Aprendizaje Profundo ¶
Diplomado en Inteligencia Artificial y Aprendizaje Profundo ¶
Técnicas modernas de clasificación de documentos ¶
{kind=link}
Profesores¶
- Alvaro Montenegro, PhD, ammontenegrod@unal.edu.co
- Camilo José Torres Jiménez, Msc, cjtorresj@unal.edu.co
- Daniel Montenegro, Msc, dextronomo@gmail.com
Asesora Medios y Marketing digital¶
- Maria del Pilar Montenegro, pmontenegro88@gmail.com
- Jessica López Mejía, jelopezme@unal.edu.co
- Venus Puertas, vpuertasg@unal.edu.co
Jefe Jurídica¶
- Paula Andrea Guzmán, guzmancruz.paula@gmail.com
Coordinador Jurídico¶
- David Fuentes, fuentesd065@gmail.com
Desarrolladores Principales¶
- Dairo Moreno, damoralesj@unal.edu.co
- Joan Castro, jocastroc@unal.edu.co
- Bryan Riveros, briveros@unal.edu.co
- Rosmer Vargas, rovargasc@unal.edu.co
Expertos en Bases de Datos¶
- Giovvani Barrera, udgiovanni@gmail.com
- Camilo Chitivo, cchitivo@unal.edu.co
Referencias¶
- Adaptado de deep-learning-methods-for-text-data
- Mikolov et al. 2013a, Google, [Distributed Representations of Words and Phrases
and their Compositionality](https://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality.pdf), 3. Xin Rong, 2016, word2vec Parameter Learning Explained, 4. Mikolov et al. 2013b, Google, Efficient Estimation of Word Representations in Vector Space. 5. Baroni et al., 2014,Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors.
Contenido¶
- Introducción
- No cuente, prediga
- Sumergimiento o incrustamiento de palabras-word embeddings
- Modelos Word2Vec
- Modelo CBOW
- Modelo Skip-gram
- Sobre que podemos esperar
- Las tareas linguísticas
- Recursos linguísticos
- Corpus de juguete
- Ejemplo The King James version of the Bible
- Pre-procesamiento del texto
- Modelos con Gensim
- Visualización de incrustaciones con TSNE
- Incrustación de documentos
- Modelos pre-entrenados. El modelo Glove
- Introducción a spaCy
- Modelos en Español
- El modelo FastText
- Modelos-de-incrustaciones-del -Español-Preentrenados
- Conclusión
Introducción¶
Trabajar con datos de texto no estructurados es difícil, especialmente cuando se intenta construir un sistema inteligente que interprete y comprenda el lenguaje natural que fluye libremente al igual que los humanos.
Debe poder procesar y transformar datos textuales no estructurados y ruidosos en algunos formatos estructurados y vectorizados que puedan ser entendidos por cualquier algoritmo de aprendizaje automático.
Los principios del procesamiento del lenguaje natural, el aprendizaje automático o el aprendizaje profundo, todos los cuales caen bajo el amplio paraguas de la inteligencia artificial, son herramientas eficaces del oficio.
Un punto importante para recordar aquí es que cualquier algoritmo de aprendizaje automático se basa en principios de estadística, matemáticas y optimización.
Por lo tanto, no son lo suficientemente inteligentes como para comenzar a procesar texto en su forma original y sin pre-procesar.
En esta lección revisamos los métodos más modernos para el descubrimiento de tópicos y clasificación de documentos. Usaremos algunos modelos globales pre-entrenados que se encuentran disponibles libremente.
Más específicamente, cubriremos el modelos Word2Vec, Glove y FasText y usaremos las herramientas nltk, gensim y spacy.
En esta lección no usaremos tensorflow.
No cuente, prediga¶
Para superar las deficiencias de perder la semántica y la escasez de características basadas en el modelo de bolsa de palabras, necesitamos hacer uso de los modelos de espacio vectorial - Vector Space Models(VSM) de tal manera que podamos incrustar vectores de palabras en este espacio vectorial continuo basado en semánticas y similitud contextual.
De hecho, la hipótesis distributiva en el campo de la semántica distributiva nos dice que las palabras que ocurren y se usan en el mismo contexto, son semánticamente similares entre sí y tienen significados similares.
En términos simples, una palabra se caracteriza por la compañía que mantiene. ¡Uno de los artículos famosos que habla en detalle sobre estos vectores de palabras semánticas y varios tipos es Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors’ by Baroni et al, de by Baroni et al.
No profundizaremos mucho, pero, en resumen, hay dos tipos principales de métodos para los vectores de palabras contextuales.
- Métodos basados en conteo como el Análisis semántico latente (LSA) que se pueden usar para calcular algunas medidas estadísticas de la frecuencia con la que las palabras ocurren con sus palabras vecinas en un corpus y luego construir vectores de palabras densas para cada palabra a partir de estas medidas.
- Los métodos predictivoss, como los modelos de lenguaje basados en redes neuronales, intentan predecir palabras a partir de las palabras vecinas observando secuencias de palabras en el corpus y, en el proceso, aprende representaciones distribuidas que nos proporcionan densas incrustaciones de palabras.
Nos centraremos en estos métodos predictivos en esta lección.
Sumergimiento o incrustamiento de palabras-word embeddings¶
Con respecto a los sistemas de reconocimiento de voz o imágenes, toda la información ya está presente en forma de vectores de características ricos y densos incrustados en conjuntos de datos de alta dimensión como espectrogramas de audio e intensidades de píxeles de imagen, como hemos estudiado en otras lecciones.
Sin embargo, cuando se trata de datos de texto sin procesar, especialmente modelos basados en conteo como la bolsa de palabras (bag of words), estamos tratando con palabras individuales que pueden tener sus propios identificadores y no capturan la relación semántica entre palabras.
En lecciones anteriores trabajamos con la técnica de bolsa de palabras en la técnica Lattent Dirichlet Allocation (LDA).
Esto conduce a enormes vectores de palabras dispersas para datos textuales y, por lo tanto, si no tenemos suficientes datos, podemos terminar obteniendo modelos deficientes o incluso sobreajustando los datos debido a la maldición de la dimensionalidad.
Modelos Word2Vec¶
La familia de modelos Word2Vec no es supervisada, lo que esto significa es que puede simplemente darle un corpus sin etiquetas o información adicionales y puede construir incrustaciones densas de palabras a partir del corpus.
Pero aún necesitará aprovechar una metodología de clasificación supervisada una vez que tenga este corpus para acceder a estas incorporaciones.
Haremos esto desde el propio corpus, sin ninguna información auxiliar. Podemos modelar esta arquitectura CBOW ahora como un modelo de clasificación de aprendizaje profundo de modo que tomemos en las palabras de contexto como nuestra entrada, X e intentemos predecir la palabra objetivo, Y.
