitled 'Using Python to review the data or customize the plots' involve modules/packages that aren't necessarily in a standard Python installation. By running in the recommended environment as directed above, the code is more likely to work without hiccups.
# ## Accessing the bendIt results: Uncompress the Archive
#
# This notebook assumes, you just ran the pipeline and are trying to access the results. There is then a number of files in the current directory beside the archive. To make things easier, I am going to suggest making a new directory with a simple name and then you could drag the archive into that folder and work there. To make things match witih the demo, I am going to write out those steps as commands, too. Feel free to run the cells or to do it by hand. If you make a different 'unpack' directory, you'll need to adjust things below accordingly.
#
# The exclamation marks in front of the shell commands, tells Jupyter to run those commands as shell commands and not Python.
# In[1]:
get_ipython().system('mkdir unpack')
get_ipython().system('mv bendit_analysis*.tar.gz unpack/')
# To make things in this notebook work, you'll need to switch the current working directory over to where we are going to unpack the archive. We'll use the Jupyter magic command `%cd` to change the working directory for all subsequent cells in the notebook. If we just used `!cd`, it would only change the directory for that cell.
# In[2]:
get_ipython().run_line_magic('cd', 'unpack')
# Note you can check anytime what is the current working directory with `pwd`. (Note most shell commands need an exclamation point but a few were added in to Jupyter so they work without it and `pwd` is one.) Also of note, is that this location is completely independent of where the file navigation pane on the left side of this window may be showing.
# In[3]:
pwd
# To **unpack the archive**, we'll run the command in the following cell.
# You need to edit the command so it will extract your file. In other words, the part after the `xzf` has to be changed to match the actual file name of the archive you are working with in particular. To make it easier you should be able to click after the default code in the cell below and hit `Tab` button on your keyboard and Jupyter will auto-complete the file name for you after a slight pause.
#
# (Note that I am keeping this untarring step as generic as possible so that it would work as written on any unix-style command line without the exclamation point.)
# In[4]:
get_ipython().system('tar xzf bendit_analysis')
# If you ran the above cell and saw anything like `tar (child): bendit_analysisZZZZZZZZZ.tar.gz: Cannot open: No such file or directory` (where `ZZZZZZZZZ` is used to represent the date time stamp), it simply means you had the file name wrong. You'll need to edit it and run the cell again.
#
# If things worked, you should just see the asterisk to the left of the cell turn to a number. If you changed the file navigation pane on the left-side of this browser window over to the 'unpack' directory, after a moment you should see more files show up in the file pane. Don't worry if you didn't switch. We are going to explore the contents using commands next anyways.
# ## Overview of the Unpacked Items
#
# If all is correct and you used the `%cd` command to previously switch to the 'unpack directory, running the next cell will show the contents of the current working directory so we can begin to explore the contents of the-now-unpacked archive.
# In[6]:
ls -lh
# That lists out the contents of the directory. The options added along with the `ls` command make the output more redable by showing. In particular, the `h` in `-lh` means the file sizes are human readable and the `l` in `-lh` says to list the details in long form and not just the names.
#
# You'll see there is much more than the compressed archive that was originally added when we made the directory just a few cells back. These are the results of the bendIt run. The following section will go through what these are and how to use them.
#
# ----
# ## About the Contents
# If you used your own data, your results will be different but the types will be the same. I am going describe the contents as if you ran the demo sequences; however, mostly you just need to pay attention to the file extensions, or sometimes the start of the name, to tell which file types correspond.
#
# After a brief overview, I am going to add some details about most of the types.
# Typical contents overview:
#
# - Log file
# - Image files for the plots
# - a Jupyter notebook for reviewing all the plots en masse
# - serialized (pickeled) bendIt data
# - bendIt data as tabular text
# - Nucleotide composition detail
# - serialized processing information and results on a per sample basis
# - input files
# - raw gnuplots
#
# ### Log file
#
# The Log file will look something like `LOG_ba