Exploring subdomains in the whole of gov.au¶
New to Jupyter notebooks? Try Using Jupyter notebooks for a quick introduction.
Most of the notebooks in this repository work with small slices of web archive data. In this notebook we'll scale things up a bit to try and find all of the subdomains that have existed in the gov.au domain. As in other notebooks, we'll obtain the data by querying the Internet Archive's CDX API. The only real difference is that it will take some hours to harvest all the data.
All we're interested in this time are unique domain names, so to minimise the amount of data we'll be harvesting we can make use of the CDX API's collapse parameter. By setting collapse=urlkey we can tell the CDX API to drop records with duplicate urlkey values – this should mean we only get one capture per page. However, this only works if the capture records are in adjacent rows, so there probably will still be some duplicates. We'll also use the fl to limit the fields returned, and the filter parameter to limit results by statuscode and mimetype. So the parameters we'll use are:
url=*.gov.au– all of the pages in all of the subdomains undergov.aucollapse=urlkey– as few captures per page as possiblefilter=statuscode:200,mimetype:text/html– only successful captures of HTML pagesfl=urlkey,timestamp,original– only these fields
Even with these limits, the query will retrieve a LOT of data. To make the harvesting process easier to manage and more robust, I'm going to make use of the requests-cache module. This will capture the results of all requests, so that if things get interrupted and we have to restart, we can retrieve already harvested requests from the cache without downloading them again. We'll also write the harvested results directly to disk rather than consuming all our computer's memory. The file format will be the NDJSON (Newline Delineated JSON) format – because each line is a separate JSON object we can just write it a line at a time as the data is received.
For a general approach to harvesting domain-level information from the IA CDX API see Harvesting data about a domain using the IA CDX API
If you'd like to access pre-harvested datasets, you can download the following files from Cloudstor:
- gov-au-cdx-data-20220406105227.ndjson (75.7gb) – this is the raw data saved as newline delimited JSON
- gov-au-domains-split-20220406155220.csv (2.4mb) – this is a CSV file containing unique domains, split into subdomains
- gov-au-unique-domains-20220406131052.csv – this is a CSV file containing unique domains in SURT format
import json
import os
import re
import time
from pathlib import Path
import arrow
import ndjson
import newick
import pandas as pd
import requests
from ete3 import Tree, TreeStyle
from IPython.display import HTML, FileLink, display
from newick import Node
from requests.adapters import HTTPAdapter
from requests.packages.urllib3.util.retry import Retry
from requests_cache import CachedSession
from slugify import slugify
from tqdm.auto import tqdm
os.environ["QT_QPA_PLATFORM"] = "offscreen"
s = CachedSession()
retries = Retry(total=10, backoff_factor=1, status_forcelist=[502, 503, 504])
s.mount("https://", HTTPAdapter(max_retries=retries))
s.mount("http://", HTTPAdapter(max_retries=retries))
domain = "gov.au"
def get_total_pages(params):
"""
Gets the total number of pages in a set of results.
"""
these_params = params.copy()
these_params["showNumPages"] = "true"
response = s.get(
"http://web.archive.org/cdx/search/cdx",
params=these_params,
headers={"User-Agent": ""},
)
return int(response.text)
def prepare_params(url, **kwargs):
"""
Prepare the parameters for a CDX API requests.
Adds all supplied keyword arguments as parameters (changing from_ to from).
Adds in a few necessary parameters.
"""
params = kwargs
params["url"] = url
params["output"] = "json"
# CDX accepts a 'from' parameter, but this is a reserved word in Python
# Use 'from_' to pass the value to the function & here we'll change it back to 'from'.
if "from_" in params:
params["from"] = params["from_"]
del params["from_"]
return params
def get_cdx_data(params):
"""
Make a request to the CDX API using the supplied parameters.
Check the results for a resumption key, and return the key (if any) and the results.
"""
try:
response = s.get(
"http://web.archive.org/cdx/search/cdx", params=params, timeout=120
)
# Some pages generate errors -- seems to be a problem at server end, so we'll ignore.
# This could mean some data is lost?
except requests.exceptions.ChunkedEncodingError:
print(f'Error page {params["page"]}')
return None
else:
response.raise_for_status()
results = response.json()
if not response.from_cache:
time.sleep(0.2)
return results
def convert_lists_to_dicts(results):
if results:
keys = results[0]
results_as_dicts = [dict(zip(keys, v)) for v in results[1:]]
else:
results_as_dicts = results
return results_as_dicts
def get_cdx_data_by_page(url, **kwargs):
page = 0
params = prepare_params(url, **kwargs)
total_pages = get_total_pages(params)
# We'll use a timestamp to distinguish between versions
timestamp = arrow.now().format("YYYYMMDDHHmmss")
file_path = Path(f"{slugify(domain)}-cdx-data-{timestamp}.ndjson")
# Remove any old versions of the data file
try:
file_path.unlink()
