Benchmarking your Hadoop file system with TestDFSIO¶
Outline¶
- Introduction
- HDFS: the Hadoop Distributed File System
- TestDFSIO basic usage
- How to interpret the results
- Clean up
- Useful links
Introduction¶
HDFS (Hadoop Distributed File System) is the basis of the Hadoop Big Data framework. HDFS offers fault tolerance thanks to the replication of data across the underlying cluster. TestDFSIO is a tool included in the Hadoop software distribution that is meant to measure the data read and write performance of your HDFS installation.
HDFS: the Hadoop Distributed File System¶
Large amounts of data are collected every day that traditional technologies cannot handle. "Big Data" has become the catch-all term for massive amounts of data as well as for frameworks and R&D initiatives aimed at working with it efficiently. Apache Hadoop is one of the most widely adopted such frameworks for Big Data processing.
The two core component of Hadoop are the Hadoop Distributed File System HDFS and the cluster and resource manager YARN (Yet Another Resource Negotiatior).
The file system HDFS is designed to run on clusters of computers and provides a reliable and efficient solution for working with large (in the GB or even TB scale) datasets. HDFS is written in Java and was originally inspired by the Google File System (GFS or GoogleFS), providing its open-source alternative.
One of the core features of HDFS is fault tolerance or high availability: this is the capability of a system to maintain continuous operations even in the event of failure of one of its parts (both hardware or software). Fault tolerance in HDFS is achieved through data replication: data is simply stored in multiple copies across different hosts.
Here is a diagram showing the architecture of a Hadoop cluster. The NameNode is responsible for storing the filesystem's metadata, whereas DataNodes store the actual data. While data storage is fault-tolerant, the name node might constitute a single point-of-failure. Therefore typically one standby NameNode service runs on one of the data nodes, providing a backup in case of failure of the main NameNode.
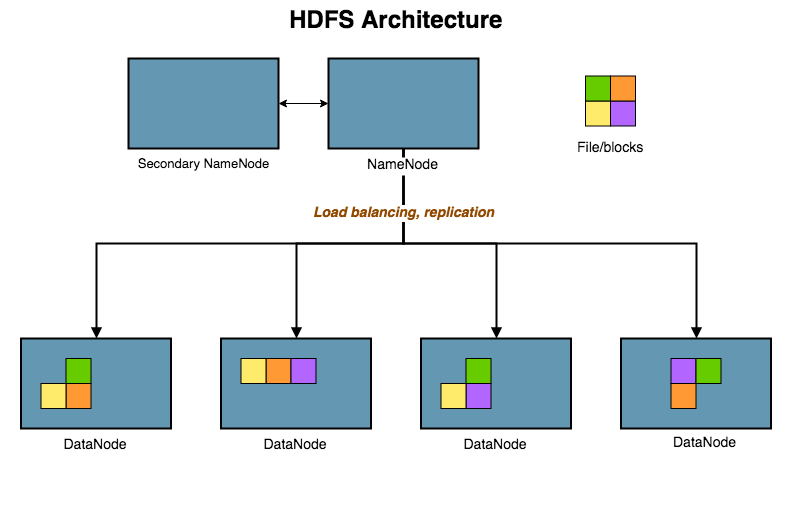 Hadoop's file system reliability through data replication clearly comes at the cost of performance. Many data processing scenarios (also known as extract, transform, load, or ETL procedures) consist a sequence of MapReduce jobs. The two main performance shortcomings in iterative computations are due to the interplay of
Hadoop's file system reliability through data replication clearly comes at the cost of performance. Many data processing scenarios (also known as extract, transform, load, or ETL procedures) consist a sequence of MapReduce jobs. The two main performance shortcomings in iterative computations are due to the interplay of
- intermediate data storage
- replication
Intermediate data in fact needs to be persisted at each step in multiple copies (the number of copies is the HDFS replication factor, typically ≥ 3).
TestDFSio¶
TestDFSio is a tool for measuring the performance of read and write operations on HDFS and can be used to measure performance, benchmark, or stress-test a Hadoop cluster.
TestDFSio uses MapReduce to write files to the HDFS filesystem spanning one mapper for file; the reducer is used to collect and summarize test data.
TestDFSIO basic usage¶
To run write or read tests you first need to locate the test file hadoop-mapreduce-client-jobclient*tests.jar. In our Cloudera installation this is located in:
/opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient.jar.
