


Tutorial¶
This notebook gets you started with using Text-Fabric for coding in Missieven Corpus.
Familiarity with the underlying data model is recommended.
Tip¶
If you start computing with this tutorial, first copy its parent directory to somewhere else, outside your repository. If you pull changes from the repository later, your work will not be overwritten. Where you put your tutorial directory is up to you. It will work from any directory.
%load_ext autoreload
%autoreload 2
from tf.app import use
Corpus data¶
Text-Fabric will fetch the Missieven corpus for you.
It will fetch the newest version by default, but you can get other versions as well.
The data will be stored under text-fabric-data in your home directory.
Incantation¶
The simplest way to get going is by this incantation:
For the very last version, use hot.
For the latest release, use latest.
If you have cloned the repos (TF app and data), use clone.
If you do not want/need to upgrade, leave out the checkout specifiers.
After downloading new data it will take several minutes to optimize the data.
The optimized data will be stored in your system, and all subsequent use of this corpus will find that optimized data.
# A = use("CLARIAH/wp6-missieven:latest", hoist=globals())
A = use("CLARIAH/wp6-missieven", hoist=globals())
Locating corpus resources ...
Data: CLARIAH - wp6-missieven 1.0e, Character table, Feature docs
Node types
| Name | # of nodes | # slots / node | % coverage |
|---|---|---|---|
| volume | 14 | 426954.79 | 100 |
| letter | 607 | 9847.39 | 100 |
| page | 11215 | 532.98 | 100 |
| table | 491 | 137.91 | 1 |
| para | 34773 | 100.79 | 59 |
| remark | 24110 | 97.49 | 39 |
| head | 607 | 31.12 | 0 |
| note | 12476 | 16.88 | 4 |
| line | 526918 | 11.34 | 100 |
| row | 8350 | 8.10 | 1 |
| entity | 4659 | 6.26 | 0 |
| folio | 7899 | 2.63 | 0 |
| cell | 32302 | 2.09 | 1 |
| ent | 17756 | 1.64 | 0 |
| subhead | 1864 | 1.42 | 0 |
| word | 5977367 | 1.00 | 100 |
Features:
General Missives Dutch East India Company 1600-1800
specified
- apiVersion:
3 - appName:
CLARIAH/wp6-missieven - appPath:
/Users/me/text-fabric-data/github/CLARIAH/wp6-missieven/app - commit:
g61b0cb1b6bb6e9c4549a53aa5db557ffe37c1946 css:
.remark {
font-size: large;
font-style: italic;
}
.folio {
font-size: small;
color: #668866;
}
.fmark:after {
font-size: small;
font-weight: bold;
vertical-align: super;
color: #ddaa22;
}
.note {
vertical-align: super;
font-size: small;
color: #774400;
}
.ref {
font-size: small;
font-weight: bold;
color: #666688;
}
.emph {
font-style: italic;
}
.und {
text-decoration: underline;
}
.q {
color: #777777;
font-weight: bold;
}
.num {
font-size: small;
vertical-align: super;
}
.den {
font-size: small;
vertical-align: sub;
}
.sub {
vertical-align: sub;
}
.super {
vertical-align: super;
}
.special {
font-family: monospace;
font-weight: bold;
color: #886666;
}dataDisplay:
textFormats:
- layout-full: {method:
layoutFull} - layout-nonorig: {method:
layoutNonOrig} - layout-nonotes: {method:
layoutNoNotes} - layout-noremarks: {method:
layoutNoRemarks} - layout-notes: {method:
layoutNotes} - layout-orig: {method:
layoutOrig} - layout-remarks: {method:
layoutRemarks}
docs:
- docPage:
about featureBase:
https://github.com/{org}/{repo}/blob/master/docs/transcription{docExt}- featurePage:
''
- docPage:
- interfaceDefaults:
{} - isCompatible:
True - local:
local localDir:
/Users/me/text-fabric-data/github/CLARIAH/wp6-missieven/_tempprovenanceSpec:
- corpus:
General Missives Dutch East India Company 1600-1800 - doi:
10.5281/zenodo.4011801 - extraData:
ner - org:
CLARIAH - relative:
/tf - repo:
wp6-missieven - version:
1.0e webBase:
http://resources.huygens.knaw.nl/retroboeken/generalemissiven- webFeature:
weblink - webHint:
Show this document on Huygens webOffset:
2:
- 1:
23 - 10:
11 - 11:
11 - 12:
11 - 13:
11 - 2:
13 - 3:
13 - 4:
15 - 5:
15 - 6:
15 - 7:
13 - 8:
11 - 9:
13
- webUrl:
{webBase}/#page=<2>&source=<1>
- corpus:
- release:
v1.1 - typeDisplay:
{}
Features¶
The data consists of features, which are pieces of information addressed to nodes.
