Aprendizaje Profundo ¶
Diplomado en Ciencia de Datos ¶
Introducción a convoluciones ¶

Fuente: Cecbur, CC BY-SA 4.0, via Wikimedia Commons
Profesores¶
- Alvaro Montenegro, PhD, ammontenegrod@unal.edu.co
- Campo Elías Pardo, PhD, cepardot@unal.edu.co
- Daniel Montenegro, Msc, dextronomo@gmail.com
- Camilo José Torres Jiménez, Msc, cjtorresj@unal.edu.co
Estudiantes auxiliares¶
- Jessica López, jelopezme@unal.edu.co
- Camilo Chitivo, cchitivo@unal.edu.co
- Daniel Rojas, anrojasor@unal.edu.co
Asesora Medios y Marketing digital¶
- Maria del Pilar Montenegro, pmontenegro88@gmail.com
- Jessica López Mejía, jelopezme@unal.edu.co
Jefe Jurídica¶
- Paula Andrea Guzmán, guzmancruz.paula@gmail.com
Coordinador Jurídico¶
- David Fuentes, fuentesd065@gmail.com
Desarrolladores Principales¶
- Dairo Moreno, damoralesj@unal.edu.co
- Joan Castro, jocastroc@unal.edu.co
- Bryan Riveros, briveros@unal.edu.co
- Rosmer Vargas, rovargasc@unal.edu.co
- Venus Puertas, vpuertasg@unal.edu.co
Expertos en Bases de Datos¶
- Giovvani Barrera, udgiovanni@gmail.com
- Camilo Chitivo, cchitivo@unal.edu.co
Referencias¶
- Ian Goodfellow, Yosua Bengio and Aaron Courville, Deep Learning, MIT press, 2016.
- Vincent Doumolin and Francesco Vision, A guide to convolution arithmetic for deep learning, ArXiv:1603.07285v2, 2018
- Applied Deep Learning - Part 4: Convolutional Neural Networks
- Gentle Dive into Math Behind Convolutional Neural Networks
- [Deep Learning for Computer Vision
Stanford - Spring 2022](https://cs231n.github.io/convolutional-networks/)
- Alvaro Montenegro y Daniel Montenegro, Inteligencia Artificial y Aprendizaje Profundo, 2022
- Alvaro Montenegro, Daniel Montenegro Campo Elías Pardo, y Oleg Jarma, Inteligencia Artificial y Aprendizaje Profundo Avanzado, 2022
- Alvaro Montenegro, Daniel Montenegro, Campo Elías Pardo y Oleg Jarma, Ciencia de datos, 2022
Contenido¶
Introducción ¶
Las redes neuronales convolucionales (RNC) son un tipo especializado de red neuronal para procesar datos que tiene una topología conocida similar a una cuadrícula.
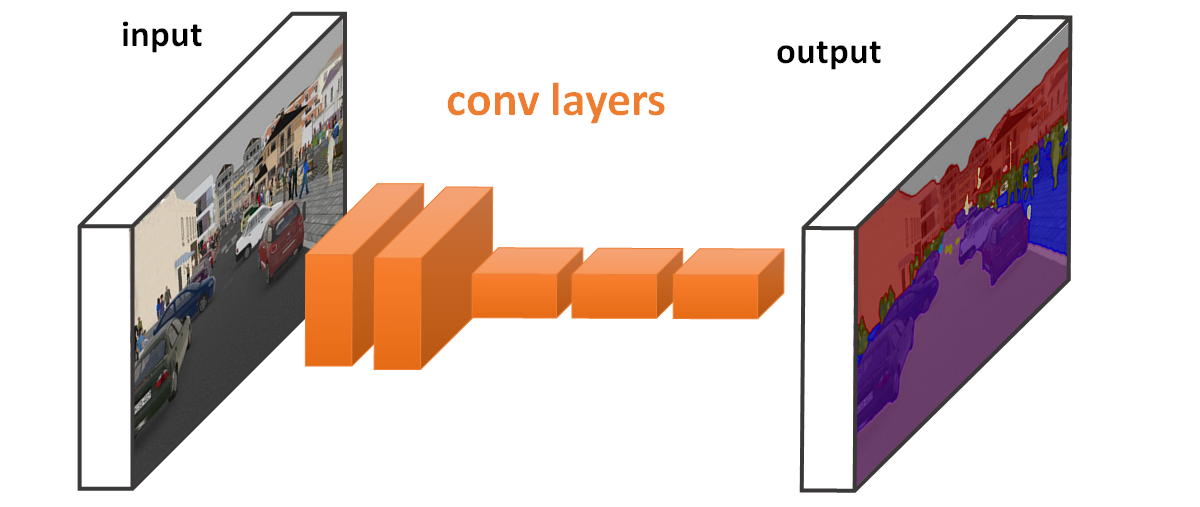
Fuente: Efficient method for running Fully Convolutional Networks (FCNs)
Los ejemplos incluyen datos de series temporales, que pueden puede considerarse como una cuadrícula 1D que toma muestras a intervalos de tiempo regulares o datos de imagen, que puede considerarse como una cuadrícula de píxeles en 2D.

