#!/usr/bin/env python
# coding: utf-8
# ## Scale with Dask
#
# The [Planetary Computer Hub](http://planetarycomputer.microsoft.com/compute) is a JupyterHub paired with [Dask Gateway](https://gateway.dask.org/) for easily creating Dask clusters to distribute your computation on a cluster of machines.
# ### Creating a cluster
#
# Use `dask_gateway.GatewayCluster` to quickly create a Dask cluster.
# In[1]:
import dask_gateway
cluster = dask_gateway.GatewayCluster()
client = cluster.get_client()
cluster.scale(4)
print(cluster.dashboard_link)
# **Don't forget the `client = cluster.get_client()` line.** That's what actually ensures the cluster will be used for computations using Dask. Otherwise, you'll end up using Dask's [local scheduler](https://docs.dask.org/en/stable/10-minutes-to-dask.html#scheduling). This will run the computation on using multiple threads on a single machine, rather than the cluster. When you're using a cluster, make sure to always use [the Dashboard](https://docs.dask.org/en/stable/dashboard.html) (more below). If you aren't seeing any tasks in the dashboard, you might have forgotten to create a Dask client.
#
#
# ### Open the dashboard
#
# The [Dask Dashboard](https://docs.dask.org/en/latest/diagnostics-distributed.html) provides invaluable information on the activity of your cluster. Clicking the "Dashboard" link above will open the Dask dashboard a new browser tab.
#
#  #
# We also include the [dask-labextension](https://github.com/dask/dask-labextension) for laying out the Dask dashboard as tabs in the Jupyterlab workspace.
#
#
#
# We also include the [dask-labextension](https://github.com/dask/dask-labextension) for laying out the Dask dashboard as tabs in the Jupyterlab workspace.
#
# 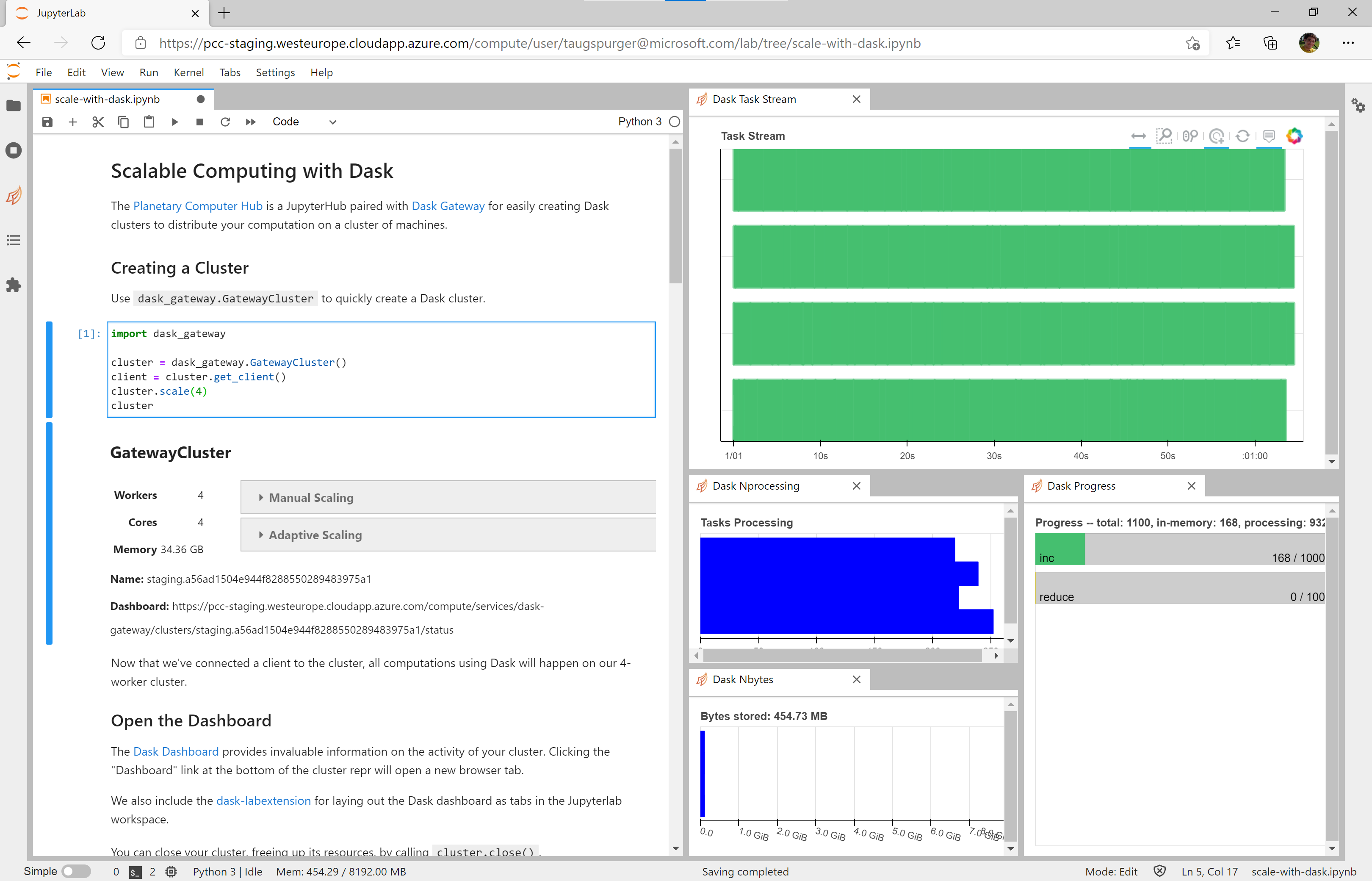 #
# To using the dask-labextension, copy the "Dashboard" address from the cluster repr, click the orange Dask logo on the lefthand navigation bar, and paste the dashboard address
#
# You can close your cluster, freeing up its resources, by calling `cluster.close()`.
# In[2]:
cluster.close()
# ### Autoscale the cluster to your workload
#
# Dask Clusters can [automatically adapt](https://docs.dask.org/en/latest/setup/adaptive.html) the cluster size based on the size of the workload. Use `cluster.adapt(minimum, maximum)` to enable adaptive mode.
# In[3]:
import dask_gateway
cluster = dask_gateway.GatewayCluster()
client = cluster.get_client()
