#!/usr/bin/env python
# coding: utf-8
# In[70]:
import transformers
import pandas as pd
import tensorflow as tf
from huggingface_hub import notebook_login
import os
transformers.logging.set_verbosity_error()
# In[71]:
notebook_login()
# A Whirlwind Tour of the 🤗 Hugging Face Ecosystem
#
# Christopher Akiki
#
# Figures in these slides reproduced under the Apache License from Natural Language Processing with Transformers published by O'Reilly Media, Inc.
# 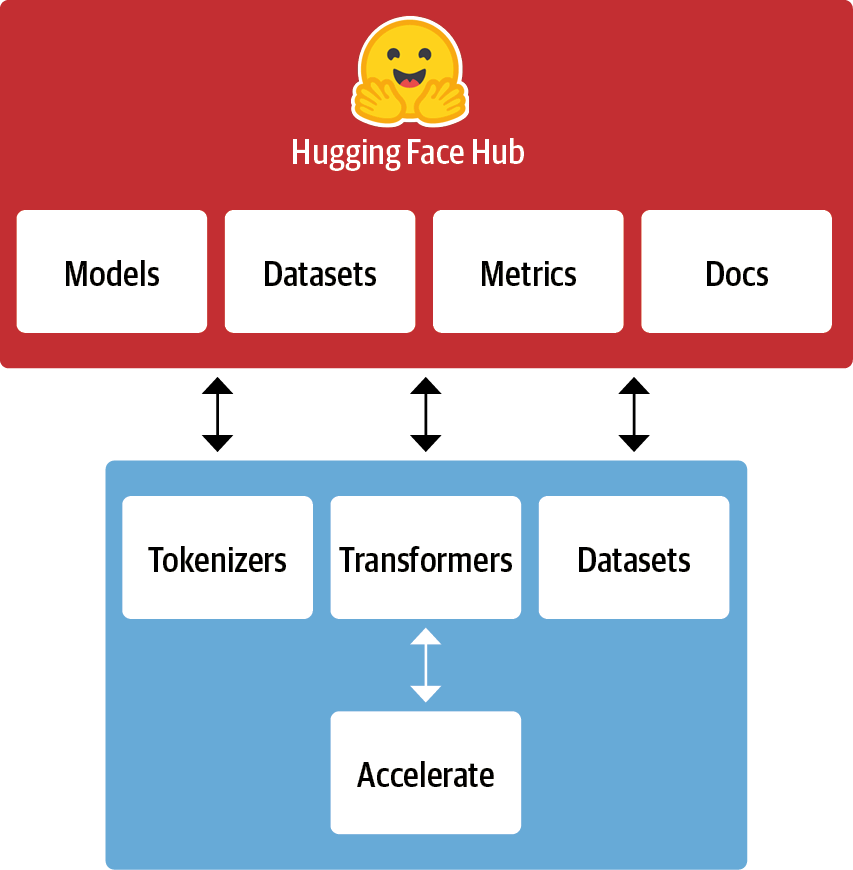 #
#  #
# 🤗 Pipelines
#
# In[1]:
from transformers import pipeline
from transformers.pipelines import get_supported_tasks
# In[5]:
print(get_supported_tasks())
#
# 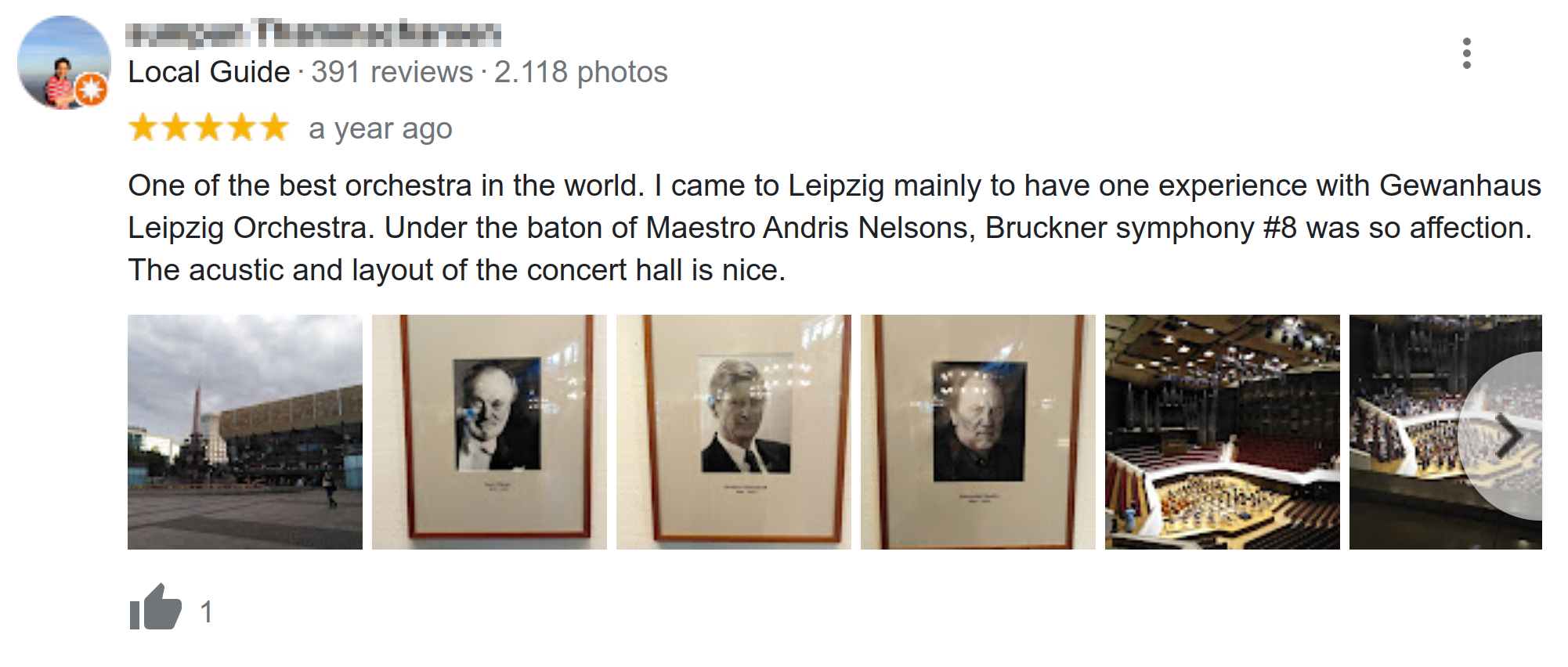 # In[7]:
text = """One of the best orchestra in the world. I came to Leipzig\
mainly to have one experience with Gewanhaus Leipzig Orchestra.
Under the baton of Maestro Andris Nelsons, Bruckner symphony #8 was so affection.
The acustic and layout of the concert hall is nice."""
# # Sentiment Analysis
# In[11]:
p = pipeline("text-classification",
model='distilbert-base-uncased-finetuned-sst-2-english', device=-1)
# In[9]:
outputs = p(text)
outputs[0]
# # Named-Entity Recognition
# In[12]:
p = pipeline("ner", aggregation_strategy="simple", model="dbmdz/bert-large-cased-finetuned-conll03-english", device=-1)
# In[13]:
outputs = p(text)
pd.DataFrame(outputs)
# # Question Answering
# In[23]:
p = pipeline("question-answering", model="distilbert-base-cased-distilled-squad", device=-1)