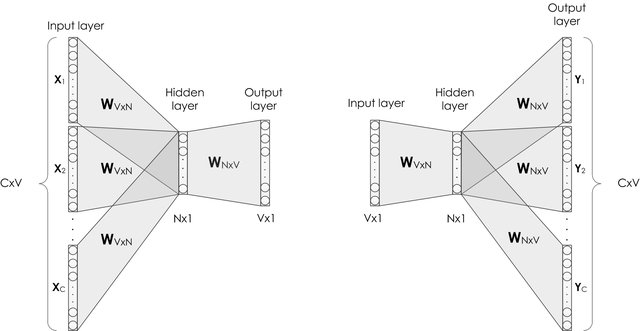
Modelo CBOW¶
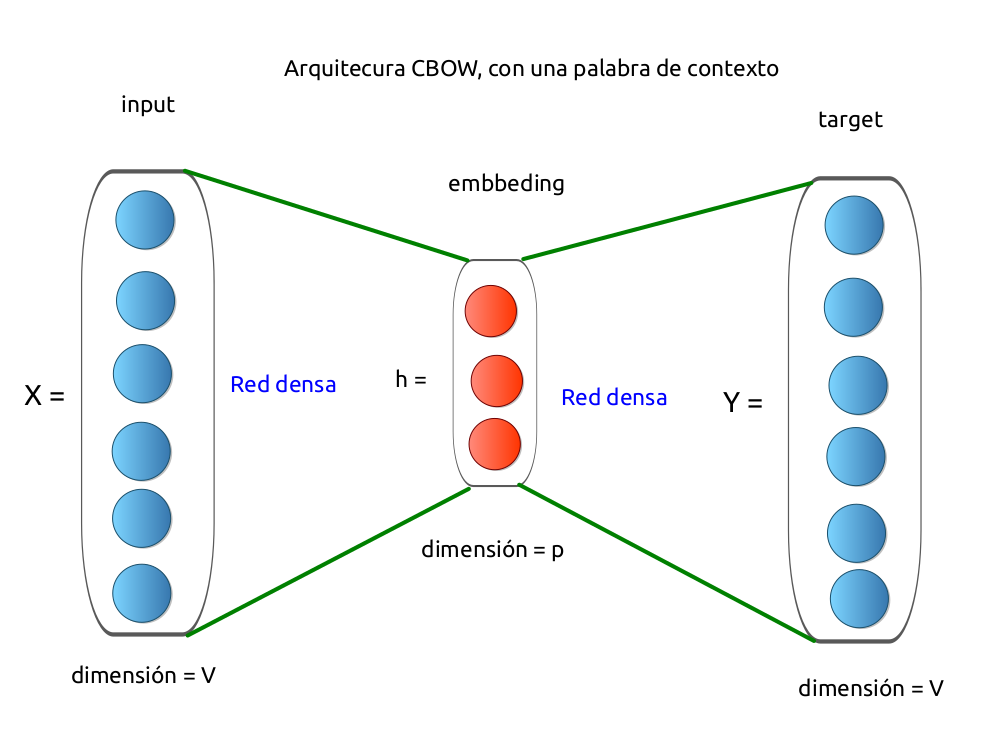
Arquitectura del modelo CBOW con una palabra de contexto
Fuente: Alvaro Montenegro
La siguiente imagen es la arquitectura general CBOW.
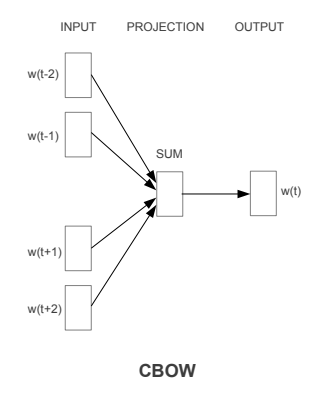
Arquitectura general del modelo CBOW
Fuente: Efficient Estimation of Word Representations in Vector space
Veamos un ejemplo de cómo se hace la preparación de los datos para CBOW
Usaremos el símbolo especial PAD para codificar los espacios faltantes (se hizo en tensorflow con la función sequence_pad. ¿Recuerda?
Consideremos la frase en inglés (más tarde mostraremos como usar las herramientas para Español)
- the quick brown fox jumps over the lazzy dog
La construcción de los contextos usando una ventana de contexto de tamaño 2 es como sigue:
- (PAD, PAD,quick, brown) -> the
- (PAD, the, brown, fox) -> quick
- (the, quick, fox, jumps) -> brown
- (quick, brown, jumps, over) -> fox
- (brown, fox, over, the) -> jumps
- (fox, jumps, the, lazzy) -> over
- (jumps, over, lazzy, dog) -> the
- (over, the, dog, PAD) -> lazzy
- (the, lazzy, PAD, PAD) -> dog
Modelo Skip-gram¶
La arquitectura del modelo Skip-gram generalmente intenta lograr lo contrario de lo que hace el modelo CBOW.
Intenta predecir las palabras de contexto de origen (palabras circundantes) dada una palabra de destino (la palabra central). Teniendo en cuenta nuestra simple oración de antes, "the quick brown fox jumps over the lazy dog”.
Si usamos el modelo CBOW, obtenemos pares de (context_window, target_word) donde si consideramos una ventana de contexto de tamaño 2, tenemos ejemplos como ([quick, fox], brown), ([the, brown], quick) , ([the, dog], lazy) y así sucesivamente.
Ahora, teniendo en cuenta que el objetivo del modelo skip-gram es predecir el contexto a partir de la palabra objetivo, el modelo normalmente invierte los contextos y objetivos e intenta predecir cada palabra de contexto a partir de su palabra objetivo.
Por lo tanto, la tarea se convierte en predecir el contexto [quick, fox] dada la palabra objetivo brown o [the brown] dada la palabra objetivo quick y así sucesivamente.
Por lo tanto, el modelo intenta predecir las palabras de la ventana context_window basándose en target_word.
La figura ilustra la arquitectura skip-gram
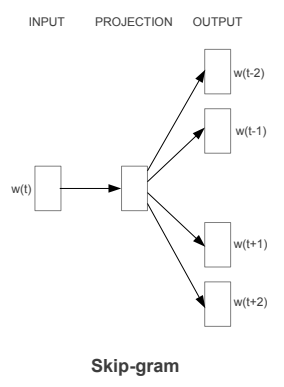
Modelo Skip-gram
Fuente: Dipanjan (DJ) Sarkar
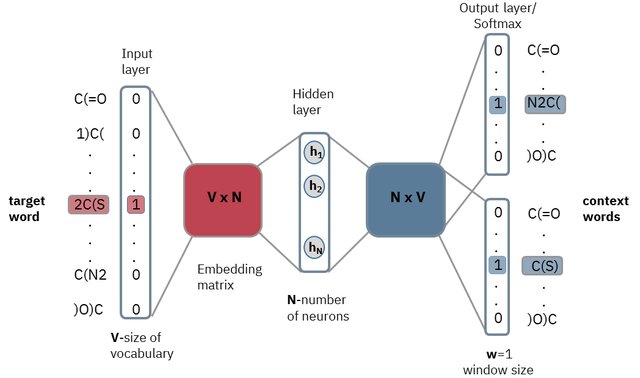
Arquitectura Skip-gram
Fuente: Exploring chemical space using natural language processing
Para esto, alimentamos nuestros pares de modelos de skip-gram son (X,Y) donde X es nuestra entrada e Y es nuestra etiqueta.
Hacemos esto usando los pares [(objetivo, contexto), 1] como muestras de entrada positivas donde objetivo es nuestra palabra de interés y contexto es una palabra de contexto que aparece cerca de la palabra objetivo y la etiqueta positiva 1 indica que este es un par contextualmente relevante.
También introducimos pares [(objetivo, aleatorio), 0] como muestras de entrada negativa donde objetivo es nuevamente nuestra palabra de interés, pero aleatorio significa que es solo una palabra seleccionada al azar de nuestro vocabulario que no tiene contexto o asociación con nuestra palabra objetivo.
