Primer 2¶
This is the second of a series of primers on the use of Text-Fabric for analyzing proto-cuneiform. In this primer we will be looking at one of the most distinctive features of proto-cuneiform, namely the sometimes elaborate ways in which subcases are used to express sub-categorization in proto-cuneiform texts.
The first of the primers, Primer 1 is available here, and there is also a set of tutorials on the use of Text-Fabric to analyze proto-cuneiform are available here.
In this primer we are going to focus on a tablet that exhibits a relatively simple use of subcases: P005162 was published as MSVO 1, 95, and deals with livestock and textiles. We will be looking in particular at the use of subcases to divide up a group of thirty sheep and goats (UDU~a) between two institutions or bureaus: |1(N58).BAD~a| and UKKIN~a.
import collections
from IPython.display import display, Markdown
from tf.extra.cunei import Cunei
LOC = ("~/github", "Nino-cunei/uruk", "primer2")
A = Cunei(*LOC)
A.api.makeAvailableIn(globals())
Found 2095 ideograph linearts Found 2724 tablet linearts Found 5495 tablet photos
Documentation: Uruk IV-III (v1.0) Feature docs Cunei API Text-Fabric API Search Reference
def dm(markdown):
display(Markdown(markdown))
We call up P005162, and look into the relatively simple examples of the use of subcases that we find in this tablet.
pNum = "P005162"
query = f"""
tablet catalogId={pNum}
"""
results = A.search(query)
tablet = results[0][0]
A.lineart(tablet, width=300)
A.show(results, withNodes=False)
1 result
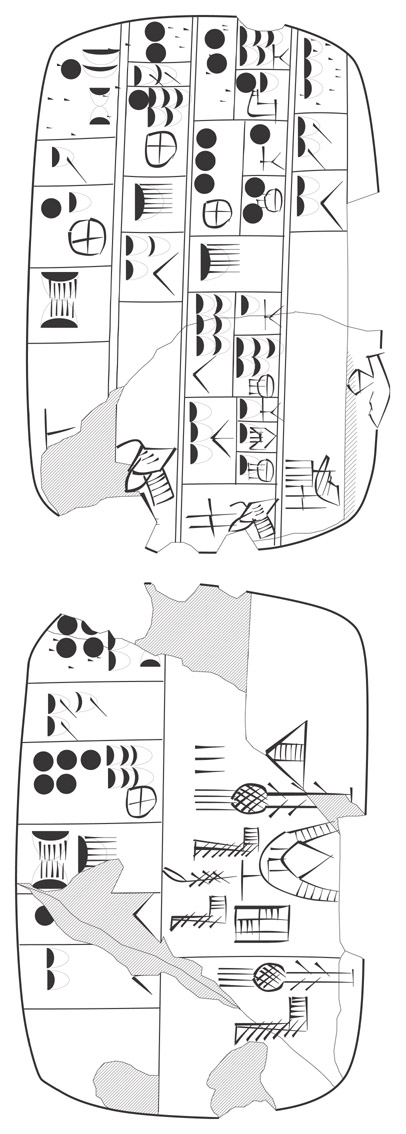
Tablet 1¶
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)

.jpg)

.jpg)
.jpg)
.jpg)
.jpg)
.jpg)



.jpg)
.BAD~a|.jpg)
.jpg)

.jpg)
.jpg)

.jpg)

.AMAR|.jpg)

.jpg)
.jpg)



.jpg)
.jpg)
.jpg)
.jpg)






If we take a look at this transliteration, there are two nice example of subcases used to show subcategorization in column 3, namely in lines 1 and 2 and lines 4 and 5. Let's zoom in to the column (we read the node of the column from the display above).
A.pretty(189761)
In the transliteration we can tell that these lines include subcases because of the curious form of the line numbers: in line 2, "2.a" marks the superordinate subcase within line 2, while "2.b1" and "2.b2" represent subcases subordinated to "2.a" in the same line.
Let's focus on line 2 and show the ATF source for that line.
line = 252264
A.pretty(line)
A.getSource(line)
['2.a. 3(N14) , UDU~a ', '2.b1. 1(N14) , |1(N58).BAD~a| ', '2.b2. 2(N14) , UKKIN~a ']
Another way, to get these source lines directly is as follows:
line = T.nodeFromSection((pNum, "obverse:3", "2"))
A.getSource(line)
['2.a. 3(N14) , UDU~a ', '2.b1. 1(N14) , |1(N58).BAD~a| ', '2.b2. 2(N14) , UKKIN~a ']
If we want to pick out one of these subcases in Text-Fabric, we simply use the same notation for subcases in the transliteration and replace "T.nodeFromSection" to "T.nodeFromCase".
case = A.nodeFromCase((pNum, "obverse:3", "2b2"))
A.pretty(case)
A.getSource(case)
['2.b2. 2(N14) , UKKIN~a ']
These subcases are dividing up a group of 30 sheep and goats, viz. 3(N14) UDU~a, into two groups, the first of which consists of tens animals (1(N14)) and is assigned to the quad |1(N58).BAD~a|, while the second consists of twenty animals (2(N14)) and is assigned to UKKIN~a.
Structure and coding of subcases in the proto-cuneiform corpus¶
The structure and coding of subcases in proto-cuneiform is described in considerable detail in the introduction to The Proto-Cuneiform Texts from Jemdet Nasr I: Copies, Transliterations and Glossary (Englund, Grégoire, and Matthews 1991 = MSVO 1) and also in Englund's "Texts from the Late Uruk Period" in the OBO series, available online here.
This following is one of its key diagrams:

But we are just going to look at the first line in the first column. The following is a single line, with one subcase on the left and three subcases on the right.

The basic principle here is that each position in the line number labels an additional subdivision within the case: "1" in first position labels the entire first line (including 1a, 1b1, 1b2 and 1b3, note that in the diagram "1b1" is abbreviated as "b1"), the opposition between "a" and "b" in the second position marks the opposition between subcase "1a" on the left and the three subcases "b1", "b2" and "b3" on the right, and, lastly, the differentiation between "1", "2" and "3" in the third position in the line number codes the three subdivisions within "1b", namely "1b1", "1b2" and "1b3". Now let's go through the coding of subcases again with a real example.
Here we have the same passage we started with above:
2.a. 3(N14) , UDU~a
2.b1. 1(N14) , |1(N58).BAD~a|
2.b2. 2(N14) , UKKIN~a
The line as a whole, which is equivalent to all three of these "lines" in the transliteration, is in the blue box below. Because of this all three of these "lines" begins with "2".

This is how Text-Fabric show it.