# In[34]:
questions = ['What city did I visit?',
'Why did I visit Leipzig?',
'What music did the orchestra play?',
'Who lead the orchestra?']
# In[42]:
outputs = p(question=questions, context=text)
with pd.option_context('display.max_colwidth', -1):
display(pd.DataFrame(zip(questions, [o['answer'] for o in outputs]), columns=['Question', 'Answer']))
# # Translation
# In[20]:
p = pipeline("translation_en_to_de",
model="Helsinki-NLP/opus-mt-en-de", device=-1)
# In[21]:
outputs = p(text, clean_up_tokenization_spaces=True)
print(outputs[0]['translation_text'])
#
# In[7]:
text = """One of the best orchestra in the world. I came to Leipzig\
mainly to have one experience with Gewanhaus Leipzig Orchestra.
Under the baton of Maestro Andris Nelsons, Bruckner symphony #8 was so affection.
The acustic and layout of the concert hall is nice."""
# # Sentiment Analysis
# In[11]:
p = pipeline("text-classification",
model='distilbert-base-uncased-finetuned-sst-2-english', device=-1)
# In[9]:
outputs = p(text)
outputs[0]
# # Named-Entity Recognition
# In[12]:
p = pipeline("ner", aggregation_strategy="simple", model="dbmdz/bert-large-cased-finetuned-conll03-english", device=-1)
# In[13]:
outputs = p(text)
pd.DataFrame(outputs)
# # Question Answering
# In[23]:
p = pipeline("question-answering", model="distilbert-base-cased-distilled-squad", device=-1)
# In[34]:
questions = ['What city did I visit?',
'Why did I visit Leipzig?',
'What music did the orchestra play?',
'Who lead the orchestra?']