Por lo tanto, la etiqueta negativa 0 indica que este es un par contextualmente irrelevante. Hacemos esto para que el modelo pueda aprender qué pares de palabras son contextualmente relevantes y cuáles no y generar incrustaciones similares para palabras semánticamente similares.
La construcción de los pares [(objetivo, aleatorio), 0] se hace tomando al azar palabras objetivo y asociándole al azar palabras con las que no haya conformado parejas de contexto. Los autores citados en las referencias proponen más de una alternativa para generar estas parejas, basados en distinto modelos de muestreo. Por lo general se sugiere que haya tantas parejas positivas como negativas.
En el mismo ejemplo anterior
- the quick brown fox jumps over the lazzy dog
se tiene que las parejas positivas son:
- the: (the, quick), (the, brown) (the, jumps), (the, over), (the, lazzy), (the,dog)
- quick: (quick, the), (quick, brown), (quick, fox)
- brown: (brown, the) (brown, quick), (brown, jumps), (brown, over)
- fox: (fox, quick), (fox, brown), (fox, jumps), (fox, over)
- jumps: (jumps, brown), (jumps, fox), (jumps, over), (jumps, the)
- lazzy: (lazzy, over), (lazzy, the), (lazzy, dog)
- dog: (dog,the), (dog, lazzy)
Una pareja negativa puede ser (quick, lazzy).
Sobre que podemos esperar¶
Supongamos que se ha obtenido la siguiente codificación word2vec para personajes de comics.
word2vec(‘Batman’) = [0.9, 0.8, 0.2]
word2vec(‘Joker’) = [0.8, 0.3, 0.1]
word2vec(‘Spiderman’) = [0.2, .9, 0.8]
word2vec(‘Thanos’) = [0.3, 0.1, 0.9]
- Parece que la primera característica representa la pertenencia al Universo DC. Observa que "Batman" y "Joker" tienen valores más altos para su primera función porque pertenecen al Universo DC.
- Quizás el segundo elemento en la representación de word2vec aquí captura las características de héroe / villano. Es por eso que "Batman" y "Spiderman" tienen valores más altos y "Joker" y "Thanos" tienen valores más pequeños.
- Se podría decir que el tercer componente de la palabra vectores representa los poderes / habilidades sobrenaturales. Todos sabemos que "Batman" y "Joker" no tienen superpoderes y es por eso que sus vectores tienen números pequeños en la tercera posición.
Arquitectura word2vec
Fuente: wor2vec arquitecture
Las tareas linguisticas¶
En el paper de Baroni et al., 2014,Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors, se comparan los métodos clásicos de distribución semántica probabilística de documentos, con los modelos predictivos presentados en esta lección. Para la comparación ello desarrolla las siguientes tareas lingüísticas
- Relación semántica de términos.
- Detección de sinónimos.
- Categorización de conceptos.
- Selección de preferencias. (verbo, sustantivo). Variedad en el uso del lenguaje
- Analogías sintácticas. [(brother,sister), grandson] -> granddaughter.
Invitamos al lector interesado la lectura del paper.
Recursos linguísticos¶
NLTK incluye una pequeña selección de textos del archivo de texto electrónico del Proyecto Gutenberg, que contiene unos 25.000 libros electrónicos gratuitos, alojados en Gutenberg project
Tokenizador de frases Punkt
Este tokenizador divide un texto en una lista de oraciones mediante el uso de un algoritmo no supervisado para construir un modelo de abreviaturas, colocaciones y palabras que inician oraciones. Debe entrenarse en una gran colección de texto sin formato en el idioma de destino antes de que pueda usarse.
El paquete de datos NLTK incluye un tokenizador Punkt previamente entrenado para inglés.
Corpus de juguete¶
Para empezar usaremos el siguiente corpus de juguete
Nuestro corpus de juguetes consta de documentos pertenecientes a varias categorías.
Otro corpus que usaremos en esta lección es la versión King James de la Biblia disponible gratuitamente en Project Gutenberg a través del módulo de corpus en nltk.
Lo cargaremos en breve, en la siguiente sección. Antes de los análisis necesitamos preprocesar y normalizar este texto.
Importa librerías (módulos)¶
import pandas as pd
import numpy as np
import re
import nltk
import matplotlib.pyplot as plt
pd.options.display.max_colwidth = 200
%matplotlib inline
Corpus de juguete¶
corpus = ['The sky is blue and beautiful.',
'Love this blue and beautiful sky!',
'The quick brown fox jumps over the lazy dog.',
"A king's breakfast has sausages, ham, bacon, eggs, toast and beans",
'I love green eggs, ham, sausages and bacon!',
'The brown fox is quick and the blue dog is lazy!',
'The sky is very blue and the sky is very beautiful today',
'The dog is lazy but the brown fox is quick!'
]
labels = ['weather', 'weather', 'animals', 'food', 'food', 'animals', 'weather', 'animals']
corpus = np.array(corpus)
corpus_df = pd.DataFrame({'Document': corpus,
'Category': labels})
corpus_df = corpus_df[['Document', 'Category']]
corpus_df
| Document | Category | |
|---|---|---|
| 0 | The sky is blue and beautiful. | weather |
| 1 | Love this blue and beautiful sky! | weather |
| 2 | The quick brown fox jumps over the lazy dog. | animals |
| 3 | A king's breakfast has sausages, ham, bacon, e... | food |
| 4 | I love green eggs, ham, sausages and bacon! | food |
| 5 | The brown fox is quick and the blue dog is lazy! | animals |
| 6 | The sky is very blue and the sky is very beaut... | weather |
| 7 | The dog is lazy but the brown fox is quick! | animals |
Pre-procesamiento del texto¶
Vamos a hacer un preprocesamiento diferente para cada corpus.
wpt = nltk.WordPunctTokenizer()
stop_words = nltk.corpus.stopwords.words('english')
def normalize_document(doc):
# remove special characters:
doc = re.sub(r'[^a-zA-Z\s]', '', doc, re.I|re.A)
# transform to lower case
doc = doc.lower()
# remove \whitespaces
doc = doc.strip()
# tokenize document
tokens = wpt.tokenize(doc)
# filter stopwords out of document
filtered_tokens = [token for token in tokens if token not in stop_words]
# re-create document from filtered tokens
doc = ' '.join(filtered_tokens)
return doc
# crea una función vectorizada para que actué sobre múltiples textos
normalize_corpus = np.vectorize(normalize_document)
#normalize_corpus
norm_corpus_toy = normalize_corpus(corpus_df)
norm_corpus_toy
array([['sky blue beautiful', 'weather'],
['love blue beautiful sky', 'weather'],
['quick brown fox jumps lazy dog', 'animals'],
['kings breakfast sausages ham bacon eggs toast beans', 'food'],
['love green eggs ham sausages bacon', 'food'],
['brown fox quick blue dog lazy', 'animals'],
['sky blue sky beautiful today', 'weather'],
['dog lazy brown fox quick', 'animals']], dtype='<U51')
The King James Version of the Bible¶
from nltk.corpus import gutenberg
from string import punctuation
nltk.download('gutenberg')
bible = gutenberg.sents('bible-kjv.txt') # tokeniza por sentencias
remove_terms = list(punctuation + '0123456789')
print(remove_terms)
['!', '"', '#', '$', '%', '&', "'", '(', ')', '*', '+', ',', '-', '.', '/', ':', ';', '<', '=', '>', '?', '@', '[', '\\', ']', '^', '_', '`', '{', '|', '}', '~', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
[nltk_data] Downloading package gutenberg to /home/alvaro/nltk_data... [nltk_data] Package gutenberg is already up-to-date!
