6. Recurrent Neural Networks and Language Models¶
- http://web.stanford.edu/class/cs224n/lectures/cs224n-2017-lecture8.pdf
- http://web.stanford.edu/class/cs224n/lectures/cs224n-2017-lecture9.pdf
- http://colah.github.io/posts/2015-08-Understanding-LSTMs/
- https://github.com/pytorch/examples/tree/master/word_language_model
- https://github.com/yunjey/pytorch-tutorial/blob/master/tutorials/02-intermediate/language_model
In [1]:
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.optim as optim
import torch.nn.functional as F
import nltk
import random
import numpy as np
from collections import Counter, OrderedDict
import nltk
from copy import deepcopy
flatten = lambda l: [item for sublist in l for item in sublist]
random.seed(1024)
In [2]:
USE_CUDA = torch.cuda.is_available()
gpus = [0]
torch.cuda.set_device(gpus[0])
FloatTensor = torch.cuda.FloatTensor if USE_CUDA else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if USE_CUDA else torch.LongTensor
ByteTensor = torch.cuda.ByteTensor if USE_CUDA else torch.ByteTensor
In [4]:
def prepare_sequence(seq, to_index):
idxs = list(map(lambda w: to_index[w] if to_index.get(w) is not None else to_index["<unk>"], seq))
return LongTensor(idxs)
Data load and Preprocessing¶
Penn TreeBank¶
In [5]:
def prepare_ptb_dataset(filename, word2index=None):
corpus = open(filename, 'r', encoding='utf-8').readlines()
corpus = flatten([co.strip().split() + ['</s>'] for co in corpus])
if word2index == None:
vocab = list(set(corpus))
word2index = {'<unk>': 0}
for vo in vocab:
if word2index.get(vo) is None:
word2index[vo] = len(word2index)
return prepare_sequence(corpus, word2index), word2index
In [175]:
# borrowed code from https://github.com/pytorch/examples/tree/master/word_language_model
def batchify(data, bsz):
# Work out how cleanly we can divide the dataset into bsz parts.
nbatch = data.size(0) // bsz
# Trim off any extra elements that wouldn't cleanly fit (remainders).
data = data.narrow(0, 0, nbatch * bsz)
# Evenly divide the data across the bsz batches.
data = data.view(bsz, -1).contiguous()
if USE_CUDA:
data = data.cuda()
return data
In [176]:
def getBatch(data, seq_length):
for i in range(0, data.size(1) - seq_length, seq_length):
inputs = Variable(data[:, i: i + seq_length])
targets = Variable(data[:, (i + 1): (i + 1) + seq_length].contiguous())
yield (inputs, targets)
In [177]:
train_data, word2index = prepare_ptb_dataset('../dataset/ptb/ptb.train.txt',)
dev_data , _ = prepare_ptb_dataset('../dataset/ptb/ptb.valid.txt', word2index)
test_data, _ = prepare_ptb_dataset('../dataset/ptb/ptb.test.txt', word2index)
In [178]:
len(word2index)
Out[178]:
10000
In [179]:
index2word = {v:k for k, v in word2index.items()}
Modeling¶
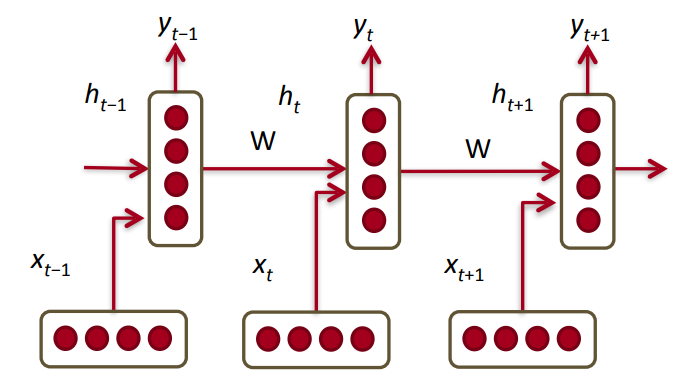
In [180]:
class LanguageModel(nn.Module):