# In[42]:
outputs = p(question=questions, context=text)
with pd.option_context('display.max_colwidth', -1):
display(pd.DataFrame(zip(questions, [o['answer'] for o in outputs]), columns=['Question', 'Answer']))
# # Translation
# In[20]:
p = pipeline("translation_en_to_de",
model="Helsinki-NLP/opus-mt-en-de", device=-1)
# In[21]:
outputs = p(text, clean_up_tokenization_spaces=True)
print(outputs[0]['translation_text'])
# 🤗 Tokenizers
#  # In[43]:
import nltk
nltk.download('gutenberg')
# In[44]:
print(nltk.corpus.gutenberg.fileids())
# In[45]:
moby_dick_raw = nltk.corpus.gutenberg.raw('melville-moby_dick.txt')
# In[46]:
size = len(moby_dick_raw.encode())
print(f"{size/1024**2:.2f} MiB")
# In[47]:
from tokenizers import Tokenizer, normalizers, pre_tokenizers, processors
from tokenizers.models import WordPiece
from tokenizers.trainers import WordPieceTrainer
# In[48]:
unk_token = "[UNK]"
pad_token = "[PAD]"
cls_token = "[CLS]"
sep_token = "[SEP]"
mask_token = "[MASK]"
special_tokens = [unk_token, pad_token, cls_token, sep_token, mask_token]
vocab_size = 6_000
# # WordPiece Tokenizer
# In[49]:
custom_tokenizer = Tokenizer(WordPiece(unk_token=unk_token))
# # Sequence of Normalizers
# In[50]:
custom_normalizer = normalizers.Sequence(
[normalizers.NFKD(), normalizers.Lowercase(), normalizers.StripAccents()]
)
# # Sequence of Pretokenizers
# In[51]:
custom_pre_tokenizer = pre_tokenizers.Sequence(
[pre_tokenizers.WhitespaceSplit(), pre_tokenizers.Punctuation()]
)
# # WordPiece Trainer
# In[52]:
custom_trainer = WordPieceTrainer(vocab_size=vocab_size, special_tokens=special_tokens, show_progress=False)
# In[53]:
custom_tokenizer.normalizer = custom_normalizer
custom_tokenizer.pre_tokenizer = custom_pre_tokenizer
# In[54]:
get_ipython().run_cell_magic('time', '', 'custom_tokenizer.train_from_iterator([moby_dick_raw], trainer=custom_trainer)\n')
# In[55]:
custom_tokenizer.get_vocab_size()
# In[56]:
encoding = custom_tokenizer.encode("Let us test this tokenizer")
print(encoding.tokens)
# In[58]:
cls_token_id = custom_tokenizer.token_to_id(cls_token)
sep_token_id = custom_tokenizer.token_to_id(sep_token)
custom_post_processor = processors.TemplateProcessing(
single=f"{cls_token}:0 $A:0 {sep_token}:0",
pair=f"{cls_token}:0 $A:0 {sep_token}:0 $B:1 {sep_token}:1",
special_tokens=[(cls_token, cls_token_id), (sep_token, sep_token_id)],
)
custom_tokenizer.post_processor = custom_post_processor
# In[59]:
encoding = custom_tokenizer.encode("Let us test this tokenizer")
print(encoding.tokens)
# In[60]:
encoding = custom_tokenizer.encode("This is the first sentence", "This is sentence number 2")
print(encoding.tokens)
print(encoding.ids)
print(encoding.type_ids)
# # Using our custom tokenizer with a model
# In[61]:
from transformers import PreTrainedTokenizerFast
model_tokenizer = PreTrainedTokenizerFast(
tokenizer_object=custom_tokenizer,
unk_token=unk_token,
pad_token=pad_token,
cls_token=cls_token,
sep_token=sep_token,
mask_token=mask_token,
)
# In[62]:
text_batch = ["To be or not to be.", "It was the best of times.", "Call me Ishmael."]
