Data Observatory¶
CARTO's Data Observatory is a spatial data platfrom that enables data scientists to augment their data and broaden their analyses by using thousands of datasets from around the globe.
This guide is intended for those who want to start augmenting their data using CARTOframes and wish to explore CARTO's public Data Observatory catalog to find datasets that best fit their use cases and analyses. For further learning you can also check out the Data Observatory examples.
Data Discovery¶
The Data Obsevatory data catalog is comprised of thousands of curated spatial datasets. When searching for data the easiest way to find what you are looking for is to make use of a faceted search. A faceted (or hierarchical) search allows you to narrow down search results by applying multiple filters based on the faceted classification of catalog datasets. For more information check the data discovery example.
Datasets are organized in these main hierarchies: country, category, provider and geography (or spatial resolution).
The catalog is public and you don't need a CARTO account to search for available datasets. You can access the web version of the catalog here.
Dataset and variables metadata¶
The Data Observatory catalog is not only a repository of curated spatial datasets, it also contains valuable information that helps better understand the underlying data of every dataset so you can make an informed decision on what data best fits your problem.
Some of the augmented metadata you can find for each dataset in the catalog is:
headandtailmethods to get a glimpse of the actual data. This helps you to understand the available columns, data types, etc., to start modelling your problem right away.geom_coverageto visualize on a map the geographical coverage of the data in theDataset.counts,fields_by_typeand a fulldescribemethod with stats of the actual values in the dataset, such as: average, stdev, quantiles, min, max, median for each of the variables of the dataset.
You don't need a subscription to a dataset to be able to query the augmented metadata, it's publicly available for anyone exploring the Data Observatory catalog.
Let's review some of that information, starting by getting a glimpse of the ten first or last rows of the actual data of the dataset:
from cartoframes.data.observatory import Dataset
dataset = Dataset.get('ags_sociodemogr_a7e14220')
dataset.head()
| DWLCY | DWLPY | HHDCY | HHDPY | POPCY | POPPY | geoid | VPHCY1 | do_date | AGECYMED | ... | MARCYDIVOR | MARCYNEVER | MARCYWIDOW | RCHCYAMNHS | RCHCYASNHS | RCHCYBLNHS | RCHCYHANHS | RCHCYMUNHS | RCHCYOTNHS | RCHCYWHNHS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1057 | 1112 | 932 | 986 | 1500 | 1648 | 040130405071 | 442 | 2020-01-01 00:00:00+00:00 | 77.40 | ... | 149 | 4 | 228 | 0 | 11 | 20 | 0 | 25 | 0 | 1317 |
| 1 | 1964 | 2069 | 1774 | 1877 | 2595 | 2868 | 040130405072 | 1049 | 2020-01-01 00:00:00+00:00 | 76.88 | ... | 414 | 160 | 699 | 0 | 74 | 68 | 7 | 55 | 0 | 2167 |
| 2 | 1049 | 1101 | 897 | 933 | 1585 | 1716 | 040130610182 | 460 | 2020-01-01 00:00:00+00:00 | 69.88 | ... | 31 | 217 | 246 | 2 | 55 | 43 | 9 | 26 | 0 | 1313 |
| 3 | 1084 | 1137 | 910 | 940 | 1503 | 1616 | 040138175002 | 392 | 2020-01-01 00:00:00+00:00 | 71.44 | ... | 191 | 79 | 268 | 8 | 24 | 38 | 0 | 8 | 0 | 1290 |
| 4 | 682 | 706 | 574 | 591 | 980 | 1039 | 040190043241 | 244 | 2020-01-01 00:00:00+00:00 | 72.38 | ... | 30 | 44 | 195 | 3 | 9 | 0 | 0 | 0 | 0 | 902 |
| 5 | 880 | 910 | 840 | 869 | 1249 | 1284 | 060133511032 | 539 | 2020-01-01 00:00:00+00:00 | 76.75 | ... | 160 | 40 | 319 | 0 | 136 | 19 | 2 | 12 | 5 | 1024 |
| 6 | 1467 | 1534 | 1314 | 1467 | 1658 | 1800 | 060590995101 | 831 | 2020-01-01 00:00:00+00:00 | 74.58 | ... | 423 | 136 | 496 | 3 | 226 | 10 | 1 | 16 | 0 | 1269 |
| 7 | 704 | 753 | 693 | 730 | 1078 | 1176 | 060610210391 | 338 | 2020-01-01 00:00:00+00:00 | 73.86 | ... | 117 | 63 | 215 | 5 | 33 | 7 | 0 | 9 | 0 | 986 |
| 8 | 1582 | 1691 | 1553 | 1650 | 2540 | 2795 | 060610236001 | 818 | 2020-01-01 00:00:00+00:00 | 68.80 | ... | 406 | 45 | 301 | 5 | 168 | 26 | 3 | 19 | 0 | 2183 |
| 9 | 1186 | 1268 | 1163 | 1234 | 1980 | 2176 | 060610236002 | 415 | 2020-01-01 00:00:00+00:00 | 68.59 | ... | 253 | 60 | 223 | 5 | 97 | 22 | 1 | 10 | 0 | 1750 |
10 rows × 110 columns
Alternatively, you can get the last ten ones with dataset.tail()
An overview of the coverage of the dataset
dataset.geom_coverage()
Some stats about the dataset:
dataset.counts()
rows 217182.0 cells 23890020.0 null_cells 0.0 null_cells_percent 0.0 dtype: float64
dataset.fields_by_type()
float 5 string 2 integer 102 timestamp 1 dtype: int64
dataset.describe()
| POPCY | POPCYGRP | POPCYGRPI | AGECY0004 | AGECY0509 | AGECY1014 | AGECY1519 | AGECY2024 | AGECY2529 | AGECY3034 | ... | DWLCYVACNT | DWLCYRENT | DWLCYOWNED | POPPY | HHDPY | DWLPY | AGEPYMED | INCPYPCAP | INCPYAVEHH | INCPYMEDHH | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| avg | 1520.470 | 37.257 | 17.988 | 90.470 | 93.410 | 95.816 | 97.264 | 100.084 | 108.362 | 104.433 | ... | 49.577 | 211.630 | 383.558 | 1568.307 | 607.559 | 671.856 | 39.894 | 42928.961 | 107309.801 | 79333.276 |
| max | 67100.000 | 19752.000 | 12053.000 | 5393.000 | 5294.000 | 5195.000 | 7606.000 | 14804.000 | 5767.000 | 5616.000 | ... | 6547.000 | 10057.000 | 23676.000 | 75845.000 | 28115.000 | 32640.000 | 87.500 | 3824975.000 | 11127199.000 | 350000.000 |
| min | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | ... | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 |
| sum | 330218663.000 | 8091501.000 | 3906704.000 | 19648543.000 | 20287023.000 | 20809454.000 | 21124098.000 | 21736551.000 | 23534360.000 | 22680873.000 | ... | 10767170.000 | 45962130.000 | 83301818.000 | 340607958.000 | 131950960.000 | 145914927.000 | 8664364.200 | 9323397645.000 | 23305757123.000 | 17229759532.000 |
| range | 67100.000 | 19752.000 | 12053.000 | 5393.000 | 5294.000 | 5195.000 | 7606.000 | 14804.000 | 5767.000 | 5616.000 | ... | 6547.000 | 10057.000 | 23676.000 | 75845.000 | 28115.000 | 32640.000 | 87.500 | 3824975.000 | 11127199.000 | 350000.000 |
| stdev | 1063.417 | 242.869 | 158.206 | 80.448 | 83.389 | 83.518 | 111.783 | 124.412 | 96.428 | 93.590 | ... | 98.498 | 235.326 | 316.331 | 1141.981 | 413.855 | 446.769 | 7.567 | 31788.703 | 78351.308 | 42620.182 |
| q1 | 850.000 | 0.000 | 0.000 | 44.000 | 44.000 | 46.000 | 45.000 | 43.000 | 50.000 | 49.000 | ... | 11.000 | 60.000 | 182.000 | 867.000 | 344.000 | 384.000 | 34.070 | 21680.000 | 55361.000 | 47018.000 |
| q3 | 1454.000 | 0.000 | 0.000 | 83.000 | 86.000 | 89.000 | 87.000 | 86.000 | 98.000 | 95.000 | ... | 34.000 | 178.000 | 375.000 | 1485.000 | 581.000 | 648.000 | 41.010 | 40582.000 | 101272.000 | 79083.000 |
| median | 1125.000 | 0.000 | 0.000 | 62.000 | 63.000 | 65.000 | 64.000 | 62.000 | 71.000 | 69.000 | ... | 20.000 | 108.000 | 274.000 | 1143.000 | 452.000 | 504.000 | 37.710 | 30563.000 | 76713.000 | 62122.000 |
| interquartile_range | 604.000 | 0.000 | 0.000 | 39.000 | 42.000 | 43.000 | 42.000 | 43.000 | 48.000 | 46.000 | ... | 23.000 | 118.000 | 193.000 | 618.000 | 237.000 | 264.000 | 6.940 | 18902.000 | 45911.000 | 32065.000 |
10 rows × 107 columns
Every Dataset instance in the catalog contains other useful metadata:
dataset.to_dict()
{'slug': 'ags_sociodemogr_a7e14220',
'name': 'Sociodemographics - United States of America (Census Block Group)',
'description': 'Census and ACS sociodemographic data estimated for the current year and data projected to five years. Projected fields are general aggregates (total population, total households, median age, avg income etc.)',
'category_id': 'demographics',
'country_id': 'usa',
'data_source_id': 'sociodemographics',
'provider_id': 'ags',
'geography_name': 'Census Block Group - United States of America',
'geography_description': None,
'temporal_aggregation': 'yearly',
'time_coverage': None,
'update_frequency': None,
'is_public_data': False,
'lang': 'eng',
'version': '2020',
'category_name': 'Demographics',
'provider_name': 'Applied Geographic Solutions',
'geography_id': 'carto-do.ags.geography_usa_blockgroup_2015',
'id': 'carto-do.ags.demographics_sociodemographics_usa_blockgroup_2015_yearly_2020'}
When exploring datasets in the Data Observatory catalog it's very important that you understand clearly what variables are available to enrich your own data.
For each Variable in each dataset, the Data Observatory provides (as it does for datasets) a set of methods and attributes to understand their underlaying data.
Some of them are:
headandtailmethods to get a glimpse of the actual data and start modelling your problem right away.counts,quantilesand a fulldescribemethod with stats of the actual values in the dataset, such as: average, stdev, quantiles, min, max, median for each of the variables of the dataset.- an
histogramplot with the distribution of the values on each variable.
