 #
#
#
#
#
#  #
#  #
#  # Alchemic treatise of [Ramon Llull](https://en.wikipedia.org/wiki/Ramon_Llull).
#
# Alchemic treatise of [Ramon Llull](https://en.wikipedia.org/wiki/Ramon_Llull).
#  #
#  #
# 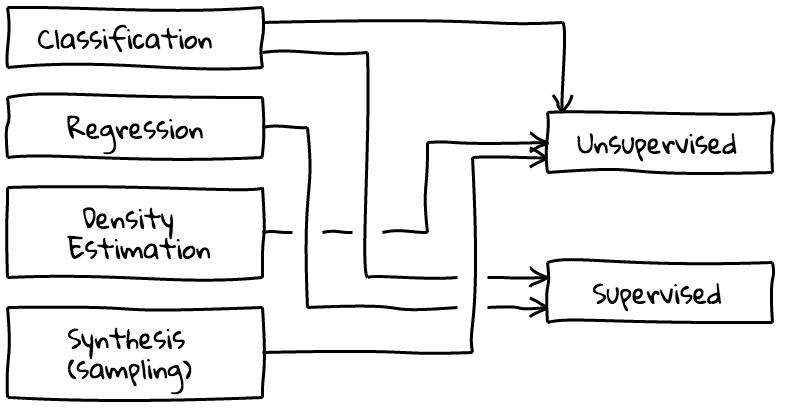 #
#  #
#  # from Scikit-learn [Choosing the right estimator](http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html).
#
# from Scikit-learn [Choosing the right estimator](http://scikit-learn.org/stable/tutorial/machine_learning_map/index.html).
#  #
#