Aprendizaje Profundo ¶
Diplomado en Inteligencia Artificial y Aprendizaje Profundo ¶
Modelos Generativos ¶
Profesores¶
- Alvaro Montenegro, PhD, ammontenegrod@unal.edu.co
- Camilo José Torres Jiménez, Msc, cjtorresj@unal.edu.co
- Daniel Montenegro, Msc, dextronomo@gmail.com
Asesora Medios y Marketing digital¶
- Maria del Pilar Montenegro, pmontenegro88@gmail.com
- Jessica López Mejía, jelopezme@unal.edu.co
- Venus Puertas, vpuertasg@unal.edu.co
Jefe Jurídica¶
- Paula Andrea Guzmán, guzmancruz.paula@gmail.com
Coordinador Jurídico¶
- David Fuentes, fuentesd065@gmail.com
Desarrolladores Principales¶
- Dairo Moreno, damoralesj@unal.edu.co
- Joan Castro, jocastroc@unal.edu.co
- Bryan Riveros, briveros@unal.edu.co
- Rosmer Vargas, rovargasc@unal.edu.co
Expertos en Bases de Datos¶
- Giovvani Barrera, udgiovanni@gmail.com
- Camilo Chitivo, cchitivo@unal.edu.co
Referencias¶
- [Improving Language Understanding
by Generative Pre-Training](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf), Radford A. et al., 2018
- Language Models are Unsupervised Multitask Learners, Radford A. et al., 2019
- Language Models are Few-Shot Learners, Brown T. et al., Julio de 2020
- Turing-NLG: A 17-billion-parameter language model by Microsoft, Febrero 13 de 2020
- Recipes for building an open-domain chatbot, Roller S. et al., Abril 28 de 2020
- Internet-Augmented Dialogue Generation, Komeili M. et al., 15 de Julio de 2021
- Beyond Goldfish Memory: Long-Term Open-Domain Conversation, Xu J. et al., 15 de Julio de 2021
- Using DeepSpeed and Megatron to Train Megatron-Turing NLG 530B, A Large-Scale Generative Language Model, 4 de Febrero de 2022
- PaLM: Scaling Language Modeling with Pathways, 5 de Abril de 2022
- OPT: Open Pre-trained Transformer Language Models, 5 de Mayo de 2022
- Aprendizaje Profundo-Diplomado
- Aprendizaje Profundo-PLN
- Ashish Vaswani et al., Attention Is All You Need, diciembre 2017.
- Dennis Rothman, Transformers for Natural Language processing, enero 2021.
1. Varios, Dive into deep learning, enero 2021
Contenido¶
Introducción¶
Para esta lección final en lenguaje natural, veamos un mapa cronológico de los modelos Transformers:
 Fuente: How do Transformers work?
Fuente: How do Transformers work?
Como se puede observar, hay muchos modelos que aún falta revisar.
Sin embargo, el grueso de las metodologías está completo.
Un hecho bastante impactante, es la aparente moda, como se ve a continuación:
 Fuente: Transformers are big models
Fuente: Transformers are big models
Aunque esto pareciera estadísticamente incorrecto y hasta matemáticamente tramposo, hay una razón de fondo para esta tendencia, que veremos más adelante y que justifica tal moda que parece no tener un límite cercano.

GPT¶
GPT significa Generative Pre-trained Transformer, y fue un modelo construido por el equipo de OpenAI de esa época para demostrar las capacidades de los modelos transformers.
Fue hecho a la par con el modelo BERT, pero en este caso, sólo se tomó la parte decodificadora del transformer original.
Recordemos la arquitectura del transformer original:
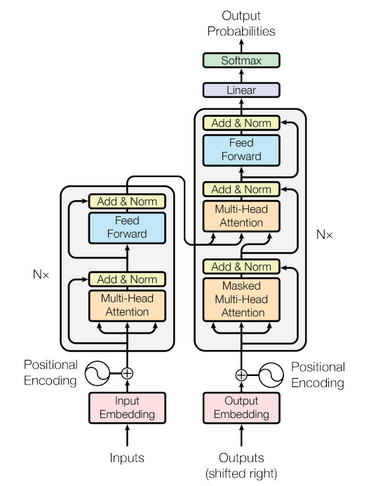
En comparación con la arquitectura BERT, como el decodificador es un modelo auto-regresivo, no permite mirar tokens hacia adelante cuando se intenta generar texto.