El nombre "red neuronal convolucional" indica que la red emplea una operación matemática llamada convolución. La convolución es un tipo especializado de operación lineal. Las redes convolucionales son simplemente redes neuronales que utilizan convolución en lugar de una matriz general en al menos una de sus capas.
¿Qué es una Convolución? ¶

Fuente Nasa
Vamos a usar un ejemplo hipotético para introducir el concepto matemático de convolución. Supongamos que estamos rastreando la ubicación de una nave espacial con un sensor láser. Nuestro sensor láser proporciona una salida única x(t), la posición de la nave espacial en el momento t. Tanto x como t tienen un valor real, es decir, podemos obtener una lectura diferente del láser sensor en cualquier instante en el tiempo.
Ahora suponga que nuestro sensor láser es algo ruidoso. Para obtener una estimación menos ruidosa de la posición de la nave espacial, una buena idea es promediar varias mediciones. Por supuesto, las mediciones más recientes son más relevantes, por lo que lo haremos un promedio ponderado que otorgue más peso a las mediciones recientes.
Podemos construir tal promedio ponderado con una función de ponderación w(a), donde a es la edad de una medición. Si aplicamos una operación promedio ponderada en cada momento, obtenemos una nueva función que proporciona una estimación suavizada de la posición s de la nave espacial:
s(t)=∫x(a)w(t−a)daObserve que si a1.…,an es una muestra de la distribución cuya función de densidad es w, entonces se tiene que
s(t)≈1nn∑i=1x(ai)w(t−ai)Esta operación se llama convolución. La operación de convolución es típicamente denotada con un asterisco:
s(t)=(x∗w)(t)En el ejemplo, w debe ser una función de densidad de probabilidad válida, o el el resultado no es un promedio ponderado. Veamos un pequeño ejemplo en acción:

Fuente: Boxcar smoothing with AstroPy
Sin embargo, podemos hacer convoluciones con funciones más generales. La fórmula matemática de la convolución de dos funciones es
(f∗h)(t)=∫∞−∞f(τ)h(t−τ)dτY se puede usar para, por ejemplo, suavizar bordes de diferentes señales, como vemos a continuación:

A pesar de esto, mantendremos nuestra notación anterior para indicar lo siguiente:
Terminología:
- x es la entrada input.
- w es el kernel de la convolución.
- s, la salida, es el feature map.
Por otro lado, es claro que en la vida real no contamos con almacenamiento de información continua, por lo que el concepto de convolución debe usarse de manera discreta (o por medio de muestreos continuos de la señal que está siendo medida):
s(t)=(x∗w)(t)≈∞∑a=−∞x(a)w(t−a)Uso en Procesamiento de Imágenes ¶
Las convoluciones son muy útiles en la ciencia y la ingeniería y se pueden consultar aqui algunas de ellas. En las próximas sesiones, nos enfocaremos en su uso para crear redes neuronales convolucionales tanto en clasificación como en predicción. Tal vez, una de las aplicaciones más usadas en el Aprendizaje de Máquina, es su uso sobre imágenes y en series de tiempo.
Sí, es posible extender el concepto de convolución a objetos en dos o más dimensiones, como es el caso de una fotografía a color o videos.
Si pensáramos en el mismo proceso anterior pero en 2D, podríamos obtener una fórmula como la siguiente: S(i,j)=(I∗K)(i,j)=∑m∑nI(m,n)K(i−m,j−n).
Conmutatividad:
La convolución es conmutativa. Podemos escribir
S(i,j)=(K∗I)(i,j)=∑m∑nI(i−m,j−n)K(m,n).Esta propiedad es conveniente para el estudio matemático de convoluciones.
Correlación Cruzada:
Por otro lado, muchas bibliotecas de redes neuronales implementan un función relacionada llamada correlación cruzada, que es lo mismo que convolución pero sin voltear el kernel:
S(i,j)=(I∗K)(i,j)=∑m∑nI(i+m,j+n)K(m,n).Muchas bibliotecas de aprendizaje automático implementan correlación cruzada pero la llaman convolución. Haremos lo mismo.
Ejemplo:
Recordemos que una imagen es un tensor, el cual en algunos casos se puede visualizar por completo:

De la fórmula a la práctica, la convolución de un kernel específico se vería así:

Fuente: Gentle Dive into Math Behind Convolutional Neural Networks
Ejemplos Reales clásicos¶
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
from scipy.signal import convolve2d
castillo=Image.open("../Imagenes/castle.jpeg")
castillo_gris=castillo.convert('L')
data_castillo=np.array(castillo_gris)
scharr = np.array([[ -3-3j, 0-10j, +3 -3j],
[-10+0j, 0+ 0j, +10 +0j],
[ -3+3j, 0+10j, +3 +3j]])
kernel=np.array([[1,2,1],
[0,0,0],
[-1,-2,-1]])
kernel2=np.array([[1,0,-1],
[1,0,-1],
[1,0,-1]])
c1 = convolve2d(data_castillo, scharr, boundary='symm', mode='same')
c2 = convolve2d(data_castillo, kernel, boundary='symm', mode='same')
c3 = convolve2d(data_castillo, kernel2, boundary='symm', mode='same')
plt.figure(figsize=(25,15))
plt.title('Imagen Original',fontsize=15)
plt.imshow(castillo,cmap='gray')
plt.axis('off')
plt.show()

plt.figure(figsize=(25,15))
#plt.suptitle('Ejemplo de Convolución',fontsize=15)
plt.subplot(221)
plt.title('Imagen Original',fontsize=15)
plt.imshow(castillo_gris,cmap='gray')
plt.axis('off')
plt.subplot(222)
plt.title('Imagen Convolucionada con Scharr',fontsize=15)
plt.imshow(np.absolute(c1), cmap='gray')
plt.axis('off')
plt.subplot(223)
plt.title('Imagen Convolucionada con Kernel',fontsize=15)
plt.imshow(np.absolute(c2), cmap='gray')
plt.axis('off')
plt.subplot(224)
plt.title('Imagen Convolucionada con Kernel 2',fontsize=15)
plt.imshow(np.absolute(c3), cmap='gray')
plt.axis('off')
plt.show()

Redes Neuronales Convolucionales¶
¿Cómo se aplican entonces las convoluciones en una red neuronal? observemos la estructura de una CNN
Capa Convolucional¶
Recordemos un poco cómo funcionan los perceptrones

Fuente: Fouzia Altaf, researchgate.net
Entran datos, se hace la suma de pesos y se aplica la función de activación. Lo que hace la red en cada entrenamiento es encontrar los pesos adecuados para obtener la mejor información posible.
Es posible aplicar esta misma idea al hacer una convolución

Fuente: Fouzia Altaf, researchgate.net
Convoluciones en detalle¶
Caso simple: kernels¶
La imagen muestra los objetos básicos que intervienen en una convolución:
- la imagen,
- el kernel.

Fuente: aprendemachinelearning.com
El gif muestra la forma como se calcula la convolución paso a paso. A la derecha se observa la imagen resultante de la convolución. Por ejemplo el elemento en posición (0,0) se obtiene mediante el siguiente cálculo
- 0∗1+0∗0+0∗(−1)+0∗2+0∗0+0.6∗(−2)+0∗1+0.6∗0+0∗(1−)=−1.2

Fuente: aprendemachinelearning.com
Al final de la lección veremos cómo expresar el cálculo completo como un producto matricial, con lo que se tiene un módulo neuronal clásico si se suma el sesgo (bias) y se aplica la función de activación. La siguiente imagen muestra el proceso completo usando la activación ReLU.

