#
Clik on the links to see the sections:
#
# -
What is Deep Learning
# -
Simple test: Is tensorflow working?
# -
1st part: classify MNIST using a simple model
# -
Evaluating the final result
# -
How to improve our model?
# -
2nd part: Deep Learning applied on MNIST
# -
Summary of the Deep Convolutional Neural Network
# -
Define functions and train the model
# -
Evaluate the model
# ---
#
# # What is Deep Learning?
# **Brief Theory:** Deep learning (also known as deep structured learning, hierarchical learning or deep machine learning) is a branch of machine learning based on a set of algorithms that attempt to model high-level abstractions in data by using multiple processing layers, with complex structures or otherwise, composed of multiple non-linear transformations.
#

#
It's time for deep learning. Our brain does't work with one or three layers. Why it would be different with machines?.
# ---
# In this tutorial, we first classify MNIST using a simple Multi-layer percepetron and then, in the second part, we use deeplearning to improve the accuracy of our results.
#
#
# # 1st part: classify MNIST using a simple model.
# We are going to create a simple Multi-layer percepetron, a simple type of Neural Network, to performe classification tasks on the MNIST digits dataset. If you are not familiar with the MNIST dataset, please consider to read more about it:
click here
# ### What is MNIST?
# According to Lecun's website, the MNIST is a: "database of handwritten digits that has a training set of 60,000 examples, and a test set of 10,000 examples. It is a subset of a larger set available from NIST. The digits have been size-normalized and centered in a fixed-size image".
# ### Import the MNIST dataset using TensorFlow built-in feature
# It's very important to notice that MNIST is a high optimized data-set and it does not contain images. You will need to build your own code if you want to see the real digits. Another important side note is the effort that the authors invested on this data-set with normalization and centering operations.
# In[1]:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
# The
One-hot = True argument only means that, in contrast to Binary representation, the labels will be presented in a way that only one bit will be on for a specific digit. For example, five and zero in a binary code would be:
#
# Number representation: 0
# Binary encoding: [2^5] [2^4] [2^3] [2^2] [2^1] [2^0]
# Array/vector: 0 0 0 0 0 0
#
# Number representation: 5
# Binary encoding: [2^5] [2^4] [2^3] [2^2] [2^1] [2^0]
# Array/vector: 0 0 0 1 0 1
#
# Using a different notation, the same digits using one-hot vector representation can be show as:
#
# Number representation: 0
# One-hot encoding: [5] [4] [3] [2] [1] [0]
# Array/vector: 0 0 0 0 0 1
#
# Number representation: 5
# One-hot encoding: [5] [4] [3] [2] [1] [0]
# Array/vector: 1 0 0 0 0 0
#
# ### Understanding the imported data
# The imported data can be divided as follow:
#
# - Training (mnist.train) >> Use the given dataset with inputs and related outputs for training of NN. In our case, if you give an image that you know that represents a "nine", this set will tell the neural network that we expect a "nine" as the output.
# - 55,000 data points
# - mnist.train.images for inputs
# - mnist.train.labels for outputs
#
#
# - Validation (mnist.validation) >> The same as training, but now the date is used to generate model properties (classification error, for example) and from this, tune parameters like the optimal number of hidden units or determine a stopping point for the back-propagation algorithm
# - 5,000 data points
# - mnist.validation.images for inputs
# - mnist.validation.labels for outputs
#
#
# - Test (mnist.test) >> the model does not have access to this informations prior to the test phase. It is used to evaluate the performance and accuracy of the model against "real life situations". No further optimization beyond this point.
# - 10,000 data points
# - mnist.test.images for inputs
# - mnist.test.labels for outputs
#
# ### Creating an interactive section
# You have two basic options when using TensorFlow to run your code:
#
# - [Build graphs and run session] Do all the set-up and THEN execute a session to evaluate tensors and run operations (ops)
# - [Interactive session] create your coding and run on the fly.
#
# For this first part, we will use the interactive session that is more suitable for environments like Jupyter notebooks.
