How to query the nametype feature?¶
The case¶
Victor Isaak reported a strange case on Slack, a SHEBANQ query
select all objects
where
[lex focus
nametype = 'pers'
OR
nametype = 'gens'
]
whose results were not shown properly shown in SHEBANQ.
In particular, in this verse there seem to be 3 hits, but only one hit (Riphath) is highlighted:
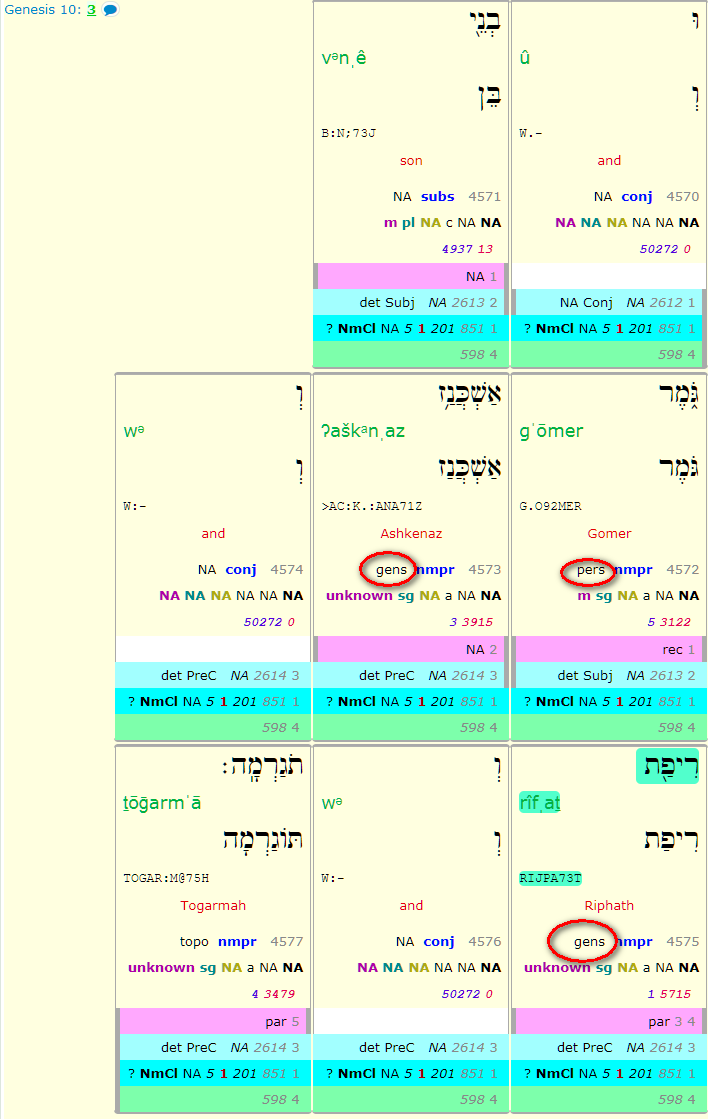
Locating¶
Let's drill down by means of Text-Fabric.
First we need to find where this case is, and in what version of the BHSA it occurs.
We start with loading version c and locating the case.
We will load the versions 4b, 2017 and c.
%load_ext autoreload
%autoreload 2
from tf.app import use
# A = use("ETCBC/bhsa", hoist=globals())
A = use("ETCBC/bhsa:clone", checkout="clone", hoist=globals())
Data: BHSA, Character table, Feature docs
Features:
BHSA = Biblia Hebraica Stuttgartensia Amstelodamensis
bookbook@ll
chapter
code
det
domain
freq_lex
function
g_cons
g_cons_utf8
g_lex
g_lex_utf8
g_word
g_word_utf8
gloss
gn
label
language
lex
lex_utf8
ls
nametype
nme
nu
number
otype
pargr
pdp
pfm
prs
prs_gn
prs_nu
prs_ps
ps
qere
qere_trailer
qere_trailer_utf8
qere_utf8
rank_lex
rela
sp
st
tab
trailer
trailer_utf8
txt
typ
uvf
vbe
vbs
verse
voc_lex
voc_lex_utf8
vs
vt
mother
oslots
Make sure which version we have:
A.version
'c'
Right. Let's start with looking for RIJPA37T in the g_word feature:
results = A.search(
"""
word g_word=RIJPA73T
"""
)
0.45s 1 result
Good, that's clear. Where is it?
w = results[0][0]
A.webLink(w)
When we click this link, the verse opens in SHEBANQ
Reproducing¶
Now let's do the original query.
query = """
lex nametype=pers|gens
"""
results = A.search(query)
0.02s 1722 results
Lets find the occurrences of the results in this verse:
query = """
lex nametype=pers|gens
w:word
verse book=Genesis chapter=10 verse=3
w
"""
results = A.search(query)
0.55s 3 results
We show these words and their name types
A.show(results, condensed=True, withNodes=True)
verse 1
This looks perfectly alright.