Entonces, la estrategia de entrenamiento es sencilla: Entrenar el modelo en un corpus no etiquetado y hacer un fine-tuning de cambios mínimos de la arquitectura para tareas específicas y ver su comportamiento en las tareas de NLU, por ejemplo, mirando el GLUE y otros.
Recordemos que la justificación de esta técnica es el hecho de no tener acceso a datasets etiquetados de gran magnitud, porque son costosos y de tiempo extenso de construcción. Incluso en el caso de tenerlos, un gran problema es la calidad de los embeddings de los tokens.
Por otro lado, en el paper se cuestiona la manera más eficiente de hacer transfer learning.
Siguiendo una línea de pensamiento específica, OpenAI decide recurrir a funciones auxiliares para realizar este proceso de fine-tuning.
Pre-entrenamiento¶
Para esta primera fase, el modelo se entrena con la siguiente función de verosimilitud (maximización):
$$L_1(U) = \sum_i\log P(u_i|u_{i-k},\dots,u_{i-1};\Theta)$$donde $U=\{u_1,\dots,u_n\}$ es la tokenización del corpus no etiquetado, $k$ es la ventana de contexto, y $P$ es la probabilidad condicional, que es modelada con una red neuronal con parámetros $\Theta$. Los parámetros se entrenan usando gradiente descendiente estocástico.
El modelo GPT es realmente, sencillo, como su ecuación indica:

Fuente: Improving Language Understanding by Generative Pre-Training
donde $U$ es el vector de contexto de los tokens, $n$ es el número de layers, $W_e$ la matriz de embeddings de los tokens y $W_p$ la matriz de embedding posicional.
Fine-tuning¶
Para el fine-tuning, se asume que se tiene una sucesión de tokens de entrada $x^1, \dots, x^m$ con una etiqueta $y$ de algún conjunto etiquetado $C$.
En este caso:
$$P(y|x^1, \dots, x^m)=\text{softmax}(h_{l}^{m} W_y)$$Dando el siguiente objetivo a maximizar:
$$L_2(C) = \sum_{(x,y)}\log P(y|x^1, \dots, x^m)$$El equipo de OpenAI encontró que la siguiente función auxiliar ayuda a la generalización del modelo supervisado, junto con una aceleración en la convergencia del modelo:
$$L_3(C) = L_2(C) + \lambda*L_1(C)$$En conclusión, los únicos hiperparámetros extra en el finetuning son los de $W_y$ y loss embeddings para delimitar los tokens en las respuestas.
Una forma más ilustrativa de ver la metodología es la siguiente:

Fuente: Improving Language Understanding by Generative Pre-Training
Mayores detalles de las estrategias supervisadas para las tareas evaluadas se encuentran en el paper.
Datasets¶
Este modelo fue entrenado utilizando el siguiente dataset:
- BookCorpus (7.000 libros únicos sin publicar de una amplia gama de géneros, incluyendo Aventura, Fantasía y Romance).
Especificaciones del Modelo¶
- 12 capas decodificadores de transformer.
- 12 cabezas de atención.
- 768 dimensiones del embedding.
- Estados internos de 3072 en las capas FFN.
- Optimizador Adam (max lr=2.5e-4).
- lr fue incrementada desde cero las primeras 2000 actualizaciones y puesta a cero utilizando un scheduker de coseno.
- Se entrenó 100 epochs con minibatches de 64, secuencias de 512 tokens.
- Tokenización BPE. con vocabulario de 40.000 mergimientos.
- Dropout de 0.1.
- Función de activatión GELU (Gaussian Linear Unit).
Para procesos de fine-tuning, se utilizan los mismos parámetros que el pre-training, excepto en la tasa de aprendizaje (lr=6.25e-5) con batches de 32, sólo por 3 epochs y $\lambda=0.5$.
Resultados¶



Análisis¶
A continuación, podemos ver el número de capas de transformer transferidas a las tareas supervisadas.
Como se puede observar, cada capa del transformer juega un papel fundamental para la tarea luego del pre-training.
Esto quiere decir que estas capas contienen funcionalidades importantes sobre cada una de las tareas evaluadas.

