Use Case: Unmatched Instances Input¶
Install Dependencies¶
In [1]:
!pip install -U panoptica > /dev/null #installs numpy and others
!pip install -U auxiliary > /dev/null
Setup Imports¶
In [2]:
import numpy as np
from auxiliary.nifti.io import read_nifti
from rich import print as pprint
from panoptica import NaiveThresholdMatching, Panoptic_Evaluator, UnmatchedInstancePair
Load Example Data¶
To demonstrate we use a reference and predicition of spine a segmentation with unmatched instances.
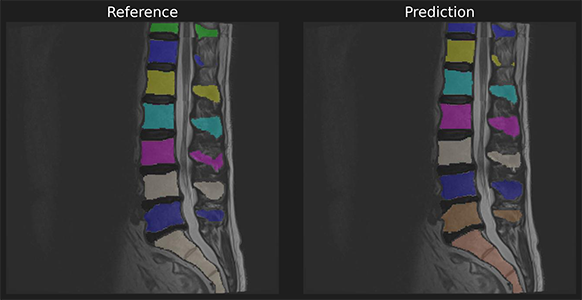
In [3]:
ref_masks = read_nifti("./spine_seg/unmatched_instance/ref.nii.gz")
pred_masks = read_nifti("./spine_seg/unmatched_instance/pred.nii.gz")
# labels are unmatching
np.unique(ref_masks), np.unique(pred_masks)
Out[3]:
(array([ 0, 2, 3, 4, 5, 6, 7, 8, 26, 102, 103, 104, 105,
106, 107, 108, 202, 203, 204, 205, 206, 207, 208], dtype=uint8),
array([ 0, 3, 4, 5, 6, 7, 8, 9, 27, 103, 104, 105, 106,
107, 108, 109, 203, 204, 205, 206, 207, 208, 209], dtype=uint8))
To use your own data please replace the example data with your own data.
In ordner to successfully load your data please use NIFTI files and the following file designation within the folder "unmatched_instance":
panoptica/spine_seg/unmatched_instance/
- Reference data ("ref.nii.gz")
- Prediction data ("pred.nii.gz")
Run Evaluation¶
In [4]:
sample = UnmatchedInstancePair(pred_masks, ref_masks)
evaluator = Panoptic_Evaluator(
expected_input=UnmatchedInstancePair,
instance_matcher=NaiveThresholdMatching(),
)
result, debug_data = evaluator.evaluate(sample)
────────────────────────────────────────── Thank you for using panoptica ──────────────────────────────────────────
Please support our development by citing
https://github.com/BrainLesion/panoptica#citation -- Thank you!
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Panoptic: Start Evaluation -- Got UnmatchedInstancePair, will match instances -- Got MatchedInstancePair, will evaluate instances -- evaluate took 3.694295644760132 seconds to execute.
Inspect Results¶
The results object allows access to individual metrics and provides helper methods for further processing
In [5]:
# print all results
print(result)
+++ MATCHING +++ Number of instances in reference (num_ref_instances): 22 Number of instances in prediction (num_pred_instances): 22 True Positives (tp): 19 False Positives (fp): 3 False Negatives (fn): 3 Recognition Quality / F1-Score (rq): 0.8636363636363636 +++ GLOBAL +++ Global Binary Dice (global_bin_dsc): 0.9744370224078394 Global Binary Centerline Dice (global_bin_cldsc): 0.9637064011802574 +++ INSTANCE +++ Segmentation Quality IoU (sq): 0.8328184295330796 +- 0.15186064004517466 Panoptic Quality IoU (pq): 0.719252280051296 Segmentation Quality Dsc (sq_dsc): 0.900292616009954 +- 0.10253566174957332 Panoptic Quality Dsc (pq_dsc): 0.7775254410995057 Segmentation Quality Assd (sq_assd): 0.250331887879225 +- 0.07696680402317076
In [6]:
# get specific metric, e.g. pq
pprint(f"{result.pq=}")
result.pq=0.719252280051296
In [7]:
# get dict for further processing, e.g. for pandas
pprint("results dict: ", result.to_dict())
results dict: { 'num_ref_instances': 22, 'num_pred_instances': 22, 'tp': 19, 'fp': 3, 'fn': 3, 'rq': 0.8636363636363636, 'global_bin_dsc': 0.9744370224078394, 'global_bin_cldsc': 0.9637064011802574, 'sq': 0.8328184295330796, 'sq_std': 0.15186064004517466, 'pq': 0.719252280051296, 'sq_dsc': 0.900292616009954, 'sq_dsc_std': 0.10253566174957332, 'pq_dsc': 0.7775254410995057, 'sq_assd': 0.250331887879225, 'sq_assd_std': 0.07696680402317076 }