
Regular Expressions in R¶
This tutorial introduces regular expressions and how they can be used when working with language data.
What are regular expressions?¶
Regular expressions, also known as regex, are patterns used to match and manipulate text. They are a powerful tool used in computer programming, data processing, and text editing.
A regular expression is a sequence of characters that defines a search pattern. They can be used to search for specific patterns in text, extract information from text, and replace text. For example, you could use a regular expression to search for all email addresses in a text file, extract all phone numbers from a web page, or replace all instances of a word in a document.
Regular expressions are supported in many programming languages, text editors, and command-line tools, such as R, Python, or Perl. Although the may be minor differences, regular expressions are very consistent across programming languages.
Preparation and session set up
In this tutorial, we will explore regular expressions in R and to start, we need to load the necessary packages.
library(dplyr)
library(stringr)
Once you have installed RStudio and have initiated the session by executing the code shown above, you are good to go.
Explaining the code¶
This section uses a couple of commands. Below is list with explanations of what these commands mean and what they do to help you understand the code shown below.
readLines(): reads in a text line-by-line%>%: called the pipe and can be read as and thenunlist(): flattens a list to a simple vector (from a hierarchical/nested to a flat data structure)str_detect()andstr_detect_all(): checks if a pattern occurs in a string (text element)str_remove()andstr_remove_all(): removes a pattern from a string (text element)str_replace()andstr_replace_all(): replaces a pattern in a string (text element) with another patternstr_view()andstr_view_all(): highlights a pattern in a string (text element)
Getting started with Regular Expressions¶
To put regular expressions into practice, we need some text that we will perform out searches on. In this tutorial, we will use texts from wikipedia about grammar.
# read in first text
text1 <- readLines("https://slcladal.github.io/data/testcorpus/linguistics02.txt")
et <- paste(text1, sep = " ", collapse = " ")
# inspect example text
et
In addition, we will split the example text into words to have another resource we can use to understand regular expressions
# split example text
set <- str_split(et, " ") %>%
unlist()
# inspect
head(set)
Before we delve into using regular expressions, we will have a look at the regular expressions that can be used in R and also check what they stand for.
There are three basic types of regular expressions:
regular expressions that stand for individual symbols and determine frequencies
regular expressions that stand for classes of symbols
regular expressions that stand for structural properties
The regular expressions below show the first type of regular expressions, i.e. regular expressions that stand for individual symbols and determine frequencies.

The regular expressions below show the second type of regular expressions, i.e. regular expressions that stand for classes of symbols.
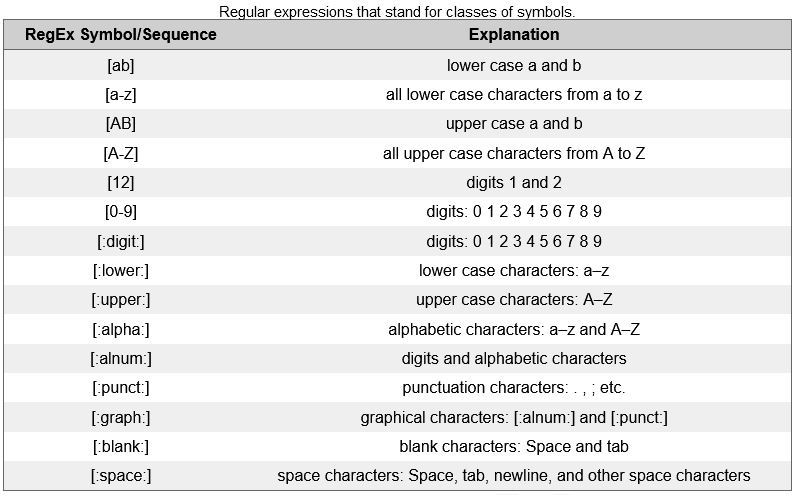
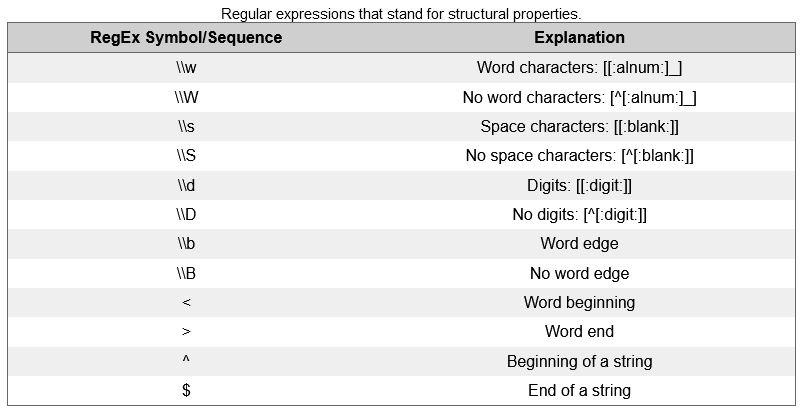
The regular expressions that denote classes of symbols are enclosed in [] and :. The last type of regular expressions, i.e. regular expressions that stand for structural properties are shown below.