Let's review some of that augmented metadata for the variables in the AGS population dataset.
from cartoframes.data.observatory import Variable
variable = Variable.get('POPCY_4534fac4')
variable
<Variable.get('POPCY_4534fac4')> #'Population (current year)'
variable.to_dict()
{'slug': 'POPCY_4534fac4',
'name': 'Total Population',
'description': 'Population (current year)',
'db_type': 'INTEGER',
'agg_method': 'SUM',
'column_name': 'POPCY',
'variable_group_id': None,
'dataset_id': 'carto-do.ags.demographics_sociodemographics_usa_blockgroup_2015_yearly_2020',
'id': 'carto-do.ags.demographics_sociodemographics_usa_blockgroup_2015_yearly_2020.POPCY'}
There's also some utility methods to understand the underlying data for each variable:
variable.head()
0 1500 1 2595 2 1585 3 1503 4 980 5 1249 6 1658 7 1078 8 2540 9 1980 dtype: int64
variable.counts()
all 217182.000 null 0.000 zero 299.000 extreme 9073.000 distinct 6756.000 outliers 26998.000 null_percent 0.000 zero_percent 0.138 extreme_percent 0.042 distinct_percent 3.111 outliers_percent 0.124 dtype: float64
variable.quantiles()
q1 850 q3 1454 median 1125 interquartile_range 604 dtype: int64
variable.histogram()

variable.describe()
avg 1520.470 max 67100.000 min 0.000 sum 330218663.000 range 67100.000 stdev 1063.417 q1 850.000 q3 1454.000 median 1125.000 interquartile_range 604.000 dtype: float64
Subscribe to a Dataset in the catalog¶
Once you have explored the catalog and have identified a dataset with the variables you need for your analysis and in the right spatial resolution, you can check is_public_data to know whether the dataset is freely accessible or you first need to purchase a license. Subscriptions are available for CARTO's Enterprise plan users.
Subscriptions to datasets allow you to either use them from CARTOframes to enrich your own data or to download them. See the enrichment guide for more information.
Let's check out the dataset and geography from our previous example:
dataset = Dataset.get('ags_sociodemogr_a7e14220')
dataset.is_public_data
False
This dataset is not public data, which means that you need a subscription to be able to use it to enrich your own data.
To subscribe to premium data in the Data Observatory catalog you need an Enterprise CARTO account with access to the Data Observatory.
from cartoframes.auth import set_default_credentials
set_default_credentials('creds.json')
dataset.subscribe()
Licenses to data in the Data Observatory grant you the right to use the data for the period of one year. Every non-public dataset or geography you want to use to enrich your own data require a valid license.
You can check the actual status of your subscriptions directly from the catalog.
from cartoframes.data.observatory import Catalog
Catalog().subscriptions()
Datasets: [<Dataset.get('ags_sociodemogr_a7e14220')>, <Dataset.get('ags_retailpoten_aaf25a8c')>, <Dataset.get('pb_consumer_po_62cddc04')>, <Dataset.get('ags_sociodemogr_f510a947')>, <Dataset.get('ags_consumer_sp_dbabddfb')>, <Dataset.get('spa_geosocial_s_d5dc42ae')>, <Dataset.get('mc_geographic__7980c5c3')>, <Dataset.get('pb_points_of_i_94bda91b')>, <Dataset.get('u360_sociodemogr_28e93b81')>]
Geographies: [<Geography.get('ags_blockgroup_1c63771c')>, <Geography.get('pb_lat_lon_d01ac868')>, <Geography.get('pb_lat_lon_b6575b9')>, <Geography.get('u360_grid100x100_24162784')>]
Data Access¶
Now that we have explored some basic information about the Dataset, we will proceed to download a sample of the Dataset into a dataframe so we can operate with it using Python.
Note: You'll need your CARTO Account credentials to perform this action.
from cartoframes.auth import set_default_credentials
set_default_credentials('creds.json')
from cartoframes.data.observatory import Dataset
dataset = Dataset.get('ags_sociodemogr_a7e14220')
# Filter by SQL query
query = "SELECT * FROM $dataset$ LIMIT 50"
dataset_df = dataset.to_dataframe(sql_query=query)
Note about SQL filters
Our SQL filtering queries allow for any PostgreSQL and PostGIS operation, so you can filter the rows (by a WHERE condition) or the columns (using the SELECT). Some common examples are filtering the Dataset by bounding box or filtering by column value:
SELECT * FROM $dataset$ WHERE ST_IntersectsBox(geom, -74.044467,40.706128,-73.891345,40.837690)
SELECT total_pop, geom FROM $dataset$
A good tool to get the bounding box of a specific area is bboxfinder.com.