except FileNotFoundError:
pass
with tqdm(total=total_pages - page) as pbar1:
with tqdm() as pbar2:
while page < total_pages:
params["page"] = page
results = get_cdx_data(params)
if results:
with file_path.open("a") as f:
writer = ndjson.writer(f, ensure_ascii=False)
for result in convert_lists_to_dicts(results):
writer.writerow(result)
pbar2.update(len(results) - 1)
page += 1
pbar1.update(1)
# Note than harvesting a domain has the same number of pages (ie requests) no matter what filters are applied -- it's just that some pages will be empty.
# So repeating a domain harvest with different filters will mean less data, but the same number of requests.
# What's most efficient? I dunno.
get_cdx_data_by_page(
f"*.{domain}",
filter=["statuscode:200", "mimetype:text/html"],
collapse="urlkey",
fl="urlkey,timestamp,original",
pageSize=5,
)
Process the harvested data¶
After many hours, and many interruptions, the harvesting process finally finished. I ended up with a 65gb ndjson file. How many captures does it include?
%%time
latest_data = sorted(list(Path(".").glob("gov-au-cdx-data-*")), reverse=True)[0]
count = 0
with latest_data.open() as f:
for line in f:
count += 1
print(f"{count:,}")
213,107,491 CPU times: user 38.5 s, sys: 29.3 s, total: 1min 7s Wall time: 1min 24s
Find unique domains¶
Now let's get extract a list of unique domains from all of those page captures. In the code below we extract domains from the urlkey and add them to a list. After every 100,000 lines, we use set to remove duplicates from the list. This is an attempt to find a reasonable balance between speed and memory consumption.
%%time
# This is slow, but will avoid eating up memory
domains = []
with latest_data.open() as f:
count = 0
with tqdm() as pbar:
for line in f:
capture = json.loads(line)
# Split the urlkey on ) to separate domain from path
domain = capture["urlkey"].split(")")[0]
# Remove port numbers
domain = re.sub(r"\:\d+", "", domain)
domains.append(domain)
count += 1
# Remove duplicates after every 100,000 lines to conserve memory
if count > 100000:
domains = list(set(domains))
pbar.update(count)
count = 0
domains = list(set(domains))
0it [00:00, ?it/s]
CPU times: user 10min 47s, sys: 21.6 s, total: 11min 9s Wall time: 11min 8s
How many unique domains are there?
len(domains)
28461
df = pd.DataFrame(domains, columns=["urlkey"])
df.head()
| urlkey | |
|---|---|
| 0 | au,gov,qld,rockhampton |
| 1 | au,gov,ag,sat |
| 2 | au,gov,vic,ffm,confluence |
| 3 | au,gov,nsw,dumaresq |
| 4 | au,gov,wa,dpc,scienceandinnovation |
Save the list of domains to a CSV file to save us having to extract them again.
unique_filename = (
f'domains/gov-au-unique-domains-{arrow.now().format("YYYYMMDDHHmmss")}.csv'
)
df.to_csv(unique_filename, index=False)
display(FileLink(unique_filename))
Reload the list of domains from the CSV if necessary.
latest_domains = sorted(
list(Path("domains").glob("gov-au-unique-domains-*")), reverse=True
)[0]
domains = pd.read_csv(latest_domains)["urlkey"].to_list()
Number of unique urls per subdomain¶
Now that we have a list of unique domains we can use this to generate a count of unique urls per subdomain. This won't be exact. As noted previously, even with collapse set to urlkey there are likely to be duplicate urls. Getting rid of all the duplicates in such a large file would require a fair bit of processing, and I'm not sure it's worth it at this point. We really just want a sense of how subdomains are actually used.
# Create a dictionary with the domains as keys and the values set to zero
domain_counts = dict(zip(domains, [0] * len(domains)))
%%time
# FIND NUMBER OF URLS PER DOMAIN
# As above we'll go though the file line by line
# but this time we'll extract the domain and increment the corresponding value in the dict.
with latest_data.open() as f:
count = 0
with tqdm() as pbar:
for line in f:
capture = json.loads(line)
# Split the urlkey on ) to separate domain from path
domain = capture["urlkey"].split(")")[0]
domain = re.sub(r"\:\d+", "", domain)
# Increment domain count
domain_counts[domain] += 1
count += 1
# This is just to update the progress bar
if count > 100000:
pbar.update(count)
count = 0
0it [00:00, ?it/s]
CPU times: user 10min 56s, sys: 18.7 s, total: 11min 15s Wall time: 11min 14s
Convert to a dataframe¶
We'll now convert the data to a dataframe and do a bit more processing.
# Reshape dict as a list of dicts
domain_counts_as_list = [
{"urlkey": k, "number_of_pages": v} for k, v in domain_counts.items()
]
# Convert to dataframe
df_counts = pd.DataFrame(domain_counts_as_list)
df_counts.head()
| urlkey | number_of_pages | |
|---|---|---|
| 0 | au,gov,qld,rockhampton | 10069 |
| 1 | au,gov,ag,sat | 14 |
| 2 | au,gov,vic,ffm,confluence | 5 |
| 3 | au,gov,nsw,dumaresq | 33 |
| 4 | au,gov,wa,dpc,scienceandinnovation | 438 |
Now we're going to split the urlkey into its separate subdomains.
# Split the urlkey on commas into separate columns -- this creates a new df
df_split = df_counts["urlkey"].str.split(",", expand=True)
# Merge the new df back with the original so we have both the urlkey and it's components
df_merged = pd.merge(df_counts, df_split, left_index=True, right_index=True)
Finally, we'll stich the subdomains back together in a traditional domain format just for readability.