# In[63]:
model_tokenizer(text_batch, padding=True, return_tensors="tf")
#
# In[43]:
import nltk
nltk.download('gutenberg')
# In[44]:
print(nltk.corpus.gutenberg.fileids())
# In[45]:
moby_dick_raw = nltk.corpus.gutenberg.raw('melville-moby_dick.txt')
# In[46]:
size = len(moby_dick_raw.encode())
print(f"{size/1024**2:.2f} MiB")
# In[47]:
from tokenizers import Tokenizer, normalizers, pre_tokenizers, processors
from tokenizers.models import WordPiece
from tokenizers.trainers import WordPieceTrainer
# In[48]:
unk_token = "[UNK]"
pad_token = "[PAD]"
cls_token = "[CLS]"
sep_token = "[SEP]"
mask_token = "[MASK]"
special_tokens = [unk_token, pad_token, cls_token, sep_token, mask_token]
vocab_size = 6_000
# # WordPiece Tokenizer
# In[49]:
custom_tokenizer = Tokenizer(WordPiece(unk_token=unk_token))
# # Sequence of Normalizers
# In[50]:
custom_normalizer = normalizers.Sequence(
[normalizers.NFKD(), normalizers.Lowercase(), normalizers.StripAccents()]
)
# # Sequence of Pretokenizers
# In[51]:
custom_pre_tokenizer = pre_tokenizers.Sequence(
[pre_tokenizers.WhitespaceSplit(), pre_tokenizers.Punctuation()]
)
# # WordPiece Trainer
# In[52]:
custom_trainer = WordPieceTrainer(vocab_size=vocab_size, special_tokens=special_tokens, show_progress=False)
# In[53]:
custom_tokenizer.normalizer = custom_normalizer
custom_tokenizer.pre_tokenizer = custom_pre_tokenizer
# In[54]:
get_ipython().run_cell_magic('time', '', 'custom_tokenizer.train_from_iterator([moby_dick_raw], trainer=custom_trainer)\n')
# In[55]:
custom_tokenizer.get_vocab_size()
# In[56]:
encoding = custom_tokenizer.encode("Let us test this tokenizer")
print(encoding.tokens)
# In[58]:
cls_token_id = custom_tokenizer.token_to_id(cls_token)
sep_token_id = custom_tokenizer.token_to_id(sep_token)
custom_post_processor = processors.TemplateProcessing(
single=f"{cls_token}:0 $A:0 {sep_token}:0",
pair=f"{cls_token}:0 $A:0 {sep_token}:0 $B:1 {sep_token}:1",
special_tokens=[(cls_token, cls_token_id), (sep_token, sep_token_id)],
)
custom_tokenizer.post_processor = custom_post_processor
# In[59]:
encoding = custom_tokenizer.encode("Let us test this tokenizer")
print(encoding.tokens)
# In[60]:
encoding = custom_tokenizer.encode("This is the first sentence", "This is sentence number 2")
print(encoding.tokens)
print(encoding.ids)
print(encoding.type_ids)
# # Using our custom tokenizer with a model
# In[61]:
from transformers import PreTrainedTokenizerFast
