Use Case: Matched Instances Input¶
Install Dependencies¶
!pip install panoptica auxiliary rich numpy > /dev/null
If you installed the packages and requirements on your own machine, you can skip this section and start from the import section.
Setup Colab environment (optional)¶
Otherwise you can follow and execute the tutorial on your browser. In order to start working on the notebook, click on the following button, this will open this page in the Colab environment and you will be able to execute the code on your own (Google account required).
Now that you are visualizing the notebook in Colab, run the next cell to install the packages we will use. There are few things you should follow in order to properly set the notebook up:
- Warning: This notebook was not authored by Google. Click on 'Run anyway'.
- When the installation commands are done, there might be "Restart runtime" button at the end of the output. Please, click it.
If you run the next cell in a Google Colab environment, it will clone the 'tutorials' repository in your google drive. This will create a new folder called "tutorials" in your Google Drive. All generated file will be created/uploaded to your Google Drive respectively.
After the first execution of the next cell, you might receive some warnings and notifications, please follow these instructions:
- 'Permit this notebook to access your Google Drive files?' Click on 'Yes', and select your account.
- Google Drive for desktop wants to access your Google Account. Click on 'Allow'.
Afterwards the "tutorials" folder has been created. You can navigate it through the lefthand panel in Colab. You might also have received an email that informs you about the access on your Google Drive.
import sys
# Check if we are in google colab currently
try:
import google.colab
colabFlag = True
except ImportError as r:
colabFlag = False
# Execute certain steps only if we are in a colab environment
if colabFlag:
# Create a folder in your Google Drive
from google.colab import drive
drive.mount("/content/drive")
# clone repository and set path
!git clone https://github.com/BrainLesion/tutorials.git /content/drive/MyDrive/tutorials
BASE_PATH = "/content/drive/MyDrive/tutorials/panoptica"
sys.path.insert(0, BASE_PATH)
else: # normal jupyter notebook environment
BASE_PATH = "." # current working directory would be BraTs-Toolkit anyways if you are not in colab
Setup Imports¶
import numpy as np
from auxiliary.nifti.io import read_nifti
from rich import print as pprint
from panoptica import InputType, Panoptica_Evaluator
from panoptica.metrics import Metric
Load Data¶
To demonstrate we use a reference and predicition of spine a segmentation with matched instances.
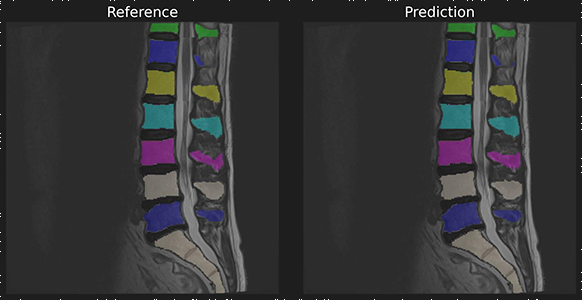
ref_masks = read_nifti(f"{BASE_PATH}/spine_seg/matched_instance/ref.nii.gz")
pred_masks = read_nifti(f"{BASE_PATH}/spine_seg/matched_instance/pred.nii.gz")
# labels are matching
np.unique(ref_masks), np.unique(pred_masks)
(array([ 0, 2, 3, 4, 5, 6, 7, 8, 26, 102, 103, 104, 105,
106, 107, 108, 202, 203, 204, 205, 206, 207, 208], dtype=uint8),
array([ 0, 2, 3, 4, 5, 6, 7, 8, 26, 102, 103, 104, 105,
106, 107, 108, 202, 203, 204, 205, 206, 207, 208], dtype=uint8))
Run Evaluation¶
evaluator = Panoptica_Evaluator(
expected_input=InputType.MATCHED_INSTANCE,
decision_metric=Metric.IOU,
decision_threshold=0.5,
)
result, intermediate_steps_data = evaluator.evaluate(pred_masks, ref_masks)["ungrouped"]
Panoptic: Start Evaluation -- Got MatchedInstancePair, will evaluate instances
Inspect Results¶
The results object allows access to individual metrics and provides helper methods for further processing
# print all results
print(result)
+++ MATCHING +++ Number of instances in reference (num_ref_instances): 22 Number of instances in prediction (num_pred_instances): 22 True Positives (tp): 22 False Positives (fp): 0 False Negatives (fn): 0 Recognition Quality / F1-Score (rq): 1.0 +++ GLOBAL +++ Global Binary Dice (global_bin_dsc): 0.9744370224078394 +++ INSTANCE +++ Segmentation Quality IoU (sq): 0.8328184295330796 +- 0.15186064004517466 Panoptic Quality IoU (pq): 0.8328184295330796 Segmentation Quality Dsc (sq_dsc): 0.900292616009954 +- 0.10253566174957332 Panoptic Quality Dsc (pq_dsc): 0.900292616009954 Segmentation Quality ASSD (sq_assd): 0.250331887879225 +- 0.07696680402317076 Segmentation Quality Relative Volume Difference (sq_rvd): 0.0028133049062930553 +- 0.034518928495505724
# get specific metric, e.g. pq
pprint(f"{result.pq=}")
result.pq=0.8328184295330796
# get dict for further processing, e.g. for pandas
pprint("results dict: ", result.to_dict())
results dict: { 'num_ref_instances': 22, 'num_pred_instances': 22, 'tp': 22, 'fp': 0, 'fn': 0, 'prec': 1.0, 'rec': 1.0, 'rq': 1.0, 'sq': 0.8328184295330796, 'sq_std': 0.15186064004517466, 'pq': 0.8328184295330796, 'sq_dsc': 0.900292616009954, 'sq_dsc_std': 0.10253566174957332, 'pq_dsc': 0.900292616009954, 'sq_assd': 0.250331887879225, 'sq_assd_std': 0.07696680402317076, 'sq_rvd': 0.0028133049062930553, 'sq_rvd_std': 0.034518928495505724, 'global_bin_dsc': 0.9744370224078394 }
# To inspect different phases, just use the returned intermediate_steps_data object
intermediate_steps_data.original_prediction_arr # yields input prediction array
intermediate_steps_data.original_reference_arr # yields input reference array
intermediate_steps_data.prediction_arr(
InputType.MATCHED_INSTANCE
) # yields prediction array after instances have been matched
intermediate_steps_data.reference_arr(
InputType.MATCHED_INSTANCE
) # yields reference array after instances have been matched
# The other InputType do not work here, as the input was already a matched instance map, therefore the steps from instance approximation and matching have been skipped
try:
intermediate_steps_data.reference_arr(InputType.SEMANTIC)
except AssertionError as e:
print(e)
# Error will indicate the problem
key SEMANTIC not in intermediate steps, maybe the step was skipped?