Aprendizaje Profundo ¶
Diplomado en Inteligencia Artificial y Aprendizaje Profundo ¶
Métricas en el aprendizaje de máquinas ¶

{kind=link}
Profesores¶
- Alvaro Montenegro, PhD, ammontenegrod@unal.edu.co
- Camilo José Torres Jiménez, Msc, cjtorresj@unal.edu.co
- Daniel Montenegro, Msc, dextronomo@gmail.com
Asesora Medios y Marketing digital¶
- Maria del Pilar Montenegro, pmontenegro88@gmail.com
- Jessica López Mejía, jelopezme@unal.edu.co
- Venus Puertas, vpuertasg@unal.edu.co
Jefe Jurídica¶
- Paula Andrea Guzmán, guzmancruz.paula@gmail.com
Coordinador Jurídico¶
- David Fuentes, fuentesd065@gmail.com
Desarrolladores Principales¶
- Dairo Moreno, damoralesj@unal.edu.co
- Joan Castro, jocastroc@unal.edu.co
- Bryan Riveros, briveros@unal.edu.co
- Rosmer Vargas, rovargasc@unal.edu.co
Expertos en Bases de Datos¶
- Giovvani Barrera, udgiovanni@gmail.com
- Camilo Chitivo, cchitivo@unal.edu.co
Introducción¶
Evaluar nuestro algoritmo de aprendizaje automático es una parte esencial de cualquier proyecto. Las métricas permite evaluar el desempeño de un modelo de acuerdo a criterios que el diseñador del modelo desea observar.
Por ejemplo, el puntaje de precisión precision_score, puede arrojar resultados deficientes cuando se evalúa con otras métricas, como cross_entropy o cualquier otra métrica similar.
La mayoría de las veces usamos la exactitud de la clasificación para medir el rendimiento de nuestro modelo, sin embargo, no es suficiente para juzgar verdaderamente nuestro modelo. En esta lección, cubriremos los diferentes tipos de métricas de evaluación disponibles.
Las funciones de pérdida pueden ser usada como métricas ne algunos casos. Por ejemplo, es bastante común tener como función de pérdida en un problema el error cuadrático medio (ECM) y como métrica el el error absoluto medio (EAM). En esta lección no revisaremos las funciones de pérdida, pero podemos tener en cuenta de varias de ellas se puede usar como métricas.
Matriz de confusión ¶
La matriz de confusión, como sugiere el nombre, nos da una matriz como resultado y describe el rendimiento completo del modelo.
Supongamos que tenemos un problema de clasificación binaria. Tenemos algunas muestras pertenecientes a dos clases: SÍ o NO. Además, tenemos nuestro propio clasificador que predice una clase para una muestra de entrada dada. Al probar nuestro modelo en N muestras, obtenemos el siguiente resultado.
| Clasificados como Positivos | Clasificados como Negativos | |
|---|---|---|
| Etiquetados como Positivos | Verdaderos Positivos | Falsos Negativos |
| Etiquetados como Negativos | Falsos Positivos | Verdaderos Negativos |
Fuente Wiki-commons
En problemas con varias clases, la matriz de confusión permite tener una idea de primera mano de como está funcionando el modelo. Revise el siguiente ejemplo. La matriz de confusión, como sugiere el nombre, nos da una matriz como resultado y describe el rendimiento completo del modelo.
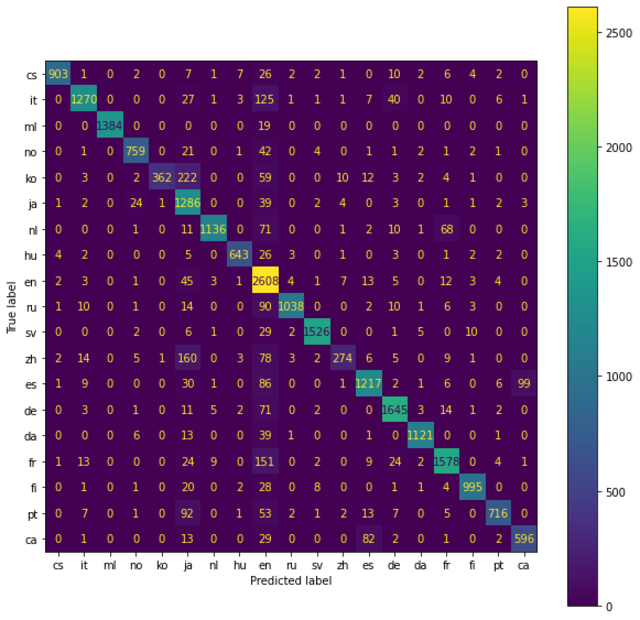
Fuente Wiki-commons
Aparentemente el modelo esta confundiendo muchos ejemplo en la clase en.
Métricas en clasificación¶
La mayor parte de las métricas son explicados para el caso binario, pero en general pueden ser aplicadas al caso de $J$ clases.
| Clasificados como Positivos | Clasificados como Negativos | |
|---|---|---|
| Etiquetados como Positivos | Verdaderos Positivos | Falsos Negativos |
| Etiquetados como Negativos | Falsos Positivos | Verdaderos Negativos |
Exactitud: Accuracy¶
La exactitud de la clasificación es lo que generalmente queremos decir cuando usamos el término exactitud. Es la relación entre el número de predicciones correctas y el número total de muestras de entrada. En el caso binario es usual la siguiente nomenclatura.
$$ Accuracy = \frac{\text{verdaderos positivos} + \text{verdaderos negativos} }{\text{total de la muestra}} $$El mejor valor es 1 y el peor valor es 0.