# In[2]:
sess = tf.InteractiveSession()
# ### Creating placeholders
# It's a best practice to create placeholders before variable assignments when using TensorFlow. Here we'll create placeholders for inputs ("Xs") and outputs ("Ys").
#
# __Placeholder 'X':__ represents the "space" allocated input or the images.
# * Each input has 784 pixels distributed by a 28 width x 28 height matrix
# * The 'shape' argument defines the tensor size by its dimensions.
# * 1st dimension = None. Indicates that the batch size, can be of any size.
# * 2nd dimension = 784. Indicates the number of pixels on a single flattened MNIST image.
#
# __Placeholder 'Y':___ represents the final output or the labels.
# * 10 possible classes (0,1,2,3,4,5,6,7,8,9)
# * The 'shape' argument defines the tensor size by its dimensions.
# * 1st dimension = None. Indicates that the batch size, can be of any size.
# * 2nd dimension = 10. Indicates the number of targets/outcomes
#
# __dtype for both placeholders:__ if you not sure, use tf.float32. The limitation here is that the later presented softmax function only accepts float32 or float64 dtypes. For more dtypes, check TensorFlow's documentation
here
#
# In[3]:
x = tf.placeholder(tf.float32, shape=[None, 784])
y_ = tf.placeholder(tf.float32, shape=[None, 10])
# ### Assigning bias and weights to null tensors
# Now we are going to create the weights and biases, for this purpose they will be used as arrays filled with zeros. The values that we choose here can be critical, but we'll cover a better way on the second part, instead of this type of initialization.
# In[4]:
# Weight tensor
W = tf.Variable(tf.zeros([784,10],tf.float32))
# Bias tensor
b = tf.Variable(tf.zeros([10],tf.float32))
# ### Execute the assignment operation
# Before, we assigned the weights and biases but we did not initialize them with null values. For this reason, TensorFlow need to initialize the variables that you assign.
# Please notice that we're using this notation "sess.run" because we previously started an interactive session.
# In[5]:
# run the op initialize_all_variables using an interactive session
sess.run(tf.initialize_all_variables())
# ### Adding Weights and Biases to input
# The only difference from our next operation to the picture below is that we are using the mathematical convention for what is being executed in the illustration. The tf.matmul operation performs a matrix multiplication between x (inputs) and W (weights) and after the code add biases.
#
#
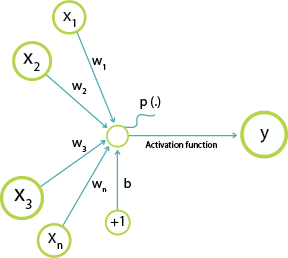
#
Illustration showing how weights and biases are added to neurons/nodes.
#
# In[6]:
#mathematical operation to add weights and biases to the inputs
tf.matmul(x,W) + b
# ### Softmax Regression
# Softmax is an activation function that is normally used in classification problems. It generate the probabilities for the output. For example, our model will not be 100% sure that one digit is the number nine, instead, the answer will be a distribution of probabilities where, if the model is right, the nine number will have the larger probability.
#
# For comparison, below is the one-hot vector for a nine digit label:
0 --> 0
1 --> 0
2 --> 0
3 --> 0
4 --> 0
5 --> 0
6 --> 0
7 --> 0
8 --> 0
9 --> 1
# A machine does not have all this certainty, so we want to know what is the best guess, but we also want to understand how sure it was and what was the second better option. Below is an example of a hypothetical distribution for a nine digit:
0 -->.0.1%
1 -->...2%
2 -->...3%
3 -->...2%
4 -->..12%
5 -->..10%
6 -->..57%
7 -->..20%
8 -->..55%
9 -->..80%
# In[7]:
y = tf.nn.softmax(tf.matmul(x,W) + b)
# Logistic function output is used for the classification between two target classes 0/1. Softmax function is generalized type of logistic function. That is, Softmax can output a multiclass categorical probability distribution.
# ### Cost function
# It is a function that is used to minimize the difference between the right answers (labels) and estimated outputs by our Network.
