DOWNLOAD ALL THE ANTECHINUSES!¶
In another notebook we discovered there are 2,883 Antechinus specimens in the Museum of Victoria. Let's see how many pictures we can find of them.

Import what we need¶
In [1]:
import requests
from slugify import slugify
from pathlib import Path
import os
from tqdm.auto import tqdm
In [2]:
SEARCH_URL = 'https://collections.museumsvictoria.com.au/api/search'
Define some functions¶
In [3]:
def get_totals(params):
'''
Get the total number of results and pages returned by a search.
'''
response = requests.get(SEARCH_URL, params=params, headers={'User-Agent': 'Mozilla/5.0'})
# The total results and pages values are in the API response's headers!
total_results = int(response.headers['Total-Results'])
total_pages = int(response.headers['Total-Pages'])
return (total_results, total_pages)
def download_images(species, size='small'):
'''
Download all the available images for the given specimen.
'''
# Create a directory to save the images in based on the species name
image_path = Path('images', slugify(species))
image_path.mkdir(exist_ok=True, parents=True)
# Note the hasimages parameter to only get records with images
params = {
'recordtype': 'specimen',
'taxon': species,
'perpage': 100,
'hasimages': 'yes',
'sort': 'date'
}
_, total_pages = get_totals(params)
# Loop through the pages
for page in tqdm(range(1, total_pages + 1)):
response = requests.get(SEARCH_URL, params=params, headers={'User-Agent': 'Mozilla/5.0'})
data = response.json()
# Loop through the records
for record in data:
# Loop through the attached media (may be more than one image in a record)
for media in record['media']:
# Media items can be videos too
if media['type'] == 'image':
url = media[size]['uri']
# Get the current image name
image_name = os.path.basename(url)
# Add the specimen id to the image name
image_file = Path(image_path, f'{slugify(record["id"])}-{image_name}')
response = requests.get(url)
# Save the image
image_file.write_bytes(response.content)
DOWNLOAD THE ANTECHINUSES!¶
In [ ]:
download_images('Antechinus agilis')
Results¶
The code above creates a directory under images for each downloaded species.
While only one of the 2,883 antechinus records had images attached, there were multiple images in that record.
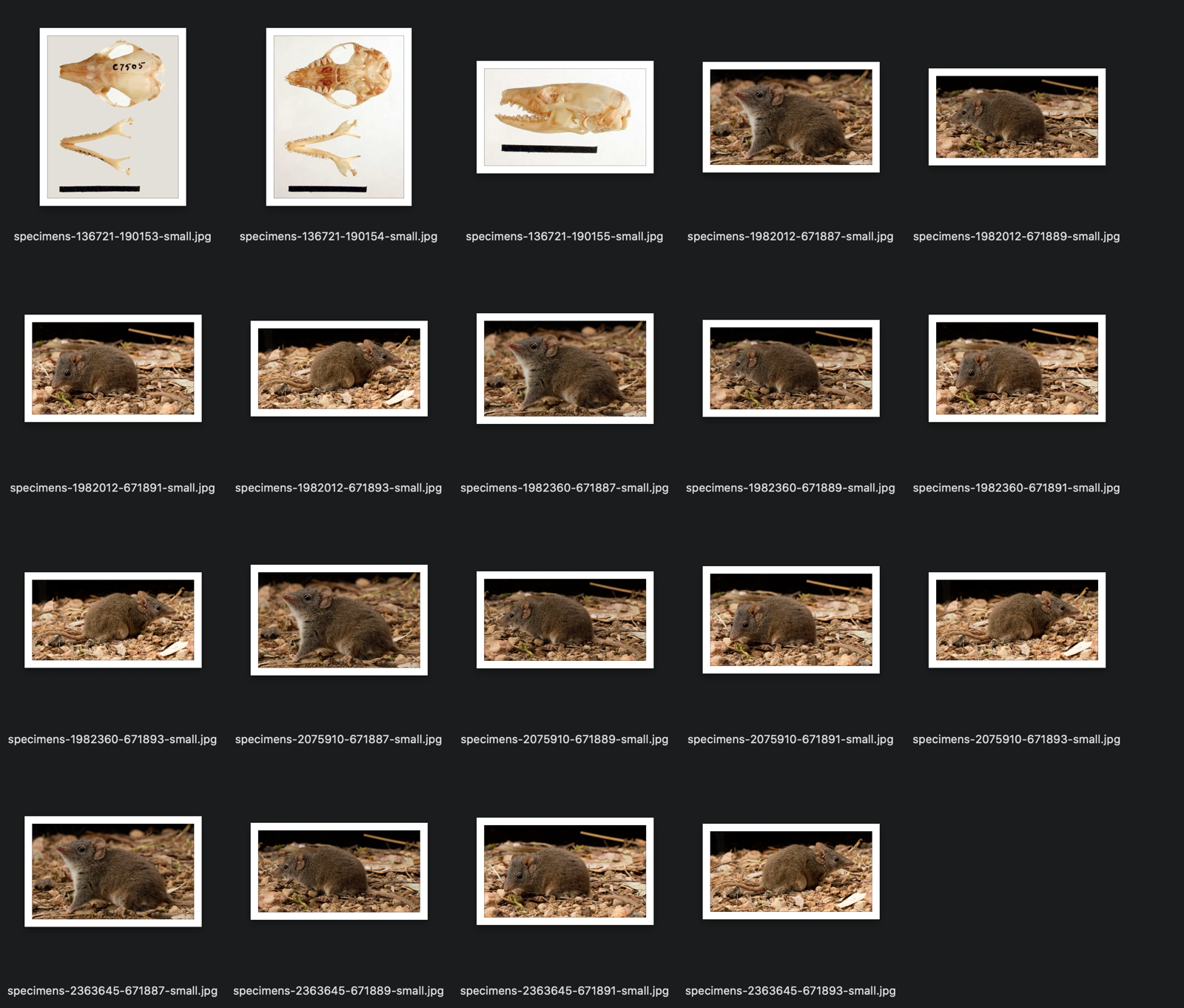
What next?¶
Obviously this little image download example could be modified to download things other than Antechinuses!
Created by Tim Sherratt for the GLAM Workbench. Support me by becoming a GitHub sponsor!