norm_bible = [[word.lower() for word in sent if word not in remove_terms] for sent in bible]
norm_bible = [' '.join(tok_sent) for tok_sent in norm_bible]
norm_bible = filter(None, normalize_corpus(norm_bible))
norm_bible = [tok_sent for tok_sent in norm_bible if len(tok_sent.split()) > 2]
print('Total lines:', len(bible))
print('\nSample line:', bible[10])
print('\nProcessed line:', norm_bible[10])
Total lines: 30103 Sample line: ['1', ':', '6', 'And', 'God', 'said', ',', 'Let', 'there', 'be', 'a', 'firmament', 'in', 'the', 'midst', 'of', 'the', 'waters', ',', 'and', 'let', 'it', 'divide', 'the', 'waters', 'from', 'the', 'waters', '.'] Processed line: god said let firmament midst waters let divide waters waters
Modelos con Gensim¶
El objeto word2vec de gensim puede usar CBOW o Skip-gram. Los autores de gensim tomaron el código original escritos por Mikolov y colegas, escrito en c++, lo optimizaron y volvieron caja negra. Según ellos gensim es 7 veces más rápido que la implementación que hicimos manualmente en otra lección, usando numpy.
Corpus Biblia ¶
from gensim.models import word2vec
# tokenize sentences in corpus
wpt = nltk.WordPunctTokenizer()
tokenized_corpus_bible = [wpt.tokenize(document) for document in norm_bible]
# Set values for various parameters
feature_size = 100 # Word vector dimensionality (embedding dim)
window_context = 30 # Context window size
min_word_count = 1 # Minimum word count
sample = 1e-3 # Downsample setting for frequent words
w2v_model = word2vec.Word2Vec(tokenized_corpus_bible, size=feature_size,
window=window_context, min_count=min_word_count,
sample=sample, iter=50)
Palabras similares, corpus biblia¶
# view similar words based on gensim's model
similar_words = {search_term: [item[0] for item in w2v_model.wv.most_similar([search_term], topn=5)]
for search_term in ['god', 'jesus', 'noah', 'egypt', 'john', 'gospel', 'moses','famine']}
similar_words
{'god': ['worldly', 'lord', 'reasonable', 'covenant', 'sworn'],
'jesus': ['peter', 'messias', 'immediately', 'apostles', 'nathanael'],
'noah': ['ham', 'shem', 'japheth', 'kenan', 'enosh'],
'egypt': ['pharaoh', 'egyptians', 'bondage', 'flowing', 'rid'],
'john': ['james', 'baptist', 'peter', 'devine', 'galilee'],
'gospel': ['christ', 'repentance', 'faith', 'godly', 'hope'],
'moses': ['congregation', 'ordinance', 'children', 'doctor', 'aaron'],
'famine': ['pestilence', 'peril', 'mildew', 'blasting', 'sword']}
help(word2vec.Word2Vec)
Gráfico con tsne¶
Incrustaciones estocásticas de vecinos con distribución t-Student.
t-SNE, Laurens van der Maaten and Geoffrey Hinton es una herramienta para visualizar datos de alta dimensión. Convierte las similitudes entre los puntos de datos en probabilidades conjuntas y trata de minimizar la divergencia de Kullback-Leibler entre las probabilidades conjuntas de la incrustación de baja dimensión y los datos de alta dimensión. t-SNE tiene una función de costo que no es convexa, es decir, con diferentes inicializaciones podemos obtener diferentes resultados.
Se recomienda fuertemente utilizar otro método de reducción de dimensionalidad (por ejemplo, PCA para datos densos o TruncatedSVD para datos escasos) para reducir el número de dimensiones a una cantidad razonable (por ejemplo, 50) si el número de características es muy alto. Esto suprimirá algo de ruido y acelerará el cálculo de distancias por pares entre muestras. Para obtener más consejos, consulte las preguntas frecuentes de Laurens van der Maaten
from sklearn.manifold import TSNE
words = sum([[k] + v for k, v in similar_words.items()], []) # a list of the words in similar_words
wvs = w2v_model.wv[words] # Coordinates of the words
tsne = TSNE(n_components=2, random_state=100, n_iter=10000, perplexity=2)
np.set_printoptions(suppress=True)
T = tsne.fit_transform(wvs)
labels = words
plt.figure(figsize=(14, 8))
plt.scatter(T[:, 0], T[:, 1], c='orange', edgecolors='r')
for label, x, y in zip(labels, T[:, 0], T[:, 1]):
plt.annotate(label, xy=(x+1, y+1), xytext=(0, 0), textcoords='offset points')

wvs
array([[-0.34405723, -2.2080076 , 0.22129701, ..., -0.27648592,
-0.12405743, -0.15957785],
[-0.11122978, -0.63676333, -0.18996008, ..., 0.06530013,
0.13042438, 0.25724903],
[ 0.9176589 , 1.1386521 , 0.03363332, ..., 1.1606003 ,
-1.6409662 , -1.9810503 ],
...,
[ 1.0055212 , 0.5959988 , -1.167708 , ..., -0.2223904 ,
0.6689782 , -0.24536332],
[ 1.0243756 , 0.62595314, -1.1647514 , ..., -0.17356953,
0.59791714, -0.216457 ],
[-1.8861887 , 0.5809999 , -0.08317056, ..., 2.7208266 ,
5.5738573 , 0.00431524]], dtype=float32)
words
['god', 'worldly', 'lord', 'reasonable', 'covenant', 'sworn', 'jesus', 'peter', 'messias', 'immediately', 'apostles', 'nathanael', 'noah', 'ham', 'shem', 'japheth', 'kenan', 'enosh', 'egypt', 'pharaoh', 'egyptians', 'bondage', 'flowing', 'rid', 'john', 'james', 'baptist', 'peter', 'devine', 'galilee', 'gospel', 'christ', 'repentance', 'faith', 'godly', 'hope', 'moses', 'congregation', 'ordinance', 'children', 'doctor', 'aaron', 'famine', 'pestilence', 'peril', 'mildew', 'blasting', 'sword']
Aplicación a etiquetado automático de textos¶
Para esta aplicación vamos a usar nuestro ejemplo de juguete.
norm_toy = [(text) for text, category in norm_corpus_toy]
#norm_toy = [tok_sent for tok_sent in norm_toy if len(tok_sent.split()) > 2]
norm_toy[5]
'brown fox quick blue dog lazy'
# build word2vec model
wpt = nltk.WordPunctTokenizer()
tokenized_corpus_toy = [wpt.tokenize(document) for document in norm_toy]
# Set values for various parameters
feature_size = 10 # Word vector dimensionality
window_context = 10 # Context window size
min_word_count = 1 # Minimum word count
sample = 1e-3 # Downsample setting for frequent words
w2v_model = word2vec.Word2Vec(tokenized_corpus_toy, size=feature_size,
window=window_context, min_count = min_word_count,
sample=sample, iter=100)
Visualización de incrustaciones con TSNE¶
# visualize embeddings
from sklearn.manifold import TSNE
words = w2v_model.wv.index2word
wvs = w2v_model.wv[words]
tsne = TSNE(n_components=2, random_state=200, n_iter=5000, perplexity=2)
np.set_printoptions(suppress=True)
T = tsne.fit_transform(wvs)
labels = words
plt.figure(figsize=(12, 6))
plt.scatter(T[:, 0], T[:, 1], c='orange', edgecolors='r')
for label, x, y in zip(labels, T[:, 0], T[:, 1]):
plt.annotate(label, xy=(x+1, y+1), xytext=(0, 0), textcoords='offset points')

Recuerde que nuestro corpus es extremadamente pequeño, por lo que para obtener incrustaciones de palabras significativas y para que el modelo obtenga más contexto y semántica, más datos ayudan.