Y finalmente, podemos ver un estudio de ablación:

Modelo en Acción¶
from transformers import pipeline
# Generador de Texto
print('Cargando GPT...')
gpt = pipeline(task='text-generation',model='openai-gpt')
# Españolización Rápida
print('Cargando Traductor Inglés-Español...')
trad_en_es = pipeline(task='translation',model='Helsinki-NLP/opus-mt-en-es')
print('Cargando Traductor Español-Inglés...')
trad_es_en = pipeline(task='translation',model='Helsinki-NLP/opus-mt-es-en')
print('Listo!!!')
Cargando GPT...
Some weights of OpenAIGPTLMHeadModel were not initialized from the model checkpoint at openai-gpt and are newly initialized: ['lm_head.weight'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
Cargando Traductor Inglés-Español... Cargando Traductor Español-Inglés... Listo!!!
text=''
import random
while 1:
text = str(input())
if text=='[FIN]':
break
text_en = trad_es_en(text)[0]['translation_text']
#ran_gen_len = random.randint(1,512)
completion = gpt(text_en)[0]['generated_text']
complet_es = trad_en_es(completion)[0]['translation_text']
print(complet_es)
Holaa Hola. encontrarás a mi amiga ahí abajo con nosotros. ella está muy ocupada, y realmente no tengo el tiempo para encontrar a alguien, así que - ¿quieres reunirte con nosotros mientras conducimos? " " seguro, voy a recogerla. " " genial. vas a tener que aparcar a una cuadra de distancia porque todo el mundo ya está estacionando así - " se detuvo y se volvió hacia nosotros. " es esta una reunión de grupo? " " sí. " asintió en Lucas. " y vamos a mostrar a todos cómo lo hacemos. todo el mundo, este es Lucas, su jefe, y ese tipo grande de allí, ese tipo que vive en la casa con él. Estamos aprendiendo a hablar, Estamos aprendiendo a hablar, "la mujer dijo después de otro par de minutos. " ¿cómo se va a 'hablar?' hay un montón de palabras que no se nos permite utilizar, de todos modos. " "'usted está 'hablando' a algún tipo de máquina, " la corrijo, " así que todo lo que está recibiendo un poco es 'ir'no va '. " miró hacia atrás, no estaba seguro de si quería ser serio o no. finalmente, puso sus manos detrás de su espalda y dijo, " bueno, el problema es que no podemos hablar nosotros mismos. incluso con la ayuda de los'máquinas' somos capaces de tratar de hablarnos unos a otros. " no estaba seguro de que me gustara el sonido de eso. no me gustó el sonido de nada de eso tampoco. y definitivamente no estaba seguro de que la máquina estaba ayudando a nadie. quiero decir, ¿quién eran ellos de todos modos? [FIN]
Fine-Tuning¶
from transformers import AutoTokenizer, AutoModel
gpt_tok = AutoTokenizer.from_pretrained('openai-gpt')
gpt = AutoModel.from_pretrained('openai-gpt')
text = 'Hola, cómo estás'
tokens = gpt_tok(text, return_tensors='pt')
out = gpt(input_ids=tokens['input_ids'],return_dict=False)
print(tokens)
out[0].shape
### FINE-TUNING HERE ###
{'input_ids': tensor([[ 1329, 246, 240, 34998, 859, 557]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1]])}
torch.Size([1, 6, 768])
Reto: Hacer Fine-tuning utilizando alguna técnica vista a lo largo de las lecciones para alguna tarea descrita en el paper.
GPT-2¶
Luego del gran éxito de los modelos GPT y BERT, OpenAI no se cruzó de brazos y comenzó a entrenar el mismo modelo, pero con más parámetros y mayor número de capas de transformer.
En esta ocasión, el modelo tiene 1500 millones de parámetros.
Según Wikipedia,
"Si bien se sabe que el costo de la capacitación de GPT-2 fue de 256 dólares por hora, se desconoce la cantidad de horas que tomó completar la capacitación; por lo tanto, el costo general de la capacitación no se puede estimar con precisión. Sin embargo, los costos de los modelos comparables de lenguaje grande que utilizan arquitecturas de transformer se han documentado con más detalle; los procesos de capacitación para BERT y XLNet consumieron, respectivamente, 6.912 y 245.000 dólares de recursos."