model_tokenizer = PreTrainedTokenizerFast(
tokenizer_object=custom_tokenizer,
unk_token=unk_token,
pad_token=pad_token,
cls_token=cls_token,
sep_token=sep_token,
mask_token=mask_token,
)
# In[62]:
text_batch = ["To be or not to be.", "It was the best of times.", "Call me Ishmael."]
# In[63]:
model_tokenizer(text_batch, padding=True, return_tensors="tf")
# 🤗 Datasets
# # Apache Arrow backend ➡️ Low RAM use
#
#
#
# ```python
# import os; import psutil; import timeit
# from datasets import load_dataset
#
# mem_before = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)
# wiki = load_dataset("wikipedia", "20220301.en", split="train")
# mem_after = psutil.Process(os.getpid()).memory_info().rss / (1024 * 1024)
#
# print(f"RAM memory used: {(mem_after - mem_before)} MB")
#
# *****RAM memory used: 50 MB*****
# ```
#
# # Apache Arrow Backend ➡️ Fast Iteration
#
#
# ```python
# s = """batch_size = 1000
# for i in range(0, len(wiki), batch_size):
# batch = wiki[i:i + batch_size]
# """
# time = timeit.timeit(stmt=s, number=1, globals=globals())
# print(f"Time to iterate over the {wiki.dataset_size >> 30}GB dataset: {time:.1f} sec, "
# f"ie. {float(wiki.dataset_size >> 27)/time:.1f} Gb/s")
#
# *****Time to iterate over the 18 GB dataset: 70.5 sec, ie. 2.1 Gb/s*****
# ```
# In[12]:
from datasets import list_datasets, load_dataset
# In[13]:
all_datasets = list_datasets()
# In[14]:
len(all_datasets)
# In[15]:
[d for d in all_datasets if "emotion" in d]
# In[21]:
emotions = load_dataset("emotion")
emotions
# In[32]:
print(emotions['train'].info.description)
print(125*"*")
print(emotions['train'].citation)
# In[33]:
train_ds = emotions["train"]
train_ds
# In[38]:
train_ds.features['label']
# In[40]:
train_ds.features['label'].int2str(5)
# In[41]:
len(train_ds)
# In[44]:
train_ds[11]
# In[45]:
train_ds[:10]
# In[46]:
train_ds[:10]['text']
# In[47]:
def compute_tweet_length(row):
return {"tweet_length": len(row['text'].split())}
# In[48]:
train_ds = train_ds.map(compute_tweet_length, load_from_cache_file=False)
# In[ ]:
train_ds.push_to_hub('emotion-with-length')
# In[49]:
train_ds.filter(lambda row: row['tweet_length'] < 25)
# In[52]:
train_ds.sort("tweet_length")[:10]
# In[54]:
def batched_compute_tweet_length(batch_of_rows):
return {"tweet_length": [len(text.split()) for text in batch_of_rows['text']]}
# In[55]:
train_ds.map(batched_compute_tweet_length, batched=True, batch_size=2000, load_from_cache_file=False)
