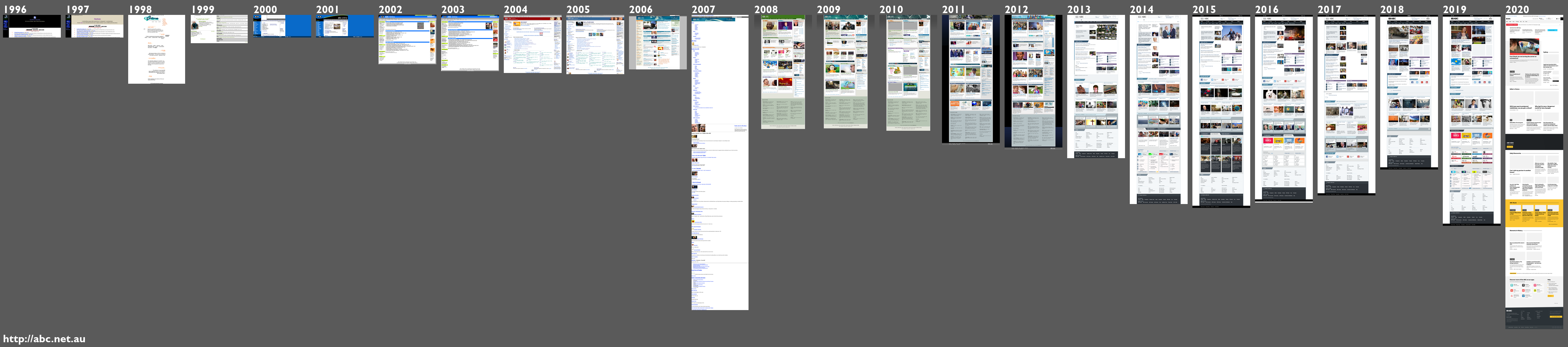
Using screenshots to visualise change in a page over time¶
TIMEMAPS VERSION
New to Jupyter notebooks? Try Using Jupyter notebooks for a quick introduction.
This notebook helps you visualise changes in a web page by generating full page screenshots for each year from the captures available in an archive. You can then combine the individual screenshots into a single composite image.
See TimeMap Visualization from the Web Science and Digital Libraries Research Group at Old Dominion University for another way of using web archive thumbnails to explore change over time.
Creating all the screenshots can be quite slow, and sometimes the captures themselves are incomplete, so I've divided the work into a number of stages:
- Create the individual screenshots
- Review the screenshot results and generate more screenshots if needed
- Create the composite image
More details are below.
If you want to create an individual screenshot, or compare a series of selected screenshots, see the Get full page screenshots from archived web pages notebook.
Import what we need¶
import base64
import io
import json
import math
import re
import time
from pathlib import Path
from urllib.parse import urlparse
import geckodriver_autoinstaller
import pandas as pd
import PIL
import requests
import selenium
from PIL import Image, ImageDraw, ImageFont
from selenium import webdriver
from selenium.webdriver.common.by import By
from slugify import slugify
geckodriver_autoinstaller.install()
# See https://github.com/ouseful-template-repos/binder-selenium-demoscraper
Define some functions¶
TIMEGATES = {
"nla": "https://web.archive.org.au/awa/",
"nlnz": "https://ndhadeliver.natlib.govt.nz/webarchive/",
"bl": "https://www.webarchive.org.uk/wayback/",
"ia": "https://web.archive.org/web/",
"is": "http://wayback.vefsafn.is/wayback/",
"ukgwa": "https://webarchive.nationalarchives.gov.uk/ukgwa/",
}
wayback = ["web.archive.org", "wayback.vefsafn.is"]
pywb = {
"web.archive.org.au": "replayFrame",
"webarchive.nla.gov.au": "replayFrame",
"webarchive.org.uk": "replay_iframe",
"ndhadeliver.natlib.govt.nz": "replayFrame",
"webarchive.nationalarchives.gov.uk": "replay_iframe",
}
html_output = []
def convert_lists_to_dicts(results):
"""
Converts IA style timemap (a JSON array of arrays) to a list of dictionaries.
Renames keys to standardise IA with other Timemaps.
"""
if results:
keys = results[0]
results_as_dicts = [dict(zip(keys, v)) for v in results[1:]]
else:
results_as_dicts = results
# Rename keys
for d in results_as_dicts:
d["status"] = d.pop("statuscode")
d["mime"] = d.pop("mimetype")
d["url"] = d.pop("original")
return results_as_dicts
def get_capture_data_from_memento(url, request_type="head"):
"""
For OpenWayback systems this can get some extra cpature info to insert in Timemaps.
