
Parallelizing Xarray with Dask¶
In this tutorial, you learn:¶
- Using Dask with Xarray
- Read/write netCDF files with Dask
- Dask backed Xarray objects and operations
- Extract Dask arrays from Xarray objects and use Dask array directly.
- Xarray built-in operations can transparently use dask
Prerequisites¶
| Concepts | Importance | Notes |
|---|---|---|
| Intro to Xarray | Necessary | |
| Dask Arrays | Necessary | |
| Dask DataFrames | Necessary |
- Time to learn: 40 minutes
Introduction¶
Xarray Quick Overview¶
Xarray is an open-source Python library designed for working with labelled multi-dimensional data. By multi-dimensional data (also often called N-dimensional), we mean data that has many independent dimensions or axes (e.g. latitude, longitude, time). By labelled we mean that these axes or dimensions are associated with coordinate names (like "latitude") and coordinate labels like "30 degrees North".
Xarray provides pandas-level convenience for working with this type of data.
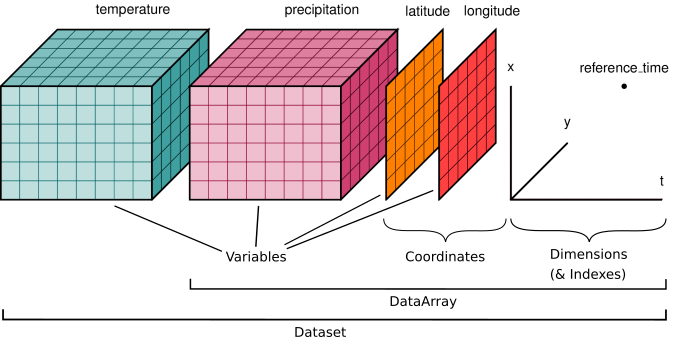
Image credit: Xarray Contributors
The dataset illustrated has two variables (temperature and precipitation) that have three dimensions. Coordinate vectors (e.g., latitude, longitude, time) that describe the data are also included.
Xarray Data Structures¶
Xarray has two fundamental data structures:
DataArray: holds a single multi-dimensional variable and its coordinatesDataset: holds multiple DataArrays that potentially share the same coordinates
Xarray DataArray
A DataArray has four essential attributes:
data: anumpy.ndarrayholding the values.dims: dimension names for each axis (e.g., latitude, longitude, time).coords: a dict-like container of arrays (coordinates) that label each point (e.g., 1-dimensional arrays of numbers, datetime objects or strings).attrs: a dictionary to hold arbitrary metadata (attributes).
Xarray DataSet
A dataset is simply an object containing multiple Xarray DataArrays indexed by variable name.
Xarray can wrap many array types like Numpy and Dask.¶
Let's start with a random 2D NumPy array, for example this can be SST (sea-surface temperature) values of a domain with dimension of 300x450 grid:
import numpy as np
import dask.array as da
import xarray as xr
xr.set_options(display_expand_data=False);
# -- numpy array
sst_np = np.random.rand(300,450)
type(sst_np)
As we saw in the previous tutorial, we can convert them to a Dask Array:
sst_da = da.from_array( sst_np)
sst_da
This is great and fast! BUT
- What if we want to attach coordinate values to this array?
- What if we want to add metadata (e.g. units) to this array?
# similarly we can convert them to xarray datarray
sst_xr = xr.DataArray(sst_da)
sst_xr
A simple DataArray without dimensions or coordinates isn't much use.
# we can add dimension names to this:
sst_xr = xr.DataArray(sst_da,dims=['lat','lon'])
sst_xr.dims
We can add our coordinates with values to it :
# -- create some dummy values for lat and lon dimensions
lat = np.random.uniform(low=-90, high=90, size=300)
lon = np.random.uniform(low=-180, high=180, size=450)
sst_xr = xr.DataArray(sst_da,
dims=['lat','lon'],
coords={'lat': lat, 'lon':lon},
attrs=dict(
description="Sea Surface Temperature.",
units="degC")
)
sst_xr
Xarray data structures are a very powerful tool that allows us to use metadata to express different analysis patterns (slicing, selecting, groupby, averaging, and many other things).
Take Away
Xarray DataArray provides a wrapper around arrays, and uses labeled dimensions and coordinates to support metadata-aware operations (e.g. da.sum(dim="time") instead of array.sum(axis=-1))
Xarray can wrap dask arrays instead of numpy arrays.
This capability turns Xarray into an extremely useful tool for Big Data earth science.
With this introduction, let's start our tutorial on features of Xarray and Dask:
Setup: Spinning up a cluster¶
from dask.distributed import LocalCluster, Client
cluster = LocalCluster()
client = Client(cluster)
client
Reading data with Dask and Xarray¶
Reading multiple netCDF files with open_mfdataset¶
Xarray provides a function called open_dataset function that allows us to load a netCDF dataset into a Python data structure. To read more about this function, please see xarray open_dataset API documentation.
Xarray also provides open_mfdataset, which open multiple files as a single xarray dataset. Passing the argument parallel=True will speed up reading multiple datasets by executing these tasks in parallel using Dask Delayed under the hood.
In this example, we are going to examine a subset of CESM2 Large Ensemble Data Sets (LENS). We will use 2m temperature (TREFHT) for this analysis.
To learn more about LENS dataset, please visit:
For this tutorial, we only look at a small subset of data. If you don't have the data, running the following code enables you to download, prepare, and stage the required datasets (../data/ folder) for this cookbook.
!./get_data.sh notebook3
We can open up multiple files using open_mfdataset function.