Fuente: aprendemachinelearning.com
Caso con varios canales: Filtros¶
¿Qué hacemos cuando tenemos una imagen a color?
Como hemos visto hasta ahora, los kernels 2D se aplican a imágenes 2D, que por convención, están representadas por tensores bidimensionales de un canal de color. Pero ¿Qué ocurre si el tensor de entrada es 3D?. Es decir, tenemos imágenes 2D con tres canales de color. Este es el caso de por ejemplo, si el tensor de entrada representa a una imagen en formato RGB.
El problema puede plantarse de manera más general en realidad. Supongamos que tenemos tensores de entrada 3D, en donde la tercera dimensión representan diferentes canales, digamos 256 canales.
El truco que usaremos se llama filtro. Lo que vamos a hacer es usar un kernel 2D por cada canal. Entonces, si se tienen 3 canales, usaremos 3 kernels 2D, uno por cada canal. Si tenemos 256 canales, usaremos 256 kernels 2D. Supongamos que en general tenemos d canales. El conjunto de los d kernels 2D que se aplicaran al tensor de tamaño h∗k∗d se denomina un filtro 2D. Revise detenidamente la siguiente imagen.

Fuente: Alvaro Montenegro
Como puede darse cuenta, sucede los siguiente:
- El tensor de entrada es de tamaño 4x4x3, el cual se puede interpretar como una imagen de tamaño 4x4 a color, con 3 canales de color.
- EL filtro tiene tamaño 2x2x3, que corresponde a 3 kernels de tamaño 2x2.
- Cada kernel se aplica a un canal diferente. Por ejemplo el kernel 1 se aplica al canal 1, haciendo la respectiva convolución. Esta convolución da origen a un mapa de características (features) de tamaño 3x3. Entonces le filtro completo produce un tensor de tamaño 3x3x3, que corresponde a tres mapas de características, cada una de de tamaño 3x3 .
- Finalmente, los mapas de características se suman componente a componente dando origen al resultado definitivo de la convolución que es un tensor de tamaño 3x3x1.
Múltiples filtros ¶
Ahora vemos la acción de varios filtros sobre la misma imagen. El tensor original tiene tamaño 663 y cada filtro es un tensor de tamaño 3x3x3. En consecuencia Cada filtro da origen a un canal de tamaño 441, se explicó arriba.
Observe que como son tres filtros, y como cada filtro da origen a un cana, la aplicación de los tres filtros da como resultado un tensor de tamaño 4x4x3, es decir imágenes de tamaño 4x4 y tres canales.
Como puede imaginar, a la salida de una capa convolucional 2D, se tienen imágenes en varios canales. Por lo que es posible ver tales imágenes por cada canal. Haremos esto en la próxima lección.

En este caso, el resultado final de la convolución se conoce como filtro. Note que en realidad se hicieron tres convoluciones.
Note que a pesar de ser una operación entre tensores de dimensión 3, el resultado es un tensor de dimensión 2.
La fórmula que explica las dimensiones de salida es:
[n,n,nc]∗[f,f,nc]=[floor(n+2p−fs+1),floor(n+2p−fs+1),nf]Importante recordar que cada kernel usado resultará en un filtro diferente y disyunto:

Fuente: Applied Deep Learning - Part 4: Convolutional Neural Networks
Relleno (Padding)¶
Al hacer nuestro proceso de convolución, se generan cierta pérdida de información debida a las esquinas de la imagen. De hecho, la imagen convolucionada sufre un cambio de dimensión a la baja.
Por lo tanto, la posición de un pixel en la imagen juega un papel fundamental, como se ilustra a continuación:

Para arreglar dicho problema, podemos por ejemplo, agregar una frontera extra de ceros al borde la imagen.
Dicho proceso es conocido como relleno de ceros o zero-padding.