Podemos ir a la página oficial de OpenAI para leer el artículo Better Language Models and Their Implications.
Cambio de Paradigma: Ask The Model¶
GPT-2 fue realmente una revolución en el mundo, y no sólo del Lenguaje Natural.
Como se promete en el paper,
"Las tareas de procesamiento del lenguaje natural, como la respuesta a preguntas, la traducción automática, la comprensión de lectura y los resúmenes, suelen ser abordadas con aprendizaje supervisado en conjuntos de datos específicos de tareas. Demostramos que los modelos de lenguaje comienzan a aprender estas tareas sin ninguna supervisión explícita cuando se entrenan en un nuevo conjunto de datos de millones de páginas web llamadas WebText."
WebText cuenta con aproximadamente 8 millones de texto, minados de Reddit, que no tienen problemas en la calidad de los datos, cómo sí lo tiene CommonCrawl.
En tamaño, es aproximadamente 40G de puro texto.
Para mayor detalle, podemos ir a Reddit Science para un ejemplo de filtrado natural y entender cómo obtuvieron semejante cantidad de texto curado.
A continuación, podemos observar una gráfica impactante:

A simple vista, parece un simple benchmark sobre una tarea de fine-tuning, pero en realidad, el modelo en sí está respondiendo a las tareas sin haber sido entrenado para tal tarea.
En el mundo de la inteligencia artificial, esto se conoce como Zero-Shot Learning, la capacidad de un modelo para desempeñarse en tareas para las que no fue entrenado explícitamente, dejando quizás en próxima deprecación al fine-tuning.
Este procedimiento se logra "hablando con el modelo", o simplemente colocando todos los requerimientos en forma textual y esperar a la completación de texto que indique la respuesta a la pregunta indicada por el ente interactuando.
Aunque en el paper se menciona que estos resultados no son del SOTA, es realmente sorprendente que siquiera funcione.
A continuación, podemos observar los detalles de la arquitectura:

Aunque en principio OpenAI escribió declaraciones sobre el potencial peligro de liberar su modelo más grande, el mercado los obligó a liberarlo, pues otras compañías ya lo habían hecho en el segundo semestre de 2019.
Modificaciones del Modelo¶
Las principales modificaciones respecto de su antecesor GPT, fueron las siguientes:
- La capa de normalización fue movida al principio de cada sub-bloque, similar a una pre-activation en una red residual.
- Una capa adicional de normalización fue puesta al final de cada bloque de atención.
- Se hicieron modificaciones sobre la inicialización de los pesos para contar con las nuevas capas introducidas.
- Se expandió el vocabulario a 50.257 tokens (usando tokenización BPE con modificaciones espaciales de mergimiento).
- Se amplió el tamaño del contexto de 512 a 1024.
- Se usaron batches de 512.
Una observación importante es que todos los modelos aún no se ajustan a WebText y la perplejidad retenida hasta ahora puede mejorar con más tiempo de entrenamiento.
Resultados Zero-Shot¶

Como ejemplo, expliquemos un poco el conjunto de datos LAMBADA:
LAMBADA evalúa las capacidades de los modelos computacionales para la comprensión de textos mediante una tarea de predicción de palabras.
LAMBADA es una colección de pasajes narrativos que comparten la característica de que los sujetos humanos pueden adivinar su última palabra si están expuestos al pasaje completo, pero no si solo ven la última oración que precede a la palabra objetivo.
Para tener éxito en LAMBADA, los modelos computacionales no pueden basarse simplemente en el contexto local, sino que deben poder realizar un seguimiento de la información en el discurso más amplio.
Winograd Schema Challenge¶
El desafío del esquema de Winograd (Levesque et al., 2012) fue construido para medir la capacidad de un sistema para realizar un razonamiento de sentido común midiendo su capacidad para resolver ambigüedades en el texto. GPT-2 mejora la precisión del SOTA en un 7 %, alcanzando un 70,70 %

Pregunta interesante: ¿Los modelos realmente están generalizando o simplemente memorizando?
Respuesta: Ir al paper, página 8.
Como conclusión, los autores escriben:
"Cuando un modelo de lenguaje grande se entrena en un conjunto de datos grande y diverso que puede funcionar bien en muchos dominios y conjuntos de datos.