# First rows of the Dataset sample
dataset_df.head()
| BLOCKGROUP | POPCY | POPCYGRP | POPCYGRPI | AGECY0004 | AGECY0509 | AGECY1014 | AGECY1519 | AGECY2024 | AGECY2529 | ... | POPPY | HHDPY | DWLPY | AGEPYMED | INCPYPCAP | INCPYAVEHH | INCPYMEDHH | geoid | do_date | geom | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 120570140122 | 1999 | 0 | 0 | 5 | 4 | 3 | 0 | 6 | 8 | ... | 2184 | 1324 | 1462 | 73.060 | 42925 | 70807 | 70419 | 120570140122 | 2020-01-01 00:00:00+00:00 | POLYGON ((-82.38386 27.68793, -82.38408 27.687... |
| 1 | 390759768011 | 3029 | 0 | 0 | 276 | 317 | 325 | 303 | 247 | 206 | ... | 2989 | 702 | 743 | 25.940 | 32716 | 139300 | 96153 | 390759768011 | 2020-01-01 00:00:00+00:00 | POLYGON ((-81.79413 40.56118, -81.79423 40.560... |
| 2 | 60372671002 | 997 | 0 | 0 | 65 | 60 | 45 | 35 | 32 | 63 | ... | 991 | 445 | 464 | 43.820 | 81355 | 181174 | 144601 | 60372671002 | 2020-01-01 00:00:00+00:00 | POLYGON ((-118.42418 34.05756, -118.42395 34.0... |
| 3 | 60379800141 | 236 | 10 | 0 | 3 | 5 | 4 | 3 | 7 | 10 | ... | 235 | 180 | 183 | 54.670 | 129559 | 168394 | 174999 | 60379800141 | 2020-01-01 00:00:00+00:00 | POLYGON ((-118.26088 33.76850, -118.26070 33.7... |
| 4 | 60750155002 | 1443 | 99 | 1 | 28 | 17 | 21 | 28 | 105 | 202 | ... | 1458 | 927 | 998 | 47.970 | 143367 | 224783 | 125191 | 60750155002 | 2020-01-01 00:00:00+00:00 | POLYGON ((-122.43821 37.78546, -122.43786 37.7... |
5 rows × 111 columns
You can also download the dataset directly to a CSV file
query = "SELECT * FROM $dataset$ LIMIT 50"
dataset_df = dataset.to_csv('my_dataset.csv', sql_query=query)
Data saved: my_dataset.csv
To load it as a DataFrame you can do:
df = pandas.read_csv('my_dataset.csv')
Data Enrichment¶
We define enrichment as the process of augmenting your data with new variables by means of a spatial join between your data and a Dataset in CARTO's Data Observatory, aggregated at a given spatial resolution, or in other words:
"Enrichment is the process of adding variables to a geometry, which we call the target, (point, line, polygon…) from a spatial (polygon) dataset, which we call the source"
We recommend you also check out the CARTOframes quickstart guide since it offers a complete example of data discovery and enrichment and also helps you build a simple dashboard to draw conclusions from the resulting data.
Note: You'll need your CARTO Account credentials to perform this action.
from cartoframes.auth import set_default_credentials
set_default_credentials('creds.json')
from cartoframes.data.observatory import Dataset
dataset = Dataset.get('ags_sociodemogr_a7e14220')
variables = dataset.variables
variables
[<Variable.get('BLOCKGROUP_30e525a6')> #'Geographic Identifier',
<Variable.get('POPCY_4534fac4')> #'Population (current year)',
<Variable.get('POPCYGRP_3033ef2e')> #'Population in Group Quarters (current year)',
<Variable.get('POPCYGRPI_1e42899')> #'Institutional Group Quarters Population (current y...',
<Variable.get('AGECY0004_aaae373a')> #'Population age 0-4 (current year)',
<Variable.get('AGECY0509_d2d4896c')> #'Population age 5-9 (current year)',
<Variable.get('AGECY1014_b09611e')> #'Population age 10-14 (current year)',
<Variable.get('AGECY1519_7373df48')> #'Population age 15-19 (current year)',
<Variable.get('AGECY2024_32919d33')> #'Population age 20-24 (current year)',
<Variable.get('AGECY2529_4aeb2365')> #'Population age 25-29 (current year)',
<Variable.get('AGECY3034_9336cb17')> #'Population age 30-34 (current year)',
<Variable.get('AGECY3539_eb4c7541')> #'Population age 35-39 (current year)',
<Variable.get('AGECY4044_41a06569')> #'Population age 40-44 (current year)',
<Variable.get('AGECY4549_39dadb3f')> #'Population age 45-49 (current year)',
<Variable.get('AGECY5054_e007334d')> #'Population age 50-54 (current year)',
<Variable.get('AGECY5559_987d8d1b')> #'Population age 55-59 (current year)',
<Variable.get('AGECY6064_d99fcf60')> #'Population age 60-64 (current year)',
<Variable.get('AGECY6569_a1e57136')> #'Population age 65-69 (current year)',
<Variable.get('AGECY7074_78389944')> #'Population age 70-74 (current year)',
<Variable.get('AGECY7579_422712')> #'Population age 75-79 (current year)',
<Variable.get('AGECY8084_a7c395dd')> #'Population age 80-84 (current year)',
<Variable.get('AGECYGT85_ac46767d')> #'Population age 85+ (current year)',
<Variable.get('AGECYMED_f218d6e9')> #'Median Age (current year)',
<Variable.get('SEXCYMAL_8ee6ade5')> #'Population male (current year)',
<Variable.get('SEXCYFEM_91d8b796')> #'Population female (current year)',