En el lenguaje de convoluciones, usualmente se usan dos modos:
- Valid: Regresa la imagen con el kernel convolucionado sin cambios (reduce dimensión de salida).
- Same: Regresa la imagen con el mismo tamaño que la imagen original.
En el caso de hacer padding y usar same, el padding debe cumplir la siguiente ecuación:
p=f−12donde p es el tamaño de relleno (padding) y f es la dimensión del kernel.
Saltos (Strides) ¶
En algunos casos, no queremos tantos detalles sobre la convolución (por ejemplo, si no hay tantos detalles de pixel en pixel). Por ejemplo en imágenes en donde los colores van cambiando muy poco de pixel a pixel. En estos casos, es grato que podemos tener en nuestras redes convolucionadas el parámetro de salto ó stride:

Fuente: Gentle Dive into Math Behind Convolutional Neural Networks
En este caso, la fórmula asociada a la dimensión de salida es:
nout=floor(nin+2p−fs+1),
en donde s es el tamaño del salto(stride).
Submuestreo. Agrupamiento (Pooling) ¶
Además de las capas convolucionadas, muchas veces es usada la operación llamada pooling para reducir el tamaño del tensor y volver más rápido el procesamiento.
Además, esto reduce el número de parámetros y un número menor de parámetros evita el sobre ajuste.
Estas capas son bastante sencillas. Una vez definidos los hiperparámetros de salto y tamaño de kernel, tenemos fundamentalmente dos tipos de pooling:
- Max Pooling: Divide la imagen en diferentes regiones y toma el valor máximo de dicha región.


- Average Pooling: Divide la imagen en diferentes regiones y toma el valor promedio de dicha región.

Fuente: Average-Pooling
Reducción en el número de parámetros¶
Como se podrán haber dado cuenta, una red densamente conectada (DNN) no son la mejor opción al momento de trabajar con imágenes, dada la cantidad tan enorme de parámetros que deben ser aprendidos.
Para entender el verdadero poder de las convoluciones, note la siguiente imagen:

Fuente: Gentle Dive into Math Behind Convolutional Neural Networks
Vemos claramente que !no todas las neuronas están conectadas entre sí!
Además, que algunas neuronas comparten los mismos pesos.
Esto significa que una red neuronal convolucionada tiene muchos menos parámetros para aprender.
Arquitectura de las redes neuronale convolucionales ¶
La siguiente imagen ilustra una arquitectura convolucinal muy general.

Fuente: aprendemachinelearning.com
Aquí encontramos la arquitectura de red convolucional clásica. Observe como cada mapa de features es mas pequeño que en la capa anterior, pero a su vez hay precencia de más filtros. No se muesyran, pero a la salida de cada capa convolucional siempre hay una activación presente.

Finalmente vemos la arquitectura de una red convolucional profunda.
En efecto, es una de las arquitecturas más famosas de la historia de la redes convolucionales, conocida como VGG