Options¶
-writeto run write tests-readto run read tests-nrFilesthe number of files (set to be equal to the number of mappers)-fileSizesize of files (followed by B|KB|MB|GB|TB)
TestDFSIO generates exactly 1 map task per file, so it is a 1:1 mapping from files to map tasks.
Specify custom i/o directory¶
to avoid permission problems (you need to have read/write access to /benchmarks/TestDFSIO on HDFS).
By default TestHDFSio uses the HDFS directory /benchmarks to read and write, therefore it is recommended to run the tests as hdfs.
In case you want to run the tests as a user who has no write permissions on HDFS' root folder (/), you can specify an alternative directory with the -D assigning a new value to test.build.data:
Running a write test¶
We are going to run a test with nrFiles files, each of size fileSize, using a custom output directory.
%%bash
export myDir=/user/${USER}/benchmarks
export nrFiles=80
export fileSize=10GB
cd ~
yarn jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -D test.build.data=$myDir -write -nrFiles $nrFiles -fileSize $fileSize
Output 25.7.2019 (20 files of size 10GB, 200GB total)¶
Note: in order to activate more than one node for the read/write operations, we need to configure the test job with more than 46 jobs (where nr. of jobs=nr. of mappers). This is because each node has 48 virtual CPUs and 46 are available (1 physical CPU or two virtualCPUs are reserved for the node's OS and bookkeeping).
19/07/25 15:07:02 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
19/07/25 15:07:02 INFO fs.TestDFSIO: Date & time: Thu Jul 25 15:07:02 CEST 2019
19/07/25 15:07:02 INFO fs.TestDFSIO: Number of files: 20
19/07/25 15:07:02 INFO fs.TestDFSIO: Total MBytes processed: 204800.0
19/07/25 15:07:02 INFO fs.TestDFSIO: Throughput mb/sec: 38.77458674204487
19/07/25 15:07:02 INFO fs.TestDFSIO: Average IO rate mb/sec: 39.016483306884766
19/07/25 15:07:02 INFO fs.TestDFSIO: IO rate std deviation: 3.2993795422143273
19/07/25 15:07:02 INFO fs.TestDFSIO: Test exec time sec: 301.748
Running a read test¶
We are going to run a test with nrFiles files, each of size fileSize.
%%bash
export myDir=/user/${USER}/benchmarks
export nrFiles=10
export fileSize=10GB
cd ~
yarn jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -D test.build.data=$myDir -read -nrFiles $nrFiles -fileSize $fileSize
Output 25.7.2019 (20 files of size 10GB, 200GB total)¶
19/07/25 15:13:39 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
19/07/25 15:13:39 INFO fs.TestDFSIO: Date & time: Thu Jul 25 15:13:39 CEST 2019
19/07/25 15:13:39 INFO fs.TestDFSIO: Number of files: 20
19/07/25 15:13:39 INFO fs.TestDFSIO: Total MBytes processed: 204800.0
19/07/25 15:13:39 INFO fs.TestDFSIO: Throughput mb/sec: 72.07788071321907
19/07/25 15:13:39 INFO fs.TestDFSIO: Average IO rate mb/sec: 97.98143005371094
19/07/25 15:13:39 INFO fs.TestDFSIO: IO rate std deviation: 83.42162014957364
19/07/25 15:13:39 INFO fs.TestDFSIO: Test exec time sec: 185.435
Run a write test with replication=1¶
In order to measure the effect of replication on the overall throughput, we are going to run a write test with replication factor 1 (no replication).
%%bash
export myDir=/user/${USER}/benchmarks
export nrFiles=10
export fileSize=10GB
cd ~
hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -D test.build.data=$myDir -D dfs.replication=1 -write -nrFiles 20 -fileSize 10GB
Output 1 (20 files of size 10GB, 200GB total)¶
19/07/25 15:44:26 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
19/07/25 15:44:26 INFO fs.TestDFSIO: Date & time: Thu Jul 25 15:44:26 CEST 2019
19/07/25 15:44:26 INFO fs.TestDFSIO: Number of files: 20
19/07/25 15:44:26 INFO fs.TestDFSIO: Total MBytes processed: 204800.0
19/07/25 15:44:26 INFO fs.TestDFSIO: Throughput mb/sec: 39.38465325447428
19/07/25 15:44:26 INFO fs.TestDFSIO: Average IO rate mb/sec: 39.59946060180664
19/07/25 15:44:26 INFO fs.TestDFSIO: IO rate std deviation: 3.0182194679812717
19/07/25 15:44:26 INFO fs.TestDFSIO: Test exec time sec: 292.66
Output 2 (20 files of size 10GB, 200GB total)¶
19/09/12 14:03:49 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
19/09/12 14:03:49 INFO fs.TestDFSIO: Date & time: Thu Sep 12 14:03:49 CEST 2019
19/09/12 14:03:49 INFO fs.TestDFSIO: Number of files: 20
19/09/12 14:03:49 INFO fs.TestDFSIO: Total MBytes processed: 204800
19/09/12 14:03:49 INFO fs.TestDFSIO: Throughput mb/sec: 41.18
19/09/12 14:03:49 INFO fs.TestDFSIO: Average IO rate mb/sec: 41.22
19/09/12 14:03:49 INFO fs.TestDFSIO: IO rate std deviation: 1.33
19/09/12 14:03:49 INFO fs.TestDFSIO: Test exec time sec: 275.41
19/09/12 14:03:49 INFO fs.TestDFSIO:
Advanced test configuration¶
read options¶
In addition to the default sequential file access, the mapper class for reading data can be configured to perform various types of random reads:
- random read always chooses a random position to read from (skipSize = 0)
- backward read reads file in reverse order (skipSize < 0)
- skip-read skips skipSize bytes after every read (skipSize > 0)
Using compression¶
The -compression option allows to specify a codec for the input and output of data.
What is a codec¶
Codec is a portmanteau of coder and decoder and it designates any hardware or software device that is used to encode—most commonly also reducing the original size—and decode information. Hadoop provides classes that encapsulate compression and decompression algorithms, such as GzipCodec for the gzip algorithm.
These are all currently available Hadoop compression codecs:
| Compression format | Hadoop CompressionCodec |
|---|---|
| DEFLATE | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| LZO | com.hadoop.compression.lzo.LzopCodec |
| LZ4 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
More options¶
For more options see usage:
$ hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -help Usage: TestDFSIO [genericOptions] -read [-random | -backward | -skip [-skipSize Size]] | -write | -append | -clean [-compression codecClassName] [-nrFiles N] [-size Size[B|KB|MB|GB|TB]] [-resFile resultFileName] [-bufferSize Bytes]
How to interpret the results¶
The main measurements produced by the HDFSio test are:
- throughput in mb/sec
- average IO rate in mb/sec
- standard deviation of the IO rate
- test execution time
All test results are logged by default to the file TestDFSIO_results.log. The log file can be changed with the option -resFile resultFileName.
!tail -8 cd ~/TestDFSIO_results.log
What is throughput¶
Throughput or data transfer rate measures the amount of data read or written (expressed in Megabytes per second -- MB/s) to the filesystem.
Throughput is one of the main performance measures used by disk manufacturers as knowing how fast data can be moved around in a disk is an important important factor to look at.
What is IO rate¶
IO rate also abbreviated as IOPS measures IO operations per second, which means the amount of read or write operations that could be done in one seconds time. A certain amount of IO operations will also give a certain throughput of Megabytes each second, so these two are related. The linking factor is the size of each IO request. This may vary depending on the operating system and the application or service that needs disk access.
Throughput and IO rate in a formula:
Average IO size x IOPS = Throughput in MB/s
The block size in our HDFS installation is the standard value of 128MiB
Concurrent versus overall throughput¶
The listed throughput shows the average throughput among all the map tasks. To get an approximate overall throughput on the cluster you can divide the total MBytes by the test execution time in seconds.
Clean up¶
To remove test files and free up space after completing the test use the option clean.
Note that files will be overwritten, so if you perform a series of tests using the same directory it is only necessary to clean up at the end.
%%bash
export myDir=/user/${USER}/benchmarks
hadoop jar /opt/cloudera/parcels/CDH/lib/hadoop-mapreduce/hadoop-mapreduce-client-jobclient-tests.jar TestDFSIO -D test.build.data=$myDir -clean
Further reading and some useful links¶
TestDFSIO does not have an official documentation but the source file TestDFSIO.java is available in the Apache source code repository.
- Distributed I/O Benchmark of HDFS
- Benchmarking and Stress Testing an Hadoop Cluster with TeraSort, TestDFSIO & Co.
- Improve TestDFSIO
- Running Hadoop Benchmarking TestDFSIO on Cloudera Clusters
- Hadoop Performance Evaluation by Benchmarking and Stress Testing with TeraSort and TestDFSIO
- TestDFSIO source code on