For each word there is a node, and one of the features in this dataset is called trans
and contains the text for each node.
Another feature, punc, contains whatever follows each word until the next word.
Hence these two features together contain the full text of the corpus.
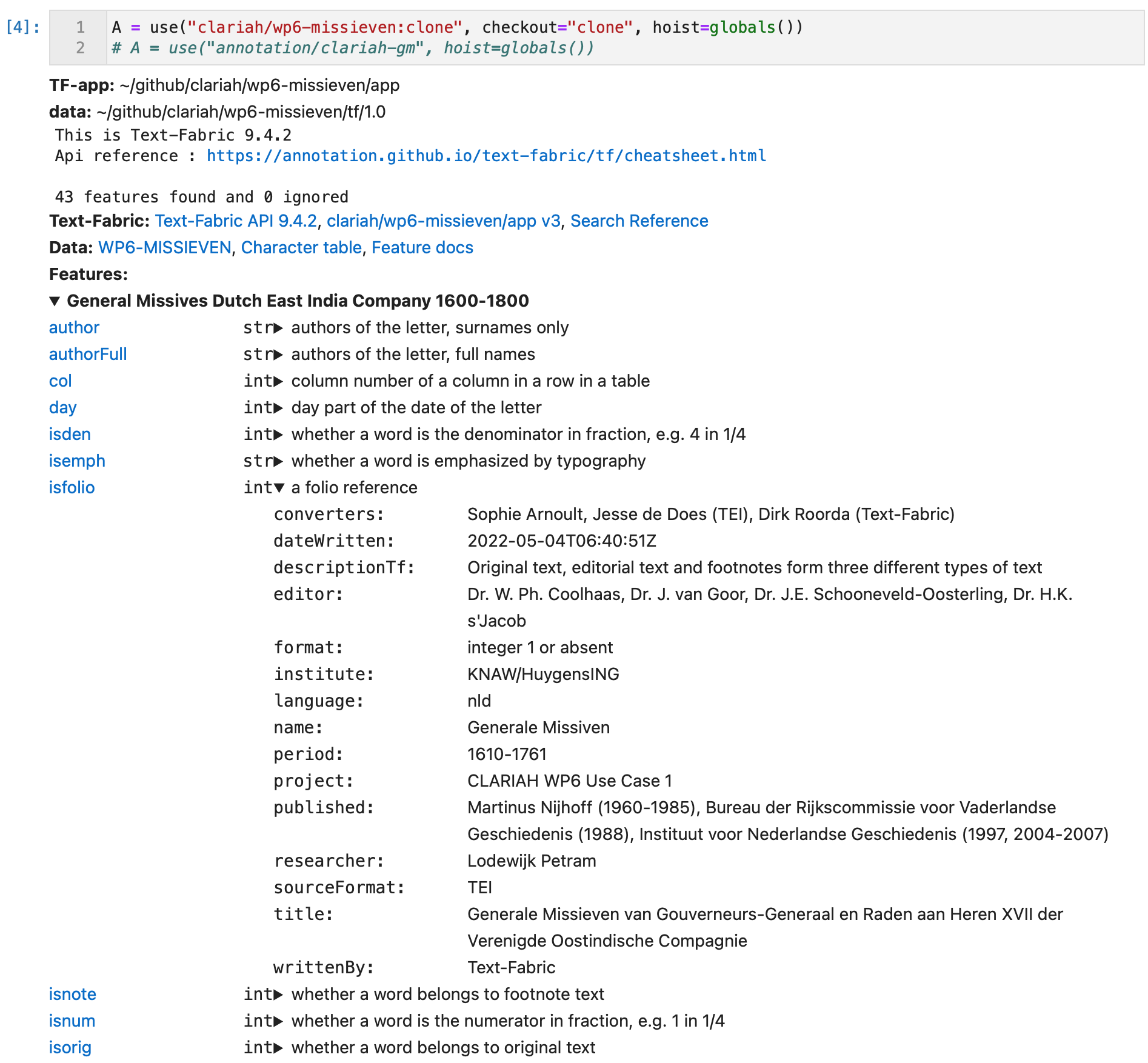
Which features are defined, and what they mean is dependent on the dataset. The dataset designer has provided metadata and documentation about features that are accessible wherever you work with Text-Fabric.