A.pretty(T.nodeFromSection((pNum, "obverse:3", "2")))
The second position in the line number, here the "a" following the period, differentiates "2.a"
2.a. 3(N14) , UDU~a
in the left subcase from "2.b"
2.b1. 1(N14) , |1(N58).BAD~a|
2.b2. 2(N14) , UKKIN~a
which consists of two subcases on the right. In the following snapshot, "2.a" on the left is in the red box, while "2.b" on the right is in the green box.

The third position in the line number codes a third subdivision within "2.b", namely within the green box above. This third subdivision distinguishes between
2.b1. 1(N14) , |1(N58).BAD~a|
which is in the upper subcase within "2.b" and is therefore called "2.b1" and
2.b2. 2(N14) , UKKIN~a
which is in the lower subcase within "2.b" and is therefore called "2.b2". In the following snapshot, the upper subcase "2.b1" is in an orange box, while the lower subcase "2.b2" is in a purple box.

Searching for data in proto-cuneiform subcases in Text-Fabric¶
Now that we have specified how the subcases are defined in line numbers in the proto-cuneiform corpus, we can start using Text-Fabric to search for the contents of certain hierarchical levels within subcases. First, let's start by looking at how many occurrences there are of subcases, sub-subcases, sub-sub-subcases and so on. Text-Fabric has a "A.casesByLevel" command, which takes two arguments: the level you are looking for and whether or not the results should exclude cases that are divided themselves.
Undivided lines and cases are called terminal cases. They each correspond to a single "line of transliteration" in ATF. Any time a line or a case is subdivided in the proto-cuneiform corpus, each of the resulting subcases is represented on a separate "line" in the transliteration. (Strictly speaking, a "line" is a subdivision of a column or face, and should not be confused with a "line of transliteration," which could correspond to a line, a subcase, a sub-subcase and so on). Divided lines and/or cases always correspond to multiple "lines of transliteration" in the ATF.
Only if we restrict ourselves to undivided lines and cases, will the materials in those segments of text add up: undivided or "terminal" lines and cases do not share signs and quads with other undivided lines and cases, but divided lines and cases always share their material with their subcases. So, in order to investigate material that occurs at a specific level of cases, set terminal to True. If you find material in a terminal case at level n, you know that it does not occur in subcases of that same case (level > n), because terminal cases do not have subcases. If terminal is set to False, subcases of the referenced level are included and the same material will get counted multiple times.
First, let's write out the set of definitions for four distinct levels of subdivision and then count the number of cases at each level.
Level 0 corresponds to undivided lines, level 1 refers to the subdivisions within a line, level 2 refers to the sub-subcases within a subcase, and so on. Note that the number of the sublevel corresponds to the number of elements that follow the initial line number in the designation at the beginning of a "line of transliteration":
1is level 01ais level 11a1is level 21a1Ais level 31a1A1is level 4
Now let's ask Text-Fabric to count up the number of occurrences of each level in the corpus.
for level in range(10):
sublevelT = A.casesByLevel(level)
sublevel = A.casesByLevel(level, terminal=False)
allCases = len(sublevel)
terminalCases = len(sublevelT)
dividedCases = allCases - terminalCases
print(f"level {level}:")
print(f" all cases/lines: {allCases:>5}")
print(f" terminal cases/lines: {terminalCases:>5}")
print(f" divided cases/lines: {dividedCases:>5}")
if allCases == 0:
break
level 0:
all cases/lines: 35842
terminal cases/lines: 32732
divided cases/lines: 3110
level 1:
all cases/lines: 6559
terminal cases/lines: 5468
divided cases/lines: 1091
level 2:
all cases/lines: 2719
terminal cases/lines: 2595
divided cases/lines: 124
level 3:
all cases/lines: 254
terminal cases/lines: 218
divided cases/lines: 36
level 4:
all cases/lines: 119
terminal cases/lines: 119
divided cases/lines: 0
level 5:
all cases/lines: 0
terminal cases/lines: 0
divided cases/lines: 0
First of all, it should be clear that the vast majority of subcases are at level 1, the shallowest level of subdivision, where 3110 lines are dividied into 6559 cases. If each of those 3110 lines had been divided into two cases, we would have only 6220 cases, so the remaining 339 "extra" cases at level 1 could be grouped in many different ways: three cases in one divided line, but ten in another.
In the intermediary levels: 1091 cases at level 1 are divided into 2719 subcases at level 2, 124 subcases at level 2 are divided into 254 sub-subcases at level 3, and 36 sub-subcases at level 3 are divided into 119 sub-sub-subcases at level 4. Since none of the 119 sub-sub-subcases at level 4 are further subdivided, all 119 are "terminal" and there are no sub-sub-sub-subcases at level 5.
The number of "extra" cases (beyond the minimal binary split) usually gets bigger as we go deeper: 339 "extra" cases at level 1 (5.2%), 537 "extra" subcases at level 2 (19.7%), and 47 "extra" sub-sub-subcases at level 4 (39.5%), but only 6 "extra" sub-subcases at level 3 (2.4%). This general pattern, except for level 3 of course, is probably due to the use of subdivided cases to list the names of individuals, an issue we will return to in another primer.
Sign frequencies at each hierarchical level¶
Since the most deeply embedded subdivision, namely sublevel4, has the fewest number of occurrences, let's start with that and see what kind of proto-cuneiform signs occur at sublevel4. The following snippet of code generates a list of all occurrences of sub-sub-sub-subcases, namely lines with line numbers like 2.b2B1 or 1.b2B4, which include four subdivisions after the line number.