Ahora bien, ¿qué es una palabra incrustada en este escenario?
Por lo general, es un vector denso para cada palabra, como se muestra en el siguiente ejemplo para la palabra sky.
w2v_model.wv['sky']
array([ 0.0222188 , -0.00322705, 0.00577812, 0.02297305, 0.00253111,
-0.03698301, -0.00314448, -0.03604106, 0.00387173, 0.01324753],
dtype=float32)
Incrustación de documentos¶
Ahora suponga que quisiéramos agrupar los ocho documentos de nuestro corpus de juguetes, necesitaríamos obtener las incrustaciones de nivel de documento de cada una de las palabras presentes en cada documento.
Una estrategia sería promediar las incrustaciones de palabras para cada palabra en un documento.
Esta es una estrategia extremadamente útil y puede adoptar la misma para sus propios problemas. Apliquemos esto ahora en nuestro corpus para obtener características para cada documento.
def average_word_vectors(words, model, vocabulary, num_features):
feature_vector = np.zeros((num_features,),dtype="float64")
nwords = 0.
for word in words:
if word in vocabulary:
nwords = nwords + 1.
feature_vector = np.add(feature_vector, model[word])
if nwords:
feature_vector = np.divide(feature_vector, nwords)
return feature_vector
def averaged_word_vectorizer(corpus, model, num_features):
vocabulary = set(model.wv.index2word)
features = [average_word_vectors(tokenized_sentence, model, vocabulary, num_features)
for tokenized_sentence in corpus]
return np.array(features)
# get document level embeddings
w2v_feature_array = averaged_word_vectorizer(corpus=tokenized_corpus_toy, model=w2v_model, num_features=feature_size)
<ipython-input-45-de269809cb6b>:9: DeprecationWarning: Call to deprecated `__getitem__` (Method will be removed in 4.0.0, use self.wv.__getitem__() instead). feature_vector = np.add(feature_vector, model[word])
pp = pd.DataFrame(w2v_feature_array)
pp
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -0.003041 | -0.007926 | 0.018282 | 0.003400 | -0.003612 | 0.017513 | -0.021539 | 0.000254 | 0.014870 | 0.001121 |
| 1 | 0.004246 | -0.016616 | 0.002898 | -0.003310 | 0.001360 | 0.015432 | -0.020553 | 0.002866 | 0.006426 | -0.000660 |
| 2 | 0.005549 | -0.010005 | -0.016900 | 0.000572 | -0.012724 | 0.019170 | -0.025599 | -0.007053 | -0.014700 | -0.017178 |
| 3 | 0.006906 | 0.009039 | 0.000851 | 0.010022 | 0.001052 | -0.004086 | 0.006732 | -0.004544 | -0.006839 | -0.005179 |
| 4 | 0.007297 | 0.004711 | -0.014360 | 0.012438 | -0.011912 | 0.015900 | 0.001450 | -0.018203 | -0.009471 | -0.005930 |
| 5 | 0.012570 | -0.009762 | -0.005562 | 0.001511 | -0.006945 | 0.023436 | -0.029692 | 0.000243 | -0.008374 | -0.003993 |
| 6 | -0.000583 | -0.003620 | 0.010479 | 0.014733 | -0.004924 | 0.005844 | -0.010194 | -0.009180 | 0.019397 | 0.006925 |
| 7 | 0.015602 | -0.009999 | -0.014323 | 0.008859 | -0.010401 | 0.020386 | -0.026200 | -0.004136 | -0.011145 | -0.012100 |
Ahora que tenemos nuestras características para cada documento, agrupemos estos documentos utilizando el algoritmo de propagación de afinidad, que es un algoritmo de agrupación basado en el concepto de "paso de mensajes" entre puntos de datos y no necesita el número de agrupaciones como una entrada explícita que a menudo es requerido por algoritmos de agrupación en clústeres basados en particiones.
Propagación por afinidad: Afinity propagation¶
Este es el resumen del artículo de Frey y Duek.
"La agrupación de datos mediante la identificación de un subconjunto de ejemplos representativos es importante para procesar señales sensoriales y detectar patrones en los datos.
Estos "ejemplos" se pueden encontrar eligiendo aleatoriamente un subconjunto inicial de puntos de datos y luego refinándolo iterativamente, pero esto funciona bien solo si esa elección inicial está cerca de una buena solución.
Diseñamos un método llamado "propagación por afinidad", que toma como entrada medidas de similitud entre pares de puntos de datos. Los mensajes de valor real se intercambian entre puntos de datos hasta que emerge gradualmente un conjunto de ejemplos de alta calidad y los grupos correspondientes.
Utilizamos la propagación por afinidad para agrupar imágenes de rostros, detectar genes en datos de microarrays, identificar oraciones representativas en este manuscrito e identificar ciudades a las que se accede de manera eficiente mediante viajes en avión.
La propagación por afinidad encontró grupos con un error mucho menor que otros métodos, y lo hizo en menos de una centésima parte del tiempo."
from sklearn.cluster import AffinityPropagation
ap = AffinityPropagation()
ap.fit(w2v_feature_array)
cluster_labels = ap.labels_
cluster_labels = pd.DataFrame(cluster_labels, columns=['ClusterLabel'])
pd.concat([corpus_df, cluster_labels], axis=1)
/home/alvaro/anaconda3/envs/nlp/lib/python3.8/site-packages/sklearn/cluster/_affinity_propagation.py:148: FutureWarning: 'random_state' has been introduced in 0.23. It will be set to None starting from 1.0 (renaming of 0.25) which means that results will differ at every function call. Set 'random_state' to None to silence this warning, or to 0 to keep the behavior of versions <0.23. warnings.warn(
| Document | Category | ClusterLabel | |
|---|---|---|---|
| 0 | The sky is blue and beautiful. | weather | 0 |
| 1 | Love this blue and beautiful sky! | weather | 0 |
| 2 | The quick brown fox jumps over the lazy dog. | animals | 2 |
| 3 | A king's breakfast has sausages, ham, bacon, eggs, toast and beans | food | 1 |
| 4 | I love green eggs, ham, sausages and bacon! | food | 1 |
| 5 | The brown fox is quick and the blue dog is lazy! | animals | 2 |
| 6 | The sky is very blue and the sky is very beautiful today | weather | 0 |
| 7 | The dog is lazy but the brown fox is quick! | animals | 2 |
Finalmente hagamos un plot de los documentos usando un análisis de componentes principales (ACP).
from sklearn.decomposition import PCA
pca = PCA(n_components=2, random_state=0)
pcs = pca.fit_transform(w2v_feature_array)
labels = ap.labels_
categories = list(corpus_df['Category'])
plt.figure(figsize=(8, 6))
for i in range(len(labels)):
label = labels[i]
color = 'orange' if label == 0 else 'blue' if label == 1 else 'green'
annotation_label = categories[i]
x, y = pcs[i]
plt.scatter(x, y, c=color, edgecolors='k')
plt.annotate(annotation_label, xy=(x+1e-4, y+1e-3), xytext=(0, 0), textcoords='offset points')

Modelos pre-entrenados. El modelo Glove¶
El modelo GloVe significa Vectores Globales, que es un modelo de aprendizaje no supervisado que se puede utilizar para obtener vectores de palabras densas similares a Word2Vec.