Click on the black triangle above, just before General Missives and you see a list of all features with a short description.
Hint 1 You can also click on the feature name to go to the documentation of the feature.
Hint 2
If you add silent="verbose" to the use() command, you get a black triangle
in every feature and when you expand that you see additional metadata for that feature.
We did not pass that argument here, but we can still get that info by:
A.header(allMeta=True)
Data: CLARIAH - wp6-missieven 1.0e, Character table, Feature docs
Node types
| Name | # of nodes | # slots / node | % coverage |
|---|---|---|---|
| volume | 14 | 426954.79 | 100 |
| letter | 607 | 9847.39 | 100 |
| page | 11215 | 532.98 | 100 |
| table | 491 | 137.91 | 1 |
| para | 34773 | 100.79 | 59 |
| remark | 24110 | 97.49 | 39 |
| head | 607 | 31.12 | 0 |
| note | 12476 | 16.88 | 4 |
| line | 526918 | 11.34 | 100 |
| row | 8350 | 8.10 | 1 |
| entity | 4659 | 6.26 | 0 |
| folio | 7899 | 2.63 | 0 |
| cell | 32302 | 2.09 | 1 |
| ent | 17756 | 1.64 | 0 |
| subhead | 1864 | 1.42 | 0 |
| word | 5977367 | 1.00 | 100 |
Features:
General Missives Dutch East India Company 1600-1800
whether a word has superscript typography possibly indicating the numerator of a fraction
specified
- apiVersion:
3 - appName:
CLARIAH/wp6-missieven - appPath:
/Users/me/text-fabric-data/github/CLARIAH/wp6-missieven/app - commit:
g61b0cb1b6bb6e9c4549a53aa5db557ffe37c1946 css:
.remark {
font-size: large;
font-style: italic;
}
.folio {
font-size: small;
color: #668866;
}
.fmark:after {
font-size: small;
font-weight: bold;
vertical-align: super;
color: #ddaa22;
}
.note {
vertical-align: super;
font-size: small;
color: #774400;
}
.ref {
font-size: small;
font-weight: bold;
color: #666688;
}
.emph {
font-style: italic;
}
.und {
text-decoration: underline;
}
.q {
color: #777777;
font-weight: bold;
}
.num {
font-size: small;
vertical-align: super;
}
.den {
font-size: small;
vertical-align: sub;
}
.sub {
vertical-align: sub;
}
.super {
vertical-align: super;
}
.special {
font-family: monospace;
font-weight: bold;
color: #886666;
}dataDisplay:
textFormats:
- layout-full: {method:
layoutFull} - layout-nonorig: {method:
layoutNonOrig} - layout-nonotes: {method:
layoutNoNotes} - layout-noremarks: {method:
layoutNoRemarks} - layout-notes: {method:
layoutNotes} - layout-orig: {method:
layoutOrig} - layout-remarks: {method:
layoutRemarks}
docs:
- docPage:
about featureBase:
https://github.com/{org}/{repo}/blob/master/docs/transcription{docExt}- featurePage:
''
- docPage:
- interfaceDefaults:
{} - isCompatible:
True - local:
local localDir:
/Users/me/text-fabric-data/github/CLARIAH/wp6-missieven/_tempprovenanceSpec:
- corpus:
General Missives Dutch East India Company 1600-1800 - doi:
10.5281/zenodo.4011801 - extraData:
ner - org:
CLARIAH - relative:
/tf - repo:
wp6-missieven - version:
1.0e webBase:
http://resources.huygens.knaw.nl/retroboeken/generalemissiven- webFeature:
weblink - webHint:
Show this document on Huygens webOffset:
2:
- 1:
23 - 10:
11 - 11:
11 - 12:
11 - 13:
11 - 2:
13 - 3:
13 - 4:
15 - 5:
15 - 6:
15 - 7:
13 - 8:
11 - 9:
13
- webUrl:
{webBase}/#page=<2>&source=<1>
- corpus:
- release:
v1.1 - typeDisplay:
{}
If you expand some triangles, you see something like this:
Provenance¶
You can get a more complete account of the provenance by:
A.showProvenance()
Getting around¶
Where am I?¶
All information in a Text-Fabric dataset is tied to nodes and edges. Nodes are integers, from 1 upwards, and the basic textual objects (slots) come first, in the order of the text. In this corpus, slots are words, and we have more than 5 millions of them.