cluster.adapt(minimum=2, maximum=50)
# Dask will add workers as necessary when a computation is submitted. As an example, we'll compute the minimum daily temperature averaged over all of Hawaii, using the [Daymet dataset](http://aka.ms/ai4edata-daymet).
# In[4]:
import pystac_client
import planetary_computer
import xarray as xr
account_name = "daymeteuwest"
container_name = "daymet-zarr"
catalog = pystac_client.Client.open(
"https://planetarycomputer.microsoft.com/api/stac/v1",
modifier=planetary_computer.sign_inplace,
)
asset = catalog.get_collection("daymet-daily-hi").assets["zarr-abfs"]
ds = xr.open_zarr(
asset.href,
**asset.extra_fields["xarray:open_kwargs"],
storage_options=asset.extra_fields["xarray:storage_options"]
)
ds
# The `.compute()` call in the next cell is what triggers computation and causes Dask to scale the cluster up to a dozen or so workers.
# In[5]:
timeseries = ds["tmin"].mean(dim=["x", "y"]).compute()
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(12, 6))
timeseries.plot(ax=ax);
# In[6]:
cluster.close()
# ### Customize your cluster
#
# `dask_gateway.GatewayCluster` creates a cluster with some default settings, which might not be appropriate for your workload. For example, we might have a memory-intensive workload which requires more memory per CPU core. Or we might need to set environment variables on the workers.
#
# To customize your cluster, create a `Gateway` object and then customize the options.
# In[7]:
import dask_gateway
gateway = dask_gateway.Gateway()
cluster_options = gateway.cluster_options()
#
#
# To using the dask-labextension, copy the "Dashboard" address from the cluster repr, click the orange Dask logo on the lefthand navigation bar, and paste the dashboard address
#
# You can close your cluster, freeing up its resources, by calling `cluster.close()`.
# In[2]:
cluster.close()
# ### Autoscale the cluster to your workload
#
# Dask Clusters can [automatically adapt](https://docs.dask.org/en/latest/setup/adaptive.html) the cluster size based on the size of the workload. Use `cluster.adapt(minimum, maximum)` to enable adaptive mode.
# In[3]:
import dask_gateway
cluster = dask_gateway.GatewayCluster()
client = cluster.get_client()
cluster.adapt(minimum=2, maximum=50)
# Dask will add workers as necessary when a computation is submitted. As an example, we'll compute the minimum daily temperature averaged over all of Hawaii, using the [Daymet dataset](http://aka.ms/ai4edata-daymet).