"""
if request_type == "head":
response = requests.head(url)
else:
response = requests.get(url)
headers = response.headers
length = headers.get("x-archive-orig-content-length")
status = headers.get("x-archive-orig-status")
status = status.split(" ")[0] if status else None
mime = headers.get("x-archive-orig-content-type")
mime = mime.split(";")[0] if mime else None
return {"length": length, "status": status, "mime": mime}
def convert_link_to_json(results, enrich_data=False):
"""
Converts link formatted Timemap to JSON.
"""
data = []
for line in results.splitlines():
parts = line.split("; ")
if len(parts) > 1:
link_type = re.search(
r'rel="(original|self|timegate|first memento|last memento|memento)"',
parts[1],
).group(1)
if link_type == "memento":
link = parts[0].strip("<>")
timestamp, original = re.search(r"/(\d{12}|\d{14})/(.*)$", link).groups()
capture = {"timestamp": timestamp, "url": original}
if enrich_data:
capture.update(get_capture_data_from_memento(link))
data.append(capture)
return data
def get_timemap_as_json(timegate, url):
"""
Get a Timemap then normalise results (if necessary) to return a list of dicts.
"""
tg_url = f"{TIMEGATES[timegate]}timemap/json/{url}/"
print(tg_url)
response = requests.get(tg_url)
response_type = response.headers["content-type"].split(";")[0]
# pywb style Timemap
if response_type == "text/x-ndjson":
data = [json.loads(line) for line in response.text.splitlines()]
# IA Wayback stype Timemap
elif response_type == "application/json":
data = convert_lists_to_dicts(response.json())
# Link style Timemap (OpenWayback)
elif response_type in ["application/link-format", "text/html"]:
data = convert_link_to_json(response.text)
return data
def get_full_page_screenshot(url, save_width=200):
"""
Gets a full page screenshot of the supplied url.
By default resizes the screenshot to a maximum width of 200px.
Provide a 'save_width' value to change this.
NOTE the webdriver sometimes fails for unknown reasons. Just try again.
"""
global html_output
domain = urlparse(url)[1].replace("www.", "")
# NZ and IA inject content into the page, so we use if_ to get the original page (with rewritten urls)
if domain in wayback and "if_" not in url:
url = re.sub(r"/(\d{12}|\d{14})/http", r"/\1if_/http", url)
print(url)
date_str, site = re.search(r"/(\d{14}|\d{12})(?:if_|mp_)*/https*://?(.+/)", url).groups()
ss_dir = Path("screenshots", slugify(site))
ss_dir.mkdir(parents=True, exist_ok=True)
ss_file = Path(ss_dir, f"{slugify(site)}-{date_str}-{save_width}.png")
if not ss_file.exists():
options = webdriver.FirefoxOptions()
options.headless = True
driver = webdriver.Firefox(options=options)
driver.implicitly_wait(15)
driver.get(url)
# Give some time for everything to load
time.sleep(30)
driver.maximize_window()
# UK and AU use pywb in framed replay mode, so we need to switch to the framed content
if domain in pywb:
try:
driver.switch_to.frame(pywb[domain])
except selenium.common.exceptions.NoSuchFrameException:
# If we pass here we'll probably still get a ss, just not full page -- better than failing?
pass
ss = None
for tag in ["body", "html", "frameset"]:
try:
elem = driver.find_element(By.TAG_NAME, tag)
ss = elem.screenshot_as_base64
break
except (
selenium.common.exceptions.NoSuchElementException,
selenium.common.exceptions.WebDriverException,
):
pass
driver.quit()
if not ss:
print(f"Couldn't get a screenshot of {url} – sorry...")
else:
img = Image.open(io.BytesIO(base64.b64decode(ss)))
ratio = save_width / img.width
(width, height) = (save_width, math.ceil(img.height * ratio))
resized_img = img.resize((width, height), PIL.Image.Resampling.LANCZOS)
resized_img.save(ss_file)
return ss_file
else:
return ss_file
def get_screenshots(timegate, url, num=1):
"""
Generate up to the specified number of screenshots for each year.
Queries Timemap for snapshots of the given url from the specified repository,
then gets the first 'num' timestamps for each year.