{kind=link}
{kind=link}
Convoluciones 1D y 3D¶
En esta lección hemos estudiado convoluciones 2D. Partimos de la hipótesis que tenemos imágenes de tamaño h×k en d canales. En términos tensoriales tenemos a la entrada tensores de tamaño h×k×d. Al aplicar convoluciones 2D a estos objetos, la tercera dimensión se interpreta como un canal. Entonces usamos m filtros de tamaño k1×k2×d dando origen a tensores de tamaño h′×k′×m. Es decir el resultado global de la convolución 2D es un tensor de dimensión 3.
Convoluciones 1D¶
Ahora solamente tiene un sentido claro, aplicar kernels de tamaño k1×1 y en consecuencia filtros de tamaño k1×k2,m. La siguiente imagen ilustra la situación con un único filtro m=1.
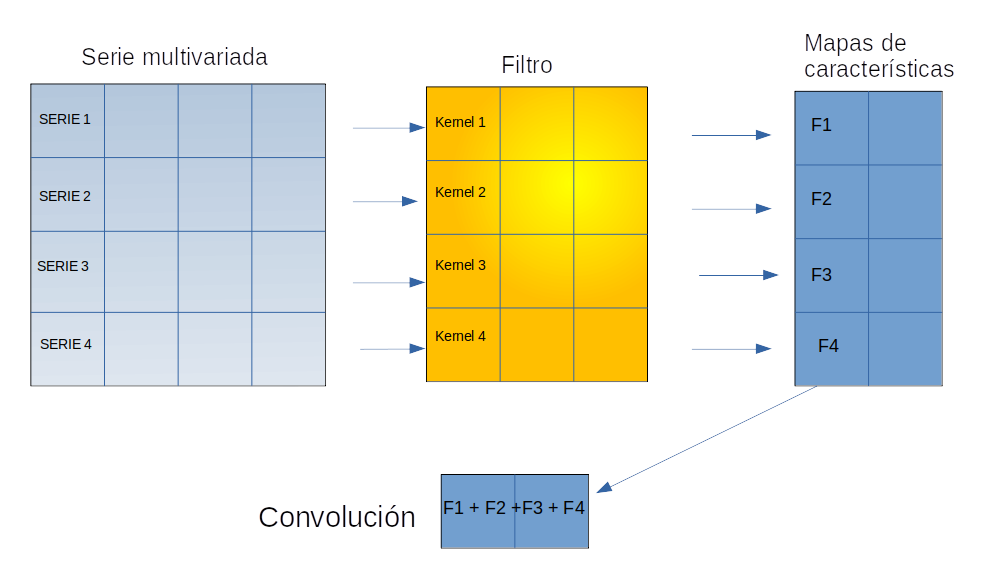
Fuente: Alvaro Montenegro
Ejercicio¶
- Describa como puede combinar las convoluciones 1D con LSTM o GRU.
- ¿ Se requiere la ventana deslizante en este caso?
- ¿Cual es la dimensión del tensor de salida en una convolución 1D?
Convoluciones 3D¶
Finalmente llegamos al caso más complejo. El caso de las convoluciones 3D. Nuestro problema básico es que ahora no es posible representar fácilmente el resultado de la convolución 3D, debido a que es un tensor de dimensión 4.
En las convoluciones 3D, suponemos que se tienen tensores de entrada de tamaño h×k×l×t. La última dimensión corresponde a los canales. En el caso de los videos, cana canal corresponde a un frame del video. Por lo tanto, si el video consta de 10000 frames, se tienen 10000 canales.
Los kernels en esta caso son tridimensionales de tamaño k1×k2×k3 y los filtros son de tamaño k1×k2×k3×m. La imagen ilustra un kernel 3D.

Fuente: towardsdatascience.com
Ejercicio¶
Suponga que se tiene un video de tamaño 1000 frames, cada uno con imágenes de tamaño 512 x 512 en RGB. Ahora suponga que aplica 100 filtros de tamaño 5x5x5.
- ¿Cuál es el tamaño del tensor de entrada y del tensor de salida?
- ¿Cómo interpretar cada canal de salida?
- ¿Si se intentara visualizar un canal de salida como lo haría?
Representación matricial de las convoluciones¶
Por facilidad supongamos que se tiene una imagen de tamaño 4×4 y un kernel de tamaño 3×3, el cual se usuara para hacer una convolución a la imagen, sin padding y strides =1. La imagen resultate tien tamaño 2×2. ¿Por qué?
La imagen ilustra la situación

Fuente: ai.stackexchange.com
El kernel es representado por la matriz
W=(w00w01w02w10w11w12w20w21w22,)y la imagen puede ser vista como
I=(i00i01i02i03i10i11i12i13i20i21i22i23i30i31i32i33)Si reescribimos el kernel de la siguiente forma
W′=(w00w01w020w10w11w120w20w21w22000000w00w01w020w10w11w120w20w21w2200000000w00w01w020w10w11w120w20w21w22000000w00w01w020w10w11w120w20w21w22)y la imagen como I′=(i00i01i02i03i10i11i12i13i20i21i22i23i30i31i32i33)
El resultado de la convolución es
C=W′×I′en donde
C=(c00c01c10c11),la cual por supuesto se puede reescribir como
C=(c00c01c10c11).En consecuencia, la convolución es realmente un módulo neuronal de tipo perceptron con con una configuración de pesos especial.
Promedios móviles y submuestreo¶
Como ejercicio final, le invitamos a pensar en las siguientes dos afirmaciones:
- Las convoluciones representan promedios móviles uni, bi o tridimensionales, segun el caso.
- El pooling es una forma de submuestreo de la imagen. De cada región en la cual se divide la imagen para hacer el pooling, se toma un resumen. Este proceso que puede interpretarse como un submuestro de la imagen.
- Un promedio móvil crea un efecto de suavizado y reduce el ruido de las fluctuaciones de los objetos.
- El pooling permite mantener elementos escenciales de los objetos descartando informacion redundante.