Introduction to Text-Fabric¶
By Martijn Naaijer (m.naaijer@vu.nl) in collaboration with Cody Kingham (c.a.kingham@student.vu.nl)
Welcome to this course on Text-Fabric. This course will teach you how to extract data from the Eep Talstra Centre for Bible and Computer (ETCBC) database using the Python package Text-Fabric. You do not need to have any Python knowledge to do this course, because you will learn Python and Text-Fabric at the same time.
Text-Fabric was developed by Dirk Roorda and Wido van Peursen as part of the SHEBANQ-project. On the SHEBANQ website you can inspect the text of the Hebrew Bible and you can make queries on the Hebrew text. Queries are made by using the Mini Query Language (MQL) with the features of the ETCBC database. Text-fabric serves as a research tool to make datasets that can be analyzed further. The whole ETCBC database is archived at the website of Data Archiving and Networked Sevices (DANS), where it can also be downloaded.
In this course you will first need to learn some basic Python, before you can start learning to use Text-Fabric.
1. About Python¶
We start with some basic things you need to know about the Python language. It includes basic data types, data structures and data flow control. When you have finished this notebook, you should know the following basic Python things:
- different data-types (string, integer, float, boolean, list, tuple, dictionary, set)
- slicing strings, string concatenation, lower() and upper()
- print()
- control flow tools (if-statements (if, elif, else), for-loop, range(), while-loop, write your own functions)
- use import
- export data to text files and csv files
There are two versions of Python one can use: Python 2 and Python 3. This notebook works with the newest version, Python 3. Many programmers still use Python 2, because there is no compatibility between Python 3 and the libraries they want to use. If you want to know more about different versions of Python, you can take a look here.
You can find a lot of good information about Python on the internet. A valuable source is the Python documentation: https://docs.python.org/3/
This introduction to Python is by no means a complete Python course. If you want to know more about Python it is recommended to follow a complete course. Good online courses can be found here: https://www.codecademy.com/learn/python
On Coursera you can find many different Python courses. Some are more general, others are focused on data science. https://www.coursera.org/courses?languages=en&query=python
In this file we will extract data from the ETCBC database with Text-Fabric using basic Python programming. However, with Text-Fabric it is also possible to make queries with an MQL-like template, which is called Search.
2. Basic Python, Data Types, Print¶
We start the course with some basic Python:
print("Hello world!")
Hello world!
This statement prints the text "Hello world!". print() is a function, and it prints what is inside the parentheses. We call this the argument. The part between the quotes is called a string and it consists of a number of characters, including a space and an exclamation mark. The function print() can have multiple arguments.
print("Hello world!", "How are you?")
Hello world! How are you?
You can add comments after #. It is strongly recommended to add comments to your code. Comments do not only clarify the code for new readers, but they are also helpful for yourself. Especially if you haven't worked on your code for a while.
The string is not the only data type in Python. There are also other data types, such as the integer. In the following cell the value 5 is assigned to the variable a. 5 is an integer. Integers a whole numbers.
a = 5 # 5 is an integer.
Python stores the data type of an object in memory. You can find out the data type of an object with the function type().
print(type(a))
<class 'int'>
print(type("Hello world!"))
<class 'str'>
The real numbers are a separate data type, called float. In the following cell numeric values are assigned to variable names with the names b, c and d. Assignment takes place with the = sign.
b = 5. # this is a float, note the decimal '.'.
c = 2.3
d = float(5)
print(type(b))
print(type(c))
print(type(d))
<class 'float'> <class 'float'> <class 'float'>
You can use the variable name to do calculations.
print(b * 5) # multiplication
print(b**5) # power
25.0 3125.0
It is important to know what the type of an object is. Let's have a look at the difference between a string and an integer.
What happens if you do '5' + '5' ?
'5' + '5' # This is called string concatenation. Strings are 'glued' together. You can do this with any kind of strings,
# e.g. 'etc' + 'bc' + '_' + '40'
'55'
The same happens if you do the following.
'5' * 2
'55'
This differs from the addition of two integers.
5 + 5
10
This happens if you want to add a string to an integer.
'5' + 5
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-12-4dd8efb5fac1> in <module> ----> 1 '5' + 5 TypeError: can only concatenate str (not "int") to str
You can convert the string '5' into an integer with int().
num_str = '5'
int(num_str) + 5
10
Another important data type is the boolean. A boolean variable can have two values: True and False.
bool_var = True
type(bool_var)
bool
3. Conditions, If Statements¶
Notice the difference between an assignment (=) and 'is equal to' (==).
4 == 5 # this is evaluated to False
False
!= is 'is not equal to' .
4 != 5
True
There is also > (greater than), < (smaller than), >= (greater than or equal to), and <= (smaller than or equal to)
4 <= 5
True
4 >= 5
False
The if statement checks if a certain condition is evaluated to True.
a = 0
if a == 0:
print('Hello,')
Hello,
if a != 0:
print('Eep')
The if statament ends with a colon. In Python it is required that the line after the colon is indented (with a tab or 4 spaces). Later you will see the colon also after for and while statements and in a function header, which starts with def.
To the if statement you can add zero or more elif's and an optional else.
if a == 0:
print('a is 0') #what is printed here is one string
elif a < 10:
print('a is geater than 0 and smaller than 10')
elif a < 15:
print('a is geater than 9 and smaller than 15')
else:
print('a is geater than 14')
a is 0
4. While Loops¶
With while you loop until a specific condition is not evaluated to the value True anymore.
number = 10
while number > 0:
print(number)
number -= 1
10 9 8 7 6 5 4 3 2 1
In the example above you saw number -= 1. This is a short way of writing number = number - 1. Similarly you have +=, *= and /= in Python.
number2 = 2
while number2 < 25:
print(number2)
number2 += 1
2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
5. Writing Functions¶
You use a function for operations that have to be done more than once in a program. The advantage of using functions is that you need to write the piece of code in the function only once, which keeps your code concise. Every time you want that piece of code to be executed, you call the function.
The structure of a function is as follows:
def functionName(arg1, arg2, ...):
"""
This is the docstring, here you explain what the function does. Use triple quotes.
It can cover more than one line.
"""
function body
...
...
return(certain_object)
If a function name consists of more words, as the name functionName, it is good Python style to use camel case, which means that the first letters of the words after the first word are capitalized. There is a whole document about Python style programming. You can find it here: https://www.python.org/dev/peps/pep-0008/ You can refer to it as PEP8. There are many things that you can do in various ways in Python. Often, one of those ways is considered the "Pythonic way". This Pythonic way gives you clean and efficient code. Many of these efficient coding manners are described in PEP8.
def cubicCalculator(num):
"""calculates cube of a number"""
cub_num = num**3
return (cub_num)
The function is called.
print(cubicCalculator(4))
print(cubicCalculator(6))
64 216
If you want to work further with the result of a function, you assign its value to a new variable.
new_var = cubicCalculator(10)
A function often has more than one argument. An argument can have a default value.
def addition(num_a, num_b=5):
'''adds two numbers together'''
num_c = num_a + num_b
return (num_c)
In the next cell the function is called. The value 10 in the function call corresponds with num_a in the function definition, and the value 12 in the function call corresponds with num_b.
print(addition(10, 12))
22
Now we give the function call only one argument. The second argument gets the default value 5 in this case.
print(addition(10))
15
6. Lists¶
A list is an ordered sequence of elements. You can recognize it by its square brackets. Here an empty list is initialized, which is called a_list.
a_list = [] # this is equivalent to a_list = list()
You can add elements to the list with the method .append() .
a_list.append(40)
print(a_list)
[40]
We add a string to a_list.
a_list.append('ETCBC')
print(a_list)
[40, 'ETCBC']
A list can also be populated manually.
unsorted_list = [3, 2, 1, 5]
print(unsorted_list)
[3, 2, 1, 5]
You can sort a list with the built-in function sorted().
print(sorted(unsorted_list))
[1, 2, 3, 5]
And you can sort it in reversed order with the argument reverse.
print(sorted(unsorted_list, reverse=True))
[5, 3, 2, 1]
7. About Text-Fabric¶
Now we start using Text-Fabric. If you want to work with it offline, you need to install it on your computer first. For the installation, look at: https://github.com/ETCBC/text-fabric.