# In[8]:
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
# ### Type of optimization: Gradient Descent
# This is the part where you configure the optimizer for you Neural Network. There are several optimizers available, in our case we will use Gradient Descent that is very well stablished.
# In[9]:
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
# ### Training batches
# Train using minibatch Gradient Descent.
#
# In practice, Batch Gradient Descent is not often used because is too computationally expensive. The good part about this method is that you have the true gradient, but with the expensive computing task of using the whole dataset in one time. Due to this problem, Neural Networks usually use minibatch to train.
# In[10]:
batch = mnist.train.next_batch(50)
# In[11]:
batch[0].shape
# In[12]:
type(batch[0])
# In[13]:
mnist.train.images.shape
# In[14]:
#Load 50 training examples for each training iteration
for i in range(1000):
batch = mnist.train.next_batch(50)
train_step.run(feed_dict={x: batch[0], y_: batch[1]})
# ### Test
# In[15]:
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
acc = accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels}) * 100
print("The final accuracy for the simple ANN model is: {} % ".format(acc) )
# In[16]:
sess.close() #finish the session
# ---
#
# # Evaluating the final result
# Is the final result good?
#
# Let's check the best algorithm available out there (10th june 2016):
#
# _Result:_ 0.21% error (99.79% accuracy)
#
Reference here
#
# # How to improve our model?
# #### Several options as follow:
# - Regularization of Neural Networks using DropConnect
# - Multi-column Deep Neural Networks for Image Classification
# - APAC: Augmented Pattern Classification with Neural Networks
# - Simple Deep Neural Network with Dropout
#
# #### In the next part we are going to explore the option:
# - Simple Deep Neural Network with Dropout (more than 1 hidden layer)
# ---
#
# # 2nd part: Deep Learning applied on MNIST
# In the first part, we learned how to use a simple ANN to classify MNIST. Now we are going to expand our knowledge using a Deep Neural Network.
#
#
# Architecture of our network is:
#
# - (Input) -> [batch_size, 28, 28, 1] >> Apply 32 filter of [5x5]
# - (Convolutional layer 1) -> [batch_size, 28, 28, 32]
# - (ReLU 1) -> [?, 28, 28, 32]
# - (Max pooling 1) -> [?, 14, 14, 32]
# - (Convolutional layer 2) -> [?, 14, 14, 64]
# - (ReLU 2) -> [?, 14, 14, 64]
# - (Max pooling 2) -> [?, 7, 7, 64]
# - [fully connected layer 3] -> [1x1024]
# - [ReLU 3] -> [1x1024]
# - [Drop out] -> [1x1024]
# - [fully connected layer 4] -> [1x10]
#
#
# The next cells will explore this new architecture.
# ### Starting the code
# In[58]:
import tensorflow as tf
# finish possible remaining session
sess.close()
#Start interactive session
sess = tf.InteractiveSession()
# ### The MNIST data
# In[59]:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
# ### Initial parameters
# Create general parameters for the model
# In[60]:
width = 28 # width of the image in pixels
height = 28 # height of the image in pixels
flat = width * height # number of pixels in one image
class_output = 10 # number of possible classifications for the problem
# ### Input and output
# Create place holders for inputs and outputs
# In[61]:
x = tf.placeholder(tf.float32, shape=[None, flat])
y_ = tf.placeholder(tf.float32, shape=[None, class_output])
# #### Converting images of the data set to tensors
# The input image is a 28 pixels by 28 pixels and 1 channel (grayscale)
#
# In this case the first dimension is the __batch number__ of the image (position of the input on the batch) and can be of any size (due to -1)
# In[62]:
x_image = tf.reshape(x, [-1,28,28,1])
# In[63]:
x_image
# ### Convolutional Layer 1
# #### Defining kernel weight and bias
# Size of the filter/kernel: 5x5;
# Input channels: 1 (greyscale);
# 32 feature maps (here, 32 feature maps means 32 different filters are applied on each image. So, the output of convolution layer would be 28x28x32). In this step, we create a filter / kernel tensor of shape `[filter_height, filter_width, in_channels, out_channels]`
# In[64]:
W_conv1 = tf.Variable(tf.truncated_normal([5, 5, 1, 32], stddev=0.1))
b_conv1 = tf.Variable(tf.constant(0.1, shape=[32])) # need 32 biases for 32 outputs
#

#
# #### Convolve with weight tensor and add biases.
#
# Defining a function to create convolutional layers. To creat convolutional layer, we use __tf.nn.conv2d__. It computes a 2-D convolution given 4-D input and filter tensors.