# In[4]:
import pystac_client
import planetary_computer
import xarray as xr
account_name = "daymeteuwest"
container_name = "daymet-zarr"
catalog = pystac_client.Client.open(
"https://planetarycomputer.microsoft.com/api/stac/v1",
modifier=planetary_computer.sign_inplace,
)
asset = catalog.get_collection("daymet-daily-hi").assets["zarr-abfs"]
ds = xr.open_zarr(
asset.href,
**asset.extra_fields["xarray:open_kwargs"],
storage_options=asset.extra_fields["xarray:storage_options"]
)
ds
# The `.compute()` call in the next cell is what triggers computation and causes Dask to scale the cluster up to a dozen or so workers.
# In[5]:
timeseries = ds["tmin"].mean(dim=["x", "y"]).compute()
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(12, 6))
timeseries.plot(ax=ax);
# In[6]:
cluster.close()
# ### Customize your cluster
#
# `dask_gateway.GatewayCluster` creates a cluster with some default settings, which might not be appropriate for your workload. For example, we might have a memory-intensive workload which requires more memory per CPU core. Or we might need to set environment variables on the workers.
#
# To customize your cluster, create a `Gateway` object and then customize the options.
# In[7]:
import dask_gateway
gateway = dask_gateway.Gateway()
cluster_options = gateway.cluster_options()
# 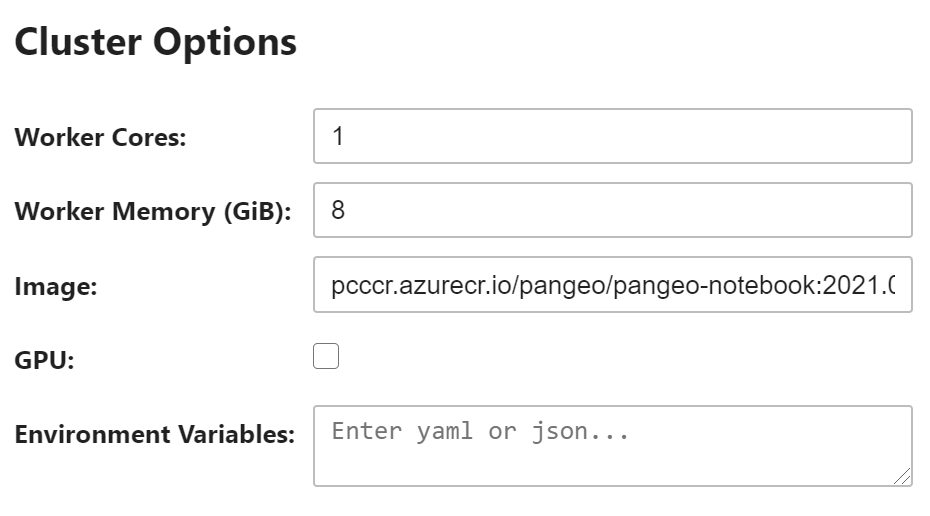 #
# In a Jupyter Notebook, you can use the HTML widget to customize the options. Or using Python you can adjust the values programmatically. We'll ask for 16GiB of memory per worker.
# In[8]:
cluster_options["worker_memory"] = 16
# Now create your cluster. **Make sure to pass the `cluster_options` object to `gateway.new_cluster`**.
# In[9]:
cluster = gateway.new_cluster(cluster_options)
client = cluster.get_client()
cluster.scale(2)
# ### Learn more
#
# The [Dask documentation](https://docs.dask.org/en/latest/) has much more information on using Dask for scalable computing. This JupyterHub deployment uses [Dask Gateway](https://gateway.dask.org/) to manage creating Dask clusters.
#
# In a Jupyter Notebook, you can use the HTML widget to customize the options. Or using Python you can adjust the values programmatically. We'll ask for 16GiB of memory per worker.
# In[8]:
cluster_options["worker_memory"] = 16
# Now create your cluster. **Make sure to pass the `cluster_options` object to `gateway.new_cluster`**.
# In[9]:
cluster = gateway.new_cluster(cluster_options)
client = cluster.get_client()
cluster.scale(2)
# ### Learn more
#
# The [Dask documentation](https://docs.dask.org/en/latest/) has much more information on using Dask for scalable computing. This JupyterHub deployment uses [Dask Gateway](https://gateway.dask.org/) to manage creating Dask clusters.