En el desempeño de Zero-Shot, GPT-2 se desempeña bien en 7 de los 8 conjuntos de datos de modelado de lenguaje probados.
La diversidad de tareas que el modelo es capaz de realizar en una configuración de disparo cero sugiere que alta capacidad modelos entrenados para maximizar la probabilidad de un variado corpus de texto comienzan a aprender a realizar un sorprendente cantidad de tareas sin necesidad de supervisión explícita"
Modelo en Acción¶
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='gpt2')
set_seed(42)
generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
Downloading: 0%| | 0.00/665 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/523M [00:00<?, ?B/s]
Downloading: 0%| | 0.00/0.99M [00:00<?, ?B/s]
Downloading: 0%| | 0.00/446k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/1.29M [00:00<?, ?B/s]
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
[{'generated_text': "Hello, I'm a language model, I'm writing a new language for you. But first, I'd like to tell you about the language itself"},
{'generated_text': "Hello, I'm a language model, and I'm trying to be as expressive as possible. In order to be expressive, it is necessary to know"},
{'generated_text': "Hello, I'm a language model, so I don't get much of a license anymore, but I'm probably more familiar with other languages on that"},
{'generated_text': "Hello, I'm a language model, a functional model... It's not me, it's me!\n\nI won't bore you with how"},
{'generated_text': "Hello, I'm a language model, not an object model.\n\nIn a nutshell, I need to give language model a set of properties that"}]
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='gpt2-large')
set_seed(42)
generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
Downloading: 0%| | 0.00/665 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/523M [00:00<?, ?B/s]
Downloading: 0%| | 0.00/0.99M [00:00<?, ?B/s]
Downloading: 0%| | 0.00/446k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/1.29M [00:00<?, ?B/s]
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
[{'generated_text': "Hello, I'm a language model, I'm writing a new language for you. But first, I'd like to tell you about the language itself"},
{'generated_text': "Hello, I'm a language model, and I'm trying to be as expressive as possible. In order to be expressive, it is necessary to know"},
{'generated_text': "Hello, I'm a language model, so I don't get much of a license anymore, but I'm probably more familiar with other languages on that"},
{'generated_text': "Hello, I'm a language model, a functional model... It's not me, it's me!\n\nI won't bore you with how"},
{'generated_text': "Hello, I'm a language model, not an object model.\n\nIn a nutshell, I need to give language model a set of properties that"}]
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='DeepESP/gpt2-spanish')
set_seed(42)
generator("Hola, soy un modelo de lenguaje,", max_length=30, num_return_sequences=5)
Downloading: 0%| | 0.00/914 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/249M [00:00<?, ?B/s]
Downloading: 0%| | 0.00/115 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/821k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/487k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/262 [00:00<?, ?B/s]
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
[{'generated_text': 'Hola, soy un modelo de lenguaje, el que más me gusta es el de tu hermana. A lo mejor lo llamo Juanita, porque a ella'},
{'generated_text': 'Hola, soy un modelo de lenguaje, pero ya me conoces y sé lo que significa para mí que te quiero tener aquí conmigo. \n\n—Está'},
{'generated_text': 'Hola, soy un modelo de lenguaje, señor Gibson. ¿Por qué no me lo explicas? \n\n—Me gusta —dijo Mike en cambio'},
{'generated_text': 'Hola, soy un modelo de lenguaje, ¿entiendes? —dijo el doctor. \n\nEl doctor, que no entendía nada, siguió hablando.'},
{'generated_text': 'Hola, soy un modelo de lenguaje, me gusta tanto que he dicho que nunca usas esos adjetivos para decir palabras como yo en lugar de nombres'}]
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='gpt2-large')
set_seed(42)
generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
Downloading: 0%| | 0.00/1.29M [00:00<?, ?B/s]
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
[{'generated_text': "Hello, I'm a language model, I can do language modeling. In fact, this is one of the reasons I use languages. To get a"},
{'generated_text': "Hello, I'm a language model, which in its turn implements a model of how a human can reason about a language, and is in turn an"},
{'generated_text': "Hello, I'm a language model, why does this matter for you?\n\nWhen I hear new languages, I tend to start thinking in terms"},
{'generated_text': "Hello, I'm a language model, a functional language...\n\nI don't need to know anything else. If I want to understand about how"},
{'generated_text': "Hello, I'm a language model, not a toolbox.\n\nIn a nutshell, a language model is a set of attributes that define how"}]
from transformers import GPT2Tokenizer, GPT2Model
gpt2_tok = GPT2Tokenizer.from_pretrained('gpt2-large')
gpt2 = GPT2Model.from_pretrained('gpt2-large')
text = 'Hello, I am alive.'