#
# Inputs:
# - tensor of shape [batch, in_height, in_width, in_channels]. x of shape [batch_size,28 ,28, 1]
# - a filter / kernel tensor of shape [filter_height, filter_width, in_channels, out_channels]. W is of size [5, 5, 1, 32]
# - stride which is [1, 1, 1, 1]
#
#
# Process:
# - change the filter to a 2-D matrix with shape [5\*5\*1,32]
# - Extracts image patches from the input tensor to form a *virtual* tensor of shape `[batch, 28, 28, 5*5*1]`.
# - For each patch, right-multiplies the filter matrix and the image patch vector.
#
# Output:
# - A `Tensor` (a 2-D convolution) of size
#
# #### Apply the ReLU activation Function
# In this step, we just go through all outputs convolution layer, __covolve1__, and wherever a negative number occurs,we swap it out for a 0. It is called ReLU activation Function.
# In[66]:
h_conv1 = tf.nn.relu(convolve1)
# #### Apply the max pooling
# Use the max pooling operation already defined, so the output would be 14x14x32
# Defining a function to perform max pooling. The maximum pooling is an operation that finds maximum values and simplifies the inputs using the spacial correlations between them.
#
# __Kernel size:__ 2x2 (if the window is a 2x2 matrix, it would result in one output pixel)
# __Strides:__ dictates the sliding behaviour of the kernel. In this case it will move 2 pixels everytime, thus not overlapping.
#
#
#  #
#
# In[67]:
h_pool1 = tf.nn.max_pool(h_conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') #max_pool_2x2
# #### First layer completed
# In[68]:
layer1= h_pool1
# ### Convolutional Layer 2
# #### Weights and Biases of kernels
# Filter/kernel: 5x5 (25 pixels) ; Input channels: 32 (from the 1st Conv layer, we had 32 feature maps); 64 output feature maps
# __Notice:__ here, the input is 14x14x32, the filter is 5x5x32, we use 64 filters, and the output of the convolutional layer would be 14x14x64.
#
# __Notice:__ the convolution result of applying a filter of size [5x5x32] on image of size [14x14x32] is an image of size [14x14x1], that is, the convolution is functioning on volume.
# In[69]:
W_conv2 = tf.Variable(tf.truncated_normal([5, 5, 32, 64], stddev=0.1))
b_conv2 = tf.Variable(tf.constant(0.1, shape=[64])) #need 64 biases for 64 outputs
# #### Convolve image with weight tensor and add biases.
# In[70]:
convolve2= tf.nn.conv2d(layer1, W_conv2, strides=[1, 1, 1, 1], padding='SAME')+ b_conv2
# #### Apply the ReLU activation Function
# In[71]:
h_conv2 = tf.nn.relu(convolve2)
# #### Apply the max pooling
# In[72]:
h_pool2 = tf.nn.max_pool(h_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') #max_pool_2x2
# #### Second layer completed
# In[73]:
layer2= h_pool2
# So, what is the output of the second layer, layer2?
# - it is 64 matrix of [7x7]
#
# ### Fully Connected Layer 3
# Type: Fully Connected Layer. You need a fully connected layer to use the Softmax and create the probabilities in the end. Fully connected layers take the high-level filtered images from previous layer, that is all 64 matrics, and convert them to an array.