Sin embargo, la técnica es diferente y el entrenamiento se realiza en una matriz global de co-ocurrencia palabra-palabra, usando el contexto de las mismas, lo que nos da un espacio vectorial con subestructuras significativas.
Este método fue inventado en Stanford por Pennington et al. y se recomienda que leer el artículo original sobre GloVe, GloVe: Global Vectors for Word Representation de Pennington et al. que es una lectura excelente para tener una perspectiva de cómo funciona este modelo.
No cubriremos la implementación del modelo desde cero con demasiado detalle aquí, pero si está interesado en el código real, puede consultar la página oficial de GloVe.
Aquí mantendremos las cosas simples e intentaremos comprender los conceptos básicos detrás del modelo GloVe. Hemos hablado de métodos de factorización matricial basados en recuento como LSA y métodos predictivos como Word2Vec.
El paper afirma que, actualmente, ambas familias sufren importantes inconvenientes.
- Los métodos como LSA aprovechan de manera eficiente la información estadística, pero funcionan relativamente mal en la tarea de analogía de palabras, como la forma en que descubrimos palabras semánticamente similares.
- Los métodos como skip-gram pueden funcionar mejor en la tarea de analogía, pero no utilizan tan bien las estadísticas del corpus a nivel global.
La metodología básica del modelo GloVe es crear primero una enorme matriz de co-ocurrencia palabra-contexto que consta de pares (palabra, contexto) de modo que cada elemento de esta matriz represente la frecuencia con la que aparece una palabra con el contexto (que puede ser una secuencia de palabras).
La idea entonces es aplicar factorización matricial para aproximar esta matriz como se muestra en la siguiente figura.
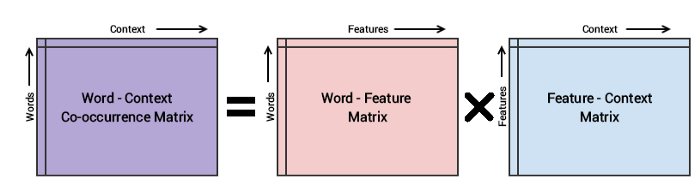
Base matemática del modelo Glove
Teniendo en cuenta la matriz Word-Context (WC), la matriz Word-Feature (WF) y la matriz Feature-Context (FC), intentamos factorizar WC = WF x FC, de modo que nuestro objetivo es reconstruir WC a partir de WF y FC multiplicando ellos.
Para esto, normalmente inicializamos WF y FC con algunos pesos aleatorios e intentamos multiplicarlos para obtener WC ’(una aproximación de WC) y medir qué tan cerca está de WC. Hacemos esto varias veces usando el Descenso de gradiente estocástico (SGD) para minimizar el error.
Finalmente, la matriz Word-Feature (WF) nos da las incrustaciones de palabras para cada palabra donde F se puede preestablecer para un número específico de dimensiones.
Un punto muy importante para recordar es que los modelos Word2Vec y GloVe son muy similares en su funcionamiento.
Ambos tienen como objetivo construir un espacio vectorial donde la posición de cada palabra está influenciada por las palabras vecinas en función de su contexto y semántica.
Word2Vec comienza con ejemplos individuales locales de pares de co-ocurrencia de palabras y GloVe comienza con estadísticas globales de co-ocurrencia agregadas en todas las palabras del corpus.
Introducción a spaCy¶
Intentemos aprovechar las incrustaciones basadas en GloVe para nuestra tarea de agrupación de documentos.
El marco de trabajo spaCy es muy popular y viene con capacidades para aprovechar las incrustaciones de GloVe basadas en diferentes modelos de lenguaje.
También puede obtener vectores de palabras previamente entrenados y cargarlos según sea necesario usando gensim o spacy.
Primero instalaremos spacy y usaremos el modelo en_core_web_md un modelo intermedio del inglés. Si desea resultados más potentes instale en_vectors_web_lg que consiste en vectores de palabras de 300 dimensiones entrenados en Common Crawl con GloVe, GloVe.
Modelos en Español¶
En la página spacy-models encuentra los modelos disponibles en spacy, basados en Glove, para distintos idiomas.
En particular para Español se tienen modelos para Español en spacy :
- es_core_news_sm (small): 15 MB
- es_core_news_md (medium): 500k keys, 20k unique vectors (300 dimensions), 45 MB
- es_core_news_lg (long): : 500k keys, 500k unique vectors (300 dimensions), 546 MB
Para bajar e instalar por ejemplo es_core_news_md puede escribir
python -m spacy download es_core_news_md
Veamos
#!conda install -c conda-forge spacy
# !python -m spacy en_core_web_md
import spacy
nlp = spacy.load('en_core_web_md')
total_vectors = len(nlp.vocab.vectors)
print('Total word vectors:', total_vectors)
Total word vectors: 20000
Si todo va bien hasta aquí, podemos continuar.
