![]()
Unsupervised classifiers¶
$$ \newcommand{\eg}{{\it e.g.}} \newcommand{\ie}{{\it i.e.}} \newcommand{\argmin}{\operatornamewithlimits{argmin}} \newcommand{\mc}{\mathcal} \newcommand{\mb}{\mathbb} \newcommand{\mf}{\mathbf} \newcommand{\minimize}{{\text{minimize}}} \newcommand{\diag}{{\text{diag}}} \newcommand{\cond}{{\text{cond}}} \newcommand{\rank}{{\text{rank }}} \newcommand{\range}{{\mathcal{R}}} \newcommand{\null}{{\mathcal{N}}} \newcommand{\tr}{{\text{trace}}} \newcommand{\dom}{{\text{dom}}} \newcommand{\dist}{{\text{dist}}} \newcommand{\R}{\mathbf{R}} \newcommand{\SM}{\mathbf{S}} \newcommand{\ball}{\mathcal{B}} \newcommand{\bmat}[1]{\begin{bmatrix}#1\end{bmatrix}} \newcommand{\loss}{\ell} \newcommand{\eloss}{\mc{L}} \newcommand{\abs}[1]{| #1 |} \newcommand{\norm}[1]{\| #1 \|} \newcommand{\tp}{T} $$Unsupervised Learning¶
In the previous class, we discussed supervised learning. For this assignment, we will focus on unsupervised learning.
Unsupervised Learning refers to a type of machine learning where the model learns patterns and structures in data without labeled outputs. This approach is often used for problems where assigning labels is challenging or infeasible.
Key Characteristics of Unsupervised Learning:¶
- No labeled Data:
- Unlike supervised learning, the dataset consists of input features only, with no corresponding output labels.
- Large datasets of X-ray, MRI, or CT images may exist, but labeling (e.g., identifying tumors) requires significant expertise and time, making it expensive to create labeled data.
- Transforming real-world photos into sketches is challenging because it is impractical to manually pair every photo with its sketch counterpart.
- Goal
- The model explores the data to find hidden patterns or structures without predefined guidance.
- Applications:
- Clustering: Grouping similar data points (e.g., K-Means, DBSCAN).
- Dimensionality Reduction: Reducing the number of features while retaining meaningful information (e.g., PCA, t-SNE).
- Anomaly Detection: Identifying outliers or unusual data points.
- Generative Models: Learning the underlying distribution of data to generate new samples (e.g., GANs, VAEs).
In this assignment, we design an autoencoder, which is a component of unsupervised learning, to support classification tasks.
Autoencoder¶
An autoencoder is a neural network model that encodes input data into a lower-dimensional or higher-dimensional latent space and then decodes it back to reconstruct the original input. The goal of the autoencoder is to make its output as close as possible to the input while learning an efficient latent representation of the data.