Precisión: precision_score¶
Esta métrica indica que tan preciso es el número de positivos detectados por el modelo. Se puede pensar como enfocada en minimizar los falsos positivos.
El mejor valor es 1 y el peor valor es 0.
Recuperación: recall_score¶
La sensibilidad o recuperación (recall) es intuitivamente la capacidad del clasificador para encontrar todas las muestras positivas. El mejor valor es 1 y el peor valor es 0.
$$ Recall = \frac{\text{verdaderos positivos} }{\text{verdaderos positivos}+ \text{falsos negativos}} $$En algunos problemas con datos altamente desbalanceados como en el problema de detección de fraude en tarjetas de crédito o la detección temprana de cáncer de seno, un valor alto de exactitud, no es realmente lo mejor. En estos problemas, la recuperación, que es la métrica que mide la capacidad del modelo para detectar muestras positivas es la métrica que se privilegia por encima de las demás. En estos casos es usual el uso de pesos diferenciados de las observaciones. Se puede pensar como enfocada en minimizar los falsos negativos.
Puntaje F1: F1 score¶
La puntuación F1 es la media armónica entre la precisión y la recuperación. El rango para F1 Score es $[0, 1]$. F1 nos dice qué tan preciso es el clasificador (cuántas instancias clasifica correctamente), así como qué tan robusto es (no pierde una cantidad significativa de instancias).
Alta precisión pero menor recuperación, le brinda una precisión extrema, pero luego pierde una gran cantidad de instancias que son difíciles de clasificar. Cuanto mayor sea el F1 Score, mejor será el rendimiento de nuestro modelo. Matemáticamente, se puede expresar como: $$ F1 = 2 \times \frac{1}{\frac{1}{precision} + \frac{1}{recall}} $$
El puntaje F1 intenta encontrar el equilibrio entre precision y recall.
Métricas disponibles en Keras¶
Las siguientes son las métricas disponibles de Keras en el año 2022.
Métricas de exactitud¶
- Accuracy
- BinaryAccuracy
- CategoricalAccuracy
- SparseCategoricalAccuracy
- TopKCategoricalAccuracy
- SparseTopKCategoricalAccuracy
Métricas de clasificación basadas en positivos y negativos¶
- AUC
- Precision
- Recall
- TruePositives
- TrueNegatives
- FalsePositives
- FalseNegatives
- PrecisionAtRecall
- SensitivityAtSpecificity
- SpecificityAtSensitivity
Métricas probabilisticas¶
- BinaryCrossentropy
- CategoricalCrossentropy
- SparseCategoricalCrossentropy
- KLDivergence
- Poisson
Métricas de regresión¶
- MeanSquaredError
- RootMeanSquaredError
- MeanAbsoluteError
- MeanAbsolutePercentageError
- MeanSquaredLogarithmicError
- CosineSimilarity
- LogCoshError
Métricas para segmentación de imágenes¶
- MeanIoU
Métricas para clasificación para máximo margen (hinge)¶
- Hinge metrics for "maximum-margin" ification
- Hinge
- SquaredHinge
- CategoricalHinge
Forma de uso en Keras¶
En el momento de compilar el modelo las métricas para el modelo se definen en una lista, como se observa en el siguiente fragmento de código.
model.compile(
optimizer='adam',
loss='mean_squared_error',
metrics=[
metrics.MeanSquaredError(),
metrics.AUC(),
]
)
En general las métricas van acumulado resultados a lo largo de cada época. En necesario reiniciarlas al comienza de la época y totalizarlas al final. Sin embargo todo lo hace Keras debajo del capó.
Métricas disponibles en Pytorch¶
En Pytorch es necesario instalar el módulo TorchMetrics como sigue
# conda install -c conda-forge torchmetrics
Este módulo ha sido desarrollado principalmente por Pytorch-Lightning. El módulo incluye más de 80 métricas para cada uno se las siguientes áreas:
- Audio
- Clasificación general
- Clasificación de imágenes.
- Detección de objetos
- Emparejamiento (pairwise)
- Regresión
- Recuperación
- Textual
- Agregación
Para los detalles visite torchmetrics.
Forma de uso en Pytorch¶
TorchMetrics puede usarse directamente en Python como se ilustra en el siguiente fragmento de código. Vaya la lección de Pytorch-lightning, para verficar como usarlas alli.
from torchmetrics.classification import Accuracy
train_accuracy = Accuracy()
valid_accuracy = Accuracy()
for epoch in range(epochs):
for x, y in train_data:
y_hat = model(x)
# training step accuracy
batch_acc = train_accuracy(y_hat, y)
print(f"Accuracy of batch{i} is {batch_acc}")
for x, y in valid_data:
y_hat = model(x)
valid_accuracy.update(y_hat, y)
# total accuracy over all training batches
total_train_accuracy = train_accuracy.compute()
# total accuracy over all validation batches
total_valid_accuracy = valid_accuracy.compute()
print(f"Training acc for epoch {epoch}: {total_train_accuracy}")
print(f"Validation acc for epoch {epoch}: {total_valid_accuracy}")
# Reset metric states after each epoch
train_accuracy.reset()
valid_accuracy.reset()