def join_domain(x):
parts = x.split(",")
parts.reverse()
return ".".join(parts)
df_merged["domain"] = df_merged["urlkey"].apply(join_domain)
df_merged.head()
| urlkey | number_of_pages | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | domain | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | au,gov,qld,rockhampton | 10069 | au | gov | qld | rockhampton | None | None | None | None | None | None | rockhampton.qld.gov.au |
| 1 | au,gov,ag,sat | 14 | au | gov | ag | sat | None | None | None | None | None | None | sat.ag.gov.au |
| 2 | au,gov,vic,ffm,confluence | 5 | au | gov | vic | ffm | confluence | None | None | None | None | None | confluence.ffm.vic.gov.au |
| 3 | au,gov,nsw,dumaresq | 33 | au | gov | nsw | dumaresq | None | None | None | None | None | None | dumaresq.nsw.gov.au |
| 4 | au,gov,wa,dpc,scienceandinnovation | 438 | au | gov | wa | dpc | scienceandinnovation | None | None | None | None | None | scienceandinnovation.dpc.wa.gov.au |
split_filename = (
f'domains/gov-au-domains-split-{arrow.now().format("YYYYMMDDHHmmss")}.csv'
)
df_merged.to_csv(split_filename, index=False)
display(FileLink(split_filename))
latest_split = sorted(
list(Path("domains").glob("gov-au-domains-split-*")), reverse=True
)[0]
df_merged = pd.read_csv(latest_split)
Let's count things!¶
How many third level domains are there?
len(pd.unique(df_merged["2"]))
1825
Which third level domains have the most subdomains?
df_merged["2"].value_counts()[:20]
nsw 8087 vic 3796 qld 3021 wa 2862 sa 1892 tas 1026 nt 792 act 385 embassy 152 nla 140 govspace 111 ga 98 health 84 ato 82 govcms 79 deewr 77 treasury 75 dest 69 abs 68 bom 63 Name: 2, dtype: int64
Which domains have the most unique pages?
top_20 = df_merged[["domain", "number_of_pages"]].sort_values(
by="number_of_pages", ascending=False
)[:20]
top_20.style.format({"number_of_pages": "{:,}"})
| domain | number_of_pages | |
|---|---|---|
| 6469 | trove.nla.gov.au | 14,053,042 |
| 20708 | nla.gov.au | 8,852,946 |
| 7925 | collectionsearch.nma.gov.au | 2,548,712 |
| 20468 | passwordreset.parliament.qld.gov.au | 2,089,256 |
| 18518 | parlinfo.aph.gov.au | 2,060,004 |
| 2400 | aph.gov.au | 1,776,889 |
| 28205 | bmcc.nsw.gov.au | 1,419,442 |
| 10710 | jobsearch.gov.au | 1,294,115 |
| 27173 | arpansa.gov.au | 1,279,296 |
| 27953 | abs.gov.au | 992,726 |
| 22648 | catalogue.nla.gov.au | 987,993 |
| 7521 | libero.gtcc.nsw.gov.au | 959,539 |
| 28006 | canterbury.nsw.gov.au | 957,261 |
| 13050 | library.campbelltown.nsw.gov.au | 935,191 |
| 3709 | defencejobs.gov.au | 895,158 |
| 11973 | health.gov.au | 882,471 |
| 15637 | webopac.gosford.nsw.gov.au | 854,803 |
| 1550 | library.lachlan.nsw.gov.au | 838,972 |
| 24291 | accc.gov.au | 828,948 |
| 17620 | data.aad.gov.au | 820,263 |
Are there really domains made up of 10 levels?
df_merged.loc[df_merged["9"].notnull()]["domain"].to_list()
['lifejacket.prod.apps.blue.prod.cds.transport.nsw.gov.au', '0-slwa.csiro.patron.eb20.com.henrietta.slwa.wa.gov.au', 'etoll.prod.apps.blue.prod.cds.transport.nsw.gov.au', '0-www.library.eb.com.au.henrietta.slwa.wa.gov.au', 'test-your-tired-self-prod.apps.p.dmp.aws.hosting.transport.nsw.gov.au']
Let's visualise things!¶
I thought it would be interesting to try and visualise all the subdomains as a circular dendrogram. After a bit of investigation I discovered the ETE Toolkit for the visualisation of phylogenetic trees – it seemed perfect. But to get data into ETE I first had to convert it into a Newick formatted string. Fortunately, there's a Python package for that.
Warning! While the code below will indeed generate circular dendrograms from a domain name hierarchy, if you have more than a few hundred domains you'll find that the image gets very big, very quickly. I successfully saved the whole of the gov.au domain as a 32mb SVG file, which you can (very slowly) view in a web browser or graphics program. But any attempt to save into another image format at a size that would make the text readable consumed huge amounts of memory and forced me to pull the plug.
def make_domain_tree(domains):
"""
Converts a list of urlkeys into a Newick tree via nodes.
"""
d_tree = Node()
for domain in domains:
domain = re.sub(r"\:\d+", "", domain)
sds = domain.split(",")
for i, sd in enumerate(sds):
parent = ".".join(reversed(sds[0:i])) if i > 0 else None
label = ".".join(reversed(sds[: i + 1]))
if not d_tree.get_node(label):
if parent:
d_tree.get_node(parent).add_descendant(Node(label))
else:
d_tree.add_descendant(Node(label))
return newick.dumps(d_tree)
# Convert domains to a Newick tree
full_tree = make_domain_tree(domains)
def save_dendrogram_to_file(tree, width, output_file):
t = Tree(tree, format=1)
circular_style = TreeStyle()
circular_style.mode = "c" # draw tree in circular mode
circular_style.optimal_scale_level = "full"
circular_style.root_opening_factor = 0
circular_style.show_scale = False
t.render(output_file, w=width, tree_style=circular_style)
First let's play safe by creating a PNG with a fixed width.
# Saving a PNG with a fixed width will work, but you won't be able to read any text
save_dendrogram_to_file(
full_tree, 1000, f'images/govau-all-{arrow.now().format("YYYYMMDDHHmmss")}-1000.png'
)
Here's the result!