#
# So, each matrix [7x7] will be converted to a matrix of [49x1], and then all of the 64 matrix will be connected, which make an array of size [3136x1]. We will connect it into another layer of size [1024x1]. So, the weight between these 2 layers will be [3136x1024]
#
#
#
#
#
# In[67]:
h_pool1 = tf.nn.max_pool(h_conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') #max_pool_2x2
# #### First layer completed
# In[68]:
layer1= h_pool1
# ### Convolutional Layer 2
# #### Weights and Biases of kernels
# Filter/kernel: 5x5 (25 pixels) ; Input channels: 32 (from the 1st Conv layer, we had 32 feature maps); 64 output feature maps
# __Notice:__ here, the input is 14x14x32, the filter is 5x5x32, we use 64 filters, and the output of the convolutional layer would be 14x14x64.
#
# __Notice:__ the convolution result of applying a filter of size [5x5x32] on image of size [14x14x32] is an image of size [14x14x1], that is, the convolution is functioning on volume.
# In[69]:
W_conv2 = tf.Variable(tf.truncated_normal([5, 5, 32, 64], stddev=0.1))
b_conv2 = tf.Variable(tf.constant(0.1, shape=[64])) #need 64 biases for 64 outputs
# #### Convolve image with weight tensor and add biases.
# In[70]:
convolve2= tf.nn.conv2d(layer1, W_conv2, strides=[1, 1, 1, 1], padding='SAME')+ b_conv2
# #### Apply the ReLU activation Function
# In[71]:
h_conv2 = tf.nn.relu(convolve2)
# #### Apply the max pooling
# In[72]:
h_pool2 = tf.nn.max_pool(h_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') #max_pool_2x2
# #### Second layer completed
# In[73]:
layer2= h_pool2
# So, what is the output of the second layer, layer2?
# - it is 64 matrix of [7x7]
#
# ### Fully Connected Layer 3
# Type: Fully Connected Layer. You need a fully connected layer to use the Softmax and create the probabilities in the end. Fully connected layers take the high-level filtered images from previous layer, that is all 64 matrics, and convert them to an array.
#
# So, each matrix [7x7] will be converted to a matrix of [49x1], and then all of the 64 matrix will be connected, which make an array of size [3136x1]. We will connect it into another layer of size [1024x1]. So, the weight between these 2 layers will be [3136x1024]
#
#
#  #
# #### Flattening Second Layer
# In[74]:
layer2_matrix = tf.reshape(layer2, [-1, 7*7*64])
# #### Weights and Biases between layer 2 and 3
# Composition of the feature map from the last layer (7x7) multiplied by the number of feature maps (64); 1027 outputs to Softmax layer
# In[75]:
W_fc1 = tf.Variable(tf.truncated_normal([7 * 7 * 64, 1024], stddev=0.1))
b_fc1 = tf.Variable(tf.constant(0.1, shape=[1024])) # need 1024 biases for 1024 outputs
# #### Matrix Multiplication (applying weights and biases)
# In[76]:
fcl3=tf.matmul(layer2_matrix, W_fc1) + b_fc1
# #### Apply the ReLU activation Function
# In[77]:
h_fc1 = tf.nn.relu(fcl3)
# #### Third layer completed
# In[78]:
layer3= h_fc1
# In[79]:
layer3
# #### Optional phase for reducing overfitting - Dropout 3
# It is a phase where the network "forget" some features. At each training step in a mini-batch, some units get switched off randomly so that it will not interact with the network. That is, it weights cannot be updated, nor affect the learning of the other network nodes. This can be very useful for very large neural networks to prevent overfitting.
# In[80]:
keep_prob = tf.placeholder(tf.float32)
layer3_drop = tf.nn.dropout(layer3, keep_prob)
# ### Layer 4- Readout Layer (Softmax Layer)
# Type: Softmax, Fully Connected Layer.
# #### Weights and Biases
# In last layer, CNN takes the high-level filtered images and translate them into votes using softmax.
# Input channels: 1024 (neurons from the 3rd Layer); 10 output features
# In[81]:
W_fc2 = tf.Variable(tf.truncated_normal([1024, 10], stddev=0.1)) #1024 neurons
b_fc2 = tf.Variable(tf.constant(0.1, shape=[10])) # 10 possibilities for digits [0,1,2,3,4,5,6,7,8,9]
# #### Matrix Multiplication (applying weights and biases)
# In[82]:
fcl4=tf.matmul(layer3_drop, W_fc2) + b_fc2
# #### Apply the Softmax activation Function
# __softmax__ allows us to interpret the outputs of __fcl4__ as probabilities. So, __y_conv__ is a tensor of probablities.