tokens = gpt2_tok(text, return_tensors='pt')
out = gpt2(input_ids=tokens['input_ids'],return_dict=False)
print(tokens)
out[0].shape
### FINE-TUNING HERE ###
Downloading: 0%| | 0.00/0.99M [00:00<?, ?B/s]
Downloading: 0%| | 0.00/446k [00:00<?, ?B/s]
Downloading: 0%| | 0.00/666 [00:00<?, ?B/s]
Downloading: 0%| | 0.00/3.02G [00:00<?, ?B/s]
{'input_ids': tensor([[15496, 11, 314, 716, 6776, 13]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1]])}
torch.Size([1, 6, 1280])
Ejemplo de Generación de Blogs Artificiales¶
En Mac M1, este ejemplo tomó varios minutos para sus ejecución.
Utilícelo con cuidado.
from transformers import GPT2LMHeadModel, GPT2Tokenizer
tokenizer = GPT2Tokenizer.from_pretrained("gpt2-large")
model = GPT2LMHeadModel.from_pretrained("gpt2-large", pad_token_id=tokenizer.eos_token_id)
topic = 'Benefits of Sleeping Early'
input_ids = tokenizer.encode(topic, return_tensors='pt')
# Generate Blog
#max_lenth-Number of Words in the Article
#num_beams-Number of different combination of words that can be chained together
#no_repeat_ngram_size-No of words that be combined together and repeated, example: ['benefits of sleeping' can be repeated 2 times but not more ]
output = model.generate(input_ids, max_length=200, num_beams=30, no_repeat_ngram_size=4, early_stopping=True)
article_en = tokenizer.decode(output[0], skip_special_tokens=True)
print(article_en)
Benefits of Sleeping Early in the Morning Sleeping early in the morning is one of the most important things you can do to improve your health and well-being. Here are some of the benefits of getting up earlier in the morning: Improves Sleep Quality A study published in the Journal of the American Medical Association (JAMA) found that people who get an early start in the morning are more likely to get a good night's sleep than those who get up later in the morning. According to the study, people who get up at 6:30 a.m. are less likely to wake up in the middle of the night than those who don't get up at all. People who get up early are also less likely to suffer from sleep apnea, a sleep disorder that makes it difficult for people to fall asleep. Reduces the Risk of Heart Disease One of the most common causes of death in the United States is
Fine-Tuning¶
Para los interesados en Fine-Tuning GPT-2 para diversas tareas del NLU, recomendamos el siguiente enlace:
Megatron y Turing-NLG¶
Siguiendo la escala de "entre más grande, mejor", los modelos posteriores que siguieron a GPT-2 fueron
- Megatron, con 8.300 millones de parámetros
- Turing-NLG, con 17.000 millones de parámetros.
Algunos de estos modelos han sido liberados, pero para los demás, hay alguna forma de pago.
Para mayor detalle, puede ir a Generate Chatbot training data with QBox — powered by Microsoft Turing NLG o Megatron HF 345m.
Cada uno de estos modelos, ha demostrado mejorar las métricas del Zero-Shot en varios conjuntos de datos y tareas de NLU distintas.
GPT-3¶
Finalmente, la gran revolución reciente en ésta area, fue el modelo entrenado por el equipo de OpenAI, la tercera versión de la familia GPT y que ha sido de gran impacto a nivel mundial.
Actualmente no es posible acceder al modelo y utlizarlo de manera libre, sino por medio de la API de OpenAI a la cual uno debe registrarse y cuenta con 18 dólares gratuitos para hacer pruebas.
El paper de GPT-3 es bastante extenso (40 páginas, ignorando los apéndices), por lo que es buena idea ver el excelente siguiente video de Yannic Kilcher:
Si no tiene acceso aún, le recomendamos aplicar y probar las posibilidades.
A modo de información, colocamos algunas tablas de los resultados del paper:





Como Bonus, mostraremos ejemplos a través de la API, a la cual hemos tenido reciente acceso.