Here is how you can visualize a slot and see where you are, if you found an arbitrary word:
n = 1_504_875
A.plain(L.u(n, otype="line")[0])
A.plain(n)
This word is in volume 4, page 717, line 2. You can click the passage specifier, and it will take you to the image of this page on the Missieven site maintained by the Huygens institute.

How to get to ...?¶
Suppose we want to move to volume 4, page 717. How do we find the node that corresponds to that page?
p = A.nodeFromSectionStr("4 717")
p
6561381
This looks like a meaningless number, but like a bar code on a product, this is the key to all information about a thing. What kind of thing?
F.otype.v(p)
'page'
We just asked for the value of the feature otype (object type) of node p, and it turned out to be a page.
In the same way we can get the page number:
F.n.v(p)
717
We can also navigate to a specific line:
ln = A.nodeFromSectionStr("4 717:2")
print(f"node {ln} is {F.otype.v(ln)} {F.n.v(ln)}")
node 6160791 is line 2
We can also do this in a more structured way:
p = T.nodeFromSection((4, 717))
p
6561381
ln = T.nodeFromSection((4, 717, 2))
ln
6160791
At this point, have a look at the cheatsheet and find the documentation of these methods.
Explore the neighbourhood¶
We show how to find the nodes of the lines in the page, how to print the text of those lines, and how to find the individual words.
Text-Fabric has an API called Locality (or simply L) to explore spatially related nodes.
From a node we can go up, down, previous and next. Here we go down.
lines = L.d(p, otype="line")
lines
(6160790, 6160791, 6160792, 6160793, 6160794, 6160795, 6160796, 6160797, 6160798, 6160799, 6160800, 6160801, 6160802, 6160803, 6160804, 6160805, 6160806, 6160807, 6160808, 6160809, 6160810, 6160811, 6160812, 6160813, 6160814, 6160815, 6160816, 6160817, 6160818, 6160819, 6160820, 6160821, 6160822, 6160823, 6160824, 6160825, 6160826, 6160827, 6160828, 6160829, 6160830, 6160831)
Again, seemingly meaningless numbers. Normally we do not display those numbers, but we display the material associated to those nodes.
Display¶
Text-Fabric has a high-level display API to show textual material in various ways.
Here is a plain view.
You do not (yet) see a clear distinction in text types. There is a mixture of editorial text and original text, and there is even a footnote.
We can show the text other text formats. Formats have been defined by the dataset designer, they are not built in into Text-Fabric. Let's see what the designer has provided in this regard:
T.formats
{'text-orig-full': 'word',
'text-orig-note': 'word',
'text-orig-remark': 'word',
'text-orig-source': 'word',
'layout-full': 'word',
'layout-noremarks': 'word',
'layout-nonotes': 'word',
'layout-nonorig': 'word',
'layout-remarks': 'word',
'layout-notes': 'word',
'layout-orig': 'word'}
Some formats show all text, others editorial texts only, and some show original letter content only and others just the footnotes. Yet other formats show all text except a specific type.
The formats that start with text- yield plain Unicode text.
The formats that start with layout- deliver formatted HTML.
We have designed the layout in such a way that the text types (editorial, original) are distinguished.
The default format is text-orig-full.
Let's switch to layout-full, which will also show the footnotes in place.
for line in lines:
A.plain(line, fmt="layout-full")
If we want to skip the remarks we can choose layout-noremarks:
for line in lines:
A.plain(line, fmt="layout-noremarks")
Or, without the footnotes:
for line in lines:
A.plain(line, fmt="layout-remarks")
Just the original text:
Drilling down¶
Lets navigate to individual words, we pick a few lines from this page we have seen in various ways.