# In[56]:
get_ipython().run_line_magic('time', 'train_ds.map(compute_tweet_length, load_from_cache_file=False)')
# In[57]:
get_ipython().run_line_magic('time', 'train_ds.map(batched_compute_tweet_length, batched=True, batch_size=2000, load_from_cache_file=False, )')
# In[58]:
train_ds.column_names
# In[59]:
train_ds = train_ds.remove_columns('tweet_length')
train_ds
# # Loading your own files
# | Data format | Loading script | Example |
|---|
| CSV & TSV | csv | load_dataset("csv", data_files="my_file.csv") |
| Text files | text | load_dataset("text", data_files="my_file.txt") |
| JSON & JSON Lines | json | load_dataset("json", data_files="my_file.jsonl") |
| Pickled DataFrames | pandas | load_dataset("pandas", data_files="my_dataframe.pkl") |
# In[60]:
import pandas as pd
# In[61]:
emotions.set_format(type="pandas")
emotions_df = emotions['train'][:]
# In[62]:
emotions_df['label_name'] = emotions_df['label'].apply(lambda x: train_ds.features['label'].int2str(x))
# In[68]:
emotions_df.head(10)
# In[65]:
emotions_df['label_name'].value_counts()
# In[66]:
emotions_df['text'].str.split().apply(len).describe()
# In[ ]:
emotions.reset_format()
# In[ ]:
train_ds
# 🤗 Transformers
# 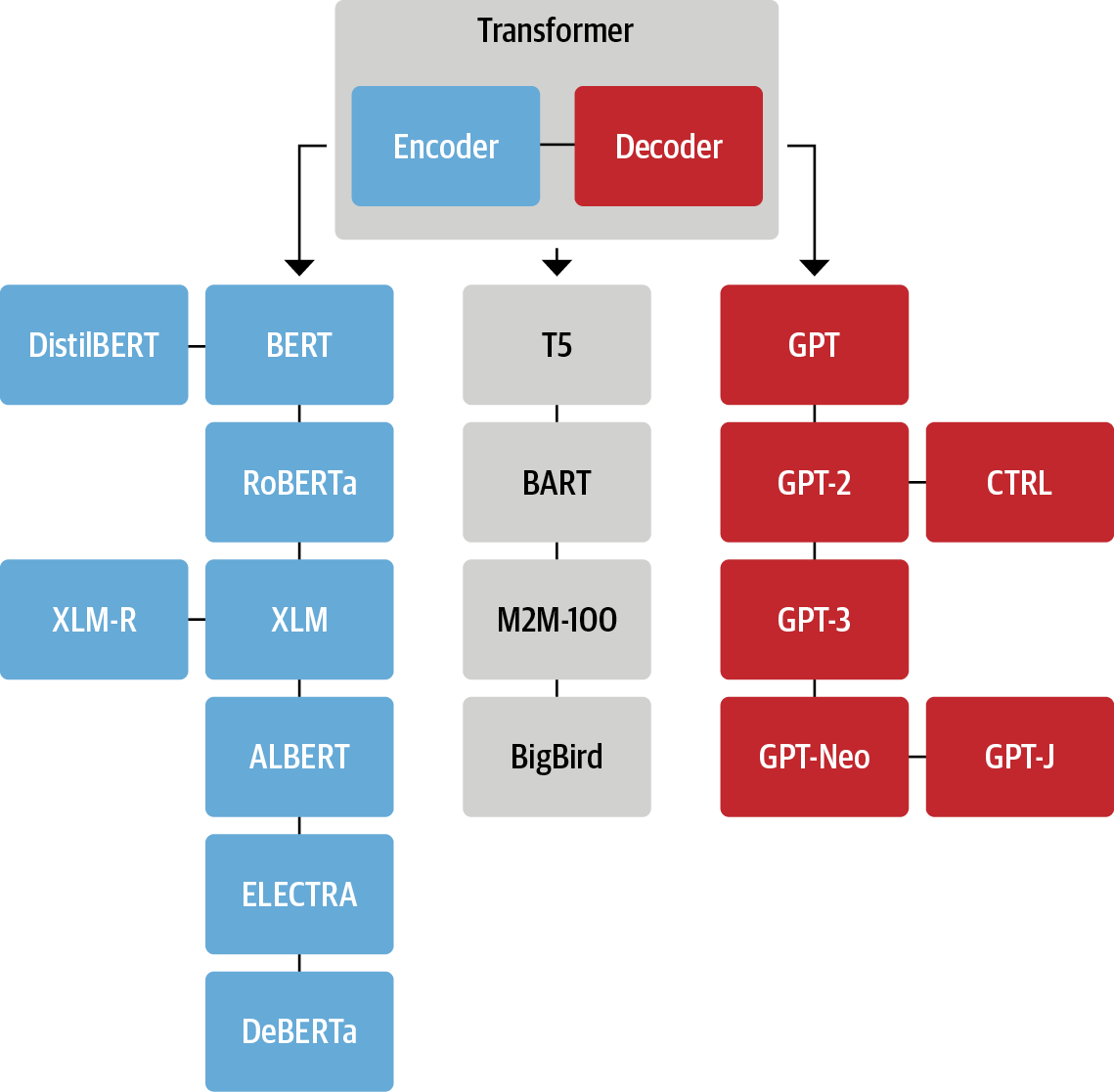 # In[ ]:
from transformers import DistilBertTokenizer, TFDistilBertForSequenceClassification, DataCollatorWithPadding
model_checkpoint = "distilbert-base-uncased"
#
# In[ ]:
from transformers import DistilBertTokenizer, TFDistilBertForSequenceClassification, DataCollatorWithPadding
model_checkpoint = "distilbert-base-uncased"
#
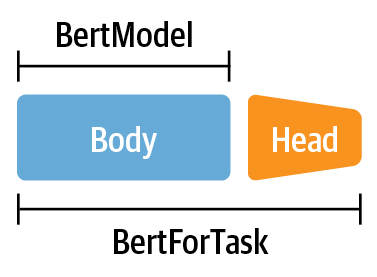 # # Transfer Learning via Feature Extraction (Homework)
#
# # Transfer Learning via Feature Extraction (Homework)
# 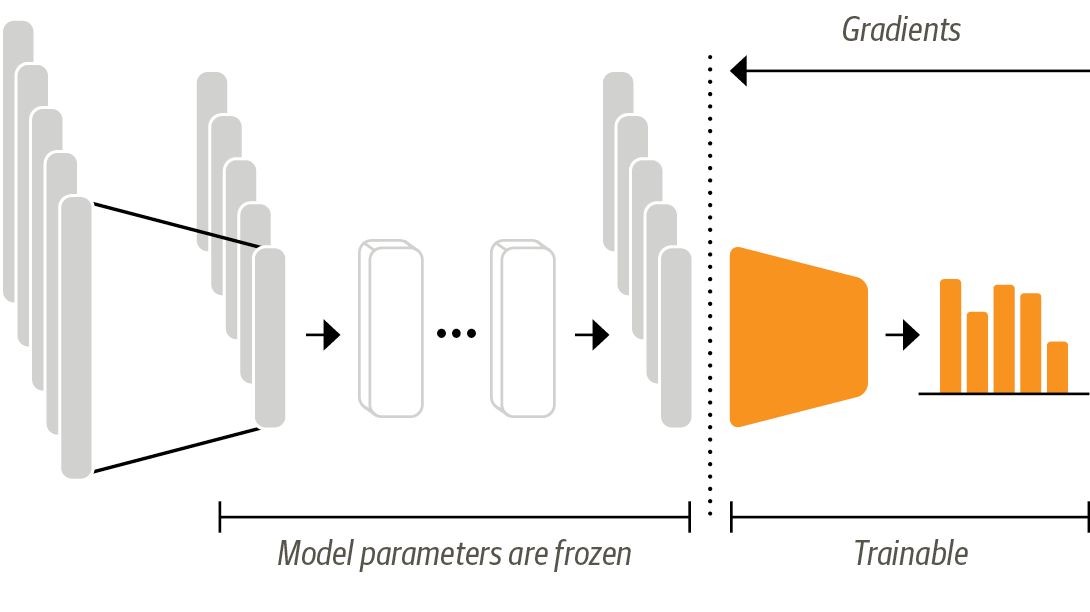 # # Transfer Learning via Finetuning
#
# # Transfer Learning via Finetuning
# 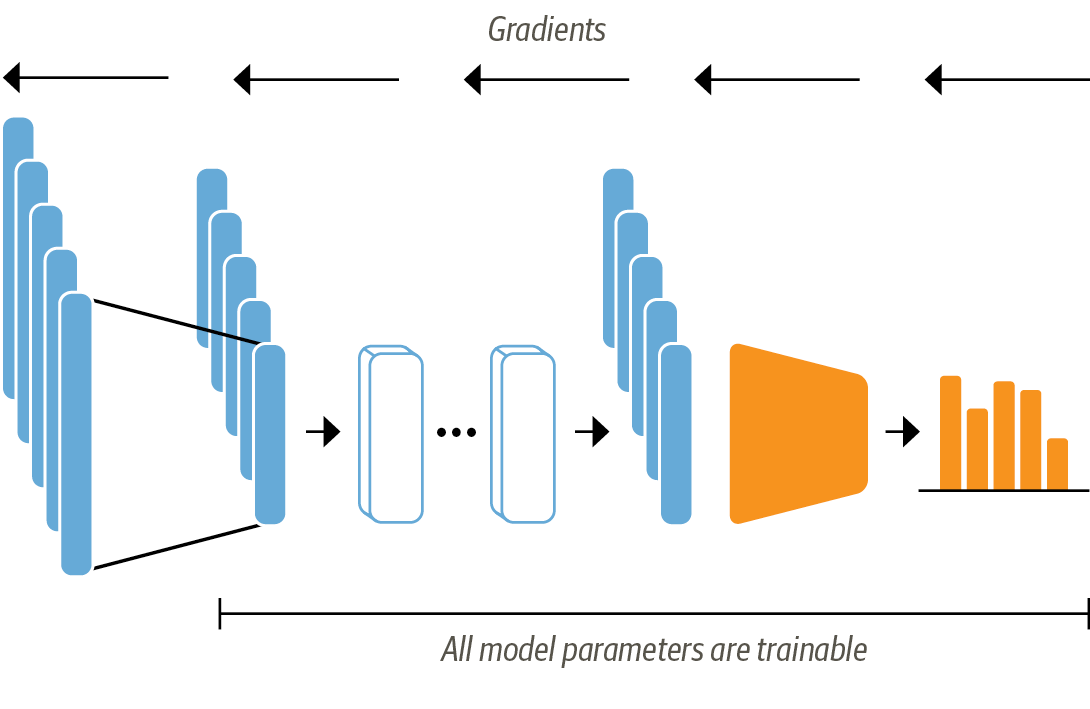 # In[ ]:
tokenizer = DistilBertTokenizer.from_pretrained(model_checkpoint)
# In[ ]:
tokenizer(["This is a test", "This is another test", "cat"], return_tensors="tf", padding=True, truncation=True)
# In[ ]:
def tokenize(batch):
return tokenizer(batch['text'], padding=True, truncation=True)
# In[ ]:
tokenized_train_ds = train_ds.map(tokenize, batched=True, batch_size=None)
tokenized_val_ds = emotions['validation'].map(tokenize, batched=True, batch_size=None)
tokenizer_test_ds = emotions['test'].map(tokenize, batched=True, batch_size=None)
# In[ ]:
BATCH_SIZE = 64