OPT¶
Debido a la restricción de GPT-3 para usuarios comunes, Facebook (Ahora Meta) liberó un equivalente a GPT-3 hace algunos días.
El paper se llama OPT: Open Pre-trained Transformer Language Models y es un intento por la democratización de los modelos del estado del arte para toda la población (¿O qué opinan ustedes?).
Según Meta, este modelo es comparable con GPT-3, a un costo de huella de carbón de 1/7 de la parte usada por GPT-3.
Esto es un paso hacia la IA preocupada por el medio ambiente.
Algo interesante de rescatar del paper (No es difícil de leer), es la comparación de toxicidad entre modelos:

Para los interesados, pueden ir al GitHub de OPT, bajarse los pesos de los modelos y requerir acceso al modelo completo a través de un formulario.
En el paper prometer acceso a la comunidad científica.
BlenderBot¶
Tener un modelo de lenguaje natural con resultados sorprendentes en el GLUE/SUPERGLUE u otros, no garantiza tener un chat-bot a la medida.
Hay otras habilidades que deben explotarse: Por ejemplo, una buena conversación requiere una serie de habilidades que un conversador experto combina a la perfección: proporcionar puntos de conversación atractivos y escuchar a sus interlocutores, y mostrar conocimiento, empatía y personalidad de manera adecuada, manteniendo una personalidad coherente.
Meta (Facebook en su tiempo), creó un modelo de varios tamaños (90M, 2.7B y 9.4B) que apunta a las recetas fundamentales de crear un chatbot eficiente.
Su nombre es BlenderBot.
Según el paper, un buen chatbot debe tener
- Habilidades de combinación (Blending Skills):
Se pueden realizar grandes mejoras ajustando los datos que enfatizan las habilidades de conversación deseables.
Se seleccionan tareas que hacen que el modelo se centre en la personalidad y el compromiso, el conocimiento y la empatía, logrando grandes ganancias mediante el uso de la recientemente introducida Configuración de Blended Skill Talk (BST), que se enfoca en esos aspectos al proporcionar datos de capacitación y conversaciones iniciales contexto (personajes y temas).
Mientras que BST enfatiza características deseables, también mostramos esta afinación puede minimizar los rasgos indeseables aprendidos de grandes corpus, como la toxicidad.
- Estrategias de Generación:
La elección del algoritmo de decodificación es de vital importancia, y dos modelos con la misma perplejidad, pero diferentes algoritmos de decodificación puede dar resultados muy diferentes.
En particular se puede mostrar que la longitud de las declaraciones del bot son cruciales para los juicios humanos de calidad – demasiado cortas y las respuestas se consideran aburridas o mostrando una falta de interés, demasiado tiempo y el bot parece vacilar y no escuchar.
Para la arquitectura, este modelo es un tipo seq2seq, que utiliza la misma arquitectura del transformer con un poly-encoder.
La tokenización usada es la BPE.
La arquitectura del modelo se describe a continuación:
"Nuestro modelo de parámetros 9.4B tiene un codificador de 4 capas, un decodificador de 32 capas con 4096 incrustaciones dimensionales y 32 cabezas de atención. Nuestro modelo de parámetros 2.7B imita aproximadamente las elecciones arquitectónicas de Adiwardana et al. (2020), con 2 capas de codificador, 24 capas de decodificador, 2560 incrustaciones dimensionales y 32 cabezas de atención."
BlenderBot2¶
BlenderBot2 es una modificación de BlenderBot que, entre otras, tiene acceso a internet para no incurrir en el fenómeno que sufren muchos modelos, conocido como alucinar conocimiento.
PaLM¶
Respecto a modelos grandes, HuggingFace tiene algo que decir en Large Language Models: A New Moore's Law?.
Quizás el modelo más grande hasta el momento, se llama PaLM y fue creado por Google hace menos de un mes.
El modelo tiene 540 mil millones de parámetros (540 billones en inglés).
Podemos acceder a:
- Paper: PaLM: Scaling Language Modeling with Pathways
- Ejemplo demostrativo: [
Integrated AI - PaLM by Google Research (Apr/2022) - Explaining jokes + Inference chaining (540B)](https://www.youtube.com/watch?v=kea2ATUEHH8)
- GitHub educativo de lucidrains: PaLM - Pytorch