


Loading¶
We load the Text-Fabric program and the BHSA data.
%load_ext autoreload
%autoreload 2
from tf.app import use
from util import getTfVerses, getShebanqData, compareResults, MQL_RESULTS
VERSION = "2017"
# A = use('ETCBC/bhsa', hoist=globals(), version=VERSION)
A = use("ETCBC/bhsa:clone", checkout="clone", hoist=globals(), version=VERSION)
Data: BHSA, Character table, Feature docs
Features:
BHSA = Biblia Hebraica Stuttgartensia Amstelodamensis
bookbook@ll
chapter
code
det
domain
freq_lex
function
g_cons
g_cons_utf8
g_lex
g_lex_utf8
g_word
g_word_utf8
gloss
gn
label
language
lex
lex_utf8
ls
nametype
nme
nu
number
otype
pargr
pdp
pfm
prs
prs_gn
prs_nu
prs_ps
ps
qere
qere_trailer
qere_trailer_utf8
qere_utf8
rank_lex
rela
sp
st
tab
trailer
trailer_utf8
txt
typ
uvf
vbe
vbs
verse
voc_lex
voc_lex_utf8
vs
vt
mother
omap@ll
oslots
Example 2¶
Bas Meeuse: Example 2: FJM + prep. L
[clause
[word FOCUS lex = 'FJM[']
..
[word FOCUS lex = "L"]
[word lex <> '<JN/' AND lex <> 'PNH/']
]
(verses, words) = getShebanqData(A, MQL_RESULTS, 2)
156 results in 136 verses with 294 words
query = """
clause
word lex=FJM[
< word lex=L
<: word lex#<JN/|PNH/
"""
results = A.search(query)
1.53s 155 results
N.B.: one result less than in SHEBANQ.
(tfVerses, tfWords) = getTfVerses(A, results, (1, 2))
135 verses 292 words
compareResults(A, verses, words, tfVerses, tfWords)
DIFFERENCE:
('Joshua', 8, 2)
('Joshua', 8, 12)
DIFFERENCE:
116852 = FIJM
117091 = J.@63FEM
-1
The TF results are skipping Joshua 8:2!
We expand this verse in SHEBANQ:
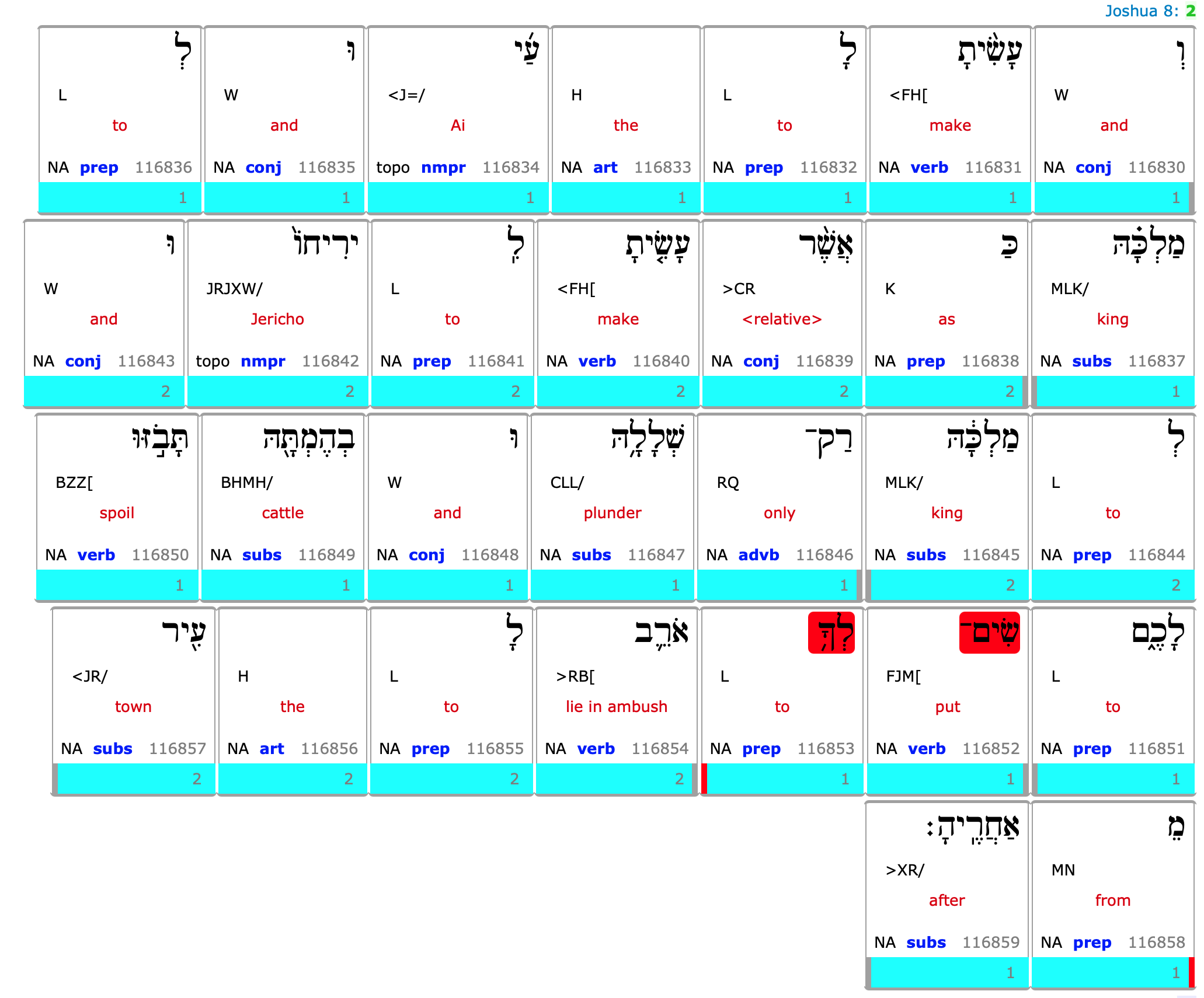
That there is a gap in the clause, right after the word L between words 116853 and 116858.