Demonstration¶
In this section, we will explore how to use regular expressions. At the end, we will go through some exercises to help you understand how you can best utilize regular expressions.
Show all words in the split example text that contain a or n.
set[str_detect(set, "[an]")]
Show all words in the split example text that begin with a lower case a.
set[str_detect(set, "^a")]
Show all words in the split example text that end in a lower case s.
set[str_detect(set, "s$")]
Show all words in the split example text in which there is an e, then any other character, and than another n.
set[str_detect(set, "e.n")]
Show all words in the split example text in which there is an e, then two other characters, and than another n.
set[str_detect(set, "e.{2,2}n")]
Show all words that consist of exactly three alphabetical characters in the split example text.
set[str_detect(set, "^[:alpha:]{3,3}$")]
Show all words that consist of six or more alphabetical characters in the split example text.
set[str_detect(set, "^[:alpha:]{6,}$")]
Replace all lower case as with upper case Es in the example text.
str_replace_all(et, "a", "E")
Remove all non-alphabetical characters in the split example text.
str_remove_all(set, "\\W")
Remove all white spaces in the example text.
str_remove_all(et, " ")
Escaping regular expressions
Remove . and ? and ,:
str_replace_all(text1, "\\.|\\?|,", " PUNCTUATION ")
Removing superfluous white spaces
whitespaces <- " This is a test sentence with superfluous white spaces "
# inspect
whitespaces
# remove superfluous white spaces
perfectwhitespaces <- str_squish(whitespaces)
# inspect
perfectwhitespaces
Replacing elements at the beginning and end of strings
Find strings that begin with a w
str_detect(set, "^w")
set[str_detect(set, "^w")]
Find all words that end with s or es:
set[str_detect(set, "e{0,1}s$")]
Limiting scope of regular expressions
We want to limit how far a regular expression extends:
limiting <- "This <get> is <rid> an </of> example <this/> sentence. "
str_remove_all(limiting, "<.*>")
What happens is that the scope of .* extends to the last instance of >. We can limit the scope by adding a ?:
str_remove_all(limiting, "<.*?>")
Highlighting patterns
We use the str_view and str_view_all functions to show the occurrences of regular expressions in the example text.
To begin with, we match an exactly defined pattern (ang).
str_view_all(et, "ang")
Now, we include . which stands for any symbol (except a new line symbol).
str_view_all(et, ".n.")
Practice¶
practicetext <- c("HTML, which stands for HyperText Markup Language, is the standard language used to create web pages. It's comprised of different tags, such as <html>, <head>, <body>, <p>, <a>, and <img>, that are used to define the structure and content of a web page.
Phone numbers can be written in various formats, but a common one in the US is (555) 555-5555. Another common format is 555-555-5555. Regular expressions can be used to match and extract phone numbers from text.")
Task 1¶
Extract all phone numbers.
practicetext
Task 2¶
Split text into words.
practicetext
Task 3¶
Extract all words containing the sequence ex.
practicetext
Task 4¶
Find all words that begin with an n
practicetext
Task 5¶
Find all words that end with a h.
practicetext
Task 6¶
Remove all html tags.
practicetext
Task 7¶
Find all words with 2 or 3 characters.
practicetext
Task 8¶
Remove all words that contain 4 characters.
practicetext
Task 9¶
Replace all words with 3 characters with the sequence LOL.
practicetext
Task 10¶
Extract all words that begin with a capital letter.
practicetext
sessionInfo()