# In[83]:
y_conv= tf.nn.softmax(fcl4)
# In[84]:
layer4= y_conv
# In[85]:
layer4
# ---
#
# # Summary of the Deep Convolutional Neural Network
# Now is time to remember the structure of our network
# #### 0) Input - MNIST dataset
# #### 1) Convolutional and Max-Pooling
# #### 2) Convolutional and Max-Pooling
# #### 3) Fully Connected Layer
# #### 4) Processing - Dropout
# #### 5) Readout layer - Fully Connected
# #### 6) Outputs - Classified digits
# ---
#
# # Define functions and train the model
# #### Define the loss function
#
# We need to compare our output, layer4 tensor, with ground truth for all mini_batch. we can use __cross entropy__ to see how bad our CNN is working - to measure the error at a softmax layer.
#
# The following code shows an toy sample of cross-entropy for a mini-batch of size 2 which its items have been classified. You can run it (first change the cell type to __code__ in the toolbar) to see hoe cross entropy changes.
import numpy as np
layer4_test =[[0.9, 0.1, 0.1],[0.9, 0.1, 0.1]]
y_test=[[1.0, 0.0, 0.0],[1.0, 0.0, 0.0]]
np.mean( -np.sum(y_test * np.log(layer4_test),1))
# __reduce_sum__ computes the sum of elements of __(y_ * tf.log(layer4)__ across second dimension of the tensor, and __reduce_mean__ computes the mean of all elements in the tensor..
# In[86]:
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(layer4), reduction_indices=[1]))
# #### Define the optimizer
#
# It is obvious that we want minimize the error of our network which is calculated by cross_entropy metric. To solve the problem, we have to compute gradients for the loss (which is minimizing the cross-entropy) and apply gradients to variables. It will be done by an optimizer: GradientDescent or Adagrad.
# In[87]:
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# #### Define prediction
# Do you want to know how many of the cases in a mini-batch has been classified correctly? lets count them.
# In[88]:
correct_prediction = tf.equal(tf.argmax(layer4,1), tf.argmax(y_,1))
# #### Define accuracy
# It makes more sense to report accuracy using average of correct cases.
# In[89]:
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# #### Run session, train
# In[90]:
sess.run(tf.initialize_all_variables())
# *If you want a fast result (**it might take sometime to train it**)*
# In[91]:
for i in range(1100):
batch = mnist.train.next_batch(50)
if i%100 == 0:
#train_accuracy = accuracy.eval(feed_dict={x:batch[0], y_: batch[1], keep_prob: 1.0})
loss, train_accuracy = sess.run([cross_entropy, accuracy], feed_dict={x: batch[0],y_: batch[1],keep_prob: 1.0})
print("step %d, loss %g, training accuracy %g"%(i, float(loss),float(train_accuracy)))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
#
#
# #### Flattening Second Layer
# In[74]:
layer2_matrix = tf.reshape(layer2, [-1, 7*7*64])
# #### Weights and Biases between layer 2 and 3
# Composition of the feature map from the last layer (7x7) multiplied by the number of feature maps (64); 1027 outputs to Softmax layer
# In[75]:
W_fc1 = tf.Variable(tf.truncated_normal([7 * 7 * 64, 1024], stddev=0.1))
b_fc1 = tf.Variable(tf.constant(0.1, shape=[1024])) # need 1024 biases for 1024 outputs
# #### Matrix Multiplication (applying weights and biases)
# In[76]:
fcl3=tf.matmul(layer2_matrix, W_fc1) + b_fc1
# #### Apply the ReLU activation Function
# In[77]:
h_fc1 = tf.nn.relu(fcl3)
# #### Third layer completed
# In[78]:
layer3= h_fc1
# In[79]:
layer3
# #### Optional phase for reducing overfitting - Dropout 3
# It is a phase where the network "forget" some features. At each training step in a mini-batch, some units get switched off randomly so that it will not interact with the network. That is, it weights cannot be updated, nor affect the learning of the other network nodes. This can be very useful for very large neural networks to prevent overfitting.
# In[80]:
keep_prob = tf.placeholder(tf.float32)
layer3_drop = tf.nn.dropout(layer3, keep_prob)
# ### Layer 4- Readout Layer (Softmax Layer)
# Type: Softmax, Fully Connected Layer.
# #### Weights and Biases
# In last layer, CNN takes the high-level filtered images and translate them into votes using softmax.
# Input channels: 1024 (neurons from the 3rd Layer); 10 output features
# In[81]:
W_fc2 = tf.Variable(tf.truncated_normal([1024, 10], stddev=0.1)) #1024 neurons
b_fc2 = tf.Variable(tf.constant(0.1, shape=[10])) # 10 possibilities for digits [0,1,2,3,4,5,6,7,8,9]
# #### Matrix Multiplication (applying weights and biases)
# In[82]:
fcl4=tf.matmul(layer3_drop, W_fc2) + b_fc2
# #### Apply the Softmax activation Function
# __softmax__ allows us to interpret the outputs of __fcl4__ as probabilities. So, __y_conv__ is a tensor of probablities.
# In[83]:
y_conv= tf.nn.softmax(fcl4)
# In[84]:
layer4= y_conv
# In[85]:
layer4
# ---
#
# # Summary of the Deep Convolutional Neural Network
# Now is time to remember the structure of our network
# #### 0) Input - MNIST dataset
# #### 1) Convolutional and Max-Pooling
# #### 2) Convolutional and Max-Pooling
# #### 3) Fully Connected Layer
# #### 4) Processing - Dropout
# #### 5) Readout layer - Fully Connected
# #### 6) Outputs - Classified digits
# ---
#
# # Define functions and train the model
# #### Define the loss function
#
# We need to compare our output, layer4 tensor, with ground truth for all mini_batch. we can use __cross entropy__ to see how bad our CNN is working - to measure the error at a softmax layer.
#
# The following code shows an toy sample of cross-entropy for a mini-batch of size 2 which its items have been classified. You can run it (first change the cell type to __code__ in the toolbar) to see hoe cross entropy changes.
import numpy as np
layer4_test =[[0.9, 0.1, 0.1],[0.9, 0.1, 0.1]]
y_test=[[1.0, 0.0, 0.0],[1.0, 0.0, 0.0]]
np.mean( -np.sum(y_test * np.log(layer4_test),1))
# __reduce_sum__ computes the sum of elements of __(y_ * tf.log(layer4)__ across second dimension of the tensor, and __reduce_mean__ computes the mean of all elements in the tensor..
# In[86]:
cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(layer4), reduction_indices=[1]))
# #### Define the optimizer
#
# It is obvious that we want minimize the error of our network which is calculated by cross_entropy metric. To solve the problem, we have to compute gradients for the loss (which is minimizing the cross-entropy) and apply gradients to variables. It will be done by an optimizer: GradientDescent or Adagrad.
