#!/usr/bin/env python
# coding: utf-8
# # Tool Evaluation with OpenAI Evals
#
# This cookbook shows how to **measure and improve a model’s ability to extract structured information from source code** with tool evaluation. In this case, the set of *symbols* (functions, classes, methods, and variables) defined in Python files.
# ## Setup
#
# Install the latest **openai** Python package ≥ 1.14.0 and set your `OPENAI_API_KEY` environment variable. If you also want to evaluate an *assistant with tools*, enable the *Assistants v2 beta* in your account.
#
# ```bash
# pip install --upgrade openai
# export OPENAI_API_KEY=sk‑...
# ```
# Below we import the SDK, create a client, and define a helper that builds a small dataset from files inside the **openai** package itself.
# In[2]:
get_ipython().run_line_magic('pip', 'install --upgrade openai pandas jinja2 rich --quiet')
import os
import time
import openai
from rich import print
client = openai.OpenAI(
api_key=os.getenv("OPENAI_API_KEY") or os.getenv("_OPENAI_API_KEY"),
)
# ### Dataset factory & grading rubric
# * `get_dataset` builds a small in-memory dataset by reading several SDK files.
# * `structured_output_grader` defines a detailed evaluation rubric.
# * `sampled.output_tools[0].function.arguments.symbols` specifies the extracted symbols from the code file based on the tool invocation.
# * `client.evals.create(...)` registers the eval with the platform.
# In[ ]:
def get_dataset(limit=None):
openai_sdk_file_path = os.path.dirname(openai.__file__)
file_paths = [
os.path.join(openai_sdk_file_path, "resources", "evals", "evals.py"),
os.path.join(openai_sdk_file_path, "resources", "responses", "responses.py"),
os.path.join(openai_sdk_file_path, "resources", "images.py"),
os.path.join(openai_sdk_file_path, "resources", "embeddings.py"),
os.path.join(openai_sdk_file_path, "resources", "files.py"),
]
items = []
for file_path in file_paths:
items.append({"input": open(file_path, "r").read()})
if limit:
return items[:limit]
return items
structured_output_grader = """
You are a helpful assistant that grades the quality of extracted information from a code file.
You will be given a code file and a list of extracted information.
You should grade the quality of the extracted information.
You should grade the quality on a scale of 1 to 7.
You should apply the following criteria, and calculate your score as follows:
You should first check for completeness on a scale of 1 to 7.
Then you should apply a quality modifier.
The quality modifier is a multiplier from 0 to 1 that you multiply by the completeness score.
If there is 100% coverage for completion and it is all high quality, then you would return 7*1.
If there is 100% coverage for completion but it is all low quality, then you would return 7*0.5.
etc.
"""
structured_output_grader_user_prompt = """
{{item.input}}
{{sample.output_tools[0].function.arguments.symbols}}
"""
# ### Evals Creation
#
# Here we create an eval that will be used to evaluate the quality of extracted information from code files.
#
# In[ ]:
logs_eval = client.evals.create(
name="Code QA Eval",
data_source_config={
"type": "custom",
"item_schema": {"type": "object", "properties": {"input": {"type": "string"}}},
"include_sample_schema": True,
},
testing_criteria=[
{
"type": "score_model",
"name": "General Evaluator",
"model": "o3",
"input": [
{"role": "system", "content": structured_output_grader},
{"role": "user", "content": structured_output_grader_user_prompt},
],
"range": [1, 7],
"pass_threshold": 5.0,
}
],
)
symbol_tool = {
"name": "extract_symbols",
"description": "Extract the symbols from the code file",
"parameters": {
"type": "object",
"properties": {
"symbols": {
"type": "array",
"description": "A list of symbols extracted from Python code.",
"items": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "The name of the symbol."},
"symbol_type": {"type": "string", "description": "The type of the symbol, e.g., variable, function, class."},
},
"required": ["name", "symbol_type"],
"additionalProperties": False,
},
}
},
"required": ["symbols"],
"additionalProperties": False,
},
}
# ### Kick off model runs
# Here we launch two runs against the same eval: one that calls the **Completions** endpoint, and one that calls the **Responses** endpoint.
# In[ ]:
gpt_4one_completions_run = client.evals.runs.create(
name="gpt-4.1",
eval_id=logs_eval.id,
data_source={
"type": "completions",
"source": {"type": "file_content", "content": [{"item": item} for item in get_dataset(limit=1)]},
"input_messages": {
"type": "template",
"template": [
{"type": "message", "role": "system", "content": {"type": "input_text", "text": "You are a helpful assistant."}},
{"type": "message", "role": "user", "content": {"type": "input_text", "text": "Extract the symbols from the code file {{item.input}}"}},
],
},
"model": "gpt-4.1",
"sampling_params": {
"seed": 42,
"temperature": 0.7,
"max_completions_tokens": 10000,
"top_p": 0.9,
"tools": [{"type": "function", "function": symbol_tool}],
},
},
)
gpt_4one_responses_run = client.evals.runs.create(
name="gpt-4.1-mini",
eval_id=logs_eval.id,
data_source={
"type": "responses",
"source": {"type": "file_content", "content": [{"item": item} for item in get_dataset(limit=1)]},
"input_messages": {
"type": "template",
"template": [
{"type": "message", "role": "system", "content": {"type": "input_text", "text": "You are a helpful assistant."}},
{"type": "message", "role": "user", "content": {"type": "input_text", "text": "Extract the symbols from the code file {{item.input}}"}},
],
},
"model": "gpt-4.1-mini",
"sampling_params": {
"seed": 42,
"temperature": 0.7,
"max_completions_tokens": 10000,
"top_p": 0.9,
"tools": [{"type": "function", **symbol_tool}],
},
},
)
# ### Utility Poller
#
# We create a utility poller that will be used to poll for the results of the eval runs.
# In[ ]:
def poll_runs(eval_id, run_ids):
# poll both runs at the same time, until they are complete or failed
while True:
runs = [client.evals.runs.retrieve(run_id, eval_id=eval_id) for run_id in run_ids]
for run in runs:
print(run.id, run.status, run.result_counts)
if all(run.status in ("completed", "failed") for run in runs):
break
time.sleep(5)
poll_runs(logs_eval.id, [gpt_4one_completions_run.id, gpt_4one_responses_run.id])
# In[ ]:
### Get Output
completions_output = client.evals.runs.output_items.list(
run_id=gpt_4one_completions_run.id, eval_id=logs_eval.id
)
responses_output = client.evals.runs.output_items.list(
run_id=gpt_4one_responses_run.id, eval_id=logs_eval.id
)
# ### Inspecting results
#
# For both completions and responses, we print the *symbols* dictionary that the model returned. You can diff this against the reference answer or compute precision / recall.
# In[ ]:
import json
import pandas as pd
from IPython.display import display, HTML
def extract_symbols(output_list):
symbols_list = []
for item in output_list:
try:
args = item.sample.output[0].tool_calls[0]["function"]["arguments"]
symbols = json.loads(args)["symbols"]
symbols_list.append(symbols)
except Exception as e:
symbols_list.append([{"error": str(e)}])
return symbols_list
completions_symbols = extract_symbols(completions_output)
responses_symbols = extract_symbols(responses_output)
def symbols_to_html_table(symbols):
if symbols and isinstance(symbols, list):
df = pd.DataFrame(symbols)
return (
df.style
.set_properties(**{
'white-space': 'pre-wrap',
'word-break': 'break-word',
'padding': '2px 6px',
'border': '1px solid #C3E7FA',
'font-size': '0.92em',
'background-color': '#FDFEFF'
})
.set_table_styles([{
'selector': 'th',
'props': [
('font-size', '0.95em'),
('background-color', '#1CA7EC'),
('color', '#fff'),
('border-bottom', '1px solid #18647E'),
('padding', '2px 6px')
]
}])
.hide(axis='index')
.to_html()
)
return f"{str(symbols)}
"
table_rows = []
max_len = max(len(completions_symbols), len(responses_symbols))
for i in range(max_len):
c_html = symbols_to_html_table(completions_symbols[i]) if i < len(completions_symbols) else ""
r_html = symbols_to_html_table(responses_symbols[i]) if i < len(responses_symbols) else ""
table_rows.append(f"""
| {c_html} |
{r_html} |
""")
table_html = f"""
Completions vs Responses Output Symbols
| Completions Output |
Responses Output |
{''.join(table_rows)}
"""
display(HTML(table_html))
# ### Visualize Evals Dashboard
#
# You can navigate to the Evals Dashboard in order to visualize the data.
#
#
# 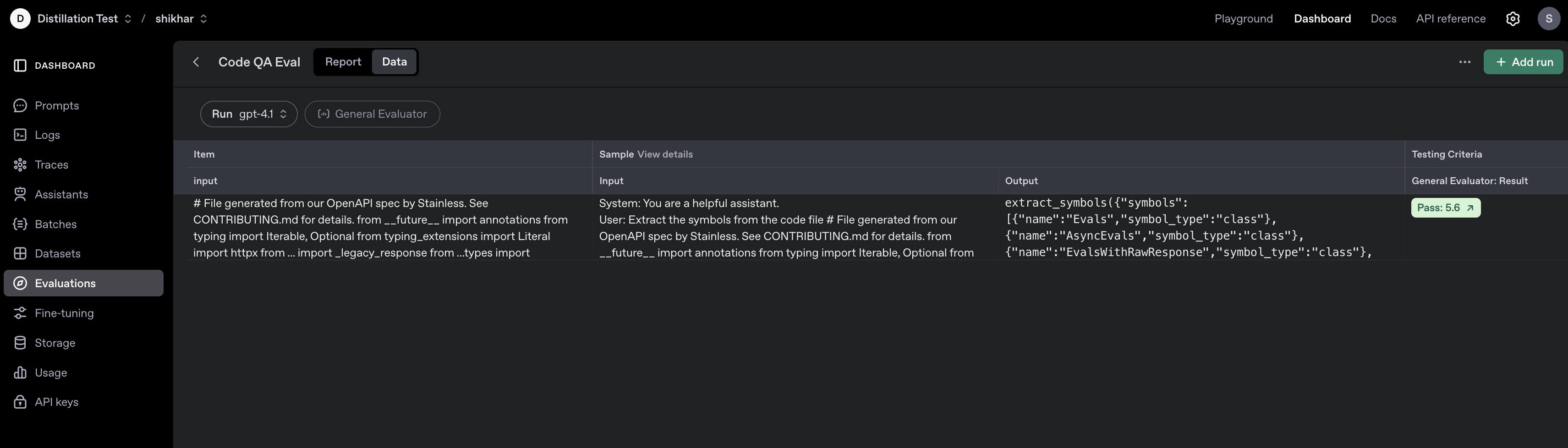
#
#
# You can also take a look at the explanation of the failed results in the Evals Dashboard after the run is complete as shown in the image below.