<Variable.get('RCHCYWHNHS_b4cab6fe')> #'Non Hispanic White (current year)',
<Variable.get('RCHCYBLNHS_93a8395b')> #'Non Hispanic Black (current year)',
<Variable.get('RCHCYAMNHS_6cb424ee')> #'Non Hispanic American Indian (current year)',
<Variable.get('RCHCYASNHS_dc720442')> #'Non Hispanic Asian (current year)',
<Variable.get('RCHCYHANHS_2b72f927')> #'Non Hispanic Hawaiian/Pacific Islander (current ye...',
<Variable.get('RCHCYOTNHS_fe95829a')> #'Non Hispanic Other Race (current year)',
<Variable.get('RCHCYMUNHS_3ce9b69f')> #'Non Hispanic Multiple Race (current year)',
<Variable.get('HISCYHISP_e62d7c2e')> #'Population Hispanic (current year)',
<Variable.get('MARCYNEVER_eee4f8c3')> #'Never Married (current year)',
<Variable.get('MARCYMARR_17f0d887')> #'Now Married (current year)',
<Variable.get('MARCYSEP_d4d69eb8')> #'Separated (current year)',
<Variable.get('MARCYWIDOW_5ce5d993')> #'Widowed (current year)',
<Variable.get('MARCYDIVOR_146db750')> #'Divorced (current year)',
<Variable.get('AGECYGT15_7d84cd34')> #'Population Age 15+ (current year)',
<Variable.get('EDUCYLTGR9_ed0362fa')> #'Pop 25+ less than 9th grade (current year)',
<Variable.get('EDUCYSHSCH_7a88e398')> #'Pop 25+ 9th-12th grade no diploma (current year)',
<Variable.get('EDUCYHSCH_a7a81733')> #'Pop 25+ HS graduate (current year)',
<Variable.get('EDUCYSCOLL_3840e65b')> #'Pop 25+ college no diploma (current year)',
<Variable.get('EDUCYASSOC_dcd76160')> #'Pop 25+ Associate degree (current year)',
<Variable.get('EDUCYBACH_d7b78049')> #'Pop 25+ Bachelor's degree (current year)',
<Variable.get('EDUCYGRAD_c58943fb')> #'Pop 25+ graduate or prof school degree (current ye...',
<Variable.get('AGECYGT25_56a99ef7')> #'Population Age 25+ (current year)',
<Variable.get('HHDCY_935c1592')> #'Households (current year)',
<Variable.get('HHDCYFAM_c1a6fccf')> #'Family Households (current year)',
<Variable.get('HHSCYMCFCH_bd115dc2')> #'Families married couple w children (current year)',
<Variable.get('HHSCYLPMCH_ce8863e2')> #'Families male no wife w children (current year)',
<Variable.get('HHSCYLPFCH_c2dd8c03')> #'Families female no husband children (current year)',
<Variable.get('HHDCYAVESZ_d265f21c')> #'Average Household Size (current year)',
<Variable.get('HHDCYMEDAG_4f099151')> #'Median Age of Householder (current year)',
<Variable.get('VPHCYNONE_3755ac60')> #'Households: No Vehicle Available (current year)',
<Variable.get('VPHCY1_bed441da')> #'Households: One Vehicle Available (current year)',
<Variable.get('VPHCYGT1_e4a07c30')> #'Households: Two or More Vehicles Available (curren...',
<Variable.get('INCCYPCAP_7c8377cf')> #'Per capita income (current year)',
<Variable.get('INCCYAVEHH_1ef75363')> #'Average household Income (current year)',
<Variable.get('INCCYMEDHH_98692c24')> #'Median household income (current year)',
<Variable.get('INCCYMEDFA_7f36b90e')> #'Median family income (current year)',
<Variable.get('HINCYLT10_61c14e29')> #'Household Income < $10000 (current year)',
<Variable.get('HINCY1015_c720a11b')> #'Household Income $10000-$14999 (current year)',
<Variable.get('HINCY1520_9aacc4bc')> #'Household Income $15000-$19999 (current year)',
<Variable.get('HINCY2025_feb85d36')> #'Household Income $20000-$24999 (current year)',
<Variable.get('HINCY2530_91025a13')> #'Household Income $25000-$29999 (current year)',
<Variable.get('HINCY3035_5f1f0b12')> #'Household Income $30000-$34999 (current year)',
<Variable.get('HINCY3540_66ffabb1')> #'Household Income $35000-$39999 (current year)',
<Variable.get('HINCY4045_8d89a56c')> #'Household Income $40000-$44999 (current year)',
<Variable.get('HINCY4550_e233a249')> #'Household Income $45000-$49999 (current year)',
<Variable.get('HINCY5060_77695404')> #'Household Income $50000-$59999 (current year)',
<Variable.get('HINCY6075_cad3e24')> #'Household Income $60000-$74999 (current year)',
<Variable.get('HINCY75100_bb90c7bb')> #'Household Income $75000-$99999 (current year)',
<Variable.get('HINCY10025_40903e13')> #'Household Income $100000-$124999 (current year)',
<Variable.get('HINCY12550_d379563b')> #'Household Income $125000-$149999 (current year)',
<Variable.get('HINCY15020_7243aae')> #'Household Income $150000-$199999 (current year)',
<Variable.get('HINCYGT200_c39e094b')> #'Household Income > $200000 (current year)',
<Variable.get('HINCYMED24_4ac9369')> #'Median Household Income: Age < 25 (current year)',
<Variable.get('HINCYMED25_73aba3ff')> #'Median Household Income: Age 25-34 (current year)',
<Variable.get('HINCYMED35_6ab092be')> #'Median Household Income: Age 35-44 (current year)',
