# # Run fastdup with TIMM Embeddings
#
# [](https://colab.research.google.com/github/visual-layer/fastdup/blob/main/examples/embeddings-timm.ipynb)
# [](https://kaggle.com/kernels/welcome?src=https://github.com/visual-layer/fastdup/blob/main/examples/embeddings-timm.ipynb)
# [](https://visual-layer.readme.io/docs/embeddings-timm)
# In this notebook we show an end-to-end example on how you can pre-compute embeddings using any models from TIMM run fastdup on top of the embeddings to surface dataset issues.
# ## Installation
#
# First, let's install the neccessary packages:
#
# - [fastdup](https://github.com/visual-layer/fastdup) - To analyze issues in the dataset.
# - [TIMM (PyTorch Image Models)](https://github.com/huggingface/pytorch-image-models) - To acquire pre-trained models.
# In[1]:
get_ipython().system('pip install -Uq fastdup timm')
# Now, test the installation. If there's no error message, we are ready to go.
# In[2]:
import fastdup
fastdup.__version__
# ## Download Dataset
#
# In this notebook, we will the [Price Match Guarantee Dataset](https://www.kaggle.com/competitions/shopee-product-matching/) from Shopee from Kaggle.
# The dataset consists of images from users who sell products on the Shopee online platform.
#
# Download the dataset [here](https://www.kaggle.com/competitions/shopee-product-matching/data), unzip, and place it in the current directory.
#
# Here's a snapshot showing some of the images from the dataset.
# 
# ## List TIMM Models
# There are currently 1212 computer vision models on TIMM. Pick a model of your choice to compute the embedding with.
#
# Now, pick a model of your choice. For demonstration, we will go with a relatively new model `vit_small_patch14_dinov2.lvd142m` from MetaAI.
#
# Let's list down models that match the keyword `dino`.
# In[3]:
import timm
timm.list_models("*dino*", pretrained=True)
# DINOv2 models produce high-performance visual features that can be directly employed with classifiers as simple as linear layers on a variety of computer vision tasks; these visual features are robust and perform well across domains without any requirement for fine-tuning. Read more about DINOv2 [here](https://github.com/facebookresearch/dinov2).
#
# It makes sense for us to use DINOv2 as a model to create an embedding of the dataset.
# ## Compute Embeddings using TIMM
#
# Loading TIMM models in fastdup is seamless with the `TimmEncoder` wrapper class. This ensures all TIMM models can be used in fastdup to compute the embeddings of your dataset.
# Under the hood, the wrapper class loads the model from TIMM excluding the final classification layer.
#
# Next, let's load the DINOv2 model using the `TimmEncoder` wrapper.
# In[4]:
from fastdup.embeddings_timm import TimmEncoder
timm_model = TimmEncoder('vit_small_patch14_dinov2.lvd142m')
# Here are other the parameters for `TimmEncoder`
#
# + `model_name` (str): The name of the model architecture to use.
# + `num_classes` (int): The number of classes for the model. Use num_features=0 to exclude the last layer. Default: `0`.
# + `pretrained` (bool): Whether to load pretrained weights. Default: `True`.
# + `device` (str): Which device to load the model on. Choices: "cuda" or "cpu". Default: `None`.
# + `torch_compile` (bool): Whether to use `torch.compile` to optimize model. Default `False`.
# To start computing embeddings, specify the directory where the images are stored.
# In[5]:
timm_model.compute_embeddings("shopee-product-matching/train_images")
# Once done, the embeddings are stored in a folder named `saved_embeddings` in the current directory as a `numpy` array with the appropriate model name.
#
# For this example the file name is `vit_small_patch14_dinov2.lvd142m_embeddings.npy`.
# ## Run fastdup
#
# Now let's load the embeddings into fastdup and run an analysis to surface dataset issues.
# In[6]:
fd = fastdup.create(input_dir=timm_model.img_folder)
fd.run(annotations=timm_model.file_paths, embeddings=timm_model.embeddings)
# ## Visualize
#
# You can use all of fastdup gallery methods to view duplicates, clusters, etc.
#
# Let's view the image clusters.
# In[7]:
fd.vis.component_gallery()
# And duplicates gallery.
# In[8]:
fd.vis.duplicates_gallery()
# ## Interactive Exploration
# In addition to the static visualizations presented above, fastdup also offers interactive exploration of the dataset.
#
# To explore the dataset and issues interactively in a browser, run:
# In[ ]:
fd.explore()
# > 🗒 **Note** - This currently requires you to sign-up (for free) to view the interactive exploration. Alternatively, you can visualize fastdup in a non-interactive way using fastdup's built in galleries shown in the upcoming cells.