In MQL, the adjacency of things is relative to the container it is in.
If the container has a gap, the words around the gap are considered adjacent.
In this example it means that this part of the query:
[word FOCUS lex = "L"]
[word lex <> '<JN/' AND lex <> 'PNH/']
is matched by words 116853 and 116858. And the MQL query considers those two words as adjacent within the clause.
In TF-Query, adjacency between words is absolute: it is not relative to a container object.
So this part of the query
< word lex=L
<: word lex#<JN/|PNH/
is not matched by words 116853 and 116854, because 116854 is not part of the embedding clause.
The Text-Fabric notion of adjacency is more crude. The reason is that in Text-Fabric, the query does not have to be a tree, where each object has a unique immediate embedder object. There could be several embedder objects in the query, and each of the them may have different gaps, and if we had the concept of relative adjacency, our query language would need a way to express relative to which object the adjacency must be taken.
It has not, and to me it is an open question whether we should complicate search templates in that way.
Anyway, as it stands, there is no obvious workaround to get the exactly the same behaviour as the MQL query.
That said, we can try something that comes close:
We state that the L is is not immediately followed by a word that is <JN/ or PNH/.
query = """
clause
word lex=FJM[
< word lex=L
/without/
<: w3:word lex=<JN/|PNH/
/-/
"""
results2 = A.search(query)
0.78s 161 results
It turns out that we get more results than in SHEBANQ. We first count the verses and words involved in the results.
(tfVerses2, tfWords2) = getTfVerses(A, results2, (1, 2))
139 verses 302 words
compareResults(A, verses, words, tfVerses2, tfWords2)
DIFFERENCE:
('Genesis', 43, 32)
('Genesis', 27, 37)
DIFFERENCE:
24760 = J.@FI71JMW.
14288 = FAM:T.I71JW
-1
Now the situation is reversed: Genesis 27:37 is in the TF results, but skipped by SHEBANQ.
A.show(results2, condenseType="clause", start=3, end=3)
result 3
The Genesis 27:37 result has something in common with the Joshua 8:2 result in SHEBANQ that we saw above:
- the
Lhas a pronominal suffix; - the
Lis at the end of its clause atom: in Joshua 8:2 it is preceding a gap; here it is also at the end of a clause.
So it seems to be an intended result of the MQL query in both cases.
Let's make a mental shift: what is the intention of the MQL query? Here is a bit of query-exegesis, in that the query itself is the object of the exegesis.
The MQL query mentions three [word] objects, but it puts only the first two of them in FOCUS.
- it is not interested in the actual value of the third one;
- the third
[word]is constrained by a very loose restriction: it can be anything, except two specific values.
These two things point to the intended meaning of the query, namely:
find a clause with the word
FJM[, and somewhere after that the wordL,
which is not followed by either the word <JN/ or the word PNH/.
This differs subtly from what the query actually says:
find a clause with the word
FJM[, and somewhere after that the wordL,
which is followed by another word that is not <JN/ and not PNH/.
The difference is one of quantification.
More schematically, the MQL states literally:
there is a word after a that is not b and not c
But the intention is:
for each word after a it is not b and not c
MQL also has a concept of quantifier, a bit more limited than in TF: NOTEXIST.
Let's try it:
[clause
[word FOCUS lex = 'FJM[']
..