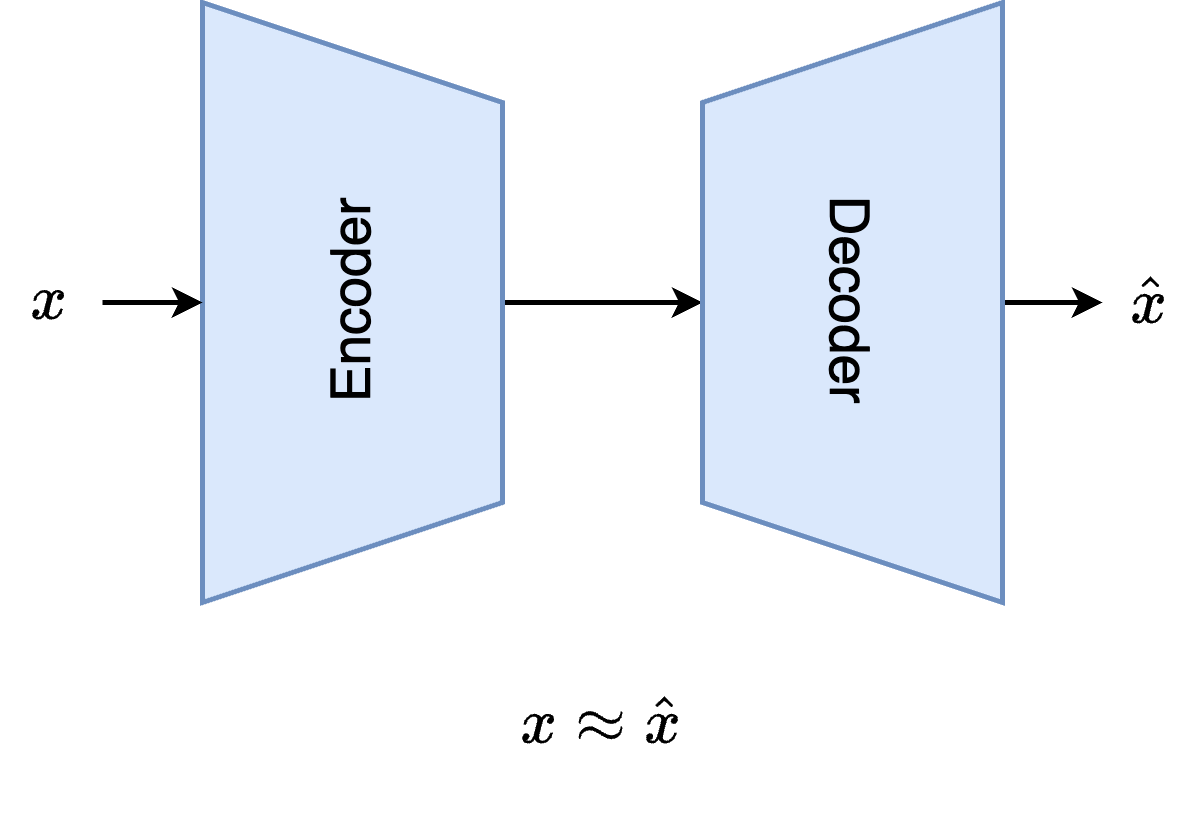
1. Encoder¶
- Maps the input data $x$ into a compressed latent space representation $z$
2. Latent space¶
- The latent space dimension is typically smaller than the input dimension, though in some cases (e.g., feature expansion), it can be higher.
- If the data can be reconstructed accurately from a low-dimensional latent space, it indicates that the latent representation contains sufficient information to describe the data and captures its most distinguishing characteristics.
3. Decoder¶
- Reconstructs the original input $x$ from the latent representation $z$.
4. Objective¶
- Minimize the reconstruction loss between the input $x\in \mathbb{R}^{n_\text{feat}}$ and the reconstructed output $\hat{x}$
where, $$\begin{aligned}X &= \begin{bmatrix} x_1 & x_2& \cdots& x_N \end{bmatrix}^T\\ \hat{X} &= \begin{bmatrix} \hat{x}_1 & \hat{x}_2& \cdots& \hat{x}_N \end{bmatrix}^T \end{aligned} $$
Autoencoder for Classification¶
The latent space of an autoencoder captures meaningful representations of input data. We can leverage this property to design a classifier by mapping the input data into the latent space and identifying the closest cluster based on the mean latent values of the training data for each class.
In this example, we use the MNIST dataset for classification. The MNIST dataset consists of grayscale images of handwritten digits (0-9), where each image is 28x28 pixels.
import numpy as np
import numpy.linalg as lg
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import Dataset, DataLoader, Subset
from tqdm import tqdm
from sklearn.manifold import TSNE
from PIL import Image
device = torch.device('cuda:0')
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = torchvision.datasets.MNIST(
root='./data',
train=True,
transform=transform,
download=True
)
test_dataset = torchvision.datasets.MNIST(
root='./data',
train=False,
transform=transform,
download=True
)
train_dataloader = DataLoader(train_dataset, batch_size=1024, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=1024, shuffle=True)
tmp = iter(train_dataset)
imgs, labels = next(tmp)
plt.imshow(imgs[0])
<matplotlib.image.AxesImage at 0x7f0a02e4ac80>

(Problem 1) Define model, loss function and optimizer.
Design an autoencoder model using MLP and nn.ReLU as the activation function. The details of architecture are specified in the comments. Refer to the last class material and use nn.Sequential where possible. This makes the code more concise.
The loss function is the nn.MSELoss to account for reconstruction errors and optimizer is optim.Adam as before.
class AutoEncoder(nn.Module):
def __init__(self, dim_in, act_func=nn.ReLU):
super().__init__()
## Encoder ##
# layer1: 28*28 x 1000
# relu
# layer2: 1000 x 25
# relu
# layer3: 25 x 50
## Decoder ##
# relu
# layer1: 50 x 1000
# relu
# layer2: 1000 x 28*28
## your code here---------------------------##
##------------------------------------------##
n_feat = 28*28
lr = 1e-3
model = AutoEncoder(n_feat).to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=1e-8)
losses = []
(Problem 2) write your code to train model. It is very similar to the structure shown in the class materials. The goal is to optimize the model by minimizing the reconstruction loss nn.MSELoss using the torch.optim.Adam.
epoch = 500
model.train()
progress = tqdm(range(epoch))
for i in progress:
## your code here---------------------------##
##------------------------------------------##
progress.set_description(f"{losses[-1]:e}")
1.244849e-02: 100%|██████████| 500/500 [17:37<00:00, 2.11s/it]
plt.figure(figsize=(1.6*3,1*3), dpi=200)
plt.semilogy(losses)
plt.grid()
plt.xlabel('Iterations')
plt.title('Training Loss')
Text(0.5, 1.0, 'Training Loss')

To visualize the latent space representation learned by the autoencoder, we use t-SNE (t-Distributed Stochastic Neighbor Embedding). t-SNE is a popular technique for mapping high-dimensional data points to a lower-dimensional space, typically 2D or 3D, while preserving the structure of the data as much as possible.
To evaluate the quality of the learned latent space, we compare the 2D projections obtained by applying t-SNE on:
- Latent Space: Representations generated by the encoder.
- Original Space: The original input data (flattened MNIST images).
Since applying t-SNE to the entire test dataset is computationally expensive, we sample 1/3 of the data for visualization.
orgs = []; outs = []; labels = []
with torch.no_grad():
for (_in, label) in train_dataloader:
n_batch = len(_in)
_in = _in.reshape(n_batch,-1).to(device)
out = model.encoder(_in)
outs.append(out)
orgs.append(_in)
labels.append(label)
outs = torch.cat(outs).cpu().detach().numpy()
orgs = torch.cat(orgs).cpu().detach().numpy()
labels = torch.cat(labels).cpu().detach().numpy()
tsne = TSNE(n_components=2, random_state=3)
itv = 3
outs_tsne = tsne.fit_transform(outs[::itv])
orgs_tsne = tsne.fit_transform(orgs[::itv])
colors = [f'C{i}' for i in range(10)]
fig, axes = plt.subplots(1,2, figsize=(1.6*3*2,1*3), dpi=200)
ax = axes[0]
ax.scatter(*orgs_tsne.T, alpha=0.1, c=[colors[int(i)] for i in labels[::itv]])
ax = axes[1]
ax.scatter(*outs_tsne.T, alpha=0.1, c=[colors[int(i)] for i in labels[::itv]])
legend_handles = [
plt.Line2D([0], [0], color=colors[i], marker='o', linestyle='None', markersize=8, label=f"{i}")
for i in np.arange(10)]
fig.legend(handles=legend_handles, loc="upper center", ncol=10)
for ax in axes.flatten():
ax.grid()

(Problem 3) To classify a given input $x$, we use the cluster centers computed from the train dataset in both latent space and original space. The process involves the following steps:
Compute the mean vector (cluster center) for each class $c$ in latent space($\mu^\text{lat}$) and original space($\mu^\text{org}$) respectively.
Calculate 2-norm distances
- Class Prediction by identifying the class $c^*$ which minimizes the distance in either space:
- In original space:
- In latent space:
## your code here ##
## your code here ##
Accuracy in original space(%) 82.03 Accuracy in latent space(%) 87.89
Extension - Constrast Learning¶
In this project, we designed a classifier using an autoencoder. This approach is based on the intuition that the autoencoder's latent space can compress data meaningfully, forming distinct regions for each class. In addition to this, we aim to improve the structure of the latent space by incorporating Contrastive Learning.
Contrastive Learning is a technique within Self-Supervised Learning that compares data pairs (positive and negative pairs) to learn efficient representations. It encourages similar data (positive pairs) to be closer in the latent space, while dissimilar data (negative pairs) are pushed farther apart. It is widely used for learning effective representations from unlabeled data.
A representative example of Contrastive Loss is the NT-Xent Loss (Normalized Temperature-scaled Cross Entropy Loss), which is defined as follows:
$$\mathbf{L}_\text{contrastive} = -\log \frac{\exp(\text{sim}(z, z^+) / \tau)}{\exp(\text{sim}(z, z^+) / \tau) + \sum_{z^-} \exp(\text{sim}(z, z^-) / \tau)}$$where,
- $\text{sim}$: The similarity metric between two vectors, typically cosine similarity.
- $\tau$: The temperature scaling parameter that controls the sharpness of the probability distribution.
For simplicity in this assignment, we focus on ensuring that dissimilar data are pushed farther apart in the latent space. This is achieved using the negative-only loss, defined as:
$$ \mathbf{L}_\text{contrastive} \approx \log \left( 1 + \sum_{z^-} \exp(\text{sim}(z, z^-) / \tau) \right) $$n_feat = 28*28
lr = 1e-3
model = AutoEncoder(n_feat).to(device)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=lr, weight_decay=1e-8)
losses = []
def constrastive_loss(z, z_neg, tau=0.5):
"""
z: latent vector for selected class (batch, latent_dim)
z_neg: negative latent vector for diffdrent class (batch, latent_dim)
"""
z = F.normalize(z, dim=1)
z_neg = F.normalize(z_neg, dim=1)
sim = torch.sum(z * z_neg, dim=1)
tmp = sim / tau
loss = torch.log(1 + torch.exp(tmp))
return loss.mean()
(Problem 4) Write your code referring to the following pseudo-code. Add a loss function considering contrastive learning to the existing training code you wrote earlier. Use contrastive_loss to incorporate this functionality.
Pseudo code: $$ \begin{array}{l} \textbf{for } i\ \textbf{to } \text{max_iter } \textbf{do }\\ \quad \vdots \quad \text{Original training process}\\ \quad\textbf{select } a_1, a_2 \in [0,9]\\ \quad\textbf{if } \text{count_length}(a_1) \neq 0 \textbf{ and } \text{count_length}(a_2) \neq 0 \textbf{ then } \\ \qquad z \leftarrow \text{latent vectors corresponding to } a_1 ;\\ \qquad z_\text{neg} \leftarrow \text{latent vectors corresponding to } a_2 ;\\ \qquad \text{loss_ ctr}\leftarrow \text{constrastive_loss}(z, z_\text{neg}); \\ \qquad \text{_len} \leftarrow \min(\text{count_length}(a_1), \text{count_length}(a_2)); \\ \qquad z \leftarrow z[:\text{_len}]; \\ \qquad z_\text{neg} \leftarrow z_\text{neg}[:\text{_len}]; \\ \quad\textbf{end}\\ \quad\textbf{else }\\ \qquad \text{loss_ ctr}\leftarrow 0;\\ \quad\textbf{end if}\\ \quad \text{loss} \leftarrow \text{loss} + \text{loss_ctr};\\ \quad \vdots \quad \text{(Continue with backpropagation and optimization)} \\ \textbf{end for} \end{array} $$
epoch = 500
model.train()
progress = tqdm(range(epoch))
for i in progress:
## your code here---------------------------##
##------------------------------------------##
progress.set_description(f"{losses[-1]:e}")
## your code here ##
Accuracy in latent space with contrast learning(%) 91.82000000000001
model.eval()
outs = []; labels = []
with torch.no_grad():
for (_in, label) in train_dataloader:
n_batch = len(_in)
_in = _in.reshape(n_batch,-1).to(device)
out = model.encoder(_in)
outs.append(out)
labels.append(label)
outs = torch.cat(outs).cpu().detach().numpy()
labels = torch.cat(labels).cpu().detach().numpy()
tsne = TSNE(n_components=2, random_state=3)
itv = 3
outs_tsne = tsne.fit_transform(outs[::itv])
colors = [f'C{i}' for i in range(10)]
plt.figure(figsize=(1.6*3,1*3), dpi=200)
plt.scatter(*outs_tsne.T, alpha=0.1, c=[colors[int(i)] for i in labels[::itv]])
legend_handles = [
plt.Line2D([0], [0], color=colors[i], marker='o', linestyle='None', markersize=8, label=f"{i}")
for i in np.arange(10)]
plt.legend(handles=legend_handles, loc="upper center", ncol=5)
plt.grid()
plt.title('Autoencoder with Constrast Learning')
Text(0.5, 1.0, 'Autoencoder with Constrast Learning')