In the API you find technical documentation about everything you can do with Text-Fabric.
It is important to know the features of the ETCBC database to be able to work with text-fabric. If you want to know more about the features, check the feature documentation. The following link explains the feature 'nu', the number of a word: https://etcbc.github.io/bhsa/features/nu/
8. Importing and Loading Text-Fabric¶
Every time you make a notebook in which you want to use text-fabric, you start with the following 'standard' cells. These standard cells import Text-Fabric data into the notebook. You can change the features that you want to load into the notebook, maybe with some slight modifications.
First import some modules
import sys, collections, os
import pprint as pp
Make sure you have installed text-fabric in Anaconda Prompt first! If not, you can to install it here by uncommenting the first line (simply remove #).
#!pip install text-fabric
from tf.app import use
A = use('bhsa:hot', hoist=globals())
9. For Loops and Looping over the Nodes in the ETCBC Database.¶
You are ready to work with text-fabric now. You can select words or clauses or other linguistic units with specific characteristics. In text-fabric you do this by looping over all the objects in the ETCBC database and check for each object whether it has the desired properties. You can do this by making a for loop. With a for loop you loop over a sequence.
We can make a numeric sequence with range() and loop over it with a for loop.
The for statement ends with a colon. In Python it is required that the line following the colon is indented. Later you will see the colon also after for and while statements and in a function header, which starts with def.
for number in range(15):
print(number)
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14
Look carefully at what range() does in the following examples.
for number in range(4, 15): # with two arguments we have range(start, stop)
print(number)
4 5 6 7 8 9 10 11 12 13 14
for number in range(
4, 15, 2): # with three arguments we have range(start, stop, step)
print(number)
4 6 8 10 12 14
Note that the arguments of range() are integers.
Instead of just printing the integers, you can store them in a list.
integer_list = []
for number in range(15):
integer_list.append(number)
print(integer_list)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
Note that the print statement in the previous cell is not indented. If we indent it it falls within the for loop:
integer_list = []
for number in range(15):
integer_list.append(number)
print(integer_list)
[0] [0, 1] [0, 1, 2] [0, 1, 2, 3] [0, 1, 2, 3, 4] [0, 1, 2, 3, 4, 5] [0, 1, 2, 3, 4, 5, 6] [0, 1, 2, 3, 4, 5, 6, 7] [0, 1, 2, 3, 4, 5, 6, 7, 8] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13] [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]
Now the print statement is executed 15 times, and each time an extra integer is added to the list. If you want to get a good impression of what your code does exactly, it can be useful to print something within a for loop. So, while coding it can help you to print intermediate results. However, if the for loop loops over a large amount of elements (for instance hundreds of thousands or even millions) your code may become very slow, and the large amount of printed text may not be so illuminating anymore.
Data Model¶
In text-fabric the ETCBC-database is constructed as a graph database. A graph consists of nodes, which are linked to each other with edges. The objects in the database are textual objects. These can be words, phrases, clauses, et cetera. The edges between the nodes indicate that certain objects are included in other objects (for instance, the words in a clause), but the edges can also indicate other linguistic relationships. If you want to know more about the data model, which is recommended, read the Text-Fabric documentation on the data model.
We are ready now to do the first search in the ETCBC database. We want to find out what the names of the biblical books are. We do this by looping over all the objects in the database and if we encounter a book, we print its name.
for node in N.walk(
): # N.walk() is a so-called generator. With this line of code you loop over all the nodes in the database.
if F.otype.v(node) == 'book':
print(F.book.v(node))
Genesis Exodus Leviticus Numeri Deuteronomium Josua Judices Samuel_I Samuel_II Reges_I Reges_II Jesaia Jeremia Ezechiel Hosea Joel Amos Obadia Jona Micha Nahum Habakuk Zephania Haggai Sacharia Maleachi Psalmi Iob Proverbia Ruth Canticum Ecclesiastes Threni Esther Daniel Esra Nehemia Chronica_I Chronica_II
What has happened here? In the first line the for loop loops over all the objects (nodes) in the database.
In the second line for each node is checked if its object type is 'book'. It is crucial to understand this line, especially this part: F.otype.v(node). F is the class of all node features. otype stands for object type, and v returns the value of the feature for a specific node. In other words, for every F.otype.v(node) returns the object type of every node, and with if F.otype.v(node) == 'book': it is checked if this value is equal to 'book'. If this condition is evaluated to True, in the third line the value of the feature book is returned for this node, which is the name of the book.
10. Lists and Retrieving Booknames and Lexemes¶
We use the same script as above, which produces the names of the biblical books, and store them in a list.
book_list = [] # an empty list is initialized.
for node in N.walk():
if F.otype.v(node) == 'book':
book_name = F.book.v(node)
book_list.append(
book_name) # every book name is appended to the list book_list
print(book_list) # book_list can be accessed later.
['Genesis', 'Exodus', 'Leviticus', 'Numeri', 'Deuteronomium', 'Josua', 'Judices', 'Samuel_I', 'Samuel_II', 'Reges_I', 'Reges_II', 'Jesaia', 'Jeremia', 'Ezechiel', 'Hosea', 'Joel', 'Amos', 'Obadia', 'Jona', 'Micha', 'Nahum', 'Habakuk', 'Zephania', 'Haggai', 'Sacharia', 'Maleachi', 'Psalmi', 'Iob', 'Proverbia', 'Ruth', 'Canticum', 'Ecclesiastes', 'Threni', 'Esther', 'Daniel', 'Esra', 'Nehemia', 'Chronica_I', 'Chronica_II']
You can check if a certain element is in a list.
'Genesis' in book_list
True
'Genesis' not in book_list
False
'Henoch' in book_list
False
If you want to know what the number of elements in a list is, you use the built-in function len().
print(len(book_list))
39
In the following cell we modify the code a little bit. Instead of selecting books, words are selected, and their lexemes are retrieved witht the feature lex. Each lexeme is stored in the list lex_list. The objects in the database are only abstract entities, and we can get information from them by using features that are related to the object type. lex is a feature that is characteristic of the word object.
lex_list = []
for node in N.walk():
if F.otype.v(node) == 'word':
lexeme = F.lex.v(node)
lex_list.append(lexeme)
What is the length of this list?
print(len(lex_list)) # this is a long list!
426584
We want to retrieve the first element in this list. You can do this by using an index with []. The first element in a list is retrieved with index 0, because Python is zero based.
print(lex_list[0])
B
Now we would like to find out what the first ten elements of the list are.
print(lex_list[0:9])
['B', 'R>CJT/', 'BR>[', '>LHJM/', '>T', 'H', 'CMJM/', 'W', '>T']
You recognize the first ten words in the book of Genesis.
What is the lexeme of the last word in the Hebrew Bible? The last element in a list is retrieved with index -1.
print(lex_list[-1])
<LH[
And the last ten elements? There is nothing after the colon, which means that it looks for everything from the tenth last element until the last element
print(lex_list[-10:])
['MJ', 'B', 'MN', 'KL/', '<M/', 'JHWH/', '>LHJM/', '<M', 'W', '<LH[']
We can choose any range that we want, of course.
print(lex_list[100000:100055]
) # do you see in which biblical book this fragment can be found?