[word FOCUS lex = "L"]
NOTEXIST [word lex = '<JN/' OR lex = 'PNH/']
]
(verses2, words2) = getShebanqData(A, MQL_RESULTS, "2a")
160 results in 138 verses with 300 words
Now we have one result more in Text-Fabric than in SHEBANQ.
compareResults(A, verses2, words2, tfVerses2, tfWords2)
DIFFERENCE:
('2_Samuel', 23, 5)
('2_Samuel', 14, 7)
DIFFERENCE:
174875 = F@74M
168181 = *FWM
-1
2 Samuel 14:7 is skipped by SHEBANQ.
A.show(results2, condenseType="clause", start=58, end=58)
result 58
When we look it up in SHEBANQ we find this:
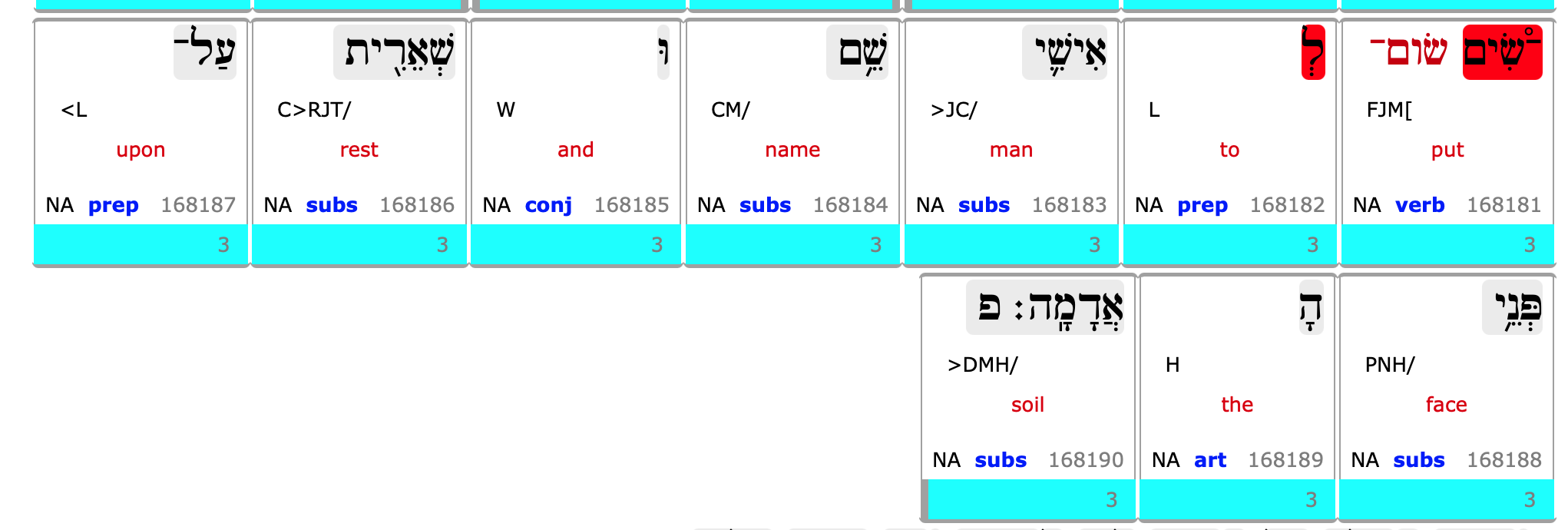
The thing here is that the forbidden word PNH/ turns up later in the clause, at 168188.
It turns out that the NOTEXIST operator in MQL quantifies over all words that follow from that position.
If NOTEXIST [word properties] meant that there is no word at that position with those properties, all was well for our purposes.
But it means that there is no word from that position with those properties.
So it turns out: nice idea, but it does not work out in MQL.
Now the tide has turned: we have trouble in MQL to find a query that exactly matches our intention, while in TF we can.
Still, there might be problems.
If there is a clause, with L, then a gap, and then either <JN/ or PNH/,
the SHEBANQ query would skip it, but the Text-Fabric query would include it.
Let's check in Text-Fabric whether this occurs.
query = """
clause
clause_atom
word lex=L
:=
< clause_atom
=: word lex=<JN/|PNH/
"""
results = A.search(query)
0.88s 0 results
Nope.
But is this query itself right? Let's look for a known case, namely Joshua 8:2 above.
query = """
clause
clause_atom
word lex=L
:=
< clause_atom
=: word lex=MN
"""
results = A.search(query)
0.88s 2 results
A.show(results, condenseType="clause")
result 1
result 2
Yes, this kind of query finds exactly what we are looking for.
Conclusion
In Text-Fabric we have found a query with slightly different results. But these results match the intention of the query just a bit better than the original query.
We tried to improve the MQL query by using NOTEXIST, but that did not work out.
However, the TF query might include (contrived) cases that the MQL query would rightfully skip. We can verify whether those cases actually exist by running a separate TF query, and it turns out they do not exist.
Lesson
Whenever an exegesis hinges on the results of a query, check and double check. You probably will have to run multiple queries in SHEBANQ and combine the results. This will quickly get very cumbersome. If that happens, it starts to pay off to use Text-Fabric, where you have more complete power over the computations and their results.