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
tf_train_dataset = tokenized_train_ds.to_tf_dataset(columns=tokenizer.model_input_names,
label_cols=['label'], shuffle=True, batch_size=BATCH_SIZE,
collate_fn=data_collator
)
tf_val_dataset = tokenized_val_ds.to_tf_dataset(columns=tokenizer.model_input_names,
label_cols=['label'], shuffle=False, batch_size=BATCH_SIZE,
collate_fn=data_collator
)
tf_test_dataset = tokenizer_test_ds.to_tf_dataset(columns=tokenizer.model_input_names,
label_cols=['label'], shuffle=False, batch_size=BATCH_SIZE,
collate_fn=data_collator
)
# In[ ]:
for i in tf_train_dataset.take(1):
print(i)
# In[ ]:
model = TFDistilBertForSequenceClassification.from_pretrained(model_checkpoint,
num_labels=train_ds.features['label'].num_classes)
# In[64]:
get_ipython().run_line_magic('load_ext', 'tensorboard')
get_ipython().run_line_magic('tensorboard', '--logdir /tf/model/logs --host 0.0.0.0')
# In[ ]:
from transformers.keras_callbacks import PushToHubCallback
from tensorflow.keras.callbacks import TensorBoard
tensorboard_callback = TensorBoard(log_dir="./model/logs")
push_to_hub_callback = PushToHubCallback(
output_dir="./model",
tokenizer=tokenizer,
hub_model_id=f"{model_checkpoint}-finetuned-tweet-sentiment",
)
callbacks = [tensorboard_callback, push_to_hub_callback]
# In[ ]:
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=5e-5),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=tf.metrics.SparseCategoricalAccuracy()
)
# In[ ]:
history = model.fit(tf_train_dataset, validation_data=tf_val_dataset, epochs=5, callbacks=callbacks)
# In[ ]:
_, accuracy = model.evaluate(tf_test_dataset)
print(f"Test accuracy: {round(accuracy * 100, 2)}%")
# In[ ]:
p = pipeline("text-classification", model='cakiki/distilbert-base-uncased-finetuned-tweet-sentiment', device=-1)
# In[ ]:
p("I am terrified")
# In[ ]:
emotions['train'].features
# In[ ]:
import gradio as gr
gr.Interface.load("huggingface/cakiki/distilbert-base-uncased-finetuned-tweet-sentiment").launch(share=True);
#
# In[ ]:
tokenizer = DistilBertTokenizer.from_pretrained(model_checkpoint)
# In[ ]:
tokenizer(["This is a test", "This is another test", "cat"], return_tensors="tf", padding=True, truncation=True)
# In[ ]:
def tokenize(batch):
return tokenizer(batch['text'], padding=True, truncation=True)
# In[ ]:
tokenized_train_ds = train_ds.map(tokenize, batched=True, batch_size=None)
tokenized_val_ds = emotions['validation'].map(tokenize, batched=True, batch_size=None)