unique_words = list(set([word for sublist in [doc.split() for doc in norm_corpus] for word in sublist]))
word_glove_vectors = np.array([nlp(word).vector for word in unique_words])
pd.DataFrame(word_glove_vectors, index=unique_words)
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 290 | 291 | 292 | 293 | 294 | 295 | 296 | 297 | 298 | 299 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| green | -0.072368 | 0.233200 | 0.137260 | -0.156630 | 0.248440 | 0.349870 | -0.241700 | -0.091426 | -0.530150 | 1.34130 | ... | -0.405170 | 0.243570 | 0.437300 | -0.461520 | -0.352710 | 0.336250 | 0.069899 | -0.111550 | 0.532930 | 0.712680 |
| dog | -0.401760 | 0.370570 | 0.021281 | -0.341250 | 0.049538 | 0.294400 | -0.173760 | -0.279820 | 0.067622 | 2.16930 | ... | 0.022908 | -0.259290 | -0.308620 | 0.001754 | -0.189620 | 0.547890 | 0.311940 | 0.246930 | 0.299290 | -0.074861 |
| fox | -0.348680 | -0.077720 | 0.177750 | -0.094953 | -0.452890 | 0.237790 | 0.209440 | 0.037886 | 0.035064 | 0.89901 | ... | -0.283050 | 0.270240 | -0.654800 | 0.105300 | -0.068738 | -0.534750 | 0.061783 | 0.123610 | -0.553700 | -0.544790 |
| toast | 0.130740 | -0.193730 | 0.253270 | 0.090102 | -0.272580 | -0.030571 | 0.096945 | -0.115060 | 0.484000 | 0.84838 | ... | 0.142080 | 0.481910 | 0.045167 | 0.057151 | -0.149520 | -0.495130 | -0.086677 | -0.569040 | -0.359290 | 0.097443 |
| lazy | -0.353320 | -0.299710 | -0.176230 | -0.321940 | -0.385640 | 0.586110 | 0.411160 | -0.418680 | 0.073093 | 1.48650 | ... | 0.402310 | -0.038554 | -0.288670 | -0.244130 | 0.460990 | 0.514170 | 0.136260 | 0.344190 | -0.845300 | -0.077383 |
| brown | -0.374120 | -0.076264 | 0.109260 | 0.186620 | 0.029943 | 0.182700 | -0.631980 | 0.133060 | -0.128980 | 0.60343 | ... | -0.015404 | 0.392890 | -0.034826 | -0.720300 | -0.365320 | 0.740510 | 0.108390 | -0.365760 | -0.288190 | 0.114630 |
| ham | -0.773320 | -0.282540 | 0.580760 | 0.841480 | 0.258540 | 0.585210 | -0.021890 | -0.463680 | 0.139070 | 0.65872 | ... | 0.464470 | 0.481400 | -0.829200 | 0.354910 | 0.224530 | -0.493920 | 0.456930 | -0.649100 | -0.131930 | 0.372040 |
| jumps | -0.334840 | 0.215990 | -0.350440 | -0.260020 | 0.411070 | 0.154010 | -0.386110 | 0.206380 | 0.386700 | 1.46050 | ... | -0.107030 | -0.279480 | -0.186200 | -0.543140 | -0.479980 | -0.284680 | 0.036022 | 0.190290 | 0.692290 | -0.071501 |
| today | -0.156570 | 0.594890 | -0.031445 | -0.077586 | 0.278630 | -0.509210 | -0.066350 | -0.081890 | -0.047986 | 2.80360 | ... | -0.326580 | -0.413380 | 0.367910 | -0.262630 | -0.203690 | -0.296560 | -0.014873 | -0.250060 | -0.115940 | 0.083741 |
| quick | -0.445630 | 0.191510 | -0.249210 | 0.465900 | 0.161950 | 0.212780 | -0.046480 | 0.021170 | 0.417660 | 1.68690 | ... | -0.329460 | 0.421860 | -0.039543 | 0.150180 | 0.338220 | 0.049554 | 0.149420 | -0.038789 | -0.019069 | 0.348650 |
| eggs | -0.417810 | -0.035192 | -0.126150 | -0.215930 | -0.669740 | 0.513250 | -0.797090 | -0.068611 | 0.634660 | 1.25630 | ... | -0.232860 | -0.139740 | -0.681080 | -0.370920 | -0.545510 | 0.073728 | 0.111620 | -0.324700 | 0.059721 | 0.159160 |
| breakfast | 0.073378 | 0.227670 | 0.208420 | -0.456790 | -0.078219 | 0.601960 | -0.024494 | -0.467980 | 0.054627 | 2.28370 | ... | 0.647710 | 0.373820 | 0.019931 | -0.033672 | -0.073184 | 0.296830 | 0.340420 | -0.599390 | -0.061114 | 0.232200 |
| beautiful | 0.171200 | 0.534390 | -0.348540 | -0.097234 | 0.101800 | -0.170860 | 0.295650 | -0.041816 | -0.516550 | 2.11720 | ... | -0.285540 | 0.104670 | 0.126310 | 0.120040 | 0.254380 | 0.247400 | 0.207670 | 0.172580 | 0.063875 | 0.350990 |
| kings | 0.259230 | -0.854690 | 0.360010 | -0.642000 | 0.568530 | -0.321420 | 0.173250 | 0.133030 | -0.089720 | 1.52860 | ... | -0.470090 | 0.063743 | -0.545210 | -0.192310 | -0.301020 | 1.068500 | 0.231160 | -0.147330 | 0.662490 | -0.577420 |
| love | 0.139490 | 0.534530 | -0.252470 | -0.125650 | 0.048748 | 0.152440 | 0.199060 | -0.065970 | 0.128830 | 2.05590 | ... | -0.124380 | 0.178440 | -0.099469 | 0.008682 | 0.089213 | -0.075513 | -0.049069 | -0.015228 | 0.088408 | 0.302170 |
| bacon | -0.430730 | -0.016025 | 0.484620 | 0.101390 | -0.299200 | 0.761820 | -0.353130 | -0.325290 | 0.156730 | 0.87321 | ... | 0.304240 | 0.413440 | -0.540730 | -0.035930 | -0.429450 | -0.246590 | 0.161490 | -1.065400 | -0.244940 | 0.269540 |
| sausages | -0.481340 | 0.023467 | 0.396470 | 0.364770 | -0.083069 | 0.684590 | 0.007079 | -0.210320 | -0.021993 | 0.81876 | ... | 0.602560 | 0.297010 | -0.543030 | -0.169150 | -0.689910 | -0.307360 | 0.193250 | -0.634980 | 0.183010 | 0.285290 |
| sky | 0.312550 | -0.303080 | 0.019587 | -0.354940 | 0.100180 | -0.141530 | -0.514270 | 0.886110 | -0.530540 | 1.55660 | ... | -0.667050 | 0.279110 | 0.500970 | -0.277580 | -0.143720 | 0.342710 | 0.287580 | 0.537740 | 0.363490 | 0.496920 |
| blue | 0.129450 | 0.036518 | 0.032298 | -0.060034 | 0.399840 | -0.103020 | -0.507880 | 0.076630 | -0.422920 | 0.81573 | ... | -0.501280 | 0.169010 | 0.548250 | -0.319380 | -0.072887 | 0.382950 | 0.237410 | 0.052289 | 0.182060 | 0.412640 |
| beans | -0.423290 | -0.264500 | 0.200870 | 0.082187 | 0.066944 | 1.027600 | -0.989140 | -0.259950 | 0.145960 | 0.76645 | ... | 0.048760 | 0.351680 | -0.786260 | -0.368790 | -0.528640 | 0.287650 | -0.273120 | -1.114000 | 0.064322 | 0.223620 |
20 rows × 300 columns
Veamos una gŕafico TSNE para este caso.
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, random_state=0, n_iter=5000, perplexity=3)
np.set_printoptions(suppress=True)
T = tsne.fit_transform(word_glove_vectors)
labels = unique_words
plt.figure(figsize=(12, 6))
plt.scatter(T[:, 0], T[:, 1], c='orange', edgecolors='r')
for label, x, y in zip(labels, T[:, 0], T[:, 1]):
plt.annotate(label, xy=(x+1, y+1), xytext=(0, 0), textcoords='offset points')

Finalmente una clasificación k-means.
from sklearn.cluster import KMeans
doc_glove_vectors = np.array([nlp(str(doc)).vector for doc in norm_corpus])
km = KMeans(n_clusters=3, random_state=0)
km.fit_transform(doc_glove_vectors)
cluster_labels = km.labels_
cluster_labels = pd.DataFrame(cluster_labels, columns=['ClusterLabel'])
pd.concat([corpus_df, cluster_labels], axis=1)
| Document | Category | ClusterLabel | |
|---|---|---|---|
| 0 | The sky is blue and beautiful. | weather | 1 |
| 1 | Love this blue and beautiful sky! | weather | 1 |
| 2 | The quick brown fox jumps over the lazy dog. | animals | 2 |
| 3 | A king's breakfast has sausages, ham, bacon, eggs, toast and beans | food | 0 |
| 4 | I love green eggs, ham, sausages and bacon! | food | 0 |
| 5 | The brown fox is quick and the blue dog is lazy! | animals | 2 |
| 6 | The sky is very blue and the sky is very beautiful today | weather | 1 |
| 7 | The dog is lazy but the brown fox is quick! | animals | 2 |
El modelo FastText¶
El modelo FastText fue introducido por primera vez por Facebook en 2016 como una extensión y supuestamente una mejora del modelo vainilla de Word2Vec.
