Lets-Plot Usage Guide¶
Lets-Plot is an open-source plotting library for statistical data. It is implemented using the Kotlin programming language that has a multi-platform nature. That's why Lets-Plot provides the plotting functionality that is packaged as a JavaScript library, a JVM library, and a native Python extension.
The design of the Lets-Plot library is heavily influenced by ggplot2 library.
Installation¶
Library is distributed via Maven Repository.
You can include it in your Kotlin or Java project using Maven or Gradle configuration files (see also Developer guide),
or include it in your Jupyter notebook script via %use lets-plot annotation (see Kotlin kernel for IPython/Jupyter).
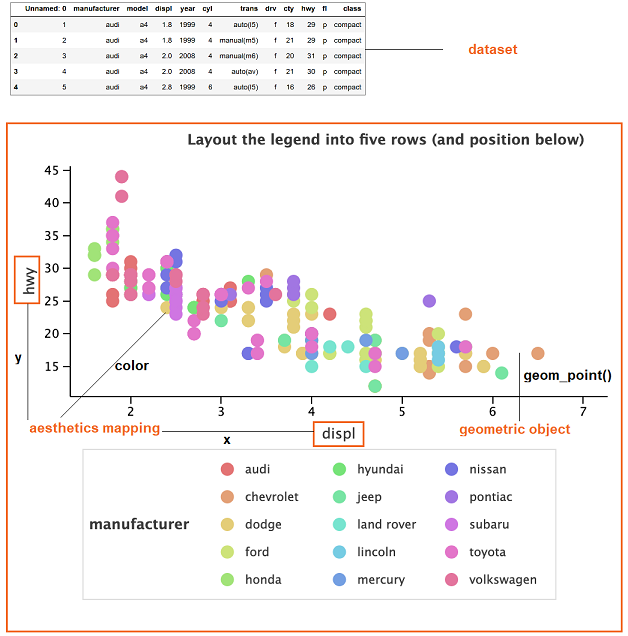
Understanding Lets-Plot architecture¶
In lets-plot, the plot is represented at least by one
layer. It can be built based on the default dataset with the aesthetics mappings, set of scales, or additional
features applied.
The Layer is responsible for creating the objects painted on the ‘canvas’ and it contains the following elements:
- Data - the set of data specified either once for all layers or on a per layer basis.
One plot can combine multiple different datasets (one per layer).
- Aesthetic mapping - describes how variables in the dataset are mapped to the visual properties of the layer, such as color, shape, size, or position.
- Geometric object - a geometric object that represents a particular type of charts.
- Statistical transformation - computes some kind of statistical summary on the raw input data.
For example, bin statistics is used for histograms and smooth is used for regression lines.
Most stats take additional parameters to specify details of the statistical transformation of data.
- Position adjustment - a method used to compute the final coordinates of geometry.
Used to build variants of the same geom object or to avoid overplotting.
Learning API¶
The typical code fragment that plots a Lets-Plot chart looks as follows:
import org.jetbrains.letsPlot.*
import org.jetbrains.letsPlot.geom.*
import org.jetbrains.letsPlot.stat.*
p = letsPlot(<dataframe>)
p + geom<ChartType>(stat=<stat>, position=<adjustment>) { <aesthetics mapping> }
Geometric objects geom¶
You can add a new geometric object (or plot layer) by creating it using the geomXxx() function and then adding this object to ggplot:
p = letsPlot(data=df)
p + geomPoint()
See the geom reference for more information about the supported geometric objects, their arguments, and default values.
There is also a few statXxx() functions which also create a plot layer.
Occasionally, it feels more naturally to use statXxx() instead of geomXxx() function to add a new plot layer.
For example, you might prefer to use statCount() instead of geomBar().
See the stat layer reference for more information about the supported stat plot-layer objects, their arguments, and default values.
Collections of plots¶
With the GGBunch() object, you can
render a collection of plots.
Use the addPlot() method to add a plot to the bunch and set an arbitrary location and size for plots inside the grid:
bunch = GGBunch()
.addPlot(plot1, 0, 0)
.addPlot(plot2, 0, 200)
bunch.show()
See the ggbunch.ipynb example for more information.
Stat stat¶
Add stat as an argument to geomXxx() function to define statistical data transformations:
geomPoint(stat=Stat.count())
Supported statistical transformations:
identity: leave the data unchangedcount: calculate the number of points with same x-axis coordinatebin: calculate the number of points falling in each of adjacent equally sized ranges along the x-axisbin2d: calculate the number of points falling in each of adjacent equal sized rectangles on the plot planesmooth: perform smoothingcontour,contourFilled, : calculate contours of 3D databoxplot: calculate components of a box plot.density,density2D,density2DFilled: perform a kernel density estimation for 1D and 2D data
See the stat reference for more information about the supported stat objects, their arguments, and default values.