Other versions¶
Let's repeat this exercise in two other versions: 2017 and 4b.
We write a function that produces the result right away.
The TF-API of the data source is passed as parameter.
def gensPers(A):
A.dm(f"Version `{A.version}`\n")
query = """
lex nametype=pers|gens
w:word
verse book=Genesis chapter=10 verse=3
w
"""
results = A.search(query)
A.show(results, condensed=True, withNodes=True)
We load version 2017, but without hoisting the API to the global namespace.
Instead, we retain the API in a mapping from version name to TF-API.
We make sure that we do not loose the API for version c which we have just loaded.
A = {"c": A}
2017¶
# A['2017'] = use('ETCBC/bhsa', version='2017')
A["2017"] = use("ETCBC/bhsa:clone", checkout="clone", version="2017")
Data: BHSA, Character table, Feature docs
Features:
BHSA = Biblia Hebraica Stuttgartensia Amstelodamensis
bookbook@ll
chapter
code
det
domain
freq_lex
function
g_cons
g_cons_utf8
g_lex
g_lex_utf8
g_word
g_word_utf8
gloss
gn
label
language
lex
lex_utf8
ls
nametype
nme
nu
number
otype
pargr
pdp
pfm
prs
prs_gn
prs_nu
prs_ps
ps
qere
qere_trailer
qere_trailer_utf8
qere_utf8
rank_lex
rela
sp
st
tab
trailer
trailer_utf8
txt
typ
uvf
vbe
vbs
verse
voc_lex
voc_lex_utf8
vs
vt
mother
omap@ll
oslots
gensPers(A["2017"])
Version 2017
0.55s 3 results
verse 1
Observation: the same words are highlighted, but the nametype feature is not shown. Why? Probably because in version 2017
the nametype feature is only available for lex nodes and not for word nodes. Let's find out for sure.
A2017 = A["2017"]
F2017 = A2017.api.F
L2017 = A2017.api.L
w = 4572
lx = L2017.u(w, otype="lex")[0]
A2017.dm(f"*word* {w} has nametype `{F2017.nametype.v(w)}`\n")
A2017.dm(f"*lexeme* {lx} has nametype `{F2017.nametype.v(lx)}`\n")
word 4572 has nametype None
lexeme 1437887 has nametype pers
Indeed!
4b¶
# A['4b'] = use('ETCBC/bhsa', version='4b')
A["4b"] = use("ETCBC/bhsa:clone", checkout="clone", version="4b")
The requested data is not available offline
There were problems with loading data. The Text-Fabric API has not been loaded! The app "bhsa" will not work!
Ok, version 4b is rather old. We go to GitHub to look at the
release notes of the BHSA data.
There we see that the latest release of the data does not include the older versions anymore.
So we have to go back to an earlier release, v1.5:
# A['4b'] = use('ETCBC/bhsa', checkout='1.5', version='4b')
A["4b"] = use("ETCBC/bhsa:clone", checkout="1.5", version="4b")
rate limit is 5000 requests per hour, with 4986 left for this hour connecting to online GitHub repo etcbc/bhsa ... connected
rate limit is 5000 requests per hour, with 4983 left for this hour connecting to online GitHub repo etcbc/phono ... connected
no release tagged "1.5" The requested data is not available online
rate limit is 5000 requests per hour, with 4981 left for this hour connecting to online GitHub repo etcbc/parallels ... connected
no release tagged "1.5" The requested data is not available online There were problems with loading data. The Text-Fabric API has not been loaded! The app "bhsa" will not work!
Now we have the core data, but TF wants to get additional data (parallels and phono which is not available for this version in this release.
We tell TF to not fetch additional modules:
# A['4b'] = use('ETCBC/bhsa', checkout='1.5', version='4b', provenanceSpec=dict(moduleSpecs=()))
A["4b"] = use(
"bhsa:clone", checkout="1.5", version="4b", provenanceSpec=dict(moduleSpecs=())
)
rate limit is 5000 requests per hour, with 4979 left for this hour connecting to online GitHub repo etcbc/bhsa ... connected
Data: BHSA, Character table, Feature docs
Features:
BHSA = Biblia Hebraica Stuttgartensia Amstelodamensis
bookbook@ll
chapter
code
det
domain
freq_lex
function
g_cons
g_cons_utf8
g_entry
g_entry_heb
g_lex
g_lex_utf8
g_qere_utf8
g_word
g_word_utf8
gloss
gn
label
language
lex
lex_utf8
ls
nametype
nme
nu
number
otype
pargr
pdp
pfm
phono
phono_sep
prs
ps
qtrailer_utf8
rank_lex
rela
sp
st
tab
trailer_utf8
txt
typ
uvf
vbe
vbs
verse
vs
vt
mother
omap@ll
oslots
App config error(s) in lex: template: feature voc_lex_utf8 not loaded label: feature voc_lex_utf8 not loaded
gensPers(A["4b"])
Version 4b
0.56s 3 results
verse 1
Again: all three highlighted.
# A['4'] = use('ETCBC/bhsa', checkout='1.5', version='4', provenanceSpec=dict(moduleSpecs=()))
A["4"] = use(
"bhsa:clone", checkout="1.5", version="4", provenanceSpec=dict(moduleSpecs=())
)
rate limit is 5000 requests per hour, with 4976 left for this hour connecting to online GitHub repo etcbc/bhsa ... connected
Data: BHSA, Character table, Feature docs
Features:
BHSA = Biblia Hebraica Stuttgartensia Amstelodamensis
bookbook@ll
chapter
clause_kind
code
det
domain
freq_lex
function
g_cons
g_cons_utf8
g_entry
g_entry_heb
g_lex
g_lex_utf8
g_qere_utf8
g_word
g_word_utf8
gloss
gn
half_verse
label
language
lex
lex_utf8
ls
nametype
nme
nu
number
otype
pargr
pdp
pfm
phono
phono_sep
prs
ps
qtrailer_utf8
rank_lex
rela
sp
st
tab
trailer_utf8
txt
typ
uvf
vbe
vbs
verse
vs
vt
mother
omap@ll
oslots
App config error(s) in lex: template: feature voc_lex_utf8 not loaded label: feature voc_lex_utf8 not loaded
gensPers(A["4"])
Version 4
0.55s 3 results
verse 1
Conclusion 1¶
Versions 4, 4b, 2017, and c of the BHSA all have the nametype feature on lex nodes with values pers, gens, gens for the three words of Genesis 10:3.
Version c also has the nametype on word nodes.
Conclusion 2¶
I have run this
query on SHEBANQ
on version 2017, and c and they all produced the expected results.
For version 4 and 4b I had to modify the query, because these versions have not the lex node type.
The data on GitHub, however, has the lex node type, see otype in version 4.
Probably I have added lex later to 4 and 4b, without bringing it over to SHEBANQ.
Without more information I can not reproduce the screenshot at the start of the notebook.
Explanation¶
How does this make sense? The meaning of the query is:
- restrict the search to the portion of the corpus from slot (word) 4539 till slot 4965 (including);
- in that portion find lexeme nodes in it with certain properties
What does it mean, lexeme nodes inside a portion of the corpus?
A lexeme node occupies the slots of its occurrences, so we are interested in lexemes that have all of their occurrences in the indicated portion.
This rules out many lexemes.
Let's verify by manual coding that the other two pers and gens words in Genesis 10:3
have occurrences outside this region.
We do this in version c and continue to work in this version only. We still have the globals N E F L T S TF tied to the c version
of the data, we only have to restore A to the c version:
A = A["c"]
We repeat the query
query = """
lex nametype=pers|gens
w:word
verse book=Genesis chapter=10 verse=3
w
"""
results = A.search(query)
0.52s 3 results
Of each result (a tuple of nodes), we pretty-display the lex node, which is the first of the tuple
since lex is the first node mentioned in the search template.
The pretty display of a lexeme shows the first and last occurrence of it.
for result in results:
lx = result[0]
A.pretty(lx)
Indeed, only RIJPA73T occurs in the narrow portion that the SHEBANQ query was looking in.
Tips¶
How to query for word with certain lexeme properties in a portion of the query?
If the lexeme properties are present on the occurrences of the lexeme (the word nodes), this query will do:
select all objects
in {4539-4965}
where
[word focus
nametype = 'pers'
OR
nametype = 'gens'
]
But, as we saw, in version 2017 the nametype property only exists on the lex nodes?
How do we go about this then?
The clue is on p. 21 of Ulrik's MQL query guide. We can search for words that are contained in a lex by using monad set relation clauses:
select all objects
in {4539-4965}
where
[word focus
[lex overlap(substrate) nametype = 'pers' OR nametype = 'gens']
]
So, we start for selecting all words 4539 - 4965, and for each word we require that there is a lex with some properties that overlaps with it.
See nametype x
on SHEBANQ.