Está basado en el artículo original titulado Enriching Word Vectors with Subword Information de Mikolov et al. que es una lectura excelente para obtener una comprensión profunda de cómo funciona este modelo. En general, FastText es un marco para el aprendizaje de representaciones de palabras y también para realizar una clasificación de texto sólida, rápida y precisa.
El marco es de código abierto de Facebook en GitHub y afirma tener lo siguiente.
- Vectores de palabras en inglés de última generación.
- Vectores de palabras para 157 idiomas entrenados en Wikipedia y rastreo.
- Modelos para identificación de idiomas y diversas tareas supervisadas.
De acuedo con los autores, en general, los modelos predictivos como el modelo Word2Vec suelen considerar cada palabra como una entidad distinta (por ejemplo, dónde) y generan una incrustación densa para la palabra.
Sin embargo, esto representa una seria limitación con los idiomas que tienen un vocabulario masivo y muchas palabras raras que pueden no aparecer mucho en diferentes corpus. El modelo Word2Vec normalmente ignora la estructura morfológica de cada palabra y considera una palabra como una sola entidad.
El modelo FastText considera cada palabra como una bolsa de n-gramas de caracteres. Esto también se denomina modelo de subpalabras en el documento.
Se agregan símbolos de límites especiales
Tomando la palabra where y n = 3 (tri-gramas) como ejemplo, estará representada por el carácter n-gramas: <wh, whe, her, ere, re> y la secuencia especial
Tenga en cuenta que la secuencia, correspondiente a la palabra
En la práctica, el artículo recomienda extraer todos los n-gramas para 3≤n≤6 Este es un enfoque muy simple, y se podrían considerar diferentes conjuntos de n-gramas, por ejemplo, tomando todos los prefijos y sufijos.
Normalmente asociamos una representación vectorial (incrustación) a cada n-grama de una palabra. Por tanto, podemos representar una palabra mediante la suma de las representaciones vectoriales de sus n-gramas o el promedio de la incrustación de estos n-gramas.
Según los autores, debido a este efecto de aprovechar los n-gramas de palabras individuales basadas en sus caracteres, existe una mayor probabilidad de que las palabras raras obtengan una buena representación, ya que sus n-gramas basados en caracteres deben aparecer en otras palabras del corpus.
Vamos a la práctica.
Gráfico basado en ACP¶
from sklearn.decomposition import PCA
words = sum([[k] + v for k, v in similar_words.items()], [])
wvs = ft_model.wv[words]
pca = PCA(n_components=2)
np.set_printoptions(suppress=True)
P = pca.fit_transform(wvs)
labels = words
plt.figure(figsize=(18, 10))
plt.scatter(P[:, 0], P[:, 1], c='lightgreen', edgecolors='g')
for label, x, y in zip(labels, P[:, 0], P[:, 1]):
plt.annotate(label, xy=(x+0.06, y+0.03), xytext=(0, 0), textcoords='offset points')

¡Podemos ver muchos patrones interesantes! Noah, su hijo Shem y su abuelo Matusalén están cerca el uno del otro.
También vemos a Dios asociado con Moisés y Egipto donde soportó las plagas bíblicas, incluidas el hambre y la pestilencia. También Jesús y algunos de sus discípulos están asociados muy cerca unos de otros.
Para acceder a cualquiera de las incrustaciones de palabras, puede indexar el modelo con la palabra de la siguiente manera.
ft_model.wv['jesus']
array([ 0.17718132, -0.19709586, 0.25530368, -0.03545383, 0.76611197,
0.13848874, -0.05604259, -0.02210611, 0.20488791, 0.17241424,
-0.48582503, 0.05138803, 0.18877277, -0.05722686, 0.16079944,
-0.35822144, 0.5743341 , 0.06780402, -0.3008401 , -0.01876839,
0.09861004, 0.19337818, -0.41912812, -0.09735594, 0.27861547,
-0.16222528, 0.4602971 , -0.46578154, -0.1064477 , 0.42992973,
0.06472561, 0.16854142, 0.00933973, 0.04791377, 0.18041942,
0.05097766, -0.27860153, 0.11862674, 0.06555321, 0.06788372,
-0.20273678, 0.40175107, -0.00107946, 0.31407824, -0.08528732,
0.0850415 , -0.47559258, 0.11246356, -0.20559783, -0.14798933,
0.14808579, -0.23450403, -0.15976913, 0.15428546, -0.17971121,
0.40536925, -0.02532636, -0.49386576, 0.20632172, -0.2625528 ,
0.00773285, 0.50493914, -0.12690398, -0.23250476, -0.41272193,
-0.28254688, -0.43109837, 0.13680667, 0.2277264 , 0.3559441 ,
0.19570442, 0.04869397, 0.23427969, -0.1791803 , 0.17570105,
0.4019909 , 0.17426194, -0.06929158, 0.09311975, -0.13352323,
-0.34312806, 0.46036175, 0.32394302, -0.5765276 , -0.0285289 ,
-0.20002018, 0.16436048, -0.2363575 , -0.21630326, -0.35550892,
-0.37143084, 0.33584678, 0.05374669, 0.0320545 , 0.1500369 ,
0.11470003, 0.50080407, -0.21105155, 0.10132139, -0.00495873],
dtype=float32)
Con estas incrustaciones, podemos realizar algunas tareas interesantes en lenguaje natural. Uno de estos sería encontrar similitudes entre diferentes palabras (entidades).
print(ft_model.wv.similarity(w1='god', w2='satan'))
print(ft_model.wv.similarity(w1='god', w2='jesus'))
0.3183717 0.6547534
o también!!
st1 = "god jesus satan john"
print('Odd one out for [',st1, ']:',
ft_model.wv.doesnt_match(st1.split()))
st2 = "john peter james judas"
print('Odd one out for [',st2, ']:',
ft_model.wv.doesnt_match(st2.split()))
Odd one out for [ god jesus satan john ]: satan Odd one out for [ john peter james judas ]: judas
/home/alvaro/anaconda3/envs/tf2/lib/python3.7/site-packages/gensim/models/keyedvectors.py:877: FutureWarning: arrays to stack must be passed as a "sequence" type such as list or tuple. Support for non-sequence iterables such as generators is deprecated as of NumPy 1.16 and will raise an error in the future. vectors = vstack(self.word_vec(word, use_norm=True) for word in used_words).astype(REAL)
Modelos de incrustaciones del Español Preentrenados¶
A continuación encontrará enlaces a incrustaciones de palabras en español calculadas con diferentes métodos y de diferentes corpus. Este trabajo es liderado en el Departamento de Ciencias de la Computación Universidad de Chile.
S incluye una descripción de los parámetros utilizados para calcular las incrustaciones, junto con estadísticas simples de los vectores, vocabulario y descripción del corpus a partir del cual se calcularon las incrustaciones.
Se proporcionan enlaces directos a las incrustaciones, así que consulte las fuentes originales para obtener una cita adecuada (consulte también las Referencias). Un ejemplo del uso de algunas de estas incrustaciones se puede encontrar aquí o en este tutorial (ambos en español).
Conclusión¶
Estos ejemplos deberían darle una buena idea acerca de las estrategias más nuevas y eficientes para aprovechar los modelos de lenguaje de aprendizaje profundo para extraer características de los datos de texto y también abordar problemas como la semántica de palabras, el contexto y la escasez de datos.