Aesthetic mappings mapping¶
With mappings, you can define how variables in dataset are mapped to the visual elements of the chart.
Add the {x=< >; y=< >; ...} closure to geom, where:
x: the dataframe column to map to the x axis.y: the dataframe column to map to the y axis....: other visual properties of the chart, such as color, shape, size, or position.
geom_point() {x = "cty"; y = "hwy"; color="cyl"}
Position adjustment position¶
All layers have a position adjustment that computes the final coordinates of geometry.
Position adjustment is used to build variances of the same plots and resolve overlapping.
Override the default settings by using the position argument in the geom functions:
geomBar(position=positionFill)
or
geomBar(position=positionDodge(width=1.01))
Available adjustments:
dodgejitterjitterdodgenudgeidentityfillstack
See position functions reference for more information about position adjustments.
Features affecting the entire plot¶
Scales¶
Enables choosing a reasonable scale for each mapped variable depending on the variable attributes. Override default scales to tweak details like the axis labels or legend keys, or to use a completely different translation from data to aesthetic. For example, to override the fill color on the histogram:
p + geomHistogram() + scaleFillContinuous("red", "green")
See the list of the available scale methods in the scale reference
Coordinated system¶
The coordinate system determines how the x and y aesthetics combine to position elements in the plot. For example, to override the default X and Y ratio:
p + coordFixed(ratio=2)
See the list of the available methods in coordinates reference
Legend¶
The axes and legends help users interpret plots.
Use the guide methods or the guide argument of the scale method to customize the legend.
For example, to define the number of columns in the legend:
p + scaleColorDiscrete(guide=guideLegend(ncol=2))
See more information about the guideColorbar, guideLegend functions in the scale reference
Adjust legend location on plot using the theme legendPosition, legendJustification and legendDirection methods, see:
theme reference
Sampling¶
Sampling is a special technique of data transformation built into Lets-Plot and it is applied after stat transformation.
Sampling helps prevents UI freezes and out-of-memory crashes when attempting to plot an excessively large number of geometries.
By default, the technique applies automatically when the data volume exceeds a certain threshold.
The samplingNone value disables any sampling for the given layer. The sampling methods can be chained together using the + operator.
Available methods:
samplingRandomStratified: randomly selects points from each group proportionally to the group size but also ensures
that each group is represented by at least a specified minimum number of points.
samplingRandom: selects data points at randomly chosen indices without replacement.samplingPick: analyses X-values and selects all points which X-values get in the set of firstnX-values found in the population.samplingSystematic: selects data points at evenly distributed indices.samplingCertexDP,samplingVertexVW: simplifies plotting of polygons.
There is a choice of two implementation algorithms: Douglas-Peucker (DP) and
Visvalingam-Whyatt (VW).
For more details, see the sampling reference.
Getting started¶
Let's plot a point chart built using the mpg dataset.
Create the DataFrame object and retrieve the data.
%useLatestDescriptors
%use lets-plot
@file:DependsOn("com.github.doyaaaaaken:kotlin-csv-jvm:0.7.3")
import com.github.doyaaaaaken.kotlincsv.client.*
val csvData = java.io.File("mpg.csv")
val mpg: List<Map<String, String>> = CsvReader().readAllWithHeader(csvData)
fun col(name: String, discrete: Boolean=false): List<*> {
return mpg.map {
val v = it[name]
if(discrete) v else v?.toDouble()
}
}
val df = mapOf(
"displ" to col("displ"),
"hwy" to col("hwy"),
"cyl" to col("cyl"),
"index" to col(""),
"cty" to col("cty"),
"drv" to col("drv", true),
"year" to col("year")
)
Plot the basic point chart.
Perform the following aesthetic mappings:
x= displ (the displ column of the dataframe)y= hwy (the hwy column of the dataframe)color= cyl (the cyl column of the dataframe)
// Mapping
letsPlot(df) {x = "displ"; y = "hwy"; color = "cyl"} + geomPoint(df)
Apply statistical data transformation to count the number of cases at each x position.
val p = letsPlot(df)
p + geomPoint(df, stat = Stat.count()) {x = "displ"; color = "..count.."; size = "..count.."}
Change the pallete and the legend, add the title.
val p = letsPlot(df) {x = "displ"; y = "hwy"; color = "cyl"}
p +
geomPoint(df, position = positionNudge()) +
scaleColorContinuous("red", "green", guide = guideLegend(ncol=2)) +
ggtitle("Displacement by horsepower")
Apply the randomly stratified sampling to select points from each group proportionally to the group size.
val p = letsPlot(df) {x = "displ"; y = "hwy"; color = "cyl"}
p + geomPoint(
data=df, position = positionNudge(),
sampling = samplingRandomStratified(40)
) + scaleColorContinuous(
"blue", "pink",
guide = guideLegend(ncol=2)
)