# In[87]:
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# #### Define prediction
# Do you want to know how many of the cases in a mini-batch has been classified correctly? lets count them.
# In[88]:
correct_prediction = tf.equal(tf.argmax(layer4,1), tf.argmax(y_,1))
# #### Define accuracy
# It makes more sense to report accuracy using average of correct cases.
# In[89]:
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# #### Run session, train
# In[90]:
sess.run(tf.initialize_all_variables())
# *If you want a fast result (**it might take sometime to train it**)*
# In[91]:
for i in range(1100):
batch = mnist.train.next_batch(50)
if i%100 == 0:
#train_accuracy = accuracy.eval(feed_dict={x:batch[0], y_: batch[1], keep_prob: 1.0})
loss, train_accuracy = sess.run([cross_entropy, accuracy], feed_dict={x: batch[0],y_: batch[1],keep_prob: 1.0})
print("step %d, loss %g, training accuracy %g"%(i, float(loss),float(train_accuracy)))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
#
#
*You can run this cell if you REALLY have time to wait (**change the type of the cell to code**)*
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print("step %d, training accuracy %g"%(i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
# _PS. If you have problems running this notebook, please shutdown all your Jupyter runnning notebooks, clear all cells outputs and run each cell only after the completion of the previous cell._
# ---
#
# # Evaluate the model
# Print the evaluation to the user
# In[92]:
print("test accuracy %g"%accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
# ## Visualization
# Do you want to look at all the filters?
# In[93]:
kernels = sess.run(tf.reshape(tf.transpose(W_conv1, perm=[2, 3, 0,1]),[32,-1]))
# In[94]:
from utils import tile_raster_images
import matplotlib.pyplot as plt
from PIL import Image
get_ipython().run_line_magic('matplotlib', 'inline')
image = Image.fromarray(tile_raster_images(kernels, img_shape=(5, 5) ,tile_shape=(4, 8), tile_spacing=(1, 1)))
### Plot image
plt.rcParams['figure.figsize'] = (18.0, 18.0)
imgplot = plt.imshow(image)
imgplot.set_cmap('gray')
# Do you want to see the output of an image passing through first convolution layer?
#
# In[95]:
import numpy as np
plt.rcParams['figure.figsize'] = (5.0, 5.0)
sampleimage = mnist.test.images[1]
plt.imshow(np.reshape(sampleimage,[28,28]), cmap="gray")
# In[100]:
ActivatedUnits.shape
# In[103]:
ActivatedUnitsL1 = sess.run(convolve1,feed_dict={x:np.reshape(sampleimage,[1,784],order='F'),keep_prob:1.0})
filters = ActivatedUnitsL1.shape[3]
plt.figure(1, figsize=(20,20))
n_columns = 6
n_rows = np.math.ceil(filters / n_columns) + 1
for i in range(filters):
plt.subplot(n_rows, n_columns, i+1)
plt.title('Cov1_ ' + str(i))
plt.imshow(ActivatedUnitsL1[0,:,:,i], interpolation="nearest", cmap="gray")
# What about second convolution layer?
# In[105]:
ActivatedUnitsL2 = sess.run(convolve2,feed_dict={x:np.reshape(sampleimage,[1,784],order='F'),keep_prob:1.0})
filters = ActivatedUnitsL2.shape[3]
plt.figure(1, figsize=(20,20))
n_columns = 8
n_rows = np.math.ceil(filters / n_columns) + 1
for i in range(filters):
plt.subplot(n_rows, n_columns, i+1)
plt.title('Conv_2 ' + str(i))
plt.imshow(ActivatedUnitsL2[0,:,:,i], interpolation="nearest", cmap="gray")
# In[57]:
sess.close() #finish the session
# ### Thanks for completing this lesson!
#
Authors:
#
#
# Saeed Aghabozorgi
# Saeed Aghabozorgi, PhD is Sr. Data Scientist in IBM with a track record of developing enterprise level applications that substantially increases clients’ ability to turn data into actionable knowledge. He is a researcher in data mining field and expert in developing advanced analytic methods like machine learning and statistical modelling on large datasets.
#
#
#
# Learn more about __Deep Leaning and TensorFlow:__
#
#

# ### References:
#
# https://en.wikipedia.org/wiki/Deep_learning
# http://sebastianruder.com/optimizing-gradient-descent/index.html#batchgradientdescent
# http://yann.lecun.com/exdb/mnist/
# https://www.quora.com/Artificial-Neural-Networks-What-is-the-difference-between-activation-functions
# https://www.tensorflow.org/versions/r0.9/tutorials/mnist/pros/index.html