Constructing Xarray Datasets from files¶
import os
import glob
var = 'TREFHT'
# find all LENS files for 1 ensemble
data_dir = '../data/data_for_cesm'
files = glob.glob(os.path.join(data_dir, 'b.e21.BSSP370smbb.f09_g17.LE2-1301.013*.nc'))
print("All files: [", len(files), "files]")
%%time
ds = xr.open_mfdataset(
sorted(files),
# concatenate along this dimension
concat_dim="time",
# concatenate files in the order provided
combine="nested",
# parallelize the reading of individual files using dask
# This means the returned arrays will be dask arrays
parallel=True,
# these are netCDF4 files, use the h5netcdf package to read them
engine="h5netcdf",
# hold off on decoding time
decode_cf=False,
# specify that data should be automatically chunked
chunks="auto",
)
ds = xr.decode_cf(ds)
ds
For complex scenarios, you can access each file individually by utilizing the open_dataset function with the specified chunks and then combine the outputs into a single dataset later.
Note that the "real" values are not displayed, since that would trigger actual computation.
Xarray automatically wraps Dask Arrays and Dask is lazy, meaning that operations are not computed until we explicitly request them, for example by calling .compute().
Please see previous notebooks for more information on "lazy evaluation".
The represntation of TREFHT DataArray shows details of chunks and chunk-sizes of Xarray DataArray:
tref = ds.TREFHT
tref
tref.chunks
- How many chunks do we have?
- What is the size of each chunk size?
Here we can see that we have a total of 9 chunks - equal to the number of our netCDF files. In general open_mfdataset will return one chunk per netCDF file.
WARNING: The chunk structure within the file is important. When re-chunking the dataset after creation with ds.chunk() it is recommended to only use multiples of the on-file chunk shape.
We can check what that shape is by looking at the encoding:
tref.encoding
TIP: The chunks parameter can significantly affect total performance when using Dask Arrays. chunks should be small enough that each chunk fit in the memory, but large enough to avoid that the communication overhead.
A good rule of thumb is to create arrays with a minimum chunksize of at least one million elements. Here we have 120x192x288 elements in each chunk (except for the last chunk).
With large arrays (10+ GB), the cost of queuing up Dask operations can be noticeable, and you may need even larger chunksizes.
Additional Reading
Xarray data structures are Dask collections.¶
This means you can call the following Dask-related functions on Xarray Data Arrays and Datasets:
.visualize().compute().persist()
For more information about Dask Arrays, please see Dask Array chapter.
tref_mean = tref.mean('time')
tref_mean.data.dask
If we check Dask Task Graph for tref_mean, we can see all the steps required for calculating it (from opening the netcdf file to calculating mean and aggreagting it).
Getting concrete values¶
At some point, you will want to actually do the calculations and receive concrete values from Dask.
There are two ways to compute values on dask arrays.
compute()returns a new xarray object with the data now represented as a numpy array.load()replaces the dask array in the xarray object with a numpy array. Equivalent tods = ds.compute().
.load() operates inplace and .compute() returns a new xarray object.
Distributed non-blocking concrete values¶
There is another option available third option : “persisting”. .persist() loads the values into distributed RAM. The values are computed but remain distributed across workers. So essentially persist turns a lazy Dask collection into a Dask collection where the results are either fully computed or actively computing in the background.
So ds.air.persist() is still backed by a Dask array. This is useful if you will be repeatedly using a dataset for computation but it is too large to load into local memory.
Read more: Dask user guide
How to access underlying data in an Xarray object?¶
There are two basic ways to extract values from an Xarray object:
- Using
.datawill return a Dask array. For example:
tref.data
This means that for Dask-backed Xarray object, we can access the values using .compute
%%time
tref.data.compute()
- We can also use
.valuesto see the "real" values of Xarray object. Another option is using.to_numpy. Both of these option return the values of underlying Dask object in a numpy array.
%%time
tref.to_numpy()
Computation¶
All built-in Xarray methods (.mean, .max, .rolling, .groupby etc.) support dask arrays.
Now, let's do some computations on this Xarray dataset.
Single Point Calculations¶
To start out, let's do the calculations on a single point first. First, we extract the time series data at a grid point and save it to a variable. Here we select the closest point using .sel and load the data.
tref_boulder = tref.sel(lat=40.0150, lon=-105.2705, method='nearest').load()
WARNING: Remember as soon as you call .load() you are telling Dask to trigger computation.
# -- take annual average
tb = tref_boulder.resample(time='AS').mean()
tb
We can either see the values of our DataArray in the text representation above or by plotting it:
tb.plot()
Calculations over all grids¶
# change the unit from Kelvin to degree Celsius
tref_c = tref - 273.15
tref_c
%%time
tref_c = tref_c.load()
%%time
# Compute monthly anomaly
# -- 1. calculate monthly average
tref_grouped = tref.groupby('time.month')
tmean = tref_grouped.mean(dim='time')
#-- 2. calculate monthly anomaly
tos_anom = tref_grouped - tmean
tos_anom
%%time
computed_anom = tos_anom.load()
type(computed_anom)
tos_anom.sel(lon=310, lat=50, method='nearest').plot( size=4)
tos_anom.sel(time='2030-01-01').plot()
TIP: Using Xarray plotting functionality automatically triggers computations on the Dask Array, similar to .compute().
We can do more complex calculations too:
rolling_mean = tref.rolling(time=5).mean()
rolling_mean # contains dask array
timeseries = rolling_mean.isel(lon=1, lat=20) # no activity on dashboard
timeseries # contains dask array
computed = rolling_mean.compute() # activity on dashboard
computed # has real numpy values
Supplementary Material: Advanced workflows