#
# 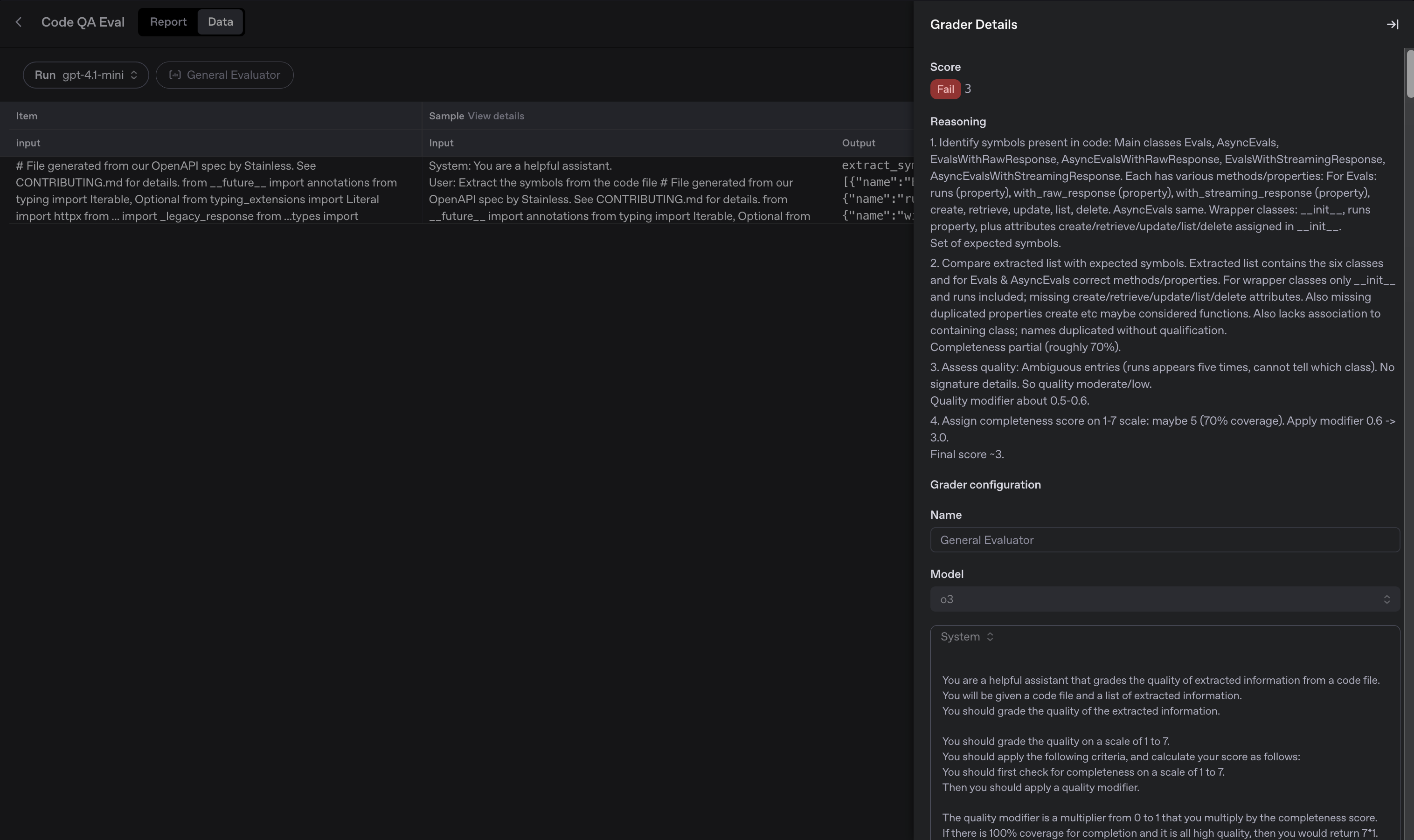
#
#
#
# This notebook demonstrated how to use OpenAI Evals to assess and improve a model’s ability to extract structured information from Python code using tool calls.
#
#
# OpenAI Evals provides a robust, reproducible framework for evaluating LLMs on structured extraction tasks. By combining clear tool schemas, rigorous grading rubrics, and well-structured datasets, you can measure and improve overall performance.
#
# *For more details, see the [OpenAI Evals documentation](https://platform.openai.com/docs/guides/evals).*