#
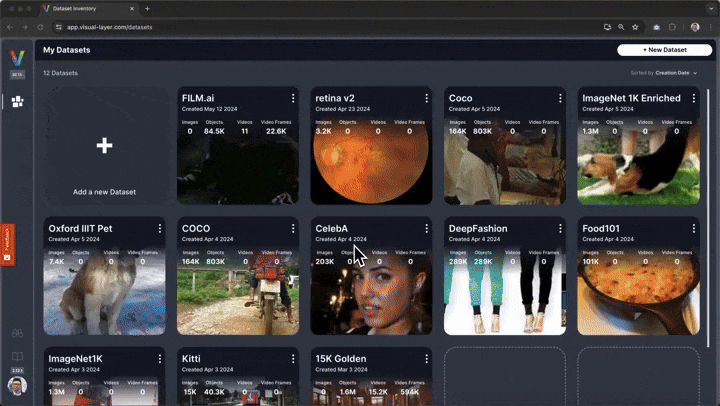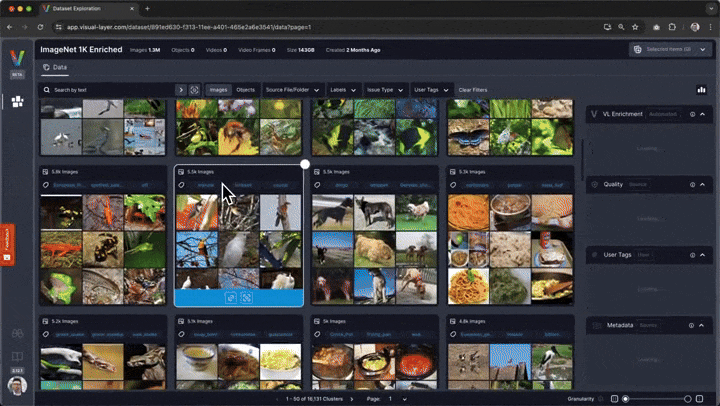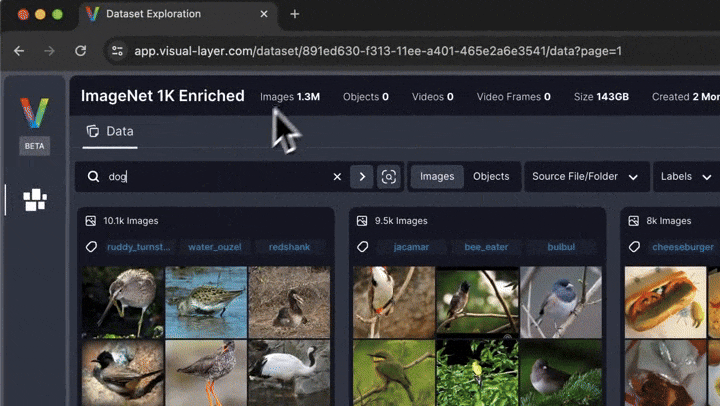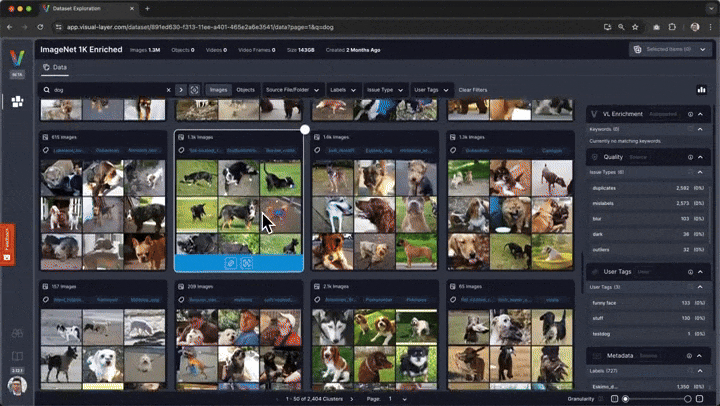
# You'll be presented with a web interface that lets you conveniently view, filter, and curate your dataset in a web interface.
#
#
# 
# ## Wrap Up
# In this tutorial, we showed how you can compute embeddings on your dataset using TIMM and run fastdup on top of it to surface dataset issues.
#
# Questions about this tutorial? Reach out to us on our [Slack channel](https://visuallayer.slack.com/)!
#
#
#
# Next, feel free to check out other tutorials -
#
# + ⚡ [**Quickstart**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/quick-dataset-analysis.ipynb): Learn how to install fastdup, load a dataset and analyze it for potential issues such as duplicates/near-duplicates, broken images, outliers, dark/bright/blurry images, and view visually similar image clusters. If you're new, start here!
# + 🧹 [**Clean Image Folder**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/cleaning-image-dataset.ipynb): Learn how to analyze and clean a folder of images from potential issues and export a list of problematic files for further action. If you have an unorganized folder of images, this is a good place to start.
# + 🖼 [**Analyze Image Classification Dataset**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/analyzing-image-classification-dataset.ipynb): Learn how to load a labeled image classification dataset and analyze for potential issues. If you have labeled ImageNet-style folder structure, have a go!
# + 🎁 [**Analyze Object Detection Dataset**](https://nbviewer.org/github/visual-layer/fastdup/blob/main/examples/analyzing-object-detection-dataset.ipynb): Learn how to load bounding box annotations for object detection and analyze for potential issues. If you have a COCO-style labeled object detection dataset, give this example a try.
#






