


Steps¶
The transliterations in the Uruk corpus are a kind of landscape. In this notebook we take our first steps around.
Landscape¶
The transcriptions of the tablets in their TF form is organized in a model of nodes, edges and features.
The things such as tablets, faces, columns, lines, cases, and, at the most basic level, signs, are numbered. The signs correspond to number 1 ... 100,000+, in the same order as they occur in the corpus. All other things are built from signs. They have higher numbers.
In TF, we call these numbers nodes. Like a barcode, this number gives access to a whole bunch of information about the corresponding object.
For example, cases have a property (in TF we call it a feature) called number.
It contains the hierarchical number of a case within a line, based on the
numbers at the start of the transcription lines.
If the node (barcode) for a case is n, we can find its hierarchical number by saying
F.number.v(n)
In words, it reads as:
F: I want to look up aFeaturenumber: the name of the feature.v: I want the value of that feature(n): for the given noden
Seen in this way, the data is like a gigantic spreadsheet of hundreds of thousands of rows (the nodes), and a few dozen columns (the features).
There is a bit more to it, since the nodes can be grouped together in ways we will see later on.
The complete reference information is in the Feature docs.
Incantation¶
We start the notebook by the familiar incantation.
%load_ext autoreload
%autoreload 2
from tf.app import use
A = use("Nino-cunei/uruk", hoist=globals())
This is Text-Fabric 9.2.2 Api reference : https://annotation.github.io/text-fabric/tf/cheatsheet.html 33 features found and 0 ignored
Data: URUK, Character table, Feature docs
Features:
Uruk IV/III: Proto-cuneiform tablets
indicates modifcation of a sign; corresponds to sign@letter in transcription. if the grapheme is a repeat, the modification applies to the whole repeat.
indicates the order between modifiers and variants on the same object; if 1, modifiers come before variants
indicates modifcation of a sign within a repeatcorresponds to sign@letter in transcription
number indicating the number of repeats of a grapheme,especially in numerals; -1 comes from repeat N in transcription
pNum = "P005381"
tablet = T.nodeFromSection((pNum,))
tablet
148166
Explanation
We have imposed a division in sections on the Uruk corpus. Three levels:
- tablets;
- columns;
- line.
With T we get access to section functions.
If we identify a section, by specifying its tablet, column number, and line number,
T will give us back the node (barcode) of that section.
If we specify just a P-number, we get the node of the corresponding tablet.
If we specify a P-number and a column number, we get the node of the corresponding column.
If we, additionally, specify a line number, we get the node of the line.
Warning
The expression (pNum, ) is the Python way of denoting a tuple with one element.
Without the awkward comma the brackets are just grouping brackets, not tuple brackets.
So if you say
tablet = T.nodeFromSection((pNum))
things go horribly wrong.
Here is its transcription, because a node is just a number, not very informative to us humans.
A.getSource(tablet)
['&P005381 = MSVO 3, 70', '#atf: lang qpc ', '@obverse ', '@column 1 ', '1.a. 2(N14) , SZE~a SAL TUR3~a NUN~a ', '1.b. 3(N19) , |GISZ.TE| ', '2. 1(N14) , NAR NUN~a SIG7 ', '3. 2(N04)# , PIRIG~b1 SIG7 URI3~a NUN~a ', '@column 2 ', '1. 3(N04) , |GISZ.TE| GAR |SZU2.((HI+1(N57))+(HI+1(N57)))| GI4~a ', '2. , GU7 AZ SI4~f ', '@reverse ', '@column 1 ', '1. 3(N14) , SZE~a ', '2. 3(N19) 5(N04) , ', '3. , GU7 ', '@column 2 ', '1. , AZ SI4~f ']
And, to be even more hands on, we show the lineart:
A.lineart(tablet, width=200)
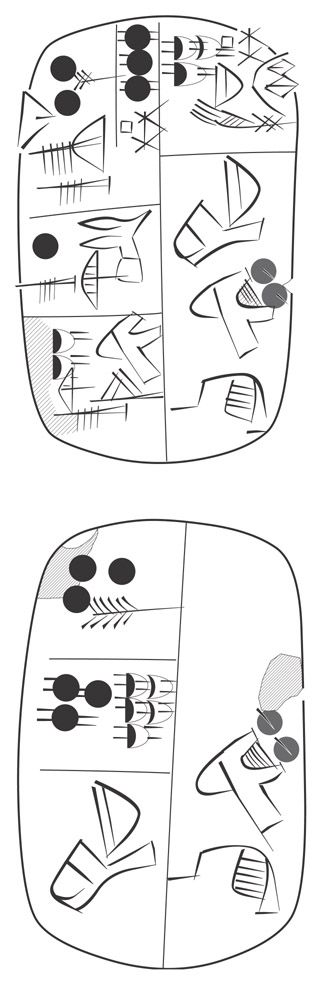
Now let's check out the columns and lines. (Note that you have to include the face-name into the column number).
column = T.nodeFromSection((pNum, "obverse:1"))
A.pretty(column)
.jpg)




.jpg)

.jpg)


.jpg)


A.getSource(column)
['@column 1 ', '1.a. 2(N14) , SZE~a SAL TUR3~a NUN~a ', '1.b. 3(N19) , |GISZ.TE| ', '2. 1(N14) , NAR NUN~a SIG7 ', '3. 2(N04)# , PIRIG~b1 SIG7 URI3~a NUN~a ']
Now lines:
line = T.nodeFromSection((pNum, "obverse:1", "1"))
A.pretty(line, lineNumbers=True)
A.getSource(line, lineNumbers=True)
['85116: 1.a. 2(N14) , SZE~a SAL TUR3~a NUN~a ', '85117: 1.b. 3(N19) , |GISZ.TE| ']
Here we have requested the line numbers in the source files. These source files are also in the data repo, e.g. uruk-iii.
We want to go one step further. We want to get the node corresponding to individual lines in the transliterations. These correspond to cases which are themselves not divided into cases (terminal cases).
Text-Fabric itself only knows three section levels, we cannot use T.sectionFromNode()
for this.
Text-Fabric is a generic package, which has been used for various other
corpora, such as the Hebrew Bible. It does not know anything of (proto)cuneiform data,
nor of the Hebrew Bible, for that matter.
But on top of Text-Fabric we are using a bunch of dedicated cuneiform functions, and
one of them mimicks T.nodeFromSection:
case = A.nodeFromCase((pNum, "obverse:1", "1.b"))
A.pretty(case)
A.getSource(case, lineNumbers=True)
['85117 1.b. 3(N19) , |GISZ.TE| ']
Sets¶
Many times we want to start with whole sets. For example all composite signs, also known as quads:
quads = F.otype.s("quad")
len(quads)
3794
This reads as:
Fgive me the featuresotypeI want the feature that gives the type of nodess('quad')I want the nodes whoseotypevalue is'quad'i.e. the nodes that supportotype-value'quad'
As we see, there are nearly 4000 of them.
Later, we'll see where they are.
primes = F.prime.s(2)
len(primes)
1
In the same manner, we want to see all things with a double prime. There is only one. We pick up a bit of additional information, but later we'll see where it is.
for n in primes:
A.pretty(n, withNodes=True)
It is the sign with node (barcode) 56360.
Alas, there is no lineart for this sign.
Click the link under sign to go to the CDLI page for the tablet on which this sign occurs.
Walk all nodes¶
If we want to go over all nodes, in a sensible order, we do it like this:
count = 0
for n in N.walk():
count += 1
count
263067
Here we show the first 20 nodes with their type:
limit = 20
for (i, n) in enumerate(N.walk()):
if i >= limit:
break
print(f"{n:>6} {F.otype.v(n)}")
143889 tablet
169360 comment
1 sign
150253 face
180450 column
227226 line
194473 cluster
2 sign
3 sign
4 sign
180451 column
227227 line
5 sign
6 sign
7 sign
194474 cluster
8 sign
143890 tablet
169361 comment
9 sign
As you see, the order is not the sequence order of the nodes. You see first things (in the corpus) first, and if several things start at the same position, the bigger things come first.
Navigation¶
After our starting points, we would like to visit the neighbourhood. We want to go from nodes to the ones in which they lie embedded, and back. We want to go to the next node on the same level and back.
We do that with L. functions.
L.d()goes "down": from enbedder to embeddee;L.u()goes "up": from embeddee to embedder;L.p()goes "previous": to the first left sibling;L.n()goes "next": to the first right sibling.
Above, we collected some "interesting" nodes, but we had not yet a way to find out where they were.
Now we have.
Remember the double prime?
caseDouble = L.u(primes[0], otype="case")[0]
A.pretty(caseDouble, lineNumbers=True)
.jpg)

So we can go to the source, to the exact line number!
We can also show the whole tablet.
It is a bit of a puzzle to spot the 1(N24'').
In the notebook on search we'll show how you can highlight things on a tablet.
tabletDouble = L.u(primes[0], otype="tablet")[0]
A.pretty(tabletDouble, standardFeatures=True)
.jpg)



.jpg)







.jpg)

.jpg)
.jpg)

.jpg)

.jpg)




.jpg)
.jpg)


.jpg)
.jpg)
.jpg)
The L.u() function takes a node as starting point and looks up all nodes that embed it.
You can restrict those to nodes of a certain type, as we did by otype='case'.
It yields a tuple of nodes, so if you want a single embedder, you have to select one,
as we did by [0].
Earlier we collected all quads (composite signs). Let us look up info for them.
The least technical way is ... a one-liner!
for q in quads[0:10]:
A.pretty(q)
|.jpg)
|.jpg)
|.jpg)

|.jpg)

We can also assemble custom information.
For each such quad we assemble the following pieces of information:
- the P-number of the tablet
- the transcription line number
- a representation of the quad
- the list of signs of which the quad is composed.
for q in quads[0:10]:
cl = A.lineFromNode(q)
(pNum, colNum, caseNum) = A.caseFromNode(cl)
lineNum = F.srcLnNum.v(cl)
qRep = A.atfFromQuad(q)
signs = L.d(q, otype="sign")
signReps = " , ".join([A.atfFromSign(s) for s in signs])
print(f"{lineNum:>5} {pNum} {caseNum:<5} {qRep:<15} with {signReps}")
27 P006428 5 |DUG~bx1(N57)| with DUG~b , 1(N57) 66 P448702 1 |U4x1(N01)| with U4 , 1(N01) 80 P448703 1 |U4.1(N08)| with U4 , 1(N08) 81 P448703 2 |U4.1(N08)| with U4 , 1(N08) 82 P448703 3 |U4.1(N08)| with U4 , 1(N08) 82 P448703 3 |GI&GI| with GI , GI 83 P448703 4 |U4.1(N08)| with U4 , 1(N08) 84 P448703 5 |U4.1(N08)| with U4 , 1(N08) 142 P482083 2a |U4x3(N01)| with U4 , 3(N01) 161 P499393 2 |LAGAB~bxX| with LAGAB~b , X
Admittedly, this was a bit advanced. We used things we haven't explained yet.
A.lineFromNode(): if your node is something that fits in a single transcription line ( (a sign or quad or cluster), it will give you the node that corresponds to that transcription line (a terminal case or terminal line);A.caseFromNode(): gives you section headings with case numbers instead of line numbers for nodes if you give it a node. (exactly opposite toA.nodeFromCase());- likewise,
T.sectionFromNode()is opposite toT.nodeFromSection(). - we have functions to generate ATF transliterations for nodes, especially for
quads and signs:
A.atfFromQuad(n)gives you the transliteration of the quad identified by node (barcode)n;A.atfFromSign(n)likewise for signs.
With our mastery of starting points and navigation, we really do not have to see the actual node numbers (barcodes) anymore.
We'll see less and less of them, but they are the invisible glue that holds the whole corpus together.