<Variable.get('HINCYMED45_25f10479')> #'Median Household Income: Age 45-54 (current year)',
<Variable.get('HINCYMED55_3cea3538')> #'Median Household Income: Age 55-64 (current year)',
<Variable.get('HINCYMED65_17c766fb')> #'Median Household Income: Age 65-74 (current year)',
<Variable.get('HINCYMED75_edc57ba')> #'Median Household Income: Age 75+ (current year)',
<Variable.get('LBFCYPOP16_75363c6f')> #'Population Age 16+ (current year)',
<Variable.get('LBFCYARM_c8f45b67')> #'Pop 16+ in Armed Forces (current year)',
<Variable.get('LBFCYEMPL_1902fd90')> #'Pop 16+ civilian employed (current year)',
<Variable.get('LBFCYUNEM_befc2d4')> #'Pop 16+ civilian unemployed (current year)',
<Variable.get('LBFCYNLF_803bfa0d')> #'Pop 16+ not in labor force (current year)',
<Variable.get('UNECYRATE_a642ed8a')> #'Unemployment Rate (current year)',
<Variable.get('LBFCYLBF_1d3c03ed')> #'Population In Labor Force (current year)',
<Variable.get('LNIEXSPAN_8f8728c7')> #'SPANISH SPEAKING HOUSEHOLDS',
<Variable.get('LNIEXISOL_c2e86dc7')> #'LINGUISTICALLY ISOLATED HOUSEHOLDS (NON-ENGLISH SP...',
<Variable.get('HOOEXMED_48df3206')> #'Median Value of Owner Occupied Housing Units',
<Variable.get('RNTEXMED_6ac2e609')> #'Median Cash Rent',
<Variable.get('HUSEX1DET_231a9f6c')> #'UNITS IN STRUCTURE: 1 DETACHED',
<Variable.get('HUSEXAPT_dc7d3c72')> #'UNITS IN STRUCTURE: 20 OR MORE',
<Variable.get('DWLCY_50c5eee2')> #'Housing units (current year)',
<Variable.get('DWLCYVACNT_6b929d9a')> #'Housing units vacant (current year)',
<Variable.get('DWLCYRENT_3601a69e')> #'Occupied units renter (current year)',
<Variable.get('DWLCYOWNED_858b3ad6')> #'Occupied units owner (current year)',
<Variable.get('POPPY_24dbbb56')> #'Population (projected, five yearsA)',
<Variable.get('HHDPY_f2b35400')> #'Households (projected, five yearsA)',
<Variable.get('DWLPY_312aaf70')> #'Housing units (projected, five yearsA)',
<Variable.get('AGEPYMED_d5583bbb')> #'Median Age (projected, five yearsA)',
<Variable.get('INCPYPCAP_f9c107fa')> #'Per capita income (projected, five yearsA)',
<Variable.get('INCPYAVEHH_48c1d530')> #'Average household Income (projected, five yearsA)',
<Variable.get('INCPYMEDHH_ce5faa77')> #'Median household income (projected, five yearsA)',
<Variable.get('geoid_818ef39c')> #'Geographical Identifier',
<Variable.get('do_date_be147af')> #'First day of time period']
The ags_sociodemogr_f510a947 dataset contains socio-demographic variables aggregated by Census block group level.
Let's try and find a variable for total population:
vdf = variables.to_dataframe()
vdf[vdf['name'].str.contains('pop', case=False, na=False)]
| slug | name | description | db_type | agg_method | column_name | variable_group_id | dataset_id | id | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | POPCY_4534fac4 | Total Population | Population (current year) | INTEGER | SUM | POPCY | None | carto-do.ags.demographics_sociodemographics_us... | carto-do.ags.demographics_sociodemographics_us... |
| 2 | POPCYGRP_3033ef2e | POPCYGRP | Population in Group Quarters (current year) | INTEGER | SUM | POPCYGRP | None | carto-do.ags.demographics_sociodemographics_us... | carto-do.ags.demographics_sociodemographics_us... |
| 3 | POPCYGRPI_1e42899 | POPCYGRPI | Institutional Group Quarters Population (curre... | INTEGER | SUM | POPCYGRPI | None | carto-do.ags.demographics_sociodemographics_us... | carto-do.ags.demographics_sociodemographics_us... |
| 84 | LBFCYPOP16_75363c6f | LBFCYPOP16 | Population Age 16+ (current year) | INTEGER | SUM | LBFCYPOP16 | carto-do.ags.demographics_sociodemographics_us... | carto-do.ags.demographics_sociodemographics_us... | carto-do.ags.demographics_sociodemographics_us... |
| 101 | POPPY_24dbbb56 | Total population | Population (projected, five yearsA) | INTEGER | SUM | POPPY | None | carto-do.ags.demographics_sociodemographics_us... | carto-do.ags.demographics_sociodemographics_us... |
We can store the variable instance we need by searching the Catalog by its slug, in this case POPCY_4534fac4:
variable = Variable.get('POPCY_4534fac4')
variable.to_dict()
{'slug': 'POPCY_4534fac4',
'name': 'Total Population',
'description': 'Population (current year)',
'db_type': 'INTEGER',
'agg_method': 'SUM',
'column_name': 'POPCY',
'variable_group_id': None,
'dataset_id': 'carto-do.ags.demographics_sociodemographics_usa_blockgroup_2015_yearly_2020',
'id': 'carto-do.ags.demographics_sociodemographics_usa_blockgroup_2015_yearly_2020.POPCY'}
The POPCY variable contains the SUM of the population per blockgroup for the year 2019. Let's enrich our stores DataFrame with that variable.