tokenizer_test_ds = emotions['test'].map(tokenize, batched=True, batch_size=None)
# In[ ]:
BATCH_SIZE = 64
data_collator = DataCollatorWithPadding(tokenizer=tokenizer, return_tensors="tf")
tf_train_dataset = tokenized_train_ds.to_tf_dataset(columns=tokenizer.model_input_names,
label_cols=['label'], shuffle=True, batch_size=BATCH_SIZE,
collate_fn=data_collator
)
tf_val_dataset = tokenized_val_ds.to_tf_dataset(columns=tokenizer.model_input_names,
label_cols=['label'], shuffle=False, batch_size=BATCH_SIZE,
collate_fn=data_collator
)
tf_test_dataset = tokenizer_test_ds.to_tf_dataset(columns=tokenizer.model_input_names,
label_cols=['label'], shuffle=False, batch_size=BATCH_SIZE,
collate_fn=data_collator
)
# In[ ]:
for i in tf_train_dataset.take(1):
print(i)
# In[ ]:
model = TFDistilBertForSequenceClassification.from_pretrained(model_checkpoint,
num_labels=train_ds.features['label'].num_classes)
# In[64]:
get_ipython().run_line_magic('load_ext', 'tensorboard')
get_ipython().run_line_magic('tensorboard', '--logdir /tf/model/logs --host 0.0.0.0')
# In[ ]:
from transformers.keras_callbacks import PushToHubCallback
from tensorflow.keras.callbacks import TensorBoard
tensorboard_callback = TensorBoard(log_dir="./model/logs")
push_to_hub_callback = PushToHubCallback(
output_dir="./model",
tokenizer=tokenizer,
hub_model_id=f"{model_checkpoint}-finetuned-tweet-sentiment",
)
callbacks = [tensorboard_callback, push_to_hub_callback]
# In[ ]:
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=5e-5),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=tf.metrics.SparseCategoricalAccuracy()
)
# In[ ]:
history = model.fit(tf_train_dataset, validation_data=tf_val_dataset, epochs=5, callbacks=callbacks)
# In[ ]:
_, accuracy = model.evaluate(tf_test_dataset)
print(f"Test accuracy: {round(accuracy * 100, 2)}%")
# In[ ]:
p = pipeline("text-classification", model='cakiki/distilbert-base-uncased-finetuned-tweet-sentiment', device=-1)
# In[ ]:
p("I am terrified")
# In[ ]:
emotions['train'].features
# In[ ]:
import gradio as gr
gr.Interface.load("huggingface/cakiki/distilbert-base-uncased-finetuned-tweet-sentiment").launch(share=True);
# (Re)sources
# - https://github.com/nlp-with-transformers/notebooks
#
# - https://huggingface.co/docs
#
# - https://github.com/huggingface/course / https://github.com/huggingface/notebooks
#
# - https://github.com/NielsRogge/Transformers-Tutorials
#
#  # In[ ]:
# In[ ]: