A Dockerfile that will produce a container with all the dependencies necessary to run this notebook is available here.
%matplotlib inline
from warnings import filterwarnings
from matplotlib import pyplot as plt
from matplotlib.patches import Ellipse
from matplotlib.ticker import StrMethodFormatter
import numpy as np
import pandas as pd
import scipy as sp
import seaborn as sns
from statsmodels.datasets import get_rdataset
# configure pyplot for readability when rendered as a slideshow and projected
plt.rc('figure', figsize=(8, 6))
LABELSIZE = 14
plt.rc('axes', labelsize=LABELSIZE)
plt.rc('axes', titlesize=LABELSIZE)
plt.rc('figure', titlesize=LABELSIZE)
plt.rc('legend', fontsize=LABELSIZE)
plt.rc('xtick', labelsize=LABELSIZE)
plt.rc('ytick', labelsize=LABELSIZE)
filterwarnings('ignore', 'findfont')
blue, green, red, purple, gold, teal = sns.color_palette()
pct_formatter = StrMethodFormatter('{x:.1%}')
SEED = 54902 # from random.org, for reproducibility
np.random.seed(SEED)
Open Source Bayesian Inference in Python with PyMC3¶
FOSSCON • Philadelphia • August 26, 2017¶
@AustinRochford¶
Who am I?¶

@AustinRochford • GitHub • Website¶
austin.rochford@gmail.com • arochford@monetate.com¶
PyMC3 developer • Principal Data Scientist at Monetate Labs¶
Bayesian Inference¶
A motivating question:
A rare disease is present in one out of one hundred thousand people. A test gives the correct diagnosis 99.9% of the time. What is the probability that a person that tests positive has the disease?
Conditional Probability¶
Conditional probability is the probability that one event will happen, given that another event has occured.
Our question,
A rare disease is present in one out of one hundred thousand people. A test gives the correct diagnosis 99.9% of the time. What is the probability that a person that tests positive has the disease?
becomes

Bayes' Theorem follows directly from the definition of conditional probability.
$$ \begin{align*} P(A\ |\ B) P(B) & = P(A \textrm{ and } B) \\ & = P(B \textrm{ and } A) \\ & = P(B\ |\ A) P(A). \end{align*} $$Dividing by $P(B)$ yields Bayes' theorem. Each component of Bayes' Theorem has a name. The posterior distribution is equal to the joint distribution divided by the marginal distribution of the evidence.
$$\color{red}{P(A\ |\ B)} = \frac{\color{blue}{P(B\ |\ A)\ P(A)}}{\color{green}{P(B)}}.$$For many useful models the marginal distribution of the evidence is hard or impossible to calculate analytically.
The first step below follows from Bayes' theorem, the second step follows from the law of total probability.
Strikingly, a person that tests positive has a less than 1% chance of actually having the disease! (Worryingly, only 21% of doctors answered this question correctly in a recent study.)
0.999 * 1e-5 / (0.999 * 1e-5 + 0.001 * (1 - 1e-5))
0.009891284975940117
Probabilistic Programming for Bayesian Inference¶
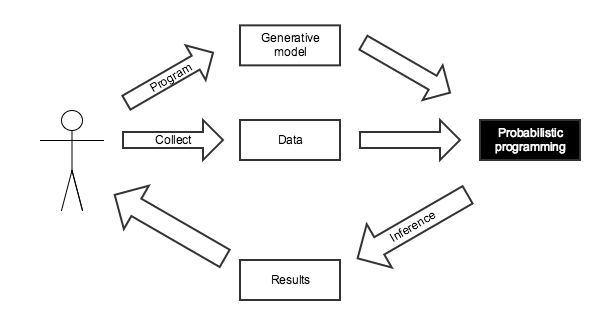
This calculation was tedious to do by hand, and only had a closed form answer because of the simplicity of this situation.

We know the disease is present in one in one hundred thousand people.
The Bernoulli distribution gives the probability that a weighted coin flip comes up heads. If $X \sim \textrm{Bernoulli}(p),$
$$ \begin{align*} P(X = 1) & = p \\ P(X = 0) & = 1 - p. \end{align*} $$import pymc3 as pm
with pm.Model() as disease_model:
has_disease = pm.Bernoulli('has_disease', 1e-5)
If a person has the disease, there is a 99.9% chance they test positive. If they do not have the disease, there is a 0.1% chance they test positive.
with disease_model:
p_test_pos = has_disease * 0.999 + (1 - has_disease) * 0.001
This person has tested positive for the disease.
with disease_model:
test_pos = pm.Bernoulli('test_pos', p_test_pos, observed=1)
What is the probability that this person has the disease?
with disease_model:
disease_trace = pm.sample(draws=10000, random_seed=SEED)
Assigned BinaryGibbsMetropolis to has_disease 100%|██████████| 10500/10500 [00:04<00:00, 2427.46it/s]
The disease_trace object contains samples from the posterior distribution of has_disease, given that we have observed a positive test.
disease_trace['has_disease']
array([0, 0, 0, ..., 0, 0, 0])
The mean of the posterior samples of has_disease is the posterior probability that the person has the disease, given that they tested positive.
disease_trace['has_disease'].mean()
0.0104
0.999 * 1e-5 / (0.999 * 1e-5 + 0.001 * (1 - 1e-5))
0.009891284975940117
Monte Carlo Methods¶
Monte Carlo methods use random sampling to approximate quantities that are difficult or impossible to calculate analytically. They are used extensively in Bayesian inference, where the marginal distribution of the evidence is usually impossible to calculate analytically for interesting models.
First we generate 5,000 points randomly distributed in a square of area one.
N = 5000
x, y = np.random.uniform(0, 1, size=(2, N))
fig, ax = plt.subplots()
ax.set_aspect('equal');
ax.scatter(x, y, c='k', alpha=0.5);
ax.set_xticks([0, 1]);
ax.set_xlim(0, 1.01);
ax.set_yticks([0, 1]);
ax.set_ylim(0, 1.01);

fig
By counting the number of these points that fall inside the quarter circle of radius one, we get an approximation of the area of this quarter circle, which is $\frac{\pi}{4}$.
in_circle = x**2 + y**2 <= 1
fig, ax = plt.subplots()
ax.set_aspect('equal');
x_plot = np.linspace(0, 1, 100)
ax.plot(x_plot, np.sqrt(1 - x_plot**2), c='k');
ax.scatter(x[in_circle], y[in_circle], c=green, alpha=0.5);
ax.scatter(x[~in_circle], y[~in_circle], c=red, alpha=0.5);
ax.set_xticks([0, 1]);
ax.set_xlim(0, 1.01);
ax.set_yticks([0, 1]);
ax.set_ylim(0, 1.01);

fig
Sure enough, four times the approximation of the quarter circle's area is quite close to $\pi$. More samples would lead to a better approximation.
4 * in_circle.mean()
3.1272000000000002
History of Monte Carlo Methods¶

Monte Carlo methods were used extensively in the Manhattan Project. Pictured above are Manhattan Project scientists Stanislaw_Ulam, Richard Feynman, and John von Neumann. While working on the Manhattan Project, Ulam gave one of the first descriptions of Markov Chain Monte Carlo algorithms. The Stan probabilistic programming package is named in his honor.
The Monty Hall Problem¶

The Monty Hall problem is a famous probability puzzle, based on the 1960s game show Let's Make a Deal and named after its original host. In the show, a contestant would be presented with three unmarked doors, two of which contained an item of little to no value (for example, a goat) and one of which contained a very valuable item (for example, a sportscar). The contestant would make an initial guess of which door contained the sportscar. After the contestant's intial guess, Monty would open on of the other two doors, revealing a goat. Monty would then offer the contestant the chance to change their choice of door. The Monty Hall problem asks, should the contestant keep their initial choice of door, or change it?
Initially, we have no information about which door the prize is behind.
with pm.Model() as monty_model:
prize = pm.DiscreteUniform('prize', 0, 2)
If we choose door one:
| Prize behind | Door 1 | Door 2 | Door 3 |
|---|---|---|---|
| Door 1 | No | Yes | Yes |
| Door 2 | No | No | Yes |
| Door 3 | No | Yes | No |
from theano import tensor as tt
with monty_model:
p_open = pm.Deterministic('p_open',
tt.switch(tt.eq(prize, 0),
# it is behind the first door
np.array([0., 0.5, 0.5]),
tt.switch(tt.eq(prize, 1),
# it is behind the second door
np.array([0., 0., 1.]),
# it is behind the third door
np.array([0., 1., 0.]))))
Monty opened the third door, revealing a goat.
with monty_model:
opened = pm.Categorical('opened', p_open, observed=2)
Should we switch our choice of door?
with monty_model:
monty_trace = pm.sample(draws=10000, random_seed=SEED)
monty_df = pm.trace_to_dataframe(monty_trace)
Assigned Metropolis to prize 100%|██████████| 10500/10500 [00:02<00:00, 4427.89it/s]
monty_df.prize.head()
0 0 1 0 2 0 3 0 4 1 Name: prize, dtype: int64
fig, ax = plt.subplots(figsize=(8, 6))
ax = (monty_df.groupby('prize')
.size()
.div(monty_df.shape[0])
.plot(kind='bar', ax=ax))
ax.set_xlabel("Door");
ax.yaxis.set_major_formatter(pct_formatter);
ax.set_ylabel("Probability of prize");

fig
Yes, we should switch our choice of door.
Optional
We can also resolve the Monty Hall problem with pen and paper, as follows.
Throughout this calculation, all probabilities assume that we have initially chosen the first door. By Bayes' Theorem, the probability that the sportscar is behind door one given that Monty opened door three is
$$P(\textrm{Behind door one}\ |\ \textrm{Opened door three}) = \frac{P(\textrm{Opened door three}\ |\ \textrm{Behind door one})P(\textrm{Behind door one})}{P(\textrm{Opened door three})}.$$The a priori probability that the prize is behind any of the doors is one third. From the table above, $P(\textrm{Opened door three}\ |\ \textrm{Behind door one}) = \frac{1}{2}$. We calculate $P(\textrm{Opened door three})$ using the law of total probability as follows:
$$ \begin{align*} P(\textrm{Opened door three}) & = P(\textrm{Opened door three}\ |\ \textrm{Behind door one})P(\textrm{Behind door one}) \\ & + P(\textrm{Opened door three}\ |\ \textrm{Behind door two})P(\textrm{Behind door two}) \\ & + P(\textrm{Opened door three}\ |\ \textrm{Behind door three})P(\textrm{Behind door three}) \\ & = \frac{1}{2} \cdot \frac{1}{3} + 1 \cdot \frac{1}{3} + 0 \cdot \frac{1}{3} \\ & = \frac{1}{2}. \end{align*} $$Therefore
$$ \begin{align*} P(\textrm{Behind door one}\ |\ \textrm{Opened door three}) & = \frac{P(\textrm{Opened door three}\ |\ \textrm{Behind door one})P(\textrm{Behind door one})}{P(\textrm{Opened door three})} \\ & = \frac{\frac{1}{2} \cdot \frac{1}{3}}{\frac{1}{3}} \\ & = \frac{1}{3}. \end{align*}$$Since $P(\textrm{Behind door three}\ |\ \textrm{Opened door three}) = 0$, because Monty wants the contestant's choice to be suspensful, $P(\textrm{Behind door two}\ |\ \textrm{Opened door three}) = \frac{2}{3}$. Therefore it is correct to switch doors, confirming our computational results.
Introduction to PyMC3¶
From the PyMC3 documentation:
PyMC3 is a Python package for Bayesian statistical modeling and Probabilistic Machine Learning which focuses on advanced Markov chain Monte Carlo and variational fitting algorithms. Its flexibility and extensibility make it applicable to a large suite of problems.
![]()

As of October 2016, PyMC3 is a NumFOCUS fiscally sponsored project.
Features¶
- Uses Theano as a computational backend
- Automated differentiation, dynamic C compilation, GPU integration
- Implements Hamiltonian Monte Carlo and No-U-Turn sampling
- High-level GLM (
R-like syntax) and Gaussian process specification - General framework for variational inference
If you are interested in starting to contribute, we maintain a list of beginner friendly issues on GitHub that require minimal knowledge of the existing codebase to resolve. We also have an active Discourse forum for discussion PyMC3 development and usage, and a somewhat less active Gitter chat.

We're also a friendly group of software engineers, statisticians, and data scientists spread across North America and Europe.

Case Study: Sleep Deprivation¶

The data for this example are from the lme4 R package, which got them from
Gregory Belenky, Nancy J. Wesensten, David R. Thorne, Maria L. Thomas, Helen C. Sing, Daniel P. Redmond, Michael B. Russo and Thomas J. Balkin (2003) Patterns of performance degradation and restoration during sleep restriction and subsequent recovery: a sleep dose-response study. Journal of Sleep Research 12, 1–12.
sleep_df = (get_rdataset('sleepstudy', 'lme4', cache=True)
.data
.rename(columns=str.lower)
.assign(reaction_std=lambda df: (df.reaction - df.reaction.mean()) / df.reaction.std()))
sleep_df.head()
| reaction | days | subject | reaction_std | |
|---|---|---|---|---|
| 0 | 249.5600 | 0 | 308 | -0.868968 |
| 1 | 258.7047 | 1 | 308 | -0.706623 |
| 2 | 250.8006 | 2 | 308 | -0.846944 |
| 3 | 321.4398 | 3 | 308 | 0.407108 |
| 4 | 356.8519 | 4 | 308 | 1.035777 |
In this study, each subject got their normal amount of sleep on the first day. They were reduced to three hours of sleep each subsequent day. The reaction column is their average response time on a number of tests. The reaction_std column is the result of standardizing reaction across all subjects and days.
fig, ax = plt.subplots(figsize=(8, 6))
(sleep_df.groupby('subject')
.plot('days', 'reaction_std',
ax=ax, legend=False));
ax.set_xlabel("Days of sleep deprivation");
ax.set_ylabel("Standardized reaction time");

fig
We translate the subject ids in sleep_df, which start at 308, to begin at zero and increase sequentially.
subject_ix, subject_map = sleep_df.subject.factorize()
n_subjects = subject_map.size
days = sleep_df.days.values
reaction_std = sleep_df.reaction_std.values
Each subject has a baseline reaction time, which should not be too far apart.
with pm.Model() as sleep_model:
μ_α = pm.Normal('μ_α', 0., 5.)
σ_α = pm.HalfCauchy('σ_α', 5.)
α = pm.Normal('α', μ_α, σ_α, shape=n_subjects)
Each subject's reaction time increases at a different rate after days of sleep deprivation.
with sleep_model:
μ_β = pm.Normal('μ_β', 0., 5.)
σ_β = pm.HalfCauchy('σ_β', 5.)
β = pm.Normal('β', μ_β, σ_β, shape=n_subjects)
The baseline reaction time and rate of increase lead to the observed reaction times.
with sleep_model:
μ = pm.Deterministic('μ', α[subject_ix] + β[subject_ix] * days)
σ = pm.HalfCauchy('σ', 5.)
obs = pm.Normal('obs', μ, σ, observed=reaction_std)
This type of model is known as a hierarchical (or mixed) linear model, because we allow the slope and intercept to vary by subject, but add a regularizing prior shared across subjects. To learn more about this type of model, consuly Gelman and Hill's Data Analysis Using Regression and Multilevel/Hierarchical Models.
N_JOBS = 3
JOB_SEEDS = [SEED + i for i in range(N_JOBS)]
with sleep_model:
sleep_trace = pm.sample(njobs=N_JOBS, random_seed=JOB_SEEDS)
Auto-assigning NUTS sampler... Initializing NUTS using jitter+adapt_diag... 100%|██████████| 1000/1000 [00:07<00:00, 134.79it/s]
Convergence Diagnostics¶
PyMC3 provides a number of statistcal convergence diagnostics to help ensure that the samples are a good approximation to the true posterior distribution.
Energy plots and the Bayesian fraction of missing information (BFMI) are two diagnostics relevant to Hamiltonian Monte Carlo sampling, which we have used in this example. If the two distributions in the energy plot differ significantly (espescially in the tails), the sampling was not very efficient. The Bayesian fraction of missing information quantifies this difference with a number between zero and one. A BFMI close to one is preferable, and a BFMI lower than 0.2 is indicative of efficiency issues.
For more information on energy plots and BFMI consult Michael Betancourt's A Conceptual Introduction to Hamiltonian Monte Carlo and Robust Statistical Workflow with PyStan.
ax = pm.energyplot(sleep_trace, legend=False)
ax.set_title("BFMI = {:.3f}".format(pm.bfmi(sleep_trace)));

In contract to energy plots and BFMI, which are specific to Hamiltonian Monte Carlo algorithms, Gelman-Rubin statistics are applicable to any MCMC algorithm, as long as multiple chains have been sampled. Gelman-Rubin statistics near one are preferable, and values less than 1.1 are generally taken to indicate convergence.
max(np.max(gr_values) for gr_values in pm.gelman_rubin(sleep_trace).values())
1.0019478091296214
Prediction¶
In the Bayesian framework, prediction is done by sampling from the posterior predictive distribution, which is the distribution of possible future observations, given the current observations.
with sleep_model:
pp_sleep_trace = pm.sample_ppc(sleep_trace)
100%|██████████| 500/500 [00:00<00:00, 1258.46it/s]
We convert the posterior predictive samples to a DataFrame.
PP_DATA= {'pp_{}'.format(i): pp_col for i, pp_col in enumerate(pp_sleep_trace['obs'])}
PP_COLS = list(PP_DATA.keys())
pp_df = sleep_df.assign(**PP_DATA)
pp_df.head()
| reaction | days | subject | reaction_std | pp_0 | pp_1 | pp_10 | pp_100 | pp_101 | pp_102 | ... | pp_90 | pp_91 | pp_92 | pp_93 | pp_94 | pp_95 | pp_96 | pp_97 | pp_98 | pp_99 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 249.5600 | 0 | 308 | -0.868968 | -0.221133 | -1.094005 | -1.479840 | -0.797150 | -0.251219 | -1.846100 | ... | -0.680005 | -0.036840 | -0.618054 | 0.158745 | -0.986407 | -0.788178 | -1.483328 | -0.423254 | -0.946230 | -0.838087 |
| 1 | 258.7047 | 1 | 308 | -0.706623 | 0.354375 | -1.192640 | -0.424441 | 0.064195 | -0.661047 | -1.181403 | ... | -0.472364 | -0.825356 | -0.374235 | -0.336909 | -0.940759 | -1.236048 | -0.749208 | -0.892589 | 0.243243 | -0.891522 |
| 2 | 250.8006 | 2 | 308 | -0.846944 | 0.487935 | -0.570185 | 0.304536 | 0.758313 | 0.566803 | 0.211791 | ... | -0.512914 | 0.156596 | -0.451047 | -0.219734 | -0.773714 | -0.237561 | -0.199602 | -0.071147 | 0.146439 | -0.193735 |
| 3 | 321.4398 | 3 | 308 | 0.407108 | 0.950116 | -0.554748 | 0.544648 | 1.037173 | -0.245327 | 0.450455 | ... | -0.183340 | 0.289252 | 0.358078 | 1.579609 | 0.652802 | -0.286667 | -0.327654 | 0.607906 | -0.087981 | -0.097427 |
| 4 | 356.8519 | 4 | 308 | 1.035777 | 0.485269 | 0.549079 | 0.564043 | 0.045464 | 0.643697 | 0.190714 | ... | 0.976137 | 0.306833 | 0.744076 | 0.493216 | 0.516644 | 1.090693 | 0.583320 | 1.079374 | 0.996899 | 0.671175 |
5 rows × 504 columns
def pp_subject_plot(pp_subject_df, ax):
low = pp_subject_df[PP_COLS].quantile(0.025, axis=1)
high = pp_subject_df[PP_COLS].quantile(0.975, axis=1)
ax.fill_between(pp_subject_df.days, low, high,
color='k', alpha=0.25)
ax.plot(pp_subject_df.days, pp_subject_df.reaction_std)
ax.plot(pp_subject_df.days, pp_subject_df[PP_COLS].mean(axis=1),
c='k');
def pp_subject_plot_helper(data=None, **_):
pp_subject_plot(data, plt.gca())
The following plot shows the predicted and observed reaction times for each subjects.
grid = sns.FacetGrid(pp_df, col='subject', col_wrap=n_subjects // 3)
grid.map_dataframe(pp_subject_plot_helper);
grid.set_axis_labels("Days of sleep deprivation", "Standardized reaction time");
grid.set_titles("Subject {col_name}");

grid.fig
Hamiltonian Monte Carlo in PyMC3¶
The following few cells can be ignored, they generate the plot for this slide.
x_ani = np.linspace(0, 1, 100)
y_ani = 1 - 2 * x_ani + np.random.normal(0., 0.25, size=100)
fig, ax = plt.subplots()
ax.scatter(x_ani, y_ani, c=blue);
ax.set_title('MCMC Data Set');

with pm.Model() as mcmc_model:
β0 = pm.Normal('β0', 0., 10.)
β = pm.Normal('β', 0., 10.)
σ = pm.HalfCauchy('σ', 5.)
y_obs = pm.Normal('y_obs', β0 + β * x_ani, σ, observed=y_ani)
mcmc_trace = pm.sample(random_seed=SEED)[:100]
Auto-assigning NUTS sampler... Initializing NUTS using jitter+adapt_diag... 100%|██████████| 1000/1000 [00:01<00:00, 689.19it/s]
mcmc_cov = np.cov(mcmc_trace['β0'], mcmc_trace['β'])
mcmc_sigma, mcmc_U = np.linalg.eig(mcmc_cov)
mcmc_angle = 180. / np.pi * np.arccos(np.abs(mcmc_U[0, 0]))
mcmc_fig, mcmc_ax = plt.subplots()
e = Ellipse((mcmc_trace['β0'].mean(), mcmc_trace['β'].mean()),
2 * np.sqrt(5.991 * mcmc_sigma[0]), 2 * np.sqrt(5.991 * mcmc_sigma[1]),
angle=mcmc_angle, zorder=5)
e.set_alpha(0.5)
e.set_facecolor(blue)
e.set_zorder(1)
mcmc_ax.plot(mcmc_trace['β0'], mcmc_trace['β'],
'-o', c='k', alpha=0.75);
mcmc_ax.add_artist(e);
mcmc_ax.set_xticklabels([]);
mcmc_ax.set_yticklabels([]);

mcmc_fig
The Curse of Dimensionality¶
The curse of dimensionality is a well-known concept in machine learning. It refers to the fact that as the number of dimensions in the sample space increases, samples become (on average) far apart quite quickly. It is related to the more complicated phenomenon of concentration of measure, which is the actual motivation for Hamiltonian Monte Carlo (HMC) algorithms.
The following plot illustrates one of the one aspect of the curse of dimensionality, that the volume of the unit ball tends to zero as the dimensionality of the space becomes large. That is, if
$$ \begin{align*} S_d & = \left\{\left.\vec{x} \in \mathbb{R}^d\ \right|\ x_1^2 + \cdots + x_d^2 \leq 1\right\}, \\ \operatorname{Vol}(S_d) & = \frac{2 \pi^{\frac{d}{2}}}{d\ \Gamma\left(\frac{d}{2}\right)}. \end{align*}$$And we get that $\operatorname{Vol}(S_d) \to 0$ as $d \to \infty$.
def sphere_volume(d):
return 2. * np.power(np.pi, d / 2.) / d / sp.special.gamma(d / 2)
fig, ax = plt.subplots()
d_plot = np.linspace(1, 100, 300)
ax.plot(d_plot, sphere_volume(d_plot));
ax.set_xscale('log');
ax.set_xlabel("Dimensions");
ax.set_ylabel("Volume of the unit sphere");

fig
Hamiltonian Monte Carlo¶

HMC algorithms mitigate the problems introduced the the curse of dimensionality/concentration of measure by taking into account the curvature of the posterior distribution. Its benefits are most apparent in models with many parameters, which correspond to high-dimesional posterior spaces. For an introduction to HMC algorithms, consult Michael Betancourt's A Conceptual Introduction to Hamiltonian Monte Carlo.
The mathematical quantification of curvature necessary for HMC algorithms involves differentiating various aspects of the model. PyMC3 uses Theano for automatic differentiation of tensor expressions to perform HMC sampling.
x = tt.dscalar('x')
x.tag.test_value = 0.
y = x**3
from theano import pprint
pprint(tt.grad(y, x))
'((fill((x ** TensorConstant{3}), TensorConstant{1.0}) * TensorConstant{3}) * (x ** (TensorConstant{3} - TensorConstant{1})))'
Case Study: 1984 Congressional Votes¶
To illustrate the benefits of the HMC algorithms that PyMC3 gives easy access to, we use a data set of key 1984 US congressional votes from the UCI Machine Learning Repository.
%%bash
export DATA_URI='https://archive.ics.uci.edu/ml/machine-learning-databases/voting-records/house-votes-84.data'
if [[ ! -e /tmp/house-votes-84.data ]]
then
wget -O /tmp/house-votes-84.data $DATA_URI
fi
N_BILL = 16
BILL_COLS = list(range(N_BILL))
vote_df = (pd.read_csv('/tmp/house-votes-84.data',
names=['party'] + BILL_COLS)
.rename_axis('rep_id', axis=0)
.reset_index())
vote_df.head()
| rep_id | party | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | republican | n | y | n | y | y | y | n | n | n | y | ? | y | y | y | n | y |
| 1 | 1 | republican | n | y | n | y | y | y | n | n | n | n | n | y | y | y | n | ? |
| 2 | 2 | democrat | ? | y | y | ? | y | y | n | n | n | n | y | n | y | y | n | n |
| 3 | 3 | democrat | n | y | y | n | ? | y | n | n | n | n | y | n | y | n | n | y |
| 4 | 4 | democrat | y | y | y | n | y | y | n | n | n | n | y | ? | y | y | y | y |
Question: can we separate Democrats and Republicans based on their voting records?
n_rep, _ = vote_df.shape
We melt the wide DataFrame to a tidy form, which is easier to use for exploration and modeling.
vote_df['party_id'], party_map = vote_df.party.factorize()
long_df = (pd.melt(vote_df, id_vars=['rep_id', 'party_id'], value_vars=BILL_COLS,
var_name='bill_id', value_name='vote_raw')
.assign(bill_id=lambda df: df.bill_id.astype(np.int64),
vote=lambda df: np.where(df.vote_raw == 'y', 1,
np.where(df.vote_raw == 'n', 0, np.nan)))
.dropna()
.drop('vote_raw', axis=1))
long_df.head()
| rep_id | party_id | bill_id | vote | |
|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0.0 |
| 1 | 1 | 0 | 0 | 0.0 |
| 3 | 3 | 1 | 0 | 0.0 |
| 4 | 4 | 1 | 0 | 1.0 |
| 5 | 5 | 1 | 0 | 0.0 |
The following plot shows the proportion of representatives that voted for each bill, broken down by party. The often large gaps between parties shows that it should be possible to separate Democrats and Republicans based only on their voting records.
grid = sns.factorplot('bill_id', 'vote', 'party_id', long_df,
kind='bar', ci=None, size=8, aspect=1.5, legend=False,
palette=[red, blue]);
ax = grid.axes[0, 0]
ax.set_yticks(np.linspace(0, 1, 5));
ax.yaxis.set_major_formatter(pct_formatter);
grid.set_axis_labels('Bill', 'Percent of party\'s\nrepresentatives voting for bill');
grid.add_legend(legend_data={party_map[int(key)].capitalize(): artist
for key, artist in grid._legend_data.items()});
grid.fig.suptitle('Key 1984 Congressional Votes');

grid.fig
We now build an ideal point model of representative's voting patterns. For more information on Bayesian ideal point models, consult Gelman and Bafumi's Practical Issues in Implementing and Understanding Bayesian Ideal Point Estimation.
Latent State Model
- Representatives ($\color{blue}{\theta_i}$) and bills ($\color{green}{b_j})$ have ideal points on a liberal-conservative spectrum.
- If the ideal points are equal, there is a 50% chance the representative will vote for the bill.
Optional
The following hierarchical_normal function implements a hierarchical normal prior distribution equivalent to those we used for the varying slopes and intercepts for the sleep deprivation case study. However, for our high-dimensional ideal point model, a noncentered parametrization of this prior will lead to more efficient sampling than the naive parametrization we used previously.
def hierarchical_normal(name, shape):
μ = pm.Normal('μ_{}'.format(name), 0., 1.)
Δ = pm.Normal('Δ_{}'.format(name), 0., 1., shape=shape)
σ = pm.Normal('σ_{}'.format(name), 5.)
return pm.Deterministic(name, μ + Δ * σ)
rep_id = long_df.rep_id.values
bill_id = long_df.bill_id.values
vote = long_df.vote.values
with pm.Model() as vote_model:
# representative ideal points
θ = pm.Normal('θ', 0., 1., shape=n_rep)
# bill ideal points
a = hierarchical_normal('a', N_BILL)
The following potential is necessary to identify the model. It restricts the second representative, a Republican, to have a positive ideal point. Conventionally in political science, conservativity corresponds to positive ideal points. See the Gelman and Bafumi paper referenced above for a discussion of why this restriction is necessary.
with vote_model:
θ_pot = pm.Potential('θ_pot', tt.switch(θ[1] < 0., -np.inf, 0.))
- Bills also have an ability to discriminate ($\color{red}{a_j}$) between conservative and liberal representatives.
- Some bills have broad bipartisan support, while some provoke votes along party lines.
with vote_model:
# bill discrimination parameters
b = hierarchical_normal('b', N_BILL)
This model has
n_rep + 2 * (N_BILL + 1)
469
parameters
This model is a logistic regression with latent parameters.
Observation Model
$$ \begin{align*} P(\textrm{Representative }i \textrm{ votes for bill }j\ |\ \color{blue}{\theta_i}, \color{green}{b_j}, \color{red}{a_j}) & = \frac{1}{1 + \exp\left(-\left(\color{red}{a_j} \cdot \color{blue}{\theta_i} - \color{green}{b_j}\right)\right)} \end{align*} $$fig, ax = plt.subplots()
t_plot = np.linspace(-10, 10, 100)
ax.plot(t_plot, sp.special.expit(t_plot));
ax.set_xlabel("$t$");
ax.set_yticks(np.linspace(0, 1, 5));
ax.set_ylabel(r"$\frac{1}{1 + \exp(-t)}$");

fig
with vote_model:
η = a[bill_id] * θ[rep_id] - b[bill_id]
p = pm.math.sigmoid(η)
obs = pm.Bernoulli('obs', p, observed=vote)
Hamiltonian Monte Carlo Inference
with vote_model:
nuts_trace = pm.sample(init='adapt_diag', njobs=N_JOBS,
random_seed=JOB_SEEDS)
Auto-assigning NUTS sampler... Initializing NUTS using adapt_diag... 100%|██████████| 1000/1000 [02:11<00:00, 12.76it/s]
Convergence Diagnostics¶
We see that the chains appear to have converged well.
ax = pm.energyplot(nuts_trace, legend=False)
ax.set_title("BFMI = {:.3f}".format(pm.bfmi(nuts_trace)));

max(np.max(gr_values) for gr_values in pm.gelman_rubin(nuts_trace).values())
1.0135857288309107
Ideal Points¶
The model has effectively separated Democrats from Republicans, soley based on their voting records.
fig, ax = plt.subplots()
dem_ids = vote_df[vote_df.party == 'democrat'].rep_id.values
rep_ids = vote_df[vote_df.party == 'republican'].rep_id.values
ax.hist(nuts_trace['θ'][:, dem_ids].ravel(),
bins=30, normed=True, alpha=0.5,
color=blue, label='Democrats');
ax.hist(nuts_trace['θ'][:, rep_ids].ravel(),
bins=30, normed=True, alpha=0.5,
color=red, label='Republicans');
ax.set_xlabel("Conservativity");
ax.set_yticks([]);
ax.legend();

fig
Discriminative Ability of Bills¶
The following plot shows that it was important to include the discrimination parameters a, as some bills are quantifiably more useful for separating Democrats from Republicans.
pm.forestplot(nuts_trace, varnames=['a'], rhat=False, xtitle="$a$",
ylabels=["Bill {}".format(i + 1) for i in range(N_BILL)]);

Comparison to Non-Hamiltonian MCMC¶
We now use standard MCMC methods (in this case, the Metropolis-Hastings algorithm) on this model to illustrate the power of HMC algorithms.
with vote_model:
step = pm.Metropolis()
met_trace_ = pm.sample(10000, step, njobs=N_JOBS, random_seed=JOB_SEEDS)
met_trace = met_trace_[5000::5]
100%|██████████| 10500/10500 [03:40<00:00, 47.65it/s]
We see that the standard MCMC samples are quite far from converging, as their Gelman-Rubin statistics vastly exceed one.
max(np.max(gr_values) for gr_values in pm.gelman_rubin(met_trace).values())
39.87901257961822
The following plot shows the vast difference between the standard MCMC and HMC samples, and the low quality of the standard MCMC samples.
fig, (met_ax, nuts_ax) = plt.subplots(ncols=2, sharex=True, sharey=True, figsize=(16, 6))
met_ax.scatter(met_trace['θ'][:, 0], met_trace['a'][:, 0],
alpha=0.25);
met_ax.set_xticklabels([]);
met_ax.set_xlabel(r"$θ_0$");
met_ax.set_yticklabels([]);
met_ax.set_ylabel("$a_0$");
met_ax.set_title("Metropolis");
nuts_ax.scatter(nuts_trace['θ'][:, 0], nuts_trace['a'][:, 0],
alpha=0.25);
nuts_ax.set_xlabel(r"$θ_0$");
nuts_ax.set_ylabel("$a_0$");
nuts_ax.set_title("Hamiltonian Monte Carlo");

fig
Next Steps¶
The following books/GitHub repositories provide good introductions to PyMC3 and Bayesian statistics.
PyMC3¶
|
|

|

|
The following chart gives an overview of the larger probabilistic programming ecosystem.
Probabilistic Programming Ecosystem¶
| Probabilistic Programming System | Language | License | Discrete Variable Support | Automatic Differentiation/Hamiltonian Monte Carlo | Variational Inference |
|---|---|---|---|---|---|
| PyMC3 | Python | Apache V2 | Yes | Yes | Yes |
| Stan | C++, R, Python, ... | BSD 3-clause | No | Yes | Yes |
| Edward | Python, ... | Apache V2 | Yes | Yes | Yes |
| BUGS | Standalone program, R | GPL V2 | Yes | No | No |
| JAGS | Standalone program, R | GPL V2 | Yes | No | No |
Thank you!¶

@AustinRochford • austin.rochford@gmail.com • arochford@monetate.com¶
The Jupyter notebook used to generate these slides is available here.
%%bash
jupyter nbconvert \
--to=slides \
--reveal-prefix=https://cdnjs.cloudflare.com/ajax/libs/reveal.js/3.2.0/ \
--output=os-bayes-pymc3-fosscon-2017 \
./Open\ Source\ Bayesian\ Inference\ in\ Python\ with\ PyMC3.ipynb
[NbConvertApp] Converting notebook ./Open Source Bayesian Inference in Python with PyMC3.ipynb to slides [NbConvertApp] Writing 1553020 bytes to ./os-bayes-pymc3-fosscon-2017.slides.html