def __init__(self, vocab_size, embedding_size, hidden_size, n_layers=1, dropout_p=0.5):
super(LanguageModel, self).__init__()
self.n_layers = n_layers
self.hidden_size = hidden_size
self.embed = nn.Embedding(vocab_size, embedding_size)
self.rnn = nn.LSTM(embedding_size, hidden_size, n_layers, batch_first=True)
self.linear = nn.Linear(hidden_size, vocab_size)
self.dropout = nn.Dropout(dropout_p)
def init_weight(self):
self.embed.weight = nn.init.xavier_uniform(self.embed.weight)
self.linear.weight = nn.init.xavier_uniform(self.linear.weight)
self.linear.bias.data.fill_(0)
def init_hidden(self,batch_size):
hidden = Variable(torch.zeros(self.n_layers,batch_size,self.hidden_size))
context = Variable(torch.zeros(self.n_layers,batch_size,self.hidden_size))
return (hidden.cuda(), context.cuda()) if USE_CUDA else (hidden, context)
def detach_hidden(self, hiddens):
return tuple([hidden.detach() for hidden in hiddens])
def forward(self, inputs, hidden, is_training=False):
embeds = self.embed(inputs)
if is_training:
embeds = self.dropout(embeds)
out,hidden = self.rnn(embeds, hidden)
return self.linear(out.contiguous().view(out.size(0) * out.size(1), -1)), hidden
Train¶
It takes for a while...
In [181]:
EMBED_SIZE = 128
HIDDEN_SIZE = 1024
NUM_LAYER = 1
LR = 0.01
SEQ_LENGTH = 30 # for bptt
BATCH_SIZE = 20
EPOCH = 40
RESCHEDULED = False
In [182]:
train_data = batchify(train_data, BATCH_SIZE)
dev_data = batchify(dev_data, BATCH_SIZE//2)
test_data = batchify(test_data, BATCH_SIZE//2)
In [185]:
model = LanguageModel(len(word2index), EMBED_SIZE, HIDDEN_SIZE, NUM_LAYER, 0.5)
model.init_weight()
if USE_CUDA:
model = model.cuda()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=LR)
In [186]:
for epoch in range(EPOCH):
total_loss = 0
losses = []
hidden = model.init_hidden(BATCH_SIZE)
for i,batch in enumerate(getBatch(train_data, SEQ_LENGTH)):
inputs, targets = batch
hidden = model.detach_hidden(hidden)
model.zero_grad()
preds, hidden = model(inputs, hidden, True)
loss = loss_function(preds, targets.view(-1))
losses.append(loss.data[0])
loss.backward()
torch.nn.utils.clip_grad_norm(model.parameters(), 0.5) # gradient clipping
optimizer.step()
if i > 0 and i % 500 == 0:
print("[%02d/%d] mean_loss : %0.2f, Perplexity : %0.2f" % (epoch,EPOCH, np.mean(losses), np.exp(np.mean(losses))))
losses = []
# learning rate anealing
# You can use http://pytorch.org/docs/master/optim.html#how-to-adjust-learning-rate
if RESCHEDULED == False and epoch == EPOCH//2:
LR *= 0.1
optimizer = optim.Adam(model.parameters(), lr=LR)
RESCHEDULED = True