['JCB[', 'B', 'BJT/', 'W', 'B', 'HLK[', 'B', 'H', 'DRK/', 'W', 'B', 'CKB[', 'W', 'B', 'QWM[', 'W', 'KTB[', '<L', 'MZWZH/', 'BJT/', 'W', 'B', 'C<R/', 'LM<N', 'RBH[', 'JWM/', 'W', 'JWM/', 'BN/', '<L', 'H', '>DMH/', '>CR', 'CB<[', 'JHWH/', 'L', '>B/', 'L', 'NTN[', 'L', 'K', 'JWM/', 'H', 'CMJM/', '<L', 'H', '>RY/', 'KJ', '>M', 'CMR[', 'CMR[', '>T', 'KL/', 'H', 'MYWH/']
11. Some Details about Lists and Strings¶
A Python list can contain elements of different data types.
varied_list = [True, 5, 5.0, 'Hebrew']
print(type(varied_list[0]))
print(type(varied_list[1]))
print(type(varied_list[2]))
print(type(varied_list[3]))
<class 'bool'> <class 'int'> <class 'float'> <class 'str'>
The following does not work.
print(type(varied_list[4]))
--------------------------------------------------------------------------- IndexError Traceback (most recent call last) <ipython-input-73-d75aa2ddf8e5> in <module> ----> 1 print(type(varied_list[4])) IndexError: list index out of range
The elements of a list can also be lists.
list_of_lists = [[1, 2], [3, 4], [5, 6]] # this is a list of lists.
# you can also say that three lists are nested in list_of_lists.
print(list_of_lists[0])
[1, 2]
We use a double index to access the individual integers.
print(list_of_lists[0][1])
2
A list comprehension is a fast and clean way to create a list.
another_list = [number**2 for number in range(12, 20)]
print(another_list)
[144, 169, 196, 225, 256, 289, 324, 361]
You can find the minimum and maximum values in a list with the functions min() and max().
print(min(another_list))
print(max(another_list))
144 361
It can be very useful to retrieve the position of a certain value in a list. You do that with the method .index().
highest_value = max(another_list)
pos_of_highest = another_list.index(highest_value)
print(pos_of_highest)
7
Here is an example of a list comprehension with strings. Look at what lower() and upper() do.
books_list = ['Genesis', 'Exodus', 'Leviticus']
book_list_lower = [book.lower() for book in books_list]
print(book_list_lower)
['genesis', 'exodus', 'leviticus']
book_list_upper = [book.upper() for book in books_list]
print(book_list_upper)
['GENESIS', 'EXODUS', 'LEVITICUS']
Often you need to make slices of a string.
book_string = 'Genesis'
If you want to retrieve the first character of a string, you use the index 0.
print(book_string[0])
G
And if you need the first three character, you use the index 0:3.
print(book_string[0:3])
Gen
If you want to know the last character, the index is -1.
print(book_string[-1])
s
And finally, if you want to know the last three letters, you use -3: .
print(book_string[-3:])
sis
12. Dictionaries and Counting Object Types¶
Which object types are there in the ETCBC database and how many of each of them? This is a problem that is slightly more difficult. We will walk through all the nodes again, but we have to keep track of all of them at the same time. To be able to do this, we introduce a new data type, the dictionary.
A dictionary is a structure which contains key-value pairs. You can recognize a dictionary by the curly brackets. A dictionary is initialized as follows.
geo_dict = {
'Netherlands': 'Amsterdam',
'Germany': 'Berlin',
'Belgium': 'Brussels',
'Italy': 'Rome'
}
# the dict geo_dict is populated manually. An empty dict would be initialized with:
# geo_dict = {}
# or: geo_dict = dict()
The geo_dict contains four keys, 'Netherlands', 'Belgium','Germany', and 'Italy', and four values. Between key and value you see a colon, and the key:value pairs are separated by comma's. How many elements does this dictionary contain?
geo_dict_len = len(geo_dict)
print(geo_dict_len)
4
We can retrieve the value of a specific key as follows.
print(geo_dict['Netherlands']) # returns the value of the key 'Netherlands'.
Amsterdam
You can add new key:value pairs to a dictionary.
geo_dict['USA'] = 'Baton Rouge'
print(geo_dict)
{'Netherlands': 'Amsterdam', 'Germany': 'Berlin', 'Belgium': 'Brussels', 'Italy': 'Rome', 'USA': 'Baton Rouge'}
If you want to iterate over all the keys, you use .keys() .
for country in geo_dict.keys():
print(geo_dict[country])
Amsterdam Berlin Brussels Rome Baton Rouge
A specific key can only occur once in a dictionary, it's keys are unique. What happens if we add an existing key with a new value?
geo_dict['USA'] = 'Amsterdam'
print(geo_dict)
{'Netherlands': 'Amsterdam', 'Germany': 'Berlin', 'Belgium': 'Brussels', 'Italy': 'Rome', 'USA': 'Amsterdam'}
You see the old value is overwritten.
There is no order in a dictionary. If you want to get the capitals in a certain order, you need an alternative solution, for instance an iteration over an ordered structure like a list.
for country in ['Netherlands', 'Germany', 'Belgium', 'Italy']:
print(geo_dict[country]) # returns capitals in alphabetical order
Amsterdam Berlin Brussels Rome
You can use a dictionary to count elements in a list.
letter_list = ['a', 'b', 'c', 'a', 'b', 'c', 'b', 'b', 'b']
let_count_dict = {}
for letter in letter_list:
if letter in let_count_dict:
let_count_dict[letter] += 1
else:
let_count_dict[letter] = 0
let_count_dict[letter] += 1
print(let_count_dict)
{'a': 2, 'b': 5, 'c': 2}
You can make this code slightly shorter by using the defaultdict() from the collections library. A library is a package which contains a number of functions. You get access to these functions with the import statement. Many libraries need to be downloaded an installed before you can use them.
import collections
let_default_dict = collections.defaultdict(int)
for letter in letter_list:
let_default_dict[letter] += 1
print(let_default_dict)
defaultdict(<class 'int'>, {'a': 2, 'b': 5, 'c': 2})
Or you can make the code even shorter with Counter(), also from the collections library.
let_counter_dict = collections.Counter(letter_list)
print(let_counter_dict)
Counter({'b': 5, 'a': 2, 'c': 2})
You can also use Counter() to count the characters in a string.
random_string = 'ajskddhcjcjfnfn djddllk;xlkkdjn'
let_counter_dict2 = collections.Counter(random_string)
print(let_counter_dict2)
Counter({'d': 6, 'j': 5, 'k': 4, 'n': 3, 'l': 3, 'c': 2, 'f': 2, ' ': 2, 'a': 1, 's': 1, 'h': 1, ';': 1, 'x': 1})
Now we return to text-fabric. Which object types are there in the ETCBC database and how many are there of each? In the following cell they are counted. The total number of objects is called n. The different types of objects are counted in the dictionary called 'object_types'. This is a defaultdict() from the collections module. Using the defaultdict instaed of an ordinary dictionary has the advantage that new keys in the dictionary do not need to be initialized explicitly.
n = 0
object_types = collections.defaultdict(int)
for node in N.walk():
n += 1
object_types[F.otype.v(node)] += 1
print(n, object_types)
1446799 defaultdict(<class 'int'>, {'book': 39, 'chapter': 929, 'verse': 23213, 'sentence': 63727, 'sentence_atom': 64525, 'clause': 88121, 'clause_atom': 90688, 'half_verse': 45180, 'phrase': 253207, 'phrase_atom': 267541, 'lex': 9233, 'word': 426584, 'subphrase': 113812})
With for node in N.walk(): you walk through all the nodes (or objects) in the database. This script will add 1 to the variable n every time it sees a new node. The next line of code is a bit more complex. Of every node, it asks what kind of object it is using the feature "otype". Note that this feature does not need to be initialized when you import Text_Fabric.
When object_types is initialized it is still an empty dictionary. Once it encounters the first node, it checks the object-type, adds that object-type to the dictionary and adds 1 to its initial value 0. In F.otype.v(), F is the class of object features, which is followed by the name of the feature. This is followed by v, which stands for the value of the feature. The values for the feature otype are word, clause, sentence, and so on.