sublevel4Nodes = A.casesByLevel(4)
for node in sublevel4Nodes:
(pNum, column, lineNum) = T.sectionFromNode(node)
srcLn = F.srcLn.v(node)
print(f"{pNum}:{column}:{lineNum} = {srcLn}")
P004735:obverse:2:1 = 1.b1B1. , (NAB DI |BU~a+DU6~a|)a P004735:obverse:2:1 = 1.b1B2. , (ZI~a#? AN)a P004735:obverse:2:1 = 1.b1B3. , (ANSZE~e 7(N57) DUR2 DU)a P004735:obverse:2:1 = 1.b1B4. , (LAL3~a#? GAR IG~b)a P004735:obverse:2:2 = 2.b2B1. , (GI6 KISZIK~a# URI3~a)a P004735:obverse:2:2 = 2.b2B2. , ([...])a P218054:reverse:1:1 = 1.a1A1. [...] 5(N01)# , [...] UDU~a#? P218054:reverse:1:1 = 1.a1A2. [...] 7(N01)# , MASZ2 P325754:reverse:1:1 = 1.c2b1. 1(N01) , [...] P325754:reverse:1:1 = 1.c2b2. 1(N14) 7(N01) , TUR P325754:reverse:1:1 = 1.c2b3. 2(N14) 6(N01) , SUR P325234:reverse:1:1 = 1.c5a1. 8(N01) , GAR U2~a P325234:reverse:1:1 = 1.c5a2. |SZU2.E2~b| P411608:obverse:1:1 = 1b2a1. 1(N01) , GAL~a P411608:obverse:1:1 = 1b2a2. 1(N01) , GA2~a1 TUR P411608:obverse:1:1 = 1b2b1. 1(N01) , |U4x3(N57)| P411608:obverse:1:1 = 1b2b2. 1(N01) , X P387752:obverse:0:1 = 1.b1.b01. , NIN NAB DI P387752:obverse:0:1 = 1.b1.b02. , SAL 1(N02) , PAP~a P387752:obverse:0:1 = 1.b1.b03. , BU~a U4 SI4~a P387752:obverse:0:1 = 1.b1.b04. , EN~a U4 P387752:obverse:0:1 = 1.b1.b05. [...] X P387752:obverse:0:1 = 1.b1.b06. , NAR P387752:obverse:0:1 = 1.b1.b07. , EN~a U4 P387752:obverse:0:1 = 1.b1.b08. , ZATU628~a KI P387752:obverse:0:1 = 1.b1.b09. [...] P387752:obverse:0:1 = 1.b1.b10. [...] P387752:obverse:0:1 = 1.b1.b11. , SAL# SAL P387752:obverse:0:1 = 1.b1.b12. , SZEG9 P387752:obverse:0:1 = 1.b1.b13. [...] P387752:obverse:0:1 = 1.b1.b14. [...] P387752:obverse:0:1 = 1.b1.b15. [...] P387752:obverse:0:1 = 1.b1.b16. , X GI4~a P387752:obverse:0:1 = 1.b1.b17. [...] P387752:obverse:0:1 = 1.b1.b18. [...] P387752:obverse:0:1 = 1.b1.b19. [...] P387752:obverse:0:1 = 1.b1.b20. [...] P387752:obverse:0:1 = 1.b2.b01. [...] P387752:obverse:0:1 = 1.b2.b02. , EN~a# [...] P387752:obverse:0:1 = 1.b2.b03. [...] P387752:obverse:0:1 = 1.b2.b04. [...] P387752:obverse:0:1 = 1.b2.b05. , NAGA~a P387752:obverse:0:1 = 1.b2.b06. [...] ZATU694~c# P387752:obverse:0:1 = 1.b2.b07. [...] P387752:obverse:0:1 = 1.b2.b08. , AN NIN DUB~a P387752:obverse:0:1 = 1.b2.b09. , NAGA~a HI P387752:obverse:0:1 = 1.b2.b10. [...] P387752:obverse:0:1 = 1.b2.b11. [...] P387752:obverse:0:1 = 1.b2.b12. , X NUN~a# [...] P387752:obverse:0:1 = 1.b2.b13. , HI@g~a [...] P387752:obverse:0:1 = 1.b2.b14. [...] P387752:obverse:0:1 = 1.b2.b15. [...] P387752:obverse:0:1 = 1.b2.b16. [...] P387752:obverse:0:1 = 1.b2.b17. [...] P387752:obverse:0:2 = 2.b1.b1. , AMA~a GI6 P387752:obverse:0:2 = 2.b1.b2. , X [...] P387752:obverse:0:2 = 2.b2.b1. , MA AN AMA~a P002856:obverse:2:3 = 3.b1B1. 2(N34) 2(N14) 4(N01) , SUHUR# [...] P002856:obverse:2:3 = 3.b1B2. 2(N14) 4(N01) , SUHUR# [...] P002856:obverse:2:3 = 3.b1B3. 4(N01) , SUHUR [...] P002856:obverse:2:3 = 3.b1B4. , [...] P006036:obverse:1:2 = 2.b1B1. , (EN~a# PAP~a#)a P006036:obverse:1:2 = 2.b1B2. , (3(N57) GAN2)a P006036:obverse:1:2 = 2.b2B1. , (EN~a |SZU2.E2~b|)a P006036:obverse:1:2 = 2.b2B2. , (BU~a SZU)a P006036:obverse:1:2 = 2.b2B3. , (SAL BU~a)a P006036:obverse:1:2 = 2.b2B4. , (EN~a HI KASZ~c)a P006056:reverse:1:3 = 3.b2B1. 2(N01) , EN~a SZE3 KUR~a P006056:reverse:1:3 = 3.b2B2. 3(N01) , DUB~a KUR~a P006092:obverse:1:2 = 2.b1A1. 1(N01) , SZUR2~a KU3~a E2~a P006092:obverse:1:2 = 2.b1A2. [1(N01)] , [...] P006160:obverse:1:2 = 2.b2B1. , ZATU836 BU~a SZE~a P006160:obverse:1:2 = 2.b2B2. , U8 LAGAB~a P006295:reverse:1:1 = 1.a1B1. 1(N01) , UD5~a P006295:reverse:1:1 = 1.a1B2. 3(N01) , MASZ2 P006307:reverse:1:2 = 2.b1B1. 2(N01)# , U8#? [...] P006307:reverse:1:2 = 2.b1B2. 1(N01)# , [...] P006307:reverse:1:2 = 2.b1B3. 4(N01) , UDUNITA~a#? [...] P006307:reverse:1:2 = 2.b1B4. 6(N01) , MASZ2#? P006307:reverse:1:2 = 2.b2B1. 2(N01) , U8? [...] P006307:reverse:1:2 = 2.b2B2. 1(N01) , SZE3 UDUNITA~a#? P006307:reverse:1:2 = 2.b2B3. 2(N01) , X [...] P005294:obverse:1:1 = 1.b1B1. , AN 3(N57) P005294:obverse:1:1 = 1.b1B2. , EN~a PA~a ERIN P005322:reverse:1:1 = 1.b1B1. 1(N20) 1(N42~a) 1(N25) , P005322:reverse:1:1 = 1.b1B2. 1(N18) 1(N40) 1(N24~a) , P005322:reverse:1:1 = 1.b2B1. 3(N20) 1(N05) 1(N42~a) , P005322:reverse:1:1 = 1.b2B2. 3(N18) 1(N03) 1(N40) , P005322:reverse:1:1 = 1.b3B1. 3(N20)# 1(N05) 2(N42~a) , P005322:reverse:1:1 = 1.b3B2. 4(N18) 5(N03)# 2(N40) , P005322:reverse:1:1 = 1.b4B1. 2(N05)? 2(N42~a)? , 1(N57)? SZE~a P005322:reverse:1:1 = 1.b4B2. 1(N03) 3(N40) , P002694:reverse:1:3 = 3.b1B1. , [...] P002694:reverse:1:3 = 3.b2B1. , X [...] P002694:reverse:1:3 = 3.b2B2. , X [...] P003529:obverse:2:3 = 3.b1A1. 1(N01) , DUG~c P003529:obverse:2:3 = 3.b1A2. 1(N01) , [...] P003529:obverse:2:3 = 3.b3B1. 2(N57) , SZA |U4x2(N01)| SZU P003529:obverse:2:3 = 3.b3B2. 1(N57) , |GIxSZE3| BAD P003531:obverse:1:1 = 1.b1A1. 1(N01) , BA AB~a AN MUSZ3~a P003531:obverse:1:1 = 1.b1A2. 1(N01) , SAL BA PIRIG~b1 P003808:obverse:3:2 = 2.b1B1. [...] , GAN~c SZU P003808:obverse:3:2 = 2.b1B2. , SZITA~a1 ADAB UTUL~a P003808:obverse:3:2 = 2.b2B1. 1(N57) , SZA SZU P003808:obverse:3:2 = 2.b2B2. 1(N57) , ZATU659? PAP~a SUKKAL P003808:obverse:5:2 = 2.a2A1. 1(N01) , E2~a ALAN~b NUN~a# TAK4~a P003808:obverse:5:2 = 2.a2A2. 1(N01) , ZATU651@g TAK4~a ALAN~b P003808:obverse:6:1 = 1.b1B1. [...] , [...] X P003808:obverse:6:1 = 1.b1B2. 1(N57) , DILMUN P003808:obverse:6:1 = 1.b2B1. 1(N57) , EN~a SZE3? TUR NUN~a P003808:obverse:6:1 = 1.b2B2. 1(N57) , X AN MUSZ3~a EN~a X P003808:obverse:6:1 = 1.b2B3. 1(N57) , SIG2~b P003808:obverse:6:1 = 1.b2B4. 1(N57) , E2~a GU P003808:obverse:6:2 = 2.b1B1. 1(N57) , EN~a# SAG# P003808:obverse:6:2 = 2.b1B2. 1(N57) , HI E2~a DILMUN NUN~a P003808:obverse:6:2 = 2.b1B3. 1(N57) , NAMESZDA P003808:obverse:6:2 = 2.b1B4. 1(N57) , GESZTU~a? DIM~a P003808:obverse:6:2 = 2.b1B5. 1(N57) , SZA SZU P003808:obverse:6:2 = 2.b1B6. 1(N57) , GI BAD
The 119 occurrences all show up in Text-Fabric, but perhaps it is easier if we just look at the first twenty or so occurrences.
for node in sublevel4Nodes[0:20]:
(pNum, column, lineNum) = T.sectionFromNode(node)
srcLn = F.srcLn.v(node)
print(f"{pNum}:{column}:{lineNum} = {srcLn}")
P004735:obverse:2:1 = 1.b1B1. , (NAB DI |BU~a+DU6~a|)a P004735:obverse:2:1 = 1.b1B2. , (ZI~a#? AN)a P004735:obverse:2:1 = 1.b1B3. , (ANSZE~e 7(N57) DUR2 DU)a P004735:obverse:2:1 = 1.b1B4. , (LAL3~a#? GAR IG~b)a P004735:obverse:2:2 = 2.b2B1. , (GI6 KISZIK~a# URI3~a)a P004735:obverse:2:2 = 2.b2B2. , ([...])a P218054:reverse:1:1 = 1.a1A1. [...] 5(N01)# , [...] UDU~a#? P218054:reverse:1:1 = 1.a1A2. [...] 7(N01)# , MASZ2 P325754:reverse:1:1 = 1.c2b1. 1(N01) , [...] P325754:reverse:1:1 = 1.c2b2. 1(N14) 7(N01) , TUR P325754:reverse:1:1 = 1.c2b3. 2(N14) 6(N01) , SUR P325234:reverse:1:1 = 1.c5a1. 8(N01) , GAR U2~a P325234:reverse:1:1 = 1.c5a2. |SZU2.E2~b| P411608:obverse:1:1 = 1b2a1. 1(N01) , GAL~a P411608:obverse:1:1 = 1b2a2. 1(N01) , GA2~a1 TUR P411608:obverse:1:1 = 1b2b1. 1(N01) , |U4x3(N57)| P411608:obverse:1:1 = 1b2b2. 1(N01) , X P387752:obverse:0:1 = 1.b1.b01. , NIN NAB DI P387752:obverse:0:1 = 1.b1.b02. , SAL 1(N02) , PAP~a P387752:obverse:0:1 = 1.b1.b03. , BU~a U4 SI4~a
This gives us the first twenty occurrences, but except for a few office titles like NAMESZDA or HI E2~a NUN~a or EN~a AN MUSZ3~a, there does not seem to be much that is really distinctive here. What we actually want, if we are looking for the distinctive characteristics of a particular level in the subcases, is the twenty most frequent signs at each level.
The following snippet of code collects all of the signs at sublevel 4 (or the sub-sub-sub-subcase level) into a list.
sublevel4Signs = []
for c4 in sublevel4Nodes:
for sign in L.d(c4, otype="sign"):
sublevel4Signs.append(sign)
Now that we have a list stored in "sublevel4Signs" we can ask Text-Fabric to count up the tokens of each sign type in "signs4count".
signs4count = collections.Counter()
for s in sublevel4Signs:
signs4count[A.atfFromSign(s)] += 1
And finally we can ask Text-Fabric to reorder the sign types from most frequent to least, and only show the most frequent signs.
for (sign, amount) in sorted(
signs4count.items(),
key=lambda x: (-x[1], x[0]),
)[:40]:
print(f"{amount:>4} x {sign}")
47 x ... 16 x 1(N01) 15 x 1(N57) 11 x EN~a 11 x X 6 x AN 5 x 2(N01) 5 x BU~a 5 x SAL 5 x SZU 5 x U4 4 x 4(N01) 4 x E2~a 4 x NUN~a 4 x SZE3 3 x 2(N14) 3 x 3(N57) 3 x HI 3 x MASZ2 3 x PAP~a 3 x SUHUR 3 x SZA 3 x TUR 3 x U8 2 x 1(N03) 2 x 1(N05) 2 x 1(N40) 2 x 1(N42~a) 2 x 2(N42~a) 2 x 3(N01) 2 x 3(N20) 2 x 6(N01) 2 x 7(N01) 2 x ALAN~b 2 x AMA~a 2 x BA 2 x BAD 2 x DI 2 x DILMUN 2 x DUB~a
Text-Fabric treats "..." and " " as distinct signs, so let's add the following lines of code
grapheme = F.grapheme.v(s)
if grapheme == '' or grapheme == '…' or grapheme == 'X':
continue
to exclude those non-signs and also to exclude unidentified signs, namely X.
signs4count = collections.Counter()
for s in sublevel4Signs:
grapheme = F.grapheme.v(s)
if grapheme == "" or grapheme == "…" or grapheme == "X":
continue
signs4count[A.atfFromSign(s)] += 1
for (sign, amount) in sorted(
signs4count.items(),
key=lambda x: (-x[1], x[0]),
)[:40]:
print(f"{amount:>4} x {sign}")
16 x 1(N01) 15 x 1(N57) 11 x EN~a 6 x AN 5 x 2(N01) 5 x BU~a 5 x SAL 5 x SZU 5 x U4 4 x 4(N01) 4 x E2~a 4 x NUN~a 4 x SZE3 3 x 2(N14) 3 x 3(N57) 3 x HI 3 x MASZ2 3 x PAP~a 3 x SUHUR 3 x SZA 3 x TUR 3 x U8 2 x 1(N03) 2 x 1(N05) 2 x 1(N40) 2 x 1(N42~a) 2 x 2(N42~a) 2 x 3(N01) 2 x 3(N20) 2 x 6(N01) 2 x 7(N01) 2 x ALAN~b 2 x AMA~a 2 x BA 2 x BAD 2 x DI 2 x DILMUN 2 x DUB~a 2 x E2~b 2 x GAR
Now let's run these pieces of code on the three other hierarchical levels within the subcases and see if there are any commonalities between the different levels.
sublevel3Nodes = A.casesByLevel(3, terminal=True)
sublevel3Signs = []
for c3 in sublevel3Nodes:
for sign in L.d(c3, otype="sign"):
sublevel3Signs.append(sign)
signs3count = collections.Counter()
for s in sublevel3Signs:
grapheme = F.grapheme.v(s)
if grapheme == "" or grapheme == "…" or grapheme == "X":
continue
signs3count[A.atfFromSign(s)] += 1
for (sign, amount) in sorted(
signs3count.items(),
key=lambda x: (-x[1], x[0]),
)[:40]:
print(f"{amount:>4} x {sign}")
25 x 1(N01) 18 x 1(N14) 17 x 2(N01) 16 x 3(N57) 14 x EN~a 13 x U4 10 x TUR 9 x 1(N57) 9 x SZE~a 8 x 4(N01) 8 x A 8 x SZU 7 x 1(N02) 7 x 2(N14) 7 x PAP~a 6 x 2(N42~a) 6 x 3(N01) 6 x 5(N01) 6 x SAG 6 x SAL 5 x 8(N01) 5 x AN 5 x BA 5 x BU~a 5 x HI@g~a 5 x KUR~a 5 x NUN~a 5 x SILA3~a 5 x UDU~a 4 x 4(N14) 4 x 6(N01) 4 x E2~a 4 x GAR 4 x GARA2~a 4 x NI~a 4 x SU~a 3 x 1(N25) 3 x 2(N57) 3 x 4(N42~a) 3 x AB~a
sublevel2Nodes = A.casesByLevel(2, terminal=True)
sublevel2Signs = []
for c2 in sublevel2Nodes:
for sign in L.d(c2, otype="sign"):
sublevel2Signs.append(sign)
signs2count = collections.Counter()
for s in sublevel2Signs:
grapheme = F.grapheme.v(s)
if grapheme == "" or grapheme == "…" or grapheme == "X":
continue
signs2count[A.atfFromSign(s)] += 1
for (sign, amount) in sorted(
signs2count.items(),
key=lambda x: (-x[1], x[0]),
)[:40]:
print(f"{amount:>4} x {sign}")
348 x 1(N01) 192 x 2(N01) 142 x 1(N14) 135 x EN~a 109 x 1(N57) 105 x SZE~a 95 x BA 90 x GI 89 x 3(N01) 84 x 4(N01) 82 x 3(N57) 82 x BU~a 76 x 2(N14) 76 x PAP~a 73 x 5(N01) 70 x SAL 68 x U4 63 x AN 56 x SZU 55 x 3(N14) 55 x E2~a 45 x 1(N34) 43 x HI@g~a 41 x DU 41 x KU3~a 40 x HI 39 x KI 39 x TUR 37 x 1(N24) 37 x 6(N01) 37 x BAR 36 x 4(N14) 36 x MUSZEN 36 x UDU~a 35 x 1(N58) 35 x A 33 x NUN~a 33 x SI 30 x 5(N14) 30 x MASZ
sublevel1Nodes = A.casesByLevel(1, terminal=True)
sublevel1Signs = []
for c1 in sublevel1Nodes:
for sign in L.d(c1, otype="sign"):
sublevel1Signs.append(sign)
signs1count = collections.Counter()
for s in sublevel1Signs:
grapheme = F.grapheme.v(s)
if grapheme == "" or grapheme == "…" or grapheme == "X":
continue
signs1count[A.atfFromSign(s)] += 1
for (sign, amount) in sorted(
signs1count.items(),
key=lambda x: (-x[1], x[0]),
)[:40]:
print(f"{amount:>4} x {sign}")
989 x 1(N01) 499 x 2(N01) 396 x 1(N14) 317 x EN~a 293 x 3(N01) 254 x SZE~a 253 x 2(N14) 209 x SAL 198 x U4 189 x 1(N57) 184 x 4(N01) 184 x 5(N01) 173 x PAP~a 153 x 3(N14) 150 x GI 128 x 1(N34) 127 x AN 127 x E2~a 126 x NUN~a 111 x UDU~a 110 x BA 103 x 3(N57) 103 x BU~a 101 x SZU 99 x 4(N14) 99 x SANGA~a 97 x GAR 93 x DU 92 x BAR 91 x 6(N01) 91 x TUR 89 x 1(N24) 87 x A 87 x SI 84 x GAN2 80 x PA~a 77 x 5(N14) 76 x GAL~a 74 x KI 73 x HI
Now let's exclude the numerals from the frequency count as well. We can do this by adding the following lines to the code:
signType = F.type.v(s)
if signType == 'numeral':
continue
sublevel1Nodes = A.casesByLevel(1, terminal=True)
sublevel1Signs = []
for c1 in sublevel1Nodes:
for sign in L.d(c1, otype="sign"):
sublevel1Signs.append(sign)
signs1count = collections.Counter()
for s in sublevel1Signs:
grapheme = F.grapheme.v(s)
if grapheme == "" or grapheme == "…" or grapheme == "X":
continue
signType = F.type.v(s)
if signType == "numeral":
continue
signs1count[A.atfFromSign(s)] += 1
for (sign, amount) in sorted(
signs1count.items(),
key=lambda x: (-x[1], x[0]),
)[:40]:
print(f"{amount:>4} x {sign}")
317 x EN~a 254 x SZE~a 209 x SAL 198 x U4 173 x PAP~a 150 x GI 127 x AN 127 x E2~a 126 x NUN~a 111 x UDU~a 110 x BA 103 x BU~a 101 x SZU 99 x SANGA~a 97 x GAR 93 x DU 92 x BAR 91 x TUR 87 x A 87 x SI 84 x GAN2 80 x PA~a 76 x GAL~a 74 x KI 73 x HI 70 x DUG~a 70 x SAG 66 x SZITA~a1 63 x NAM2 62 x TUG2~a 61 x KUR~a 57 x DUG~c 53 x HI@g~a 53 x KASZ~a 53 x KU6~a 53 x ME~a 52 x AB~a 51 x IB~a 51 x TAR~a 49 x LAGAB~b
Constructing frequency tables for numerical and non-numerical signs at each level¶
Now let's run construct frequency tables for all hierarchical levels. For each level we collect the top 20 signs (frequency). We take the union of all those signs, and we show their frequencies for all levels.
We also do the same for level "-1": the whole corpus, as a standard of reference. That way any commonalities between the different levels will become apparent.
Auxiliary function getSigns(sourceNodes) collects sign nodes that belong to the source nodes. The source nodes can be tablets, lines, cases, it does not matter.
The sign nodes will be separated into a set of ideographs and a set of numerals. Other kinds of signs (unknown, ellipsis, empty) will be ignored.
def getSigns(sourceNodes):
ideoNodes = set()
numeralNodes = set()
for sn in sourceNodes:
signs = L.d(sn, otype="sign")
for s in signs:
signType = F.type.v(s)
if signType == "ideograph":
ideoNodes.add(s)
elif signType == "numeral":
numeralNodes.add(s)
return (ideoNodes, numeralNodes)
Auxiliary function getSignFrequency(signNodes) computes the frequency distribution of
the signs on the basis of their ATF representation (without flags).
def getSignFrequency(signNodes):
signFreqs = collections.Counter()
for s in signNodes:
atf = A.atfFromSign(s)
signFreqs[atf] += 1
signRanks = {}
for s in sorted(signFreqs, key=lambda x: -signFreqs[x]):
signRanks[s] = len(signRanks) + 1
return (signFreqs, signRanks)
We make our first level (-1), which consist of all signs in the corpus and their frequencies.
allLines = list(F.otype.s("line"))
(ideoAllNodes, numeralAllNodes) = getSigns(allLines)
(ideoAllFreqs, ideoAllRanks) = getSignFrequency(ideoAllNodes)
(numeralAllFreqs, numeralAllRanks) = getSignFrequency(numeralAllNodes)
levelIdeo = {
-1: ideoAllFreqs,
}
levelNumeral = {
-1: numeralAllFreqs,
}
rankIdeo = {
-1: ideoAllRanks,
}
rankNumeral = {
-1: numeralAllRanks,
}
Now we do the same for all real levels: the lines, cases, subcases and so on. We'll see how deep it gets.
for level in range(10):
levelNodesT = A.casesByLevel(level)
levelNodes = A.casesByLevel(level, terminal=False)
allCases = len(levelNodes)
terminalCases = len(levelNodesT)
dividedCases = allCases - terminalCases
print(f"level {level}:")
print(f" all cases/lines: {allCases:>5}")
print(f" terminal cases/lines: {terminalCases:>5}")
print(f" divided cases/lines: {dividedCases:>5}")
if allCases == 0:
break
(ideoNodes, numeralNodes) = getSigns(levelNodesT)
(levelIdeo[level], rankIdeo[level]) = getSignFrequency(ideoNodes)
(levelNumeral[level], rankNumeral[level]) = getSignFrequency(numeralNodes)
print(f" distinct ideographs : {len(levelIdeo[level]):>5}")
print(f" distinct numerals : {len(levelNumeral[level]):>5}")
level 0:
all cases/lines: 35842
terminal cases/lines: 32732
divided cases/lines: 3110
distinct ideographs : 1131
distinct numerals : 276
level 1:
all cases/lines: 6559
terminal cases/lines: 5468
divided cases/lines: 1091
distinct ideographs : 530
distinct numerals : 181
level 2:
all cases/lines: 2719
terminal cases/lines: 2595
divided cases/lines: 124
distinct ideographs : 406
distinct numerals : 140
level 3:
all cases/lines: 254
terminal cases/lines: 218
divided cases/lines: 36
distinct ideographs : 119
distinct numerals : 50
level 4:
all cases/lines: 119
terminal cases/lines: 119
divided cases/lines: 0
distinct ideographs : 84
distinct numerals : 32
level 5:
all cases/lines: 0
terminal cases/lines: 0
divided cases/lines: 0
Now we are going to construct frequency tables:
- for the top twenty ideographs at all levels
- for the top twenty numerals at all levels
Auxiliary function getTop(levelData, amount) collects the union of top amount signs
for each level of frequency data in levelData.
def getTop(levelData, amount):
topSigns = set()
for (level, frequency) in levelData.items():
topSigns |= set(sorted(frequency, key=lambda x: -frequency[x])[0:amount])
return sorted(topSigns, key=lambda x: -levelData[-1][x])
Auxiliary function makeTable(levelData, amount) composes the frequency table.
headingFromLevel = {
-1: "all",
0: "line",
1: "case",
}
def getHeading(level):
if level < 2:
return headingFromLevel[level]
else:
return f"lv{level}"
def makeTable(heading, levelData, rankData, amount):
maxLevel = max(levelData)
topSigns = getTop(levelData, amount)
subDelims = " | --- | --- " * (2 * (maxLevel + 1))
subHeadings = "".join(
f" | {getHeading(level)} | {getHeading(level)} r"
for level in range(maxLevel + 1)
)
markdown = f"""
# {heading}
sign | {getHeading(-1)} | {getHeading(-1)} r {subHeadings}
--- | --- | --- {subDelims}
"""
for sign in topSigns:
fAll = levelData[-1][sign]
fAllR = rankData[-1][sign]
markdownLine = f"**{sign}** | **{fAll}** | **{fAllR}**"
for level in range(maxLevel + 1):
f = levelData[level][sign] or " "
fr = rankData[level].get(sign, " ")
markdownLine += f" | {f} | *{fr}*"
markdown += f"{markdownLine}\n"
dm(markdown)
Here is the table for non-numerical signs. For each sign, you see how many times it occurs and which rank it has in terms of frequency. (Rank 1 is the most frequent sign, rank 2 the second most frequent sign, and so on). The sublevels are abbreviated as "lv2" through "lv4", but sublevel 1 is designed as "case" in the table.
makeTable("Non-numerals", levelIdeo, rankIdeo, 20)
Non-numerals¶
| sign | all | all r | line | line r | case | case r | lv2 | lv2 r | lv3 | lv3 r | lv4 | lv4 r | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| EN~a | 1830 | 1 | 1353 | 1 | 317 | 1 | 135 | 1 | 14 | 1 | 11 | 1 | ||||||||||
| SZE~a | 1294 | 2 | 924 | 3 | 254 | 2 | 105 | 2 | 9 | 4 | 2 | 17 | ||||||||||
| GAL~a | 1164 | 3 | 1060 | 2 | 76 | 23 | 24 | 31 | 3 | 26 | 1 | 75 | ||||||||||
| U4 | 1022 | 4 | 738 | 5 | 198 | 4 | 68 | 8 | 13 | 2 | 5 | 5 | ||||||||||
| AN | 1020 | 5 | 819 | 4 | 127 | 8 | 63 | 9 | 5 | 13 | 6 | 2 | ||||||||||
| SAL | 876 | 6 | 586 | 9 | 209 | 3 | 70 | 7 | 6 | 8 | 5 | 3 | ||||||||||
| PAP~a | 851 | 7 | 592 | 8 | 173 | 5 | 76 | 6 | 7 | 7 | 3 | 10 | ||||||||||
| GI | 849 | 8 | 604 | 6 | 150 | 6 | 90 | 4 | 3 | 23 | 2 | 30 | ||||||||||
| BA | 781 | 9 | 569 | 10 | 110 | 11 | 95 | 3 | 5 | 15 | 2 | 34 | ||||||||||
| NUN~a | 719 | 10 | 551 | 12 | 126 | 9 | 33 | 22 | 5 | 14 | 4 | 7 | ||||||||||
| SANGA~a | 714 | 11 | 599 | 7 | 99 | 14 | 15 | 60 | 1 | 66 | * * | |||||||||||
| SZU | 680 | 12 | 510 | 13 | 101 | 13 | 56 | 10 | 8 | 6 | 5 | 6 | ||||||||||
| BU~a | 653 | 13 | 458 | 17 | 103 | 12 | 82 | 5 | 5 | 11 | 5 | 4 | ||||||||||
| NAM2 | 649 | 14 | 562 | 11 | 63 | 29 | 22 | 37 | 2 | 43 | * * | |||||||||||
| E2~a | 646 | 15 | 456 | 18 | 127 | 7 | 55 | 11 | 4 | 22 | 4 | 9 | ||||||||||
| UDU~a | 616 | 16 | 463 | 16 | 111 | 10 | 36 | 19 | 5 | 10 | 1 | 84 | ||||||||||
| A | 600 | 17 | 470 | 15 | 87 | 19 | 35 | 21 | 8 | 5 | * * | |||||||||||
| KI | 546 | 18 | 429 | 19 | 74 | 24 | 39 | 16 | 3 | 33 | 1 | 41 | ||||||||||
| DUG~b | 509 | 19 | 493 | 14 | 13 | 134 | 3 | 222 | * * | * * | ||||||||||||
| DU | 480 | 20 | 342 | 25 | 93 | 16 | 41 | 14 | 3 | 32 | 1 | 67 | ||||||||||
| GISZ | 478 | 21 | 426 | 20 | 35 | 55 | 16 | 54 | 1 | 67 | * * | |||||||||||
| SAG | 453 | 23 | 346 | 23 | 70 | 27 | 30 | 25 | 6 | 9 | 1 | 79 | ||||||||||
| BAR | 424 | 26 | 293 | 31 | 92 | 17 | 37 | 18 | 2 | 39 | * * | |||||||||||
| SI | 419 | 28 | 299 | 30 | 87 | 20 | 33 | 23 | * * | * * | ||||||||||||
| HI | 408 | 29 | 290 | 33 | 73 | 25 | 40 | 15 | 2 | 41 | 3 | 12 | ||||||||||
| GAR | 401 | 30 | 279 | 36 | 97 | 15 | 19 | 45 | 4 | 20 | 2 | 29 | ||||||||||
| TUR | 382 | 32 | 239 | 43 | 91 | 18 | 39 | 17 | 10 | 3 | 3 | 15 | ||||||||||
| NI~a | 372 | 33 | 308 | 28 | 40 | 49 | 20 | 43 | 4 | 18 | * * | |||||||||||
| MUSZEN | 319 | 41 | 242 | 42 | 41 | 48 | 36 | 20 | * * | * * | ||||||||||||
| SUHUR | 315 | 42 | 279 | 37 | 23 | 86 | 9 | 101 | 1 | 117 | 3 | 16 | ||||||||||
| KUR~a | 312 | 44 | 219 | 46 | 61 | 31 | 25 | 30 | 5 | 12 | 2 | 28 | ||||||||||
| SU~a | 290 | 48 | 219 | 47 | 49 | 40 | 18 | 46 | 4 | 19 | * * | |||||||||||
| KU3~a | 264 | 52 | 191 | 56 | 29 | 66 | 41 | 13 | 2 | 53 | 1 | 58 | ||||||||||
| HI@g~a | 235 | 58 | 133 | 84 | 53 | 35 | 43 | 12 | 5 | 17 | 1 | 46 | ||||||||||
| SILA3~a | 233 | 59 | 186 | 60 | 24 | 81 | 18 | 48 | 5 | 16 | * * | |||||||||||
| SZE3 | 201 | 68 | 156 | 68 | 23 | 84 | 15 | 62 | 3 | 25 | 4 | 8 | ||||||||||
| U8 | 188 | 71 | 151 | 71 | 17 | 111 | 17 | 50 | * * | 3 | 13 | |||||||||||
| SZA | 169 | 82 | 114 | 94 | 33 | 57 | 18 | 47 | 1 | 98 | 3 | 14 | ||||||||||
| MASZ2 | 163 | 85 | 140 | 80 | 5 | 224 | 14 | 65 | 1 | 111 | 3 | 11 | ||||||||||
| DI | 155 | 92 | 135 | 83 | 11 | 151 | 5 | 150 | 2 | 45 | 2 | 20 | ||||||||||
| NIN | 106 | 119 | 78 | 129 | 17 | 109 | 9 | 96 | * * | 2 | 18 | |||||||||||
| NAB | 20 | 329 | 11 | 403 | 4 | 260 | 1 | 392 | 2 | 44 | 2 | 19 |
Several important things about the table should be emphasized here: because we are only counting occurrences of a sign in terminal cases, no sign is counted twice and, consequently, we can add up the occurrences of any sign at each level and arrive at the number of signs in the corpus. The most frequent non-numerical sign in the corpus is EN~a, which probably refers to an office holder or elite male: it occurs 1353 times in undivided lines, 317 times at sublevel 1, 135 times at sublevel 2, 14 times at sublevel 3, and 11 times at sublevel 4. If we add these up, we arrive at 1830 occurrences in the corpus as a whole.
For the most part, signs in (sub)cases occur at roughly the same frequency as in ordinary lines, but there are interesting exceptions. GAL~a, which usually refers to the head of a bureau, is actually the second most frequent sign in ordinary lines, with 1060 occurrences, but drops to 23rd position, with 76 occurrences, at sublevel 1, and only occurs a couple dozen times at lower levels.
Now let's look at a similar table for the numerals alone.
makeTable("Numerals", levelNumeral, rankNumeral, 20)
Numerals¶
| sign | all | all r | line | line r | case | case r | lv2 | lv2 r | lv3 | lv3 r | lv4 | lv4 r | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1(N01) | 12983 | 1 | 11605 | 1 | 989 | 1 | 348 | 1 | 25 | 1 | 16 | 1 | ||||||||||
| 2(N01) | 3080 | 2 | 2367 | 2 | 499 | 2 | 192 | 2 | 17 | 3 | 5 | 3 | ||||||||||
| 1(N14) | 2584 | 3 | 2027 | 3 | 396 | 3 | 142 | 3 | 18 | 2 | 1 | 30 | ||||||||||
| 3(N01) | 1598 | 4 | 1208 | 4 | 293 | 4 | 89 | 5 | 6 | 9 | 2 | 14 | ||||||||||
| 2(N14) | 1357 | 5 | 1018 | 6 | 253 | 5 | 76 | 8 | 7 | 7 | 3 | 6 | ||||||||||
| 5(N01) | 1294 | 6 | 1030 | 5 | 184 | 8 | 73 | 9 | 6 | 10 | 1 | 32 | ||||||||||
| 4(N01) | 1117 | 7 | 837 | 7 | 184 | 7 | 84 | 6 | 8 | 6 | 4 | 4 | ||||||||||
| 1(N34) | 999 | 8 | 824 | 8 | 128 | 10 | 45 | 11 | 2 | 22 | * * | |||||||||||
| 3(N14) | 791 | 9 | 583 | 10 | 153 | 9 | 55 | 10 | * * | * * | ||||||||||||
| 1(N57) | 789 | 10 | 467 | 11 | 189 | 6 | 109 | 4 | 9 | 5 | 15 | 2 | ||||||||||
| N | 716 | 11 | 697 | 9 | 17 | 54 | 2 | 95 | * * | * * | ||||||||||||
| 3(N57) | 592 | 12 | 388 | 13 | 103 | 11 | 82 | 7 | 16 | 4 | 3 | 5 | ||||||||||
| 6(N01) | 583 | 13 | 449 | 12 | 91 | 13 | 37 | 13 | 4 | 13 | 2 | 7 | ||||||||||
| 4(N14) | 511 | 14 | 372 | 14 | 99 | 12 | 36 | 14 | 4 | 14 | * * | |||||||||||
| 7(N01) | 369 | 15 | 292 | 15 | 51 | 22 | 23 | 24 | 1 | 34 | 2 | 15 | ||||||||||
| 5(N14) | 368 | 16 | 260 | 18 | 77 | 15 | 30 | 16 | 1 | 29 | * * | |||||||||||
| 8(N01) | 359 | 17 | 267 | 16 | 59 | 16 | 27 | 17 | 5 | 12 | 1 | 18 | ||||||||||
| 1(N24) | 348 | 18 | 221 | 21 | 89 | 14 | 37 | 12 | 1 | 36 | * * | |||||||||||
| 2(N34) | 326 | 19 | 260 | 17 | 53 | 21 | 10 | 46 | 2 | 18 | 1 | 31 | ||||||||||
| 1(N45) | 310 | 20 | 251 | 19 | 36 | 29 | 22 | 25 | 1 | 32 | * * | |||||||||||
| 1(N08) | 286 | 21 | 226 | 20 | 47 | 24 | 13 | 36 | * * | * * | ||||||||||||
| 2(N57) | 218 | 23 | 140 | 23 | 48 | 23 | 26 | 20 | 3 | 15 | 1 | 16 | ||||||||||
| 1(N58) | 216 | 24 | 136 | 25 | 45 | 25 | 35 | 15 | * * | * * | ||||||||||||
| 1(N39~a) | 207 | 25 | 136 | 24 | 44 | 26 | 27 | 18 | * * | * * | ||||||||||||
| 2(N39~a) | 189 | 26 | 107 | 28 | 54 | 19 | 26 | 21 | 2 | 21 | * * | |||||||||||
| 1(N02) | 165 | 28 | 90 | 31 | 41 | 28 | 26 | 19 | 7 | 8 | 1 | 26 | ||||||||||
| 1(N25) | 150 | 29 | 67 | 37 | 55 | 18 | 24 | 23 | 3 | 16 | 1 | 19 | ||||||||||
| 1(N42~a) | 130 | 32 | 52 | 40 | 56 | 17 | 18 | 28 | 2 | 25 | 2 | 8 | ||||||||||
| 1(N05) | 104 | 36 | 46 | 47 | 43 | 27 | 13 | 35 | * * | 2 | 11 | |||||||||||
| 2(N42~a) | 89 | 43 | 42 | 51 | 26 | 35 | 13 | 37 | 6 | 11 | 2 | 13 | ||||||||||
| 1(N22) | 89 | 44 | 27 | 69 | 54 | 20 | 7 | 61 | 1 | 39 | * * | |||||||||||
| 1(N03) | 68 | 50 | 45 | 49 | 3 | 112 | 18 | 29 | * * | 2 | 12 | |||||||||||
| 1(N20) | 62 | 53 | 31 | 60 | 22 | 41 | 8 | 52 | * * | 1 | 17 | |||||||||||
| 1(N29~a) | 54 | 59 | 27 | 68 | 12 | 66 | 13 | 33 | 2 | 20 | * * | |||||||||||
| 1(N40) | 40 | 75 | 21 | 83 | 9 | 72 | 8 | 53 | * * | 2 | 9 | |||||||||||
| 4(N42~a) | 25 | 97 | 9 | 133 | 9 | 71 | 4 | 83 | 3 | 17 | * * | |||||||||||
| 3(N20) | 24 | 99 | 17 | 93 | 3 | 121 | * * | 2 | 23 | 2 | 10 | |||||||||||
| 7(N19) | 22 | 105 | 12 | 118 | 4 | 108 | 4 | 76 | 2 | 19 | * * | |||||||||||
| 1(N18) | 19 | 108 | 12 | 112 | 3 | 117 | 3 | 91 | * * | 1 | 20 |
Here each transliteration of a numeral is treated as a distinct entity, so one occurrence of N01 is counted separately from two occurrences of the same numerical sign, but in future primers we will discuss how the different numerical systems in proto-cuneiform can be isolated and how to count occurrences of number systems.
Already here, however, N57, which is often used as a diacritic in the formation of new signs, also appears with a much higher frequency ranking in (sub)cases than in undivided lines. 1(N57), for example, which is ranked 10th in both the corpus as a whole and in undivided lines, is in 6th position at sublevel 1, 4th position at sublevel 2, 5th position at sublevel 3 and 2nd position at sublevel 4. Here frequency ranking tells us a great deal more than simple counts, since there are 467 occurrences of 1(N57) in undivided lines, and only 322 occurrences in (sub)cases, so the sign occurs more frequently in undivided lines, but its ranking in the frequency tables actually increases as we move into lower levels within the (sub)case system.