[00/40] mean_loss : 9.45, Perplexity : 12712.23 [00/40] mean_loss : 5.88, Perplexity : 358.21 [00/40] mean_loss : 5.55, Perplexity : 256.44 [01/40] mean_loss : 5.38, Perplexity : 217.46 [01/40] mean_loss : 5.21, Perplexity : 182.41 [01/40] mean_loss : 5.10, Perplexity : 164.39 [02/40] mean_loss : 5.08, Perplexity : 160.87 [02/40] mean_loss : 4.99, Perplexity : 147.18 [02/40] mean_loss : 4.92, Perplexity : 136.52 [03/40] mean_loss : 4.92, Perplexity : 136.64 [03/40] mean_loss : 4.86, Perplexity : 129.32 [03/40] mean_loss : 4.80, Perplexity : 121.46 [04/40] mean_loss : 4.80, Perplexity : 121.91 [04/40] mean_loss : 4.77, Perplexity : 117.64 [04/40] mean_loss : 4.71, Perplexity : 111.22 [05/40] mean_loss : 4.72, Perplexity : 112.01 [05/40] mean_loss : 4.70, Perplexity : 109.46 [05/40] mean_loss : 4.64, Perplexity : 103.96 [06/40] mean_loss : 4.66, Perplexity : 105.25 [06/40] mean_loss : 4.64, Perplexity : 103.63 [06/40] mean_loss : 4.60, Perplexity : 99.00 [07/40] mean_loss : 4.60, Perplexity : 99.89 [07/40] mean_loss : 4.59, Perplexity : 98.97 [07/40] mean_loss : 4.55, Perplexity : 94.97 [08/40] mean_loss : 4.56, Perplexity : 95.54 [08/40] mean_loss : 4.56, Perplexity : 95.67 [08/40] mean_loss : 4.52, Perplexity : 91.98 [09/40] mean_loss : 4.53, Perplexity : 92.61 [09/40] mean_loss : 4.53, Perplexity : 92.79 [09/40] mean_loss : 4.50, Perplexity : 89.63 [10/40] mean_loss : 4.50, Perplexity : 90.13 [10/40] mean_loss : 4.50, Perplexity : 90.19 [10/40] mean_loss : 4.47, Perplexity : 87.11 [11/40] mean_loss : 4.48, Perplexity : 88.11 [11/40] mean_loss : 4.48, Perplexity : 88.26 [11/40] mean_loss : 4.45, Perplexity : 86.05 [12/40] mean_loss : 4.46, Perplexity : 86.81 [12/40] mean_loss : 4.47, Perplexity : 87.03 [12/40] mean_loss : 4.43, Perplexity : 84.04 [13/40] mean_loss : 4.45, Perplexity : 85.27 [13/40] mean_loss : 4.45, Perplexity : 85.83 [13/40] mean_loss : 4.42, Perplexity : 83.33 [14/40] mean_loss : 4.43, Perplexity : 84.15 [14/40] mean_loss : 4.43, Perplexity : 84.31 [14/40] mean_loss : 4.41, Perplexity : 82.29 [15/40] mean_loss : 4.43, Perplexity : 83.82 [15/40] mean_loss : 4.43, Perplexity : 83.70 [15/40] mean_loss : 4.40, Perplexity : 81.59 [16/40] mean_loss : 4.42, Perplexity : 83.06 [16/40] mean_loss : 4.42, Perplexity : 83.29 [16/40] mean_loss : 4.39, Perplexity : 80.89 [17/40] mean_loss : 4.41, Perplexity : 82.44 [17/40] mean_loss : 4.41, Perplexity : 82.51 [17/40] mean_loss : 4.39, Perplexity : 80.59 [18/40] mean_loss : 4.40, Perplexity : 81.59 [18/40] mean_loss : 4.41, Perplexity : 82.21 [18/40] mean_loss : 4.38, Perplexity : 79.87 [19/40] mean_loss : 4.40, Perplexity : 81.43 [19/40] mean_loss : 4.40, Perplexity : 81.67 [19/40] mean_loss : 4.37, Perplexity : 79.28 [20/40] mean_loss : 4.40, Perplexity : 81.18 [20/40] mean_loss : 4.40, Perplexity : 81.17 [20/40] mean_loss : 4.37, Perplexity : 79.11 [21/40] mean_loss : 4.40, Perplexity : 81.44 [21/40] mean_loss : 4.34, Perplexity : 76.43 [21/40] mean_loss : 4.21, Perplexity : 67.17 [22/40] mean_loss : 4.26, Perplexity : 70.84 [22/40] mean_loss : 4.26, Perplexity : 