Compare print() with pprint() from the pprint module. It prints a dictionary in a clear way in alphabetical order.
pp.pprint(object_types)
defaultdict(<class 'int'>,
{'book': 39,
'chapter': 929,
'clause': 88121,
'clause_atom': 90688,
'half_verse': 45180,
'lex': 9233,
'phrase': 253207,
'phrase_atom': 267541,
'sentence': 63727,
'sentence_atom': 64525,
'subphrase': 113812,
'verse': 23213,
'word': 426584})
The result is clear, the database contains 39 books, 929 chapters, and so on.
If we would not have used the defaultdict(), the script would have looked like this:
n = 0
object_types = {}
for node in N.walk():
n += 1
if F.otype.v(node) in object_types:
object_types[F.otype.v(node)] += 1
else:
object_types[F.otype.v(node)] = 1
# the object-type has to be initialized
print(n, object_types)
1446799 {'book': 39, 'chapter': 929, 'verse': 23213, 'sentence': 63727, 'sentence_atom': 64525, 'clause': 88121, 'clause_atom': 90688, 'half_verse': 45180, 'phrase': 253207, 'phrase_atom': 267541, 'lex': 9233, 'word': 426584, 'subphrase': 113812}
There is a more efficient way of walking through the nodes. In general you do not need information from all the objects, but only from one specific object-type, for instance words. If this is the case, you do the following:
word_count = 0
for word in F.otype.s('word'): # now you walk through the word nodes only. You can do this with all the object types.
word_count += 1
print(word_count)
426584
In previous examples you have seen that dictionaries are useful if you want to count things, for instance object types. It becomes a bit more difficult if you want to count the object types in each book of the Hebrew Bible. How many words, clauses, sentences, and so on can be found in each book? We solve this problem by using embedded dictionaries.
obj_per_book_dict = collections.defaultdict(lambda: collections.defaultdict(
int)) #we do not discuss the syntax of lambda here
for node in N.walk():
where = T.sectionFromNode(node)
book = where[0] # now we know the book
obj_type = F.otype.v(node) #now we know the object type
obj_per_book_dict[book][obj_type] += 1
pp.pprint(obj_per_book_dict)
defaultdict(<function <lambda> at 0x0000013D100DCC18>,
{'1_Chronicles': defaultdict(<class 'int'>,
{'book': 1,
'chapter': 29,
'clause': 2514,
'clause_atom': 2577,
'half_verse': 1609,
'lex': 515,
'phrase': 7189,
'phrase_atom': 8336,
'sentence': 1856,
'sentence_atom': 1891,
'subphrase': 5828,
'verse': 943,
'word': 15564}),
'1_Kings': defaultdict(<class 'int'>,
{'book': 1,
'chapter': 22,
'clause': 3596,
'clause_atom': 3701,
'half_verse': 1593,
'lex': 233,
'phrase': 10684,
'phrase_atom': 11578,
'sentence': 2512,
'sentence_atom': 2535,
'subphrase': 4686,
'verse': 817,
'word': 18685}),
'1_Samuel': defaultdict(<class 'int'>,
{'book': 1,
'chapter': 31,
'clause': 4012,
'clause_atom': 4079,
'half_verse': 1608,
'lex': 244,
'phrase': 12194,
'phrase_atom': 12612,
'sentence': 3124,
'sentence_atom': 3131,
'subphrase': 3786,
'verse': 811,
'word': 18929}),
'2_Chronicles': defaultdict(<class 'int'>,
{'book': 1,
'chapter': 36,
'clause': 3317,
'clause_atom': 3439,
'half_verse': 1599,
'lex': 67,
'phrase': 10155,
'phrase_atom': 11144,
'sentence': 2244,
'sentence_atom': 2271,
'subphrase': 6146,
'verse': 822,
'word': 19764}),
'2_Kings': defaultdict(<class 'int'>,
{'book': 1,
'chapter': 25,
'clause': 3400,
'clause_atom': 3506,
'half_verse': 1425,
'lex': 247,
'phrase': 10024,
'phrase_atom': 10832,
'sentence': 2530,
'sentence_atom': 2544,
'subphrase': 4672,
'verse': 719,
'word': 17307}),
'2_Samuel': defaultdict(<class 'int'>,
{'book': 1,
'chapter': 24,
'clause': 3185,
'clause_atom': 3253,
'half_verse': 1370,
'lex': 274,
'phrase': 9585,
'phrase_atom': 10181,
'sentence': 2406,
'sentence_atom': 2418,
'subphrase': 3398,
'verse': 695,
'word': 15612}),
'Amos': defaultdict(<class 'int'>,
{'book': 1,
'chapter': 9,
'clause': 639,
'clause_atom': 647,
'half_verse': 288,
'lex': 35,
'phrase': 1849,
'phrase_atom': 1915,
'sentence': 451,
'sentence_atom': 457,
'subphrase': 642,
'verse': 146,
'word': 2780}),
'Daniel': defaultdict(<class 'int'>,
{'book': 1,
'chapter': 12,
'clause': 1732,
'clause_atom': 1817,
'half_verse': 704,
'lex': 579,
'phrase': 5074,
'phrase_atom': 5295,
'sentence': 1155,
'sentence_atom': 1164,
'subphrase': 2126,
'verse': 357,
'word': 8072}),
'Deuteronomy': defaultdict(<class 'int'>,
{'book': 1,
'chapter': 34,
'clause': 3859,
'clause_atom': 4012,
'half_verse': 1867,
'lex': 323,
'phrase': 11542,
'phrase_atom': 12310,
'sentence': 2354,
'sentence_atom': 2379,
'subphrase': 5046,
'verse': 959,
'word': 20127}),
'Ecclesiastes': defaultdict(<class 'int'>,
{'book': 1,
'chapter': 12,
'clause': 998,
'clause_atom': 1024,
'half_verse': 425,
'lex': 52,
'phrase': 2722,
'phrase_atom': 2772,
'sentence': 575,
'sentence_atom': 593,
'subphrase': 810,
'verse': 222,
'word': 4233}),
'Esther': defaultdict(<class 'int'>,
{'book': 1,
'chapter': 10,
'clause': 733,
'clause_atom': 785,
'half_verse': 324,
'lex': 80,
'phrase': 2291,
'phrase_atom': 2502,
'sentence': 434,
'sentence_atom': 451,
'subphrase': 1356,
'verse': 167,
'word': 4621}),
'Exodus': defaultdict(<class 'int'>,
{'book': 1,
'chapter': 40,
'clause': 4326,
'clause_atom': 4454,
'half_verse': 2358,
'lex': 633,
'phrase': 13238,
'phrase_atom': 13784,
'sentence': 3227,
'sentence_atom': 3262,
'subphrase': 6998,
'verse': 1213,
'word': 23748}),
'Ezekiel': defaultdict(<class 'int'>,
{'book': 1,
'chapter': 48,
'clause': 5534,
'clause_atom': 5683,
'half_verse': 2477,
'lex': 286,
'phrase': 15801,
'phrase_atom': 16418,
'sentence': 4094,
'sentence_atom': 4150,
'subphrase': 7400,
For information about lambda, read the Python documentation.
13. More Features and Tuples¶
If you want to know which range of slots is used for one specific object, you use sInterval.
print(F.otype.sInterval('word'))
print(F.otype.sInterval('phrase'))
print(F.otype.sInterval('clause'))
(1, 426584) (651542, 904748) (427553, 515673)
We have seen the word feature lex, but there are more features, such as sp, part of speech.
for word_slot in range(1, 11):
print(F.sp.v(word_slot))
prep subs verb subs prep art subs conj prep art
We saw that the range of phrases is (605144, 858317). What are the phrase types and phrase functions of the first ten phrases within this range?
for phr in range(605144, 605153):
print(F.typ.v(phr), F.function.v(phr))
InfC None ZIm0 None ZYq0 None WayX None InfC None Defc None NmCl None ZQt0 None NmCl None
In which book can you find word slot 100000? To be able to locate it, use T.sectionfromNode(), which returns a tuple with the book (by default in English), chapter and verse.
T.sectionFromNode(100000)
('Deuteronomy', 11, 19)
If you need the name of the book in a different language, you use the argument "lang".
T.sectionFromNode(100000, lang='fr')
('Deutéronome', 11, 19)
T.sectionFromNode returns a tuple. A tuple is also an ordered sequence of elements, but its values are immutable. It elements can be indexed with [] and a tuple can be recognized by the parentheses that embrace it.
this_tuple = (2, 4, 4, 5)
print(this_tuple[3])
5
T.sectionFromNode() returns a tuple of length 3.
print(len(T.sectionFromNode(10)))
3
The tuple starts with the biblical book of a node.
print(T.sectionFromNode(10)[0])
Genesis
Another way of accessing the elements in the tuple is by using tuple unpacking. As already said, T.sectionFromNode() returns a tuple with three elements, which are book, chapter and verse.
book, chapter, verse = T.sectionFromNode(
10
) # each element on the left hand side corresponds to an element in the tuple.
print(book)
print(chapter)
print(verse)
Genesis 1 1
We have seen the feature "lex", which is a word feature. Other important word features are "sp" (part of speech), "gn" (gender), "nu" (number), "vt" (verbal tense), "vs" (verbal stem). The latter two have a value only if the word is a verb. Suppose you want to know the values of all of these features of the first 10 words of Genesis, we do this:
for word in F.otype.s('word'):
if word < 11: # an alternative way of finding the first 10 words
print(F.lex.v(word), F.sp.v(word), F.gn.v(word), F.nu.v(word),
F.vt.v(word), F.vs.v(word))
B prep NA NA NA NA R>CJT/ subs f sg NA NA BR>[ verb m sg perf qal >LHJM/ subs m pl NA NA >T prep NA NA NA NA H art NA NA NA NA CMJM/ subs m pl NA NA W conj NA NA NA NA >T prep NA NA NA NA H art NA NA NA NA
If a feature has no value in the case of a specific word, NA is returned.
14. Sets and Counting the Number of Unique Lexemes in the Hebrew Bible¶
The set is another basic data type in Python. In contrast to the list it contains unique elements only without order. You can use a set if you want to know which unique elements there are in a large mount of data. First we look at a simple example.
integer_set = set() # an empty set is initialized
print(integer_set) # prints the empty set
set()
With .add() you can add an element to a set. In this case we add the integer 5.
integer_set.add(5)
print(integer_set)
{5}
Now we add another integer.
integer_set.add(27)
print(integer_set)
{27, 5}
Now we try to add 5 again.
integer_set.add(5)
print(integer_set)
{27, 5}
Now you see that the set still contains 27 and 5 only once, because the set becomes bigger only if a new unique element is added.
In the following cell we investigate how many unique lexemes occur in the Hebrew parts of the Hebrew Bible.
lex_set = set()
for word in F.otype.s('word'):
if F.language.v(word) == 'hbo':
lex_set.add(F.lex.v(word))
#print(lex_set) #uncomment this line if you want to see the whole set of lexemes. You will see that there is no specific order
print(len(lex_set)) # returns the number of elements in the set
0
Use a Set or a List?¶
You could have solved the problem of counting the unique lexemes in the Hebrew Bible with a list as well, by simply appending a lexeme to a list if it does not occur in the list already. The code would be only one line longer, but there is another difference, and that is the time it takes to do the calculation. Let us compare the time it would take using a list and a set.
We start with the list-implementation. First we import the class datetime from the module datetime.
from datetime import datetime
startTime = datetime.now(
) # the variable startTime saves the date and the time of the start of the execution of the cell
lex_list = []
for word in F.otype.s('word'):
if F.language.v(word) == 'hbo':
if not F.lex.v(
word
) in lex_list: # this is the extra line of code. It checks whether a lexeme occurs in the list already.
lex_list.append(F.lex.v(word))
print(len(lex_list))
print(
datetime.now() -
startTime) # again, the time is measured and the starttime is subtracted.
0 0:00:00.108708
And now we look at the set-implementation again and measure how long it takes to execute the code.
startTime = datetime.now()
lex_set = set()
for word in F.otype.s('word'):
if F.language.v(word) == 'hbo':
lex_set.add(F.lex.v(word))
print(len(lex_set))
print(datetime.now() - startTime)
0 0:00:00.106714
It is clear that the set-implementation is much faster than the list-implementation. This is the case because checking whether a certain lexeme occurs already in the list takes more time when the list becomes longer.
15. Who Is Eating? Retrieving the Subject of a Predicate¶
Very often you may not only interested be interested in the features of specific objects, but also of other objects in its environment. Suppose you are interested in eating habits in the Hebrew Bible. You decide to search for cases of the verb >KL[ (to eat), used as the predicate of a clause, and you are interested in those cases in which that clause has an explicit subject. You would like to know all the lexemes in the subject.
The strategy is as follows. Fist we search for all cases of >KL[. From the word >KL[ we move upward to the phrase in which it occurs, using L.u(). Of this phrase it is checked if it is a predicate. We move upward again, to the level of the clause, and in the clause we check if there is an explicit subject, by moving downwards to the phrases in the clause, which is done with L.d().
The L in L.u() and L.d() stands for Layer, and u and d stand for up and down. Going up and down between linguistic layers is very important if you want to get access to various elements of linguistic units like clauses. In the script below we use L four times. In the figure below the use of L is schematically pictured.
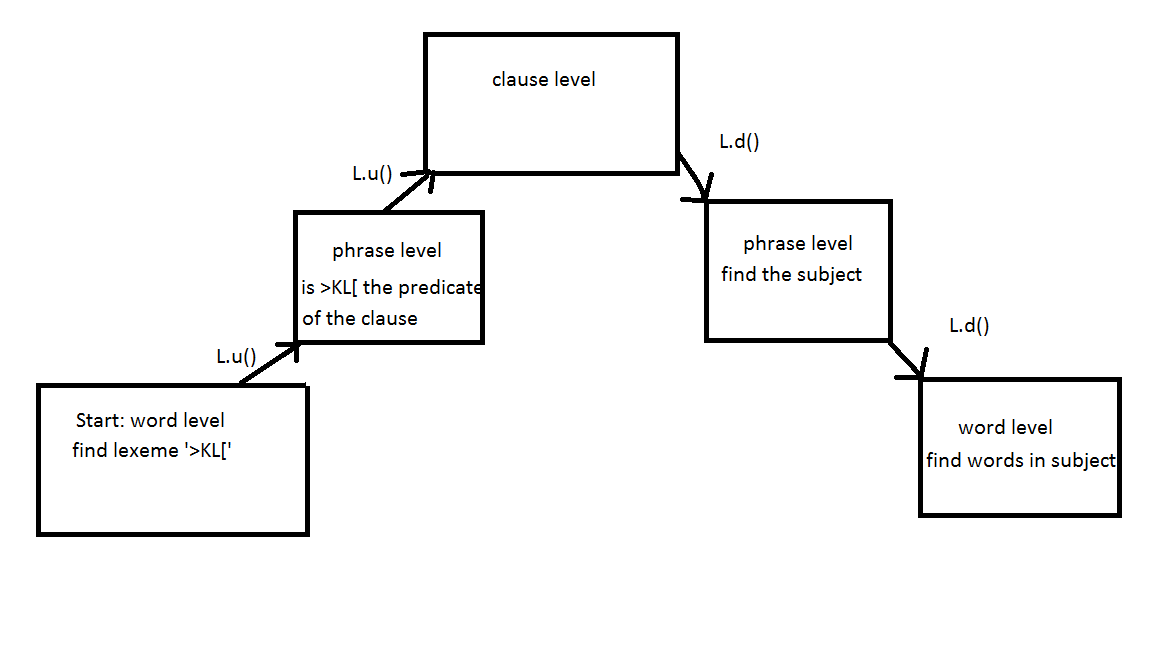
for word in F.otype.s('word'):
if F.lex.v(word) == '>KL[':
phrase = L.u(word, 'phrase')[0] # L.u() returns a tuple.
# We want to know the id of the phrase, so we add the index [0], which is the first value of the tuple.
# now we check if the phrase is a predicate, we chech also for cases in a nominal predicate (PreC),
# and predicates with an object suffix (PreO):
if F.function.v(phrase) in {'Pred', 'PreC', 'PreO'}:
# we move upwards to the clause
clause = L.u(phrase, 'clause')[0]
# and we go down again to all the phrases in that clause
phrases = L.d(clause, 'phrase')
# we loop over all the phrases to check if there is an explicit subject:
for phr in phrases:
if F.function.v(phr) == 'Subj':
# we create an empty list, in which all lexemes are stored.
lex_list = []
# we move down to the lexemes of the subject:
words = L.d(phr, 'word')
for word in words:
lex_list.append(F.lex.v(word))
print(lex_list)
['H', 'N<R/'] ['XRB=/'] ['BN/', 'JFR>L/'] ['XJH/', 'R</'] ['XJH/', 'R</'] ['HW>'] ['H', '<WP/'] ['H', '<WP/'] ['H', 'PRH/', 'R</', 'H', 'MR>H/', 'W', 'DQ/', 'H', 'BFR/'] ['H', 'PRH/', 'H', 'RQ=/', 'W', 'H', 'R</'] ['H', '>JC/'] ['KL/', 'BN/', 'NKR/'] ['TWCB/', 'W', 'FKJR/'] ['KL/', '<RL/'] ['XMY/'] ['BN/', 'JFR>L/'] ['>T', 'BFR/'] ['GDJC/', '>W', 'H', 'QMH/', '>W', 'H', 'FDH/'] ['>BJWN/', '<M/'] ['XJH/', 'H', 'FDH/'] ['MR>H/', 'KBWD/', 'JHWH/'] ['>HRN/', 'W', 'BN/'] ['ZR/'] ['H', '>C/'] ['>HRN/', 'W', 'BN/'] ['KL/', 'ZKR=/', 'B', 'BN/', '>HRN/'] ['H', 'KHN/'] ['KL/', 'ZKR=/', 'B', 'H', 'KHN/'] ['KL/', 'XV>T/'] ['KL/', 'ZKR=/', 'B', 'H', 'KHN/'] ['BFR/', 'ZBX/', 'TWDH/', 'CLM/'] ['H', 'BFR/'] ['KL/', 'VHR/'] ['>HRN/', 'W', 'BN/'] ['>TH', 'W', 'BN/', 'W', 'BT/', '>T=='] ['KL/', 'NPC/', 'MN'] ['H', 'GR/'] ['>JC/', '>JC/', 'MN', 'ZR</', '>HRN/'] ['KL/', 'ZR/'] ['TWCB/', 'KHN/', 'W', 'FKJR/'] ['HW>'] ['HM'] ['HJ>'] ['BT/', 'KHN/'] ['KL/', 'ZR/'] ['>JB['] ['>RY/', '>JB['] ['MJ'] ['MJ'] ['XYJ/', 'BFR/'] ['KL/', 'ZKR=/'] ['KL/', 'VHR/', 'B', 'BJT/'] ['KL/', 'VHR/', 'B', 'BJT/'] ['>TM', 'W', 'BJT/'] ['H', '<M/'] ['H', '>C/'] ['HW>'] ['H', '>C/', 'H', 'GDWL/', 'H', 'Z>T'] ['HW>'] ['H', 'VM>/', 'W', 'H', 'VHR/'] ['>TH', 'W', 'BN/', 'W', 'BT/', 'W', '<BD/', 'W', '>MH/', 'W', 'H', 'LWJ/'] ['>T', 'H', 'YBJ=/', 'W', '>T', 'H', '>JL/'] ['H', 'VM>/', 'W', 'H', 'VHR/'] ['>TH', 'W', 'BJT/'] ['<M/'] ['H', 'TWL<T/'] ['XRB/'] ['>TM'] ['CNJM/'] ['CNJM/'] ['H', '<M/'] ['H', 'QR>['] ['C>WL=/'] ['H', '<M/'] ['H', '<M/'] ['XRB/'] ['>TH'] ['MPJBCT/', 'BN/', '>DWN/'] ['MPJBCT/'] ['HW>'] ['H', 'XRB/'] ['H', 'N<R/'] ['H', 'XRB/'] ['>C/', 'MN', 'PH/'] ['H', '>RJH/'] ['H', 'KLB/'] ['<WP/', 'H', 'CMJM/'] ['H', 'KLB/'] ['<WP/', 'H', 'CMJM/'] ['HJ>', 'W', 'HW>', 'W', 'BJT/'] ['H', 'KLB/'] ['H', 'KLB/'] ['<WP/', 'H', 'CMJM/'] ['H', 'KLB/'] ['H', 'KLB/'] ['ZR/'] ['GWR['] ['LCWN/', '>C/'] ['KL/'] ['>RJH/'] ['>LH=/'] ['>P', '>C/', 'YR=/'] ['H', '>LP/', 'W', 'H', '<JR=/'] ['LCWN/'] ['XRB/', 'L>', '>DM/'] ['<C/'] ['<C/'] ['SS/'] ['<BD/'] ['>XR=/'] ['>RJH/'] ['XRB/'] ['H', 'BCT/'] ['BN/', 'W', 'BT/'] ['XRB/', 'L', 'JHWH/'] ['KL/', '>KL['] ['>B/'] ['H', 'BSR/'] ['XRB/'] ['XRB/'] ['KL/', 'MY>['] ['MLK/', '>CWR/'] ['BN/', 'JFR>L/'] ['>B/'] ['BN/'] ['R<B/', 'W', 'DBR=/'] ['H', '>C/'] ['>C/'] ['H', '>C/'] ['>B/'] ['>C/'] ['>XRJT/'] ['HMH'] ['HJ>'] ['XJH/', 'H', '>RY/'] ['>T='] ['>TJQ/'] ['H', 'KHN/'] ['HMH'] ['H', 'KHN/'] ['XJH/', 'H', 'FDH/'] ['XDC=/'] ['ZR/'] ['H', '>RBH/'] ['H', 'JLQ/'] ['H', 'XSJL/'] ['>C/'] ['>C/'] ['>C/'] ['H', '>RBH/', 'H', 'JLQ/', 'W', 'H', 'XSJL/', 'W', 'H', 'GZM/', 'XJL/', 'H', 'GDWL/'] ['H', 'GZM/'] ['>TH'] ['XRB/'] ['>C/'] ['>C/'] ['KL/', 'H', '>RY/'] ['KL/', 'H', '>RY/'] ['HJ>'] ['>C/'] ['>KL[', '<M/'] ['>C/'] ['>C/'] ['<NW/'] ['>C/'] ['>KL[', '<M/'] ['QN>H/', 'BJT/'] ['>JC/'] ['>C/'] ['BN/', 'W', 'BT/'] ['BN/', 'W', 'BT/'] ['R<B=/'] ['TPL=/'] ['<C/'] ['>C/'] ['BKR/', 'MWT/'] ['>C/'] ['>C/'] ['>XR=/'] ['JTWM/'] ['BHMWT/'] ['YDJQ/'] ['>HB['] ['NYR[', 'T>NH/'] ['BN/', 'NCR/'] ['B<Z/'] ['MJ'] ['>JC/', 'NKRJ/'] ['FR/'] ['FR/'] ['>CH/'] ['QRY/', 'DJ', 'JHWDJ/'] ['BN/', 'JFR>L/', 'W', 'KL/'] ['C<R/'] ['C<R/'] ['>NJ', 'W', '>X/']
You can use T.nodeFromSection() to find out which node corresponds in a specific piece of text. You can print the text of a sequence of words with T.text().
exod_1_1 = T.nodeFromSection(('Exodus', 1, 1))
words_exod_1_1 = L.d(exod_1_1, 'word') # retrieve the word nodes with L.d()
print(T.text(words_exod_1_1))
וְאֵ֗לֶּה שְׁמֹות֙ בְּנֵ֣י יִשְׂרָאֵ֔ל הַבָּאִ֖ים מִצְרָ֑יְמָה אֵ֣ת יַעֲקֹ֔ב אִ֥ישׁ וּבֵיתֹ֖ו בָּֽאוּ׃
The following is nearly the same, but now we print the whole chapter
exod_1 = T.nodeFromSection((
'Exodus',
1,
))
words_exod_1 = L.d(exod_1, 'word') # retrieve the word nodes with L.d()
print(T.text(words_exod_1))
וְאֵ֗לֶּה שְׁמֹות֙ בְּנֵ֣י יִשְׂרָאֵ֔ל הַבָּאִ֖ים מִצְרָ֑יְמָה אֵ֣ת יַעֲקֹ֔ב אִ֥ישׁ וּבֵיתֹ֖ו בָּֽאוּ׃ רְאוּבֵ֣ן שִׁמְעֹ֔ון לֵוִ֖י וִיהוּדָֽה׃ יִשָּׂשכָ֥ר זְבוּלֻ֖ן וּבְנְיָמִֽן׃ דָּ֥ן וְנַפְתָּלִ֖י גָּ֥ד וְאָשֵֽׁר׃ וַֽיְהִ֗י כָּל־נֶ֛פֶשׁ יֹצְאֵ֥י יֶֽרֶךְ־יַעֲקֹ֖ב שִׁבְעִ֣ים נָ֑פֶשׁ וְיֹוסֵ֖ף הָיָ֥ה בְמִצְרָֽיִם׃ וַיָּ֤מָת יֹוסֵף֙ וְכָל־אֶחָ֔יו וְכֹ֖ל הַדֹּ֥ור הַהֽוּא׃ וּבְנֵ֣י יִשְׂרָאֵ֗ל פָּר֧וּ וַֽיִּשְׁרְצ֛וּ וַיִּרְבּ֥וּ וַיַּֽעַצְמ֖וּ בִּמְאֹ֣ד מְאֹ֑ד וַתִּמָּלֵ֥א הָאָ֖רֶץ אֹתָֽם׃ פ וַיָּ֥קָם מֶֽלֶךְ־חָדָ֖שׁ עַל־מִצְרָ֑יִם אֲשֶׁ֥ר לֹֽא־יָדַ֖ע אֶת־יֹוסֵֽף׃ וַיֹּ֖אמֶר אֶל־עַמֹּ֑ו הִנֵּ֗ה עַ֚ם בְּנֵ֣י יִשְׂרָאֵ֔ל רַ֥ב וְעָצ֖וּם מִמֶּֽנּוּ׃ הָ֥בָה נִֽתְחַכְּמָ֖ה לֹ֑ו פֶּן־יִרְבֶּ֗ה וְהָיָ֞ה כִּֽי־תִקְרֶ֤אנָה מִלְחָמָה֙ וְנֹוסַ֤ף גַּם־הוּא֙ עַל־שֹׂ֣נְאֵ֔ינוּ וְנִלְחַם־בָּ֖נוּ וְעָלָ֥ה מִן־הָאָֽרֶץ׃ וַיָּשִׂ֤ימוּ עָלָיו֙ שָׂרֵ֣י מִסִּ֔ים לְמַ֥עַן עַנֹּתֹ֖ו בְּסִבְלֹתָ֑ם וַיִּ֜בֶן עָרֵ֤י מִסְכְּנֹות֙ לְפַרְעֹ֔ה אֶת־פִּתֹ֖ם וְאֶת־רַעַמְסֵֽס׃ וְכַאֲשֶׁר֙ יְעַנּ֣וּ אֹתֹ֔ו כֵּ֥ן יִרְבֶּ֖ה וְכֵ֣ן יִפְרֹ֑ץ וַיָּקֻ֕צוּ מִפְּנֵ֖י בְּנֵ֥י יִשְׂרָאֵֽל׃ וַיַּעֲבִ֧דוּ מִצְרַ֛יִם אֶת־בְּנֵ֥י יִשְׂרָאֵ֖ל בְּפָֽרֶךְ׃ וַיְמָרְר֨וּ אֶת־חַיֵּיהֶ֜ם בַּעֲבֹדָ֣ה קָשָׁ֗ה בְּחֹ֨מֶר֙ וּבִלְבֵנִ֔ים וּבְכָל־עֲבֹדָ֖ה בַּשָּׂדֶ֑ה אֵ֚ת כָּל־עֲבֹ֣דָתָ֔ם אֲשֶׁר־עָבְד֥וּ בָהֶ֖ם בְּפָֽרֶךְ׃ וַיֹּ֨אמֶר֙ מֶ֣לֶךְ מִצְרַ֔יִם לַֽמְיַלְּדֹ֖ת הָֽעִבְרִיֹּ֑ת אֲשֶׁ֨ר שֵׁ֤ם הָֽאַחַת֙ שִׁפְרָ֔ה וְשֵׁ֥ם הַשֵּׁנִ֖ית פּוּעָֽה׃ וַיֹּ֗אמֶר בְּיַלֶּדְכֶן֙ אֶת־הָֽעִבְרִיֹּ֔ות וּרְאִיתֶ֖ן עַל־הָאָבְנָ֑יִם אִם־בֵּ֥ן הוּא֙ וַהֲמִתֶּ֣ן אֹתֹ֔ו וְאִם־בַּ֥ת הִ֖יא וָחָֽיָה׃ וַתִּירֶ֤אןָ הַֽמְיַלְּדֹת֙ אֶת־הָ֣אֱלֹהִ֔ים וְלֹ֣א עָשׂ֔וּ כַּאֲשֶׁ֛ר דִּבֶּ֥ר אֲלֵיהֶ֖ן מֶ֣לֶךְ מִצְרָ֑יִם וַתְּחַיֶּ֖יןָ אֶת־הַיְלָדִֽים׃ וַיִּקְרָ֤א מֶֽלֶךְ־מִצְרַ֨יִם֙ לַֽמְיַלְּדֹ֔ת וַיֹּ֣אמֶר לָהֶ֔ן מַדּ֥וּעַ עֲשִׂיתֶ֖ן הַדָּבָ֣ר הַזֶּ֑ה וַתְּחַיֶּ֖יןָ אֶת־הַיְלָדִֽים׃ וַתֹּאמַ֤רְןָ הַֽמְיַלְּדֹת֙ אֶל־פַּרְעֹ֔ה כִּ֣י לֹ֧א כַנָּשִׁ֛ים הַמִּצְרִיֹּ֖ת הָֽעִבְרִיֹּ֑ת כִּֽי־חָיֹ֣ות הֵ֔נָּה בְּטֶ֨רֶם תָּבֹ֧וא אֲלֵהֶ֛ן הַמְיַלֶּ֖דֶת וְיָלָֽדוּ׃ וַיֵּ֥יטֶב אֱלֹהִ֖ים לַֽמְיַלְּדֹ֑ת וַיִּ֧רֶב הָעָ֛ם וַיַּֽעַצְמ֖וּ מְאֹֽד׃ וַיְהִ֕י כִּֽי־יָֽרְא֥וּ הַֽמְיַלְּדֹ֖ת אֶת־הָאֱלֹהִ֑ים וַיַּ֥עַשׂ לָהֶ֖ם בָּתִּֽים׃ וַיְצַ֣ו פַּרְעֹ֔ה לְכָל־עַמֹּ֖ו לֵאמֹ֑ר כָּל־הַבֵּ֣ן הַיִּלֹּ֗וד הַיְאֹ֨רָה֙ תַּשְׁלִיכֻ֔הוּ וְכָל־הַבַּ֖ת תְּחַיּֽוּן׃ ס
16. Making Structured Datasets with Text-Fabric, a Standard Recipe¶
In the following cells a csv file containing a number of features related to a topic of interest is created. The file is saved on the harddisk and can be processed further. The strategy of making this file is as follows. The features of an observation are stored in a list, and all these lists are stored in a dictionary:
{id1 : [feat11, feat12, feat13, ...],
id2 : [feat21, feat22, feat23, ...],
id3 : [feat31, feat32, feat33, ...],
...
...
}
The keys of this dictionary have to be unique of course, so in general it is convenient to use the tf-id of the object under investigation as key. The dictionary does not remember the order of the id's, so another structure is needed in which this order is remembered. We use a list to do this. The id's are added to the list in the canonical order in which our observations occur:
[id1, id2, id3, ...]
After all the observations are stored in the list and the dictionary the csv file is made by looping over the id's in the list, then for each id the feature list is fetched in the dictionary and added to the csv.
We will first show this with a very simple example, in which we make a csv file which contains all the places where the name JHWH occurs. The csv file will contain 4 columns: slot of the lexeme JHWH/, book, chapter, verse. On every row there will be one observation of the name.
jhwh_list = []
jhwh_dict = {}
for word in F.otype.s('word'):
if F.lex.v(word) == 'JHWH/':
bo, ch, ve = T.sectionFromNode(word) # unpack the tuple!
info = [str(word), bo, str(ch), str(ve)]
jhwh_list.append(word)
jhwh_dict[word] = info
print(len(jhwh_list)) # prints total number of occurrences of the name
6828
with open(r'jhwh_data.csv', "w") as csv_file:
# it is often useful to make a header
header = ['slot', 'book', 'chapter', 'verse']
csv_file.write('{}\n'.format(','.join(header)))
for case in jhwh_list:
info = jhwh_dict[case]
# with .write() the information from info is added to the our file, but the elements in info need to be formatted first.
csv_file.write('{}\n'.format(
','.join(info))) #see below for explanation of this line
17. Join() and String Formatting¶
In the last line of the previous code cell the information in the info-list was added to the csv file. How exactly was this done?
Join()¶
First all the elements in the list were concatenated into one string with join(). join() concatenates everything in the list into one long string, and the separator is specified first. We want to make a csv file, so the comma is the natural choice, but you can use any character. Note that the list should contain only strings.
info = ['Genesis', '1', '1']
new_string = (','.join(info))
print(new_string)
Genesis,1,1
String Formatting¶
String formatting is used if you want to organize various kinds of information in a string.
t = 5 # integer
p = 'Amsterdam' # string
f = True # boolean
If you want to put these together in one string, you use the placeholders {} and separate them with a character of choice. In the example below they are separated by spaces.
'{} {} {}'.format(t, p, f)
'5 Amsterdam True'
In the cell in which the jhwh_data.csv file was made, you saw {}\n . \n is the newline. With this the next string that is added to the csv file comes on a new line.
18. Semi-structured Datasets¶
In the previous examples a so called structured dataset was made, which we saved in a csv file. The dataset is called structured, because it has a fixed format. It consists of a number of columns, and in each column you find the same kind of information for each case in the database.
You should also be able to make unstructured or semi-structured datasets. An unstructured dataset contains data that are closer to the raw data as we find them in 'nature'. An example is a picture of a Dead Sea Scroll. In a semi-structured dataset the data are structured partly. In our case you could for instance make a text file with the consonantal text of the Hebrew Bible. In the following example, a text file is made in which the biblical text is represented per verse as a sequence of lexemes, separated by spaces.
with open("lexemes.txt", "w") as lex_file:
for verse in F.otype.s('verse'):
bo, ch, ve = T.sectionFromNode(verse)
# do not forget to make strings of chapter and verse
verse_string = '{} {} {} '.format(bo, ch, ve)
words = L.d(verse, 'word')
for word in words: # this is an alternative approach to string formatting
if word != words[-1]: # if the word is not the last word,
verse_string += F.lex.v(word) #add the lexeme
verse_string += ' ' # and add a space
else: # this is the last word
verse_string += F.lex.v(word)
verse_string += '\n' # add a newline
lex_file.write(verse_string)
In the previous script a file was made that contains the text of the whole MT. If you want to make a separate file for each book, you can do the following.
def lexeme_processing(v):
"""
This function returns a string of lexemes for a verse node, which is the input.
It is identical to part of the code you have seen in the previous cell.
"""
bo, ch, ve = T.sectionFromNode(v)
verse_string = '{} {} {} '.format(bo, ch, ve)
words = L.d(verse, 'word')
for word in words:
if word != words[-1]:
verse_string += F.lex.v(word)
verse_string += ' '
else:
verse_string += F.lex.v(word)
# a new verse gets a new line.
verse_string += '\n'
return (verse_string)
# for every book a new file is created.
for book in F.otype.s('book'):
book_file = F.book.v(book) + '.txt'
with open(book_file, "w") as new_file:
verses = L.d(book, 'verse')
for verse in verses:
# here the function lexeme_processing is called
new_string = lexeme_processing(verse)
new_file.write(new_string)
19. Final Example of a Structured Dataset: the Eat-Data¶
Now we continue with the >KL[ data. On every row in the csv file we store information about one clause containing >KL[, with the following information in columns:
slot of >KL[,
book,
chapter,
verse,
verbal tense,
verbal stem,
predicate type (Pred, PreC, PreO, PreS)
lexemes of the subject, concatenated in a string, separated by underscores.
The first 6 columns contain information about the verb, the predicate type contains information about the phrase in which >KL[ occurs, and the last column contains information about the subject of the clause. It may look like a lot of work, but you will notice that it is done straightforwardly.
eat_list = []
eat_dict = {}
# this part is nearly identical to what you have already seen
for w in F.otype.s('word'):
# select the words with the right lexeme and make sure the language is Hebrew.
if F.lex.v(w) == '>KL[' and F.language.v(w) == 'hbo':
phrase = L.u(w, 'phrase')[0]
# we include cases with a subjectsuffix
if F.function.v(phrase) == 'PreS':
suffix = F.prs.v(w)
# now we collect the information needed in a list called info
bo, ch, ve = T.sectionFromNode(w)
info = [
w, bo, ch, ve,
F.vt.v(w),
F.vs.v(w),
F.function.v(phrase), suffix
]
eat_dict[w] = info
eat_list.append(w)
# the other predicate types are processed now
else:
if F.function.v(phrase) in {'Pred', 'PreC', 'PreO'}:
bo, ch, ve = T.sectionFromNode(w)
clause = L.u(phrase, 'clause')[0]
phrases = L.d(clause, 'phrase')
subject = False # we only include those cases that have an explicit subject
for phr in phrases:
if F.function.v(phr) == 'Subj':
subject = True
words = L.d(phr, 'word')
words_lex = (F.lex.v(w) for w in words)
subj_lexemes = "_".join(words_lex)
if subject: # this is the same as: if subject == True:, but it is a bit cleaner
info = [
w, bo, ch, ve,
F.vt.v(w),
F.vs.v(w),
F.function.v(phrase), subj_lexemes
]
eat_dict[w] = info
eat_list.append(w)
with open(r'eat_data.csv', "w") as csv_file:
# we make a header again
header = [
'slot', 'book', 'chapter', 'verse', 'tense', 'stem', 'predicate',
'subj_lex'
]
csv_file.write('{}\n'.format(','.join(header)))
for case in eat_list:
info_list = eat_dict[case]
line = [str(element) for element in info_list]
csv_file.write('{}\n'.format(','.join(line)))