"""
data = get_timemap_as_json(timegate, url)
df = pd.DataFrame(data)
# Convert the timestamp string into a datetime object
df["date"] = pd.to_datetime(df["timestamp"])
# Sort by date
df.sort_values(by=["date"], inplace=True)
# Only keep the first instance of each digest if it exists
# OpenWayback systems won't return digests
try:
df.drop_duplicates(subset=["digest"], inplace=True)
except KeyError:
pass
# Extract year from date
df["year"] = df["date"].dt.year
# Get the first 'num' instances from each year
# (you only need one, but if there are failures, you might want a backup)
df_years = df.groupby("year", as_index=False).head(num)
timestamps = df_years["timestamp"].to_list()
for timestamp in timestamps:
capture_url = f"{TIMEGATES[timegate]}{timestamp}/{url}"
capture_url = (
f"{capture_url}/" if not capture_url.endswith("/") else capture_url
)
print(f"Generating screenshot for: {capture_url}...")
get_full_page_screenshot(capture_url)
def make_composite(url):
"""
Combine single screenshots into a composite image.
Loops through images in a directory with the given (slugified) domain.
"""
max_height = 0
url_path = re.sub(r"^https*://", "", url)
pngs = sorted(Path("screenshots", slugify(url_path)).glob("*.png"))
for png in pngs:
img = Image.open(png)
if img.height > max_height:
max_height = img.height
height = max_height + 110
width = (len(pngs) * 200) + (len(pngs) * 10) + 10
comp = Image.new("RGB", (width, height), (90, 90, 90))
# Canvas to write in the dates
draw = ImageDraw.Draw(comp)
# Change this to suit your system
# font = ImageFont.truetype("/Library/Fonts/Microsoft/Gill Sans MT Bold.ttf", 36)
# Something like this should work on Binder?
font = ImageFont.truetype(
"/usr/share/fonts/truetype/liberation/LiberationSansNarrow-Regular.ttf", 36
)
draw.text((10, height - 50), url, (255, 255, 255), font=font)
for i, png in enumerate(pngs):
year = re.search(r"-(\d{4})(\d{10}|\d{8}).*?\.png", png.name).group(1)
draw.text(((i * 210) + 10, 10), year, (255, 255, 255), font=font)
img = Image.open(png)
comp.paste(img, ((i * 210) + 10, 50))
comp.save(Path("screenshots", f"{slugify(url_path)}.png"))
Create screenshots¶
Edit the cell below to change the timegate and url values as desired. Timegate values can be one of:
bl– UK Web Archiveukgwa– UK Government Web Archivenla– National Library of Australianlnz– National Library of New Zealandia– Internet Archiveis– Icelandic Web Archive
The num parameter is the maximum number of screenshots to create for each year. Of course you only need one screenshot per year for the composite image, but getting two is allows you to select the best capture before generating the composite.
Screenshots will be saved in a sub-directory of the screenshots directory. The name of the sub-directory will a slugified version of the url. Screenshots are named with the url, timestamp and width (which is set at 200 in this notebook). Existing screenshots will not be overwritten, so if the process fails you can easily pick up where it left off by just running the cell again.
# Edit timegate and url values
get_screenshots(timegate="ukgwa", url="http://mod.uk/", num=1)
Review Screenshots¶
Have a look at the results in the screenshots directory. If you've created more than one per year, choose the best one and delete the others. If you're not satisfied with a particular capture, you can browse the web interface of the archive until you find the capture you're after. Then just copy the url of the capture (it should have a timestamp in it) and feed it directly to the get_full_page_screenshot() function as indicated in the cell below. Once you're happy with your collection of screenshots, move on to the next step.
# Use this to add individual captures to fill gaps, or improve screenshots
# Just paste in a url from the archive's web interface
get_full_page_screenshot(
"http://wayback.vefsafn.is/wayback/20200107111708/https://www.government.is/"
)
Create composite¶
Edit the cell below to include the url that you've generated the screenshots from. The script will grap all of the screenshots in the corrresponding directory and build the composite image. The composite will be saved in the screenshots directory using a slugified version of the url as a name.
If you're running this on your own machine, you'll probably need to edit the function to set the font location where indicated.
# Edit url as required
make_composite("http://digitalnz.org/")
Created by Tim Sherratt for the GLAM Workbench. Support me by becoming a GitHub sponsor!
Work on this notebook was supported by the IIPC Discretionary Funding Programme 2019-2020.
The Web Archives section of the GLAM Workbench is sponsored by the British Library.