lineNum = 5
ln = A.nodeFromSectionStr(f"4 717:{lineNum}")
A.plain(ln)
words = L.d(ln, otype="word")
words
(1504915, 1504916, 1504917, 1504918, 1504919, 1504920, 1504921, 1504922, 1504923, 1504924, 1504925, 1504926, 1504927, 1504928, 1504929, 1504930)
Let's make a table of the words of this line and the values of some features that they carry:
features = "trans transo transr transn punc isorig isremark isnote".split()
table = []
for lno in range(lineNum - 2, lineNum + 3):
ln = T.nodeFromSection((3, 717, lno))
for w in L.d(ln, otype="word"):
row = tuple(Fs(feature).v(w) for feature in features)
table.append(row)
table
[('door', None, 'door', None, ' ', None, 1, None),
('Sjivadji', None, 'Sjivadji', None, ' ', None, 1, None),
('en', None, 'en', None, ' ', None, 1, None),
('de', None, 'de', None, ' ', None, 1, None),
('hoofden', None, 'hoofden', None, ' ', None, 1, None),
('van', None, 'van', None, ' ', None, 1, None),
('Bijapur', None, 'Bijapur', None, '; ', None, 1, None),
('de', None, 'de', None, ' ', None, 1, None),
('resident', None, 'resident', None, ' ', None, 1, None),
('Leendertsz', None, 'Leendertsz', None, '. ', None, 1, None),
('raadt', None, 'raadt', None, ' ', None, 1, None),
('aan', None, 'aan', None, ' ', None, 1, None),
('hun', None, 'hun', None, ' ', None, 1, None),
('te', None, 'te', None, ' ', None, 1, None),
('laten', None, 'laten', None, ' ', None, 1, None),
('weten', None, 'weten', None, ', ', None, 1, None),
('dat', None, 'dat', None, ' ', None, 1, None),
('de', None, 'de', None, ' ', None, 1, None),
('vestiging', None, 'vestiging', None, ' ', None, 1, None),
('wordt', None, 'wordt', None, ' ', None, 1, None),
('opgeheven', None, 'opgeheven', None, ', ', None, 1, None),
('indien', None, 'indien', None, ' ', None, 1, None),
('zij', None, 'zij', None, ' ', None, 1, None),
('zo', None, 'zo', None, ' ', None, 1, None),
('voortgaan', None, 'voortgaan', None, ' » ', None, 1, None),
('', None, None, None, '', None, None, None),
('Wij', 'Wij', None, None, ' ', 1, None, None),
('twijfelen', 'twijfelen', None, None, ', ', 1, None, None),
('of', 'of', None, None, ' ', 1, None, None),
('sij', 'sij', None, None, ' ', 1, None, None),
('sooveel', 'sooveel', None, None, ' ', 1, None, None),
('werck', 'werck', None, None, ' ', 1, None, None),
('al', 'al', None, None, ' ', 1, None, None),
('van', 'van', None, None, ' ', 1, None, None),
('ons', 'ons', None, None, ' ', 1, None, None),
('soude', 'soude', None, None, ' ', 1, None, None),
('maecken', 'maecken', None, None, ', ', 1, None, None),
('omdat', 'omdat', None, None, ' ', 1, None, None),
('se', 'se', None, None, ' ', 1, None, None),
('de', 'de', None, None, ' ', 1, None, None),
('Engelsen', 'Engelsen', None, None, ' ', 1, None, None),
('ende', 'ende', None, None, ' ', 1, None, None),
('nu', 'nu', None, None, ' ', 1, None, None),
('oocq', 'oocq', None, None, ' ', 1, None, None),
('de', 'de', None, None, ' ', 1, None, None),
('Francen', 'Francen', None, None, ' ', 1, None, None),
('bij', 'bij', None, None, ' ', 1, None, None),
('de', 'de', None, None, ' ', 1, None, None),
('wercken', 'wercken', None, None, ' ', 1, None, None),
('hebben', 'hebben', None, None, ' ', 1, None, None),
('ende', 'ende', None, None, ' ', 1, None, None),
('van', 'van', None, None, ' ', 1, None, None),
('dewelcke', 'dewelcke', None, None, ' ', 1, None, None),
('sij', 'sij', None, None, ' ', 1, None, None)]
We can show that more prettily in a markdown table, but it is a bit of a hassle to compose the markdown string. Once we have that, we can pass it to a method in the Text-Fabric API that displays it as markdown.