70.75 [22/40] mean_loss : 4.17, Perplexity : 64.99 [23/40] mean_loss : 4.22, Perplexity : 68.36 [23/40] mean_loss : 4.22, Perplexity : 67.82 [23/40] mean_loss : 4.15, Perplexity : 63.74 [24/40] mean_loss : 4.20, Perplexity : 66.66 [24/40] mean_loss : 4.20, Perplexity : 66.43 [24/40] mean_loss : 4.14, Perplexity : 62.85 [25/40] mean_loss : 4.18, Perplexity : 65.53 [25/40] mean_loss : 4.17, Perplexity : 64.99 [25/40] mean_loss : 4.13, Perplexity : 61.94 [26/40] mean_loss : 4.17, Perplexity : 64.61 [26/40] mean_loss : 4.16, Perplexity : 64.34 [26/40] mean_loss : 4.12, Perplexity : 61.27 [27/40] mean_loss : 4.15, Perplexity : 63.73 [27/40] mean_loss : 4.15, Perplexity : 63.32 [27/40] mean_loss : 4.11, Perplexity : 60.87 [28/40] mean_loss : 4.14, Perplexity : 62.96 [28/40] mean_loss : 4.14, Perplexity : 63.01 [28/40] mean_loss : 4.10, Perplexity : 60.33 [29/40] mean_loss : 4.14, Perplexity : 62.54 [29/40] mean_loss : 4.13, Perplexity : 62.36 [29/40] mean_loss : 4.10, Perplexity : 60.06 [30/40] mean_loss : 4.13, Perplexity : 62.05 [30/40] mean_loss : 4.13, Perplexity : 61.91 [30/40] mean_loss : 4.09, Perplexity : 59.46 [31/40] mean_loss : 4.12, Perplexity : 61.45 [31/40] mean_loss : 4.11, Perplexity : 61.24 [31/40] mean_loss : 4.08, Perplexity : 59.12 [32/40] mean_loss : 4.11, Perplexity : 61.03 [32/40] mean_loss : 4.11, Perplexity : 60.88 [32/40] mean_loss : 4.07, Perplexity : 58.69 [33/40] mean_loss : 4.11, Perplexity : 60.71 [33/40] mean_loss : 4.10, Perplexity : 60.57 [33/40] mean_loss : 4.07, Perplexity : 58.38 [34/40] mean_loss : 4.10, Perplexity : 60.33 [34/40] mean_loss : 4.10, Perplexity : 60.23 [34/40] mean_loss : 4.06, Perplexity : 58.06 [35/40] mean_loss : 4.09, Perplexity : 60.00 [35/40] mean_loss : 4.09, Perplexity : 59.74 [35/40] mean_loss : 4.06, Perplexity : 57.75 [36/40] mean_loss : 4.09, Perplexity : 59.58 [36/40] mean_loss : 4.09, Perplexity : 59.47 [36/40] mean_loss : 4.05, Perplexity : 57.59 [37/40] mean_loss : 4.08, Perplexity : 59.30 [37/40] mean_loss : 4.08, Perplexity : 59.11 [37/40] mean_loss : 4.05, Perplexity : 57.11 [38/40] mean_loss : 4.08, Perplexity : 58.98 [38/40] mean_loss : 4.07, Perplexity : 58.70 [38/40] mean_loss : 4.04, Perplexity : 57.10 [39/40] mean_loss : 4.07, Perplexity : 58.79 [39/40] mean_loss : 4.07, Perplexity : 58.58 [39/40] mean_loss : 4.04, Perplexity : 56.79
Test¶
In [189]:
total_loss = 0
hidden = model.init_hidden(BATCH_SIZE//2)
for batch in getBatch(test_data, SEQ_LENGTH):
inputs,targets = batch
hidden = model.detach_hidden(hidden)
model.zero_grad()
preds, hidden = model(inputs, hidden)
total_loss += inputs.size(1) * loss_function(preds, targets.view(-1)).data
total_loss = total_loss[0]/test_data.size(1)
print("Test Perpelexity : %5.2f" % (np.exp(total_loss)))
Test Perpelexity : 155.89
Further topics¶
In [ ]: