
from tqdm.auto import tqdm
import torch
from torch import autocast
import PIL.Image
import numpy as np
Structure¶
The API of diffusers consists of three main blocks:
- Pipelines: high-level classes designed to rapidly generate samples from popular trained diffusion models in a user-friendly fashion.
- Models: NN architectures with trainable weights, e.g., Unet
- predict the noise residual (or slightly less noisy image)
- Schedulers: algorithms without parameters
- in training, generate noisy images for training
- in inference, compute the next sample given the model's output

Models and schedulers are kept as independent from each other as possible:
- A scheduler should never accept a model as an input and vice-versa.
Pipeline¶
from_pretrained() downloads the model and its configuration from Hugging Face
from diffusers import DDPMPipeline
image_pipe = DDPMPipeline.from_pretrained("google/ddpm-celebahq-256")
diffusion_pytorch_model.safetensors not found
Fetching 4 files: 0%| | 0/4 [00:00<?, ?it/s]
Loading pipeline components...: 0%| | 0/2 [00:00<?, ?it/s]
The pipeline will generate a random initial noise sample and then iterate the diffusion process.
image_pipe.to("cuda")
images = image_pipe()["images"]
images[0]
0%| | 0/1000 [00:00<?, ?it/s]

Let's take a look inside the pipeline
image_pipe
DDPMPipeline {
"_class_name": "DDPMPipeline",
"_diffusers_version": "0.27.2",
"_name_or_path": "google/ddpm-celebahq-256",
"scheduler": [
"diffusers",
"DDPMScheduler"
],
"unet": [
"diffusers",
"UNet2DModel"
]
}
The pipeline contains the DDPMScheduler and the UNet2DModel model. Let's look at them closely.
Models¶
- Instances of the model class are neural networks that take a noisy
sampleas well as atimestepas inputs to predict a less noisy outputsample. - We'll load a simple unconditional image generation model of type
UNet2DModeltrained on church images withfrom_pretrained()function
from diffusers import UNet2DModel
repo_id = "google/ddpm-church-256"
model = UNet2DModel.from_pretrained(repo_id)
The model is a pure PyTorch torch.nn.Module class which you can see when printing out model.
# model
model
UNet2DModel(
(conv_in): Conv2d(3, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_proj): Timesteps()
(time_embedding): TimestepEmbedding(
(linear_1): Linear(in_features=128, out_features=512, bias=True)
(act): SiLU()
(linear_2): Linear(in_features=512, out_features=512, bias=True)
)
(down_blocks): ModuleList(
(0-1): 2 x DownBlock2D(
(resnets): ModuleList(
(0-1): 2 x ResnetBlock2D(
(norm1): GroupNorm(32, 128, eps=1e-06, affine=True)
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=128, bias=True)
(norm2): GroupNorm(32, 128, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
(downsamplers): ModuleList(
(0): Downsample2D(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2))
)
)
)
(2): DownBlock2D(
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 128, eps=1e-06, affine=True)
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=256, bias=True)
(norm2): GroupNorm(32, 256, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1))
)
(1): ResnetBlock2D(
(norm1): GroupNorm(32, 256, eps=1e-06, affine=True)
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=256, bias=True)
(norm2): GroupNorm(32, 256, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
(downsamplers): ModuleList(
(0): Downsample2D(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2))
)
)
)
(3): DownBlock2D(
(resnets): ModuleList(
(0-1): 2 x ResnetBlock2D(
(norm1): GroupNorm(32, 256, eps=1e-06, affine=True)
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=256, bias=True)
(norm2): GroupNorm(32, 256, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
(downsamplers): ModuleList(
(0): Downsample2D(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2))
)
)
)
(4): AttnDownBlock2D(
(attentions): ModuleList(
(0-1): 2 x Attention(
(group_norm): GroupNorm(32, 512, eps=1e-06, affine=True)
(to_q): Linear(in_features=512, out_features=512, bias=True)
(to_k): Linear(in_features=512, out_features=512, bias=True)
(to_v): Linear(in_features=512, out_features=512, bias=True)
(to_out): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
)
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 256, eps=1e-06, affine=True)
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=512, bias=True)
(norm2): GroupNorm(32, 512, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1))
)
(1): ResnetBlock2D(
(norm1): GroupNorm(32, 512, eps=1e-06, affine=True)
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=512, bias=True)
(norm2): GroupNorm(32, 512, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
(downsamplers): ModuleList(
(0): Downsample2D(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2))
)
)
)
(5): DownBlock2D(
(resnets): ModuleList(
(0-1): 2 x ResnetBlock2D(
(norm1): GroupNorm(32, 512, eps=1e-06, affine=True)
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=512, bias=True)
(norm2): GroupNorm(32, 512, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
)
)
(up_blocks): ModuleList(
(0): UpBlock2D(
(resnets): ModuleList(
(0-2): 3 x ResnetBlock2D(
(norm1): GroupNorm(32, 1024, eps=1e-06, affine=True)
(conv1): Conv2d(1024, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=512, bias=True)
(norm2): GroupNorm(32, 512, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))
)
)
(upsamplers): ModuleList(
(0): Upsample2D(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(1): AttnUpBlock2D(
(attentions): ModuleList(
(0-2): 3 x Attention(
(group_norm): GroupNorm(32, 512, eps=1e-06, affine=True)
(to_q): Linear(in_features=512, out_features=512, bias=True)
(to_k): Linear(in_features=512, out_features=512, bias=True)
(to_v): Linear(in_features=512, out_features=512, bias=True)
(to_out): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
)
(resnets): ModuleList(
(0-1): 2 x ResnetBlock2D(
(norm1): GroupNorm(32, 1024, eps=1e-06, affine=True)
(conv1): Conv2d(1024, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=512, bias=True)
(norm2): GroupNorm(32, 512, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1))
)
(2): ResnetBlock2D(
(norm1): GroupNorm(32, 768, eps=1e-06, affine=True)
(conv1): Conv2d(768, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=512, bias=True)
(norm2): GroupNorm(32, 512, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(768, 512, kernel_size=(1, 1), stride=(1, 1))
)
)
(upsamplers): ModuleList(
(0): Upsample2D(
(conv): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(2): UpBlock2D(
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 768, eps=1e-06, affine=True)
(conv1): Conv2d(768, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=256, bias=True)
(norm2): GroupNorm(32, 256, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(768, 256, kernel_size=(1, 1), stride=(1, 1))
)
(1-2): 2 x ResnetBlock2D(
(norm1): GroupNorm(32, 512, eps=1e-06, affine=True)
(conv1): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=256, bias=True)
(norm2): GroupNorm(32, 256, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
)
)
(upsamplers): ModuleList(
(0): Upsample2D(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(3): UpBlock2D(
(resnets): ModuleList(
(0-1): 2 x ResnetBlock2D(
(norm1): GroupNorm(32, 512, eps=1e-06, affine=True)
(conv1): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=256, bias=True)
(norm2): GroupNorm(32, 256, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1))
)
(2): ResnetBlock2D(
(norm1): GroupNorm(32, 384, eps=1e-06, affine=True)
(conv1): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=256, bias=True)
(norm2): GroupNorm(32, 256, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(384, 256, kernel_size=(1, 1), stride=(1, 1))
)
)
(upsamplers): ModuleList(
(0): Upsample2D(
(conv): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(4): UpBlock2D(
(resnets): ModuleList(
(0): ResnetBlock2D(
(norm1): GroupNorm(32, 384, eps=1e-06, affine=True)
(conv1): Conv2d(384, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=128, bias=True)
(norm2): GroupNorm(32, 128, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(384, 128, kernel_size=(1, 1), stride=(1, 1))
)
(1-2): 2 x ResnetBlock2D(
(norm1): GroupNorm(32, 256, eps=1e-06, affine=True)
(conv1): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=128, bias=True)
(norm2): GroupNorm(32, 128, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
)
)
(upsamplers): ModuleList(
(0): Upsample2D(
(conv): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
)
)
(5): UpBlock2D(
(resnets): ModuleList(
(0-2): 3 x ResnetBlock2D(
(norm1): GroupNorm(32, 256, eps=1e-06, affine=True)
(conv1): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=128, bias=True)
(norm2): GroupNorm(32, 128, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
(conv_shortcut): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1))
)
)
)
)
(mid_block): UNetMidBlock2D(
(attentions): ModuleList(
(0): Attention(
(group_norm): GroupNorm(32, 512, eps=1e-06, affine=True)
(to_q): Linear(in_features=512, out_features=512, bias=True)
(to_k): Linear(in_features=512, out_features=512, bias=True)
(to_v): Linear(in_features=512, out_features=512, bias=True)
(to_out): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Dropout(p=0.0, inplace=False)
)
)
)
(resnets): ModuleList(
(0-1): 2 x ResnetBlock2D(
(norm1): GroupNorm(32, 512, eps=1e-06, affine=True)
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(time_emb_proj): Linear(in_features=512, out_features=512, bias=True)
(norm2): GroupNorm(32, 512, eps=1e-06, affine=True)
(dropout): Dropout(p=0.0, inplace=False)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(nonlinearity): SiLU()
)
)
)
(conv_norm_out): GroupNorm(32, 128, eps=1e-06, affine=True)
(conv_act): SiLU()
(conv_out): Conv2d(128, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
A concise description of the model configuration can be obtain from the config attribute
model.config
FrozenDict([('sample_size', 256),
('in_channels', 3),
('out_channels', 3),
('center_input_sample', False),
('time_embedding_type', 'positional'),
('freq_shift', 1),
('flip_sin_to_cos', False),
('down_block_types',
['DownBlock2D',
'DownBlock2D',
'DownBlock2D',
'DownBlock2D',
'AttnDownBlock2D',
'DownBlock2D']),
('up_block_types',
['UpBlock2D',
'AttnUpBlock2D',
'UpBlock2D',
'UpBlock2D',
'UpBlock2D',
'UpBlock2D']),
('block_out_channels', [128, 128, 256, 256, 512, 512]),
('layers_per_block', 2),
('mid_block_scale_factor', 1),
('downsample_padding', 0),
('downsample_type', 'conv'),
('upsample_type', 'conv'),
('dropout', 0.0),
('act_fn', 'silu'),
('attention_head_dim', None),
('norm_num_groups', 32),
('attn_norm_num_groups', None),
('norm_eps', 1e-06),
('resnet_time_scale_shift', 'default'),
('add_attention', True),
('class_embed_type', None),
('num_class_embeds', None),
('num_train_timesteps', None),
('_use_default_values',
['num_train_timesteps',
'resnet_time_scale_shift',
'add_attention',
'downsample_type',
'class_embed_type',
'attn_norm_num_groups',
'dropout',
'upsample_type',
'num_class_embeds']),
('_class_name', 'UNet2DModel'),
('_diffusers_version', '0.0.4'),
('_name_or_path', 'google/ddpm-church-256')])
The model takes a random gaussian sample in the shape of an image (batch_size × in_channels × image_size × image_size).
noisy_sample = torch.randn(
1, model.config.in_channels, model.config.sample_size, model.config.sample_size
)
noisy_sample.shape
torch.Size([1, 3, 256, 256])
To perform inference, we give the noisy sample and a timestep to the model.
A Diffusers's model can predict
- a slightly less noisy image
- the difference between the slightly less noisy image
- the input image
- or even something else. The information can be found in the model card.
In this case, the model predicts the noise residual $\boldsymbol{\tilde z_t}$, which has the same size of the input.
with torch.no_grad():
noisy_residual = model(sample=noisy_sample, timestep=2)["sample"]
noisy_residual.shape
torch.Size([1, 3, 256, 256])
The next step is to combine this model with the correct scheduler to generate actual images.
Schedulers¶
- Schedulers are algorithms wrapped into a Python class
- Differently from models, schedulers have no trainable weights
- In training, they define the schedule used to add noise
- In inference, they compute the next sample given the model output
- Run the
from_pretrained()method to load a configuration and instantiate a scheduler - Note that we did something similar to load pipes and models
from diffusers import DDPMScheduler
scheduler = DDPMScheduler.from_pretrained(repo_id)
Like for models, we can access the configuration of the scheduler with config.
scheduler.config
FrozenDict([('num_train_timesteps', 1000),
('beta_start', 0.0001),
('beta_end', 0.02),
('beta_schedule', 'linear'),
('trained_betas', None),
('variance_type', 'fixed_small'),
('clip_sample', True),
('prediction_type', 'epsilon'),
('thresholding', False),
('dynamic_thresholding_ratio', 0.995),
('clip_sample_range', 1.0),
('sample_max_value', 1.0),
('timestep_spacing', 'leading'),
('steps_offset', 0),
('rescale_betas_zero_snr', False),
('_use_default_values',
['prediction_type',
'sample_max_value',
'timestep_spacing',
'rescale_betas_zero_snr',
'thresholding',
'dynamic_thresholding_ratio',
'clip_sample_range',
'steps_offset']),
('_class_name', 'DDPMScheduler'),
('_diffusers_version', '0.1.1')])
Note:
num_train_timesteps: the length of the denoising process, e.g. how many timesteps are need to transform random gaussian noise to a data sample.beta_startandbeta_end: define the smallest and highest values assumed by $\beta_t$beta_schedule: define how the noise changes over time, both in inference and training
All schedulers provide one (or more) step() methods to compute the slightly less noisy image.
The step() method may vary from one scheduler to another, but normally expects:
- the model output $\tilde z_t$ (what we called
noisy_residual) - the
timestep$t$ - the current
noisy_sample$\tilde x_t$

less_noisy_sample = scheduler.step(
model_output=noisy_residual, timestep=12, sample=noisy_sample
)["prev_sample"]
less_noisy_sample.shape
torch.Size([1, 3, 256, 256])
Note some schedulers might implement step() slightly differently: always check the code/documentation of the API
Time to define the denoising loop.
- We loop over
scheduler.timesteps, the sequence of timesteps for the denoising process. - Usually, the denoising process goes in decreasing order of timesteps (here from 1000 to 0).
- To visualize what is going on, we print out the (less and less) noisy samples every 50 steps.
# define the function to visualize the images as they get denoised
def display_sample(sample, i):
image_processed = sample.cpu().permute(0, 2, 3, 1)
image_processed = (image_processed + 1.0) * 127.5
image_processed = image_processed.numpy().astype(np.uint8)
image_pil = PIL.Image.fromarray(image_processed[0])
display(f"Image at step {i}")
display(image_pil)
# move model and input to gpu to speed things up
model.to("cuda")
noisy_sample = noisy_sample.to("cuda")
sample = noisy_sample # pure noise
for i, t in enumerate(tqdm(scheduler.timesteps)):
# 1. predict noisy residual z_t
with torch.no_grad():
residual = model(sample, t)["sample"]
# 2. compute less noisy image and set x_t -> x_t-1
sample = scheduler.step(residual, t, sample)["prev_sample"]
# 3. optionally look at image
if (i + 1) % 50 == 0:
display_sample(sample, i + 1)
0%| | 0/1000 [00:00<?, ?it/s]
'Image at step 50'

'Image at step 100'

'Image at step 150'

'Image at step 200'

'Image at step 250'

'Image at step 300'

'Image at step 350'

'Image at step 400'

'Image at step 450'

'Image at step 500'

'Image at step 550'

'Image at step 600'

'Image at step 650'

'Image at step 700'

'Image at step 750'

'Image at step 800'

'Image at step 850'

'Image at step 900'

'Image at step 950'

'Image at step 1000'

- It takes quite some time to produce a meaningful image
- To speed-up the generation, we switch the DDPM scheduler with the DDIM scheduler
- The DDIM scheduler removes stochasticity during sampling and updates the samples every $T/S$ steps
- The total number of inference steps is reduced from $T$ to $S$
- Note that some schedulers follow different protocols and cannot be switched so easily like in this case
from diffusers import DDIMScheduler
scheduler = DDIMScheduler.from_pretrained(repo_id)
- The DDIM scheduler allows the user to specify the number of inference steps $S$
- In this case, we set $S=50$ through the variable
num_inference_steps
scheduler.set_timesteps(num_inference_steps=50)
sample = noisy_sample
for i, t in enumerate(tqdm(scheduler.timesteps)):
# 1. predict noise residual
with torch.no_grad():
residual = model(sample, t)["sample"]
# 2. compute previous image and set x_t -> x_t-1
sample = scheduler.step(residual, t, sample)["prev_sample"]
# 3. optionally look at image
if (i + 1) % 10 == 0:
display_sample(sample, i + 1)
0%| | 0/50 [00:00<?, ?it/s]
'Image at step 10'

'Image at step 20'

'Image at step 30'

'Image at step 40'

'Image at step 50'

- In DDPM some noise with variance $\sigma_t$ (or $\tilde \beta_t$) is added to get the next sample
- Instead, the DDIM scheduler is deterministic
- Starting from the same input $x_T$ gives the same output $x_0$
Stable Diffusion¶
- Stable Diffusion is based on a particular type of diffusion model called Latent Diffusion
- Latent diffusion can reduce the memory and compute complexity by applying the diffusion process over a lower dimensional latent space, instead of using the actual pixel space
There are 3 main components in the latent diffusion model.
- A tokenizer + text-encoder (CLIP)
- An autoencoder (VAE)
- The U-Net (as in DDPM/DDIM)
Tokenizer + text-encoder:
- The text-encoder is responsible for transforming a text prompt into an embedding space that can be understood by the U-Net
- It is usually a transformer-based encoder that maps a sequence of tokens (generated with a tokenizer) into a (large fixed size) text-embedding
- Stable Diffusion does not train the text-encoder and simply uses an already trained one such as CLIP or BERT
The VAE model has two parts:
- The encoder is used to convert the image into a low dimensional latent representation, which will serve as the input to the U-Net
- The decoder transforms the latent representation back into an image.
- During training, the encoder is used to get the latent representations of the images for the forward diffusion process
- During inference, the denoised latents generated by the reverse diffusion process are converted back into images using the VAE decoder
- Working with latens is the key of the speed and memory efficiency of Stable Diffusion
- The VAE reduces the input size by a factor of 8
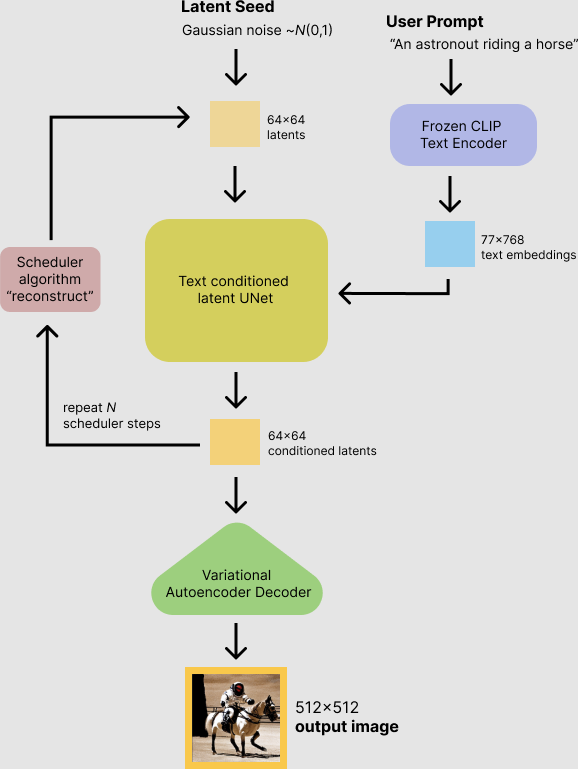
Pre-built pipeline¶
Has 5 components:
scheduler: scheduling algorithm used to progressively add noise to the image during training.text_encoder: Stable Diffusion uses CLIP, but other diffusion models may use other encoders such as BERT.tokenizer: it must match the one used by the text_encoder model.unet: model used to generate the latent representation of the input.vae: module used to decode latent representations into real images.
from diffusers import StableDiffusionPipeline
image_pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
image_pipe.to("cuda");
Fetching 16 files: 0%| | 0/16 [00:00<?, ?it/s]
Loading pipeline components...: 0%| | 0/7 [00:00<?, ?it/s]
Let's try it out.
prompt = "A cat wearing a top hat. sharp, rendered in unreal engine 5, digital art, by greg rutkowski, dramatic lighting"
image = image_pipe(prompt,
guidance_scale=7.5, # Values between 7 and 8.5 are usually good
num_inference_steps=50, # Lower values makes image generation faster but reduces quality
generator=torch.Generator("cuda").manual_seed(0),
height=512,
width=512)["images"][0]
image
0%| | 0/50 [00:00<?, ?it/s]

guidance_scaleforces the generation to match the prompt at the cost of image quality or diversity.num_inference_stepsspecifies how many denoising steps are done to generate an image.
Custom pipeline¶
- As we did before, we will replace the
schedulerin the pre-built pipeline. - The other 4 components,
vae,tokenizer,text_encoder, andunetare not changed but they could also be switched (e.g., CLIPtext_encoderwith BERT or a differentvae) - We start by loading them
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel
# 1. Load the autoencoder model which will be used to decode the latents into image space.
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae")
# 2. Load the tokenizer and text encoder to tokenize and encode the text.
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
# 3. The UNet model for generating the latents.
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet")
tokenizer_config.json: 0%| | 0.00/905 [00:00<?, ?B/s]
vocab.json: 0%| | 0.00/961k [00:00<?, ?B/s]
merges.txt: 0%| | 0.00/525k [00:00<?, ?B/s]
special_tokens_map.json: 0%| | 0.00/389 [00:00<?, ?B/s]
tokenizer.json: 0%| | 0.00/2.22M [00:00<?, ?B/s]
config.json: 0%| | 0.00/4.52k [00:00<?, ?B/s]
model.safetensors: 0%| | 0.00/1.71G [00:00<?, ?B/s]
Next, we load an LMS scheduler instead of the PNDMScheduler from the default pipeline
from diffusers import LMSDiscreteScheduler
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
torch_device = "cuda"
vae.to(torch_device)
text_encoder.to(torch_device)
unet.to(torch_device);
Hyperparameters
prompt = ["A cat wearing a top hat. sharp, rendered in unreal engine 5, digital art, by greg rutkowski, dramatic lighting"]
height = 512 # default height of Stable Diffusion
width = 512 # default width of Stable Diffusion
generator = torch.manual_seed(0) # Use the same random seed as before
guidance_scale = 7.5 # Scale for classifier-free guidance
num_inference_steps = 100 # Number of denoising steps
Text embeddings
- First, we get the embeddings for the prompt
- These embeddings will be used to condition the UNet model and guide the image generation towards something that should resemble the input prompt
- The
text_embeddingsare arrays of size $77 \times 768$
text_input = tokenizer(prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")
text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
text_embeddings.shape
torch.Size([1, 77, 768])
- We'll also get the unconditional text embeddings for classifier-free guidance, which are just the embeddings for the empty text
""
uncond_input = tokenizer([""], padding="max_length", max_length=tokenizer.model_max_length, return_tensors="pt")
uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
text_embeddings.shape
torch.Size([1, 77, 768])
Guidance
For classifier-free guidance, we need $\tilde z = \tilde z_x + \gamma \big( \tilde z_{x|y} - \tilde z_x \big)$.
We need two forward passes:
- one with the conditioned input (
text_embeddings) to get $\tilde z_{x|y}$ (i.e., the score function $\nabla_x p(x|y)$) - one with the unconditional embeddings (
uncond_embeddings) to get $\tilde z_x$ (i.e., the score function $\nabla_x p(x)$)
In practice, we can concatenate both into a single batch to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
Initial random noise
- Stable Diffusion takes denoising in the latent space, which is $8$ times smaller than the input space ($64 \times 64$ vs. $512 \times 512$)
latents = torch.randn(
(1, unet.in_channels, height // 8, width // 8),
generator=generator,
)
latents = latents.to(torch_device)
latents.shape
/tmp/ipykernel_666745/906192936.py:2: FutureWarning: Accessing config attribute `in_channels` directly via 'UNet2DConditionModel' object attribute is deprecated. Please access 'in_channels' over 'UNet2DConditionModel's config object instead, e.g. 'unet.config.in_channels'. (1, unet.in_channels, height // 8, width // 8),
torch.Size([1, 4, 64, 64])
Scheduler
- We initialize the LMS scheduler with the
num_inference_stepshyperparameter - The scheduler will compute the sigmas $\sigma_t$ to be used during the denoising process
- LMS computes the next latent to be fed in the U-net as $\tilde x_t = \frac{\tilde x_t}{\sqrt{\sigma_t^2 +1}}$
# Denoise loop
scheduler.set_timesteps(num_inference_steps)
latents = latents * scheduler.sigmas[0]
with autocast("cuda"):
for i, t in tqdm(enumerate(scheduler.timesteps)):
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
latent_model_input = torch.cat([latents] * 2)
sigma = scheduler.sigmas[i]
latent_model_input = latent_model_input / ((sigma**2 + 1) ** 0.5)
# predict the noise residual
with torch.no_grad():
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings)["sample"]
# perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = scheduler.step(noise_pred, t, latents).prev_sample
0it [00:00, ?it/s]
/home/filippo/miniconda3/envs/diffusion/lib/python3.11/site-packages/diffusers/schedulers/scheduling_lms_discrete.py:398: UserWarning: The `scale_model_input` function should be called before `step` to ensure correct denoising. See `StableDiffusionPipeline` for a usage example. warnings.warn(
# scale and decode the image latents with vae
latents = 1 / 0.18215 * latents
image = vae.decode(latents).sample
# visualize the image
image = (image / 2 + 0.5).clamp(0, 1)
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (image * 255).round().astype("uint8")
pil_images = [PIL.Image.fromarray(image) for image in images]
pil_images[0]

Evaluation metrics¶
There are two metrics commonly used to evaluate the performance of a generative model:
- the Frechet Inception Distance (FID)
- the CLIP score
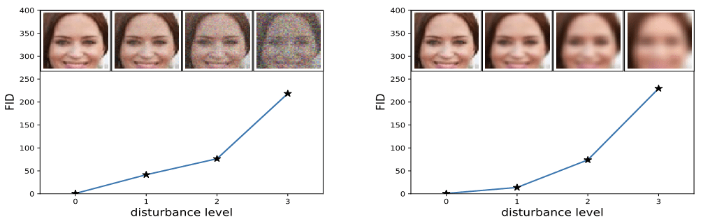
Frechet Inception Distance (FID)
- Take a sample of generated images, feed them into a pre-trained Inception v3 model, and take the outputs from the last pooling layer (a feature vector of size 2,048)
- Do the same with real images
- The result is two collections of 2,048 feature vectors for real and generated images
- The two collections are summarized by two multivariate Gaussians $\mathcal{N}(\mu_1, C_1)$ and $\mathcal{N}(\mu_2, C_2)$
- $\mu_1$ and $\mu_2$ are the means of the two collections of vectors
- $C_1$ and $C_2$ are the covariance matrices
- FID computes the dissimilarity between the two Gaussians as
- A low FID indicates a good match between real and generated images
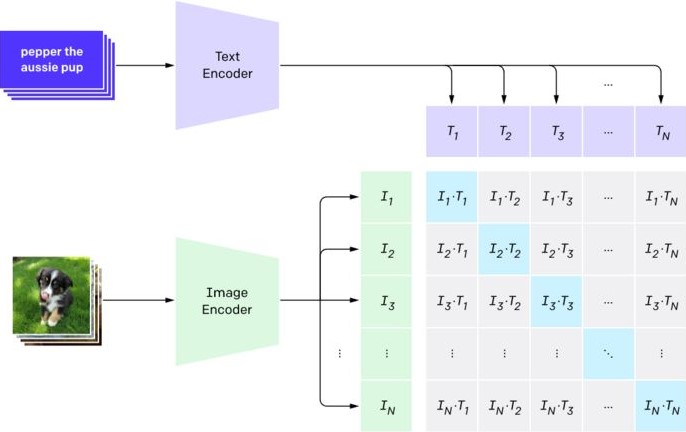
CLIP score
- CLIP is a multi-modal vision and language model
- It can return the best caption given an image and has impressive zero-shot capabilities
- CLIP uses a ViT to get visual features
- CLIP uses a causal language model (predicts the token after a sequence of tokens) to get the text features
- Both the text and visual features are projected to a latent space with identical dimension
- The dot product between the projected image and text features can be used as a similar score
- A CLIP score quantifies the adherence of a generated image to the text prompt
Performance of different Stable Diffusion checkpoints