NL = "\n"
mdHead = f"""
{" | ".join(features)}
{" | ".join("---" for _ in features)}
"""
mdData = "\n".join(
f"""{" | ".join(str(c or "").replace(NL, " ") for c in row)}""" for row in table
)
A.dm(f"""{mdHead}{mdData}""")
| trans | transo | transr | transn | punc | isorig | isremark | isnote |
|---|---|---|---|---|---|---|---|
| door | door | 1 | |||||
| Sjivadji | Sjivadji | 1 | |||||
| en | en | 1 | |||||
| de | de | 1 | |||||
| hoofden | hoofden | 1 | |||||
| van | van | 1 | |||||
| Bijapur | Bijapur | ; | 1 | ||||
| de | de | 1 | |||||
| resident | resident | 1 | |||||
| Leendertsz | Leendertsz | . | 1 | ||||
| raadt | raadt | 1 | |||||
| aan | aan | 1 | |||||
| hun | hun | 1 | |||||
| te | te | 1 | |||||
| laten | laten | 1 | |||||
| weten | weten | , | 1 | ||||
| dat | dat | 1 | |||||
| de | de | 1 | |||||
| vestiging | vestiging | 1 | |||||
| wordt | wordt | 1 | |||||
| opgeheven | opgeheven | , | 1 | ||||
| indien | indien | 1 | |||||
| zij | zij | 1 | |||||
| zo | zo | 1 | |||||
| voortgaan | voortgaan | » | 1 | ||||
| Wij | Wij | 1 | |||||
| twijfelen | twijfelen | , | 1 | ||||
| of | of | 1 | |||||
| sij | sij | 1 | |||||
| sooveel | sooveel | 1 | |||||
| werck | werck | 1 | |||||
| al | al | 1 | |||||
| van | van | 1 | |||||
| ons | ons | 1 | |||||
| soude | soude | 1 | |||||
| maecken | maecken | , | 1 | ||||
| omdat | omdat | 1 | |||||
| se | se | 1 | |||||
| de | de | 1 | |||||
| Engelsen | Engelsen | 1 | |||||
| ende | ende | 1 | |||||
| nu | nu | 1 | |||||
| oocq | oocq | 1 | |||||
| de | de | 1 | |||||
| Francen | Francen | 1 | |||||
| bij | bij | 1 | |||||
| de | de | 1 | |||||
| wercken | wercken | 1 | |||||
| hebben | hebben | 1 | |||||
| ende | ende | 1 | |||||
| van | van | 1 | |||||
| dewelcke | dewelcke | 1 | |||||
| sij | sij | 1 |
Note that the dataset designer has the text strings of all words into the feature trans;
editorial words also go into transr, but not into transo;
original words go into transo, but not into transr.
The existence of these features is mainly to make it possible to define the selective text formats we have seen above.
If constructing a low level dataset is too low-level for your taste, we can just collect a bunch of nodes and feed it to a higher-level display function of Text-Fabric:
table = []
for lno in range(lineNum - 2, lineNum + 3):
ln = T.nodeFromSection((3, 717, lno))
for w in L.d(ln, otype="word"):
table.append((w,))
table
[(1094113,), (1094114,), (1094115,), (1094116,), (1094117,), (1094118,), (1094119,), (1094120,), (1094121,), (1094122,), (1094123,), (1094124,), (1094125,), (1094126,), (1094127,), (1094128,), (1094129,), (1094130,), (1094131,), (1094132,), (1094133,), (1094134,), (1094135,), (1094136,), (1094137,), (1094138,), (1094139,), (1094140,), (1094141,), (1094142,), (1094143,), (1094144,), (1094145,), (1094146,), (1094147,), (1094148,), (1094149,), (1094150,), (1094151,), (1094152,), (1094153,), (1094154,), (1094155,), (1094156,), (1094157,), (1094158,), (1094159,), (1094160,), (1094161,), (1094162,), (1094163,), (1094164,), (1094165,), (1094166,)]
Before we ask Text-Fabric to display this, we tell it the features we're interested in.
A.displaySetup(extraFeatures=features)
A.show(table, condensed=True, fmt="layout-full")
line 1
line 2
line 3
line 4
line 5
Where this machinery really shines is when it comes to displaying the results of queries. See search.
Next steps¶
By now you have an impression how to orient yourself in the Missieven dataset. The next steps will show you how to get powerful: searching and computing.
After that it is time for collecting results, use them in new annotations and share them.
- start start computing with this corpus
- search turbo charge your hand-coding with search templates
- compute sink down a level and compute it yourself
- exportExcel make tailor-made spreadsheets out of your results
- annotate export text, annotate with BRAT, import annotations
- share draw in other people's data and let them use yours
- entities use results of third-party NER (named entity recognition)
- porting port features made against an older version to a newer version
- volumes work with selected volumes only
CC-BY Dirk Roorda