This will save a zoomable SVG version that allows you to read the labels, but it will be very slow to use, and difficult to convert into other formats.
# Here be dendrodragons!
# I don't think width does anything if you save to SVG
save_dendrogram_to_file(
full_tree, 5000, f'images/govau-all-{arrow.now().format("YYYYMMDDHHmmss")}.svg'
)
Let's try some third level domains.
def display_dendrogram(label, level="2", df=df_merged, width=300):
domains = df.loc[df["2"] == label]["urlkey"].to_list()
tree = make_domain_tree(domains)
filename = (
f'images/{label}-domains-{arrow.now().format("YYYYMMDDHHmmss")}-{width}.png'
)
save_dendrogram_to_file(
tree,
width,
filename,
)
return f'<div style="width: 300px; float: left; margin-right: 10px;"><img src="{filename}" style=""><p style="text-align: center;">{label.upper()}</p></div>'
# Create dendrograms for each state/territory
html = ""
for state in ["nsw", "vic", "qld", "sa", "wa", "tas", "nt", "act"]:
html += display_dendrogram(state)
display(HTML(html))

NSW

VIC

QLD

SA
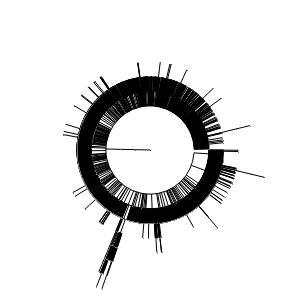
WA

TAS

NT

ACT
If there are fewer domains you can see more detail.
act = display_dendrogram(state, width=1000)
display(HTML(act))

ACT
I've generated and saved 5000px wide versions of the national and state dendrograms in a Cloudstor shared folder.
Created by Tim Sherratt for the GLAM Workbench. Support me by becoming a GitHub sponsor!
Work on this notebook was supported by the IIPC Discretionary Funding Programme 2019-2020.
The Web Archives section of the GLAM Workbench is sponsored by the British Library.