Enrich points¶
Let's start by loading the geocoded Starbucks stores:
from geopandas import read_file
stores_gdf = read_file('http://libs.cartocdn.com/cartoframes/files/starbucks_brooklyn_geocoded.geojson')
stores_gdf.head()
| cartodb_id | field_1 | name | address | revenue | geometry | |
|---|---|---|---|---|---|---|
| 0 | 1 | 0 | Franklin Ave & Eastern Pkwy | 341 Eastern Pkwy,Brooklyn, NY 11238 | 1321040.772 | POINT (-73.95901 40.67109) |
| 1 | 2 | 1 | 607 Brighton Beach Ave | 607 Brighton Beach Avenue,Brooklyn, NY 11235 | 1268080.418 | POINT (-73.96122 40.57796) |
| 2 | 3 | 2 | 65th St & 18th Ave | 6423 18th Avenue,Brooklyn, NY 11204 | 1248133.699 | POINT (-73.98976 40.61912) |
| 3 | 4 | 3 | Bay Ridge Pkwy & 3rd Ave | 7419 3rd Avenue,Brooklyn, NY 11209 | 1185702.676 | POINT (-74.02744 40.63152) |
| 4 | 5 | 4 | Caesar's Bay Shopping Center | 8973 Bay Parkway,Brooklyn, NY 11214 | 1148427.411 | POINT (-74.00098 40.59321) |
Alternatively, you can load data in any geospatial format supported by GeoPandas or CARTO.
As we can see, for each store we have its name, address, the total revenue by year and a geometry column indicating the location of the store. This is important because for the enrichment service to work, we need a DataFrame with a geometry column encoded as a shapely object.
We can now create a new Enrichment instance, and since the stores_gdf dataset represents store locations (points), we can use the enrich_points function passing as arguments the stores DataFrame and a list of Variables (that we have a valid subscription from the Data Observatory catalog for).
In this case we are only enriching one variable (the total population), but we could enrich a list of them.
from cartoframes.data.observatory import Enrichment
enriched_stores_gdf = Enrichment().enrich_points(stores_gdf, [variable])
enriched_stores_gdf.head()
| cartodb_id | field_1 | name | address | revenue | geometry | POPCY | do_area | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | Franklin Ave & Eastern Pkwy | 341 Eastern Pkwy,Brooklyn, NY 11238 | 1321040.772 | POINT (-73.95901 40.67109) | 2608 | 59840.197 |
| 1 | 2 | 1 | 607 Brighton Beach Ave | 607 Brighton Beach Avenue,Brooklyn, NY 11235 | 1268080.418 | POINT (-73.96122 40.57796) | 1792 | 60150.637 |
| 2 | 3 | 2 | 65th St & 18th Ave | 6423 18th Avenue,Brooklyn, NY 11204 | 1248133.699 | POINT (-73.98976 40.61912) | 733 | 38950.619 |
| 3 | 4 | 3 | Bay Ridge Pkwy & 3rd Ave | 7419 3rd Avenue,Brooklyn, NY 11209 | 1185702.676 | POINT (-74.02744 40.63152) | 1155 | 57353.293 |
| 4 | 5 | 4 | Caesar's Bay Shopping Center | 8973 Bay Parkway,Brooklyn, NY 11214 | 1148427.411 | POINT (-74.00098 40.59321) | 2266 | 188379.243 |
Once the enrichment finishes, we can see there is a new column in our DataFrame called POPCY with population projected for the year 2019, from the US Census block group which contains each one of our Starbucks stores. The enrichment process also provides an extra column called do_area with the information of the area in square meters covered by the polygons in the source dataset we are using to enrich our data.
Enrich polygons¶
Next, let's do a second enrichment, but this time using a DataFrame with areas of influence calculated using the CARTOframes isochrones service to obtain the polygon around each store that covers the area within an 8, 17 and 25 minute walk.
aoi_gdf = read_file('http://libs.cartocdn.com/cartoframes/files/starbucks_brooklyn_isolines.geojson')
aoi_gdf.head()
| data_range | lower_data_range | range_label | geometry | |
|---|---|---|---|---|
| 0 | 500 | 0 | 8 min. | MULTIPOLYGON (((-73.95959 40.67571, -73.95971 ... |
| 1 | 1000 | 500 | 17 min. | POLYGON ((-73.95988 40.68110, -73.95863 40.681... |
| 2 | 1500 | 1000 | 25 min. | POLYGON ((-73.95986 40.68815, -73.95711 40.688... |
| 3 | 500 | 0 | 8 min. | MULTIPOLYGON (((-73.96185 40.58321, -73.96231 ... |
| 4 | 1000 | 500 | 17 min. | MULTIPOLYGON (((-73.96684 40.57483, -73.96830 ... |
In this case we have a DataFrame which, for each index in the stores_gdf, contains a polygon of the areas of influence around each store at 8, 17 and 25 minute walking intervals. Again the geometry is encoded as a shapely object.
In this case, the Enrichment service provides an enrich_polygons function, which in its basic version, works in the same way as the enrich_points function. It just needs a DataFrame with polygon geometries and a list of variables to enrich:
from cartoframes.data.observatory import Enrichment
enriched_aoi_gdf = Enrichment().enrich_polygons(aoi_gdf, [variable])
enriched_aoi_gdf.head()
| data_range | lower_data_range | range_label | geometry | POPCY | |
|---|---|---|---|---|---|
| 0 | 500 | 0 | 8 min. | MULTIPOLYGON (((-73.95959 40.67571, -73.95971 ... | 21893.522 |
| 1 | 1000 | 500 | 17 min. | POLYGON ((-73.95988 40.68110, -73.95863 40.681... | 60463.830 |
| 2 | 1500 | 1000 | 25 min. | POLYGON ((-73.95986 40.68815, -73.95711 40.688... | 111036.740 |
| 3 | 500 | 0 | 8 min. | MULTIPOLYGON (((-73.96185 40.58321, -73.96231 ... | 23118.114 |
| 4 | 1000 | 500 | 17 min. | MULTIPOLYGON (((-73.96684 40.57483, -73.96830 ... | 29213.000 |
We now have a new column in our areas of influence DataFrame, SUM_POPCY, which represents the SUM of the total population in the Census block groups that instersect with each polygon in our DataFrame.
How enrichment works¶
Let's take a deeper look into what happens under the hood when you execute a polygon enrichment.
Imagine we have polygons representing municipalities, in blue, each of which have a population attribute, and we want to find out the population inside the green circle.
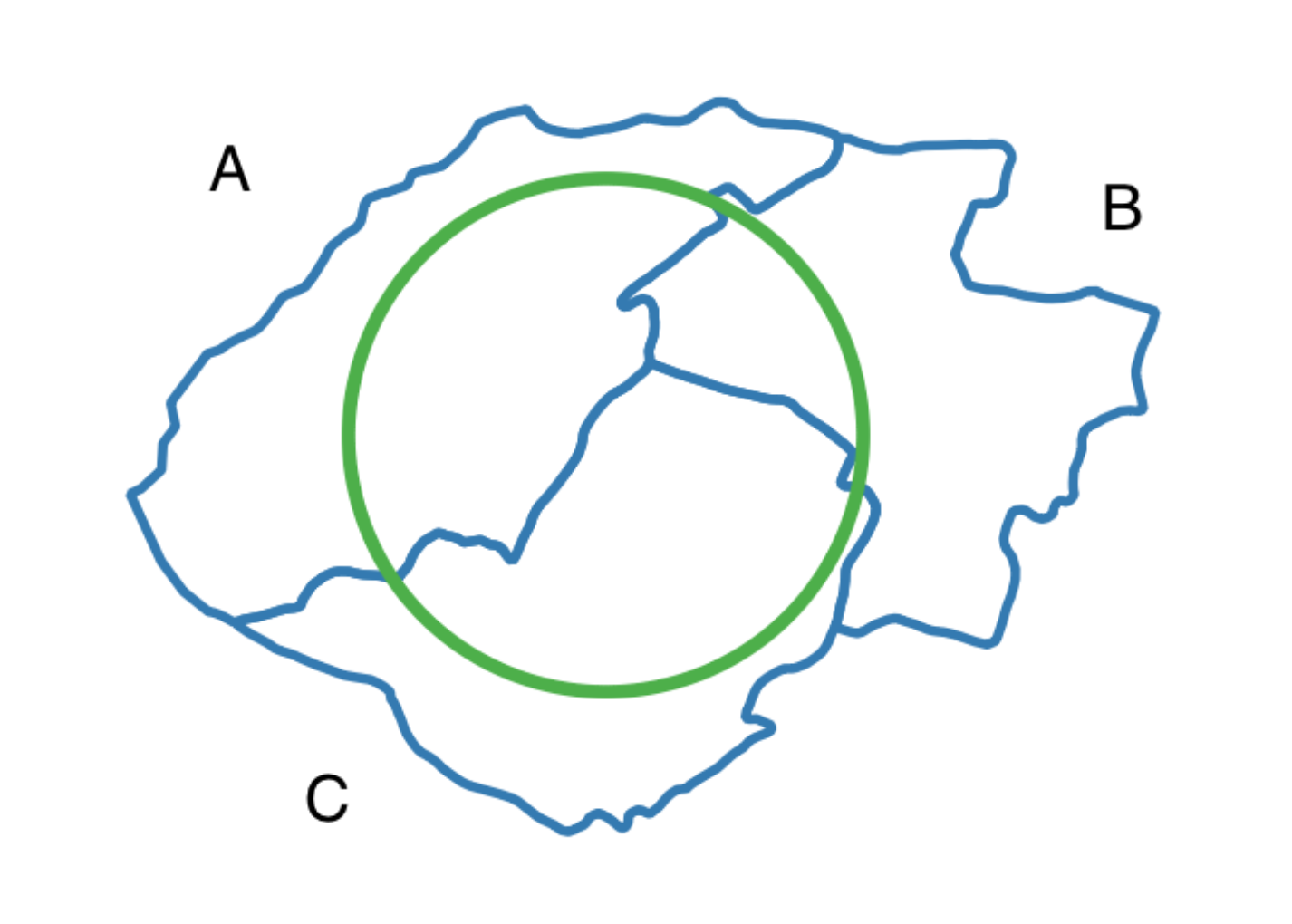
We don’t know how the population is distributed inside these municipalities. They are probably concentrated in cities somewhere, but, since we don’t know where they are, our best guess is to assume that the population is evenly distributed in the municipality (i.e. every point inside the municipality has the same population density).
Population is an extensive property (it grows with area), so we can subset it (a region inside the municipality will always have a smaller population than the whole municipality), and also aggregate it by summing.
In this case, we’d calculate the population inside each part of the circle that intersects with a municipality.
Default aggregation methods
In the Data Observatory, we suggest a default aggregation method for certain fields. However, some fields don’t have a clear best method, and some just can’t be aggregated. In these cases, we leave the agg_method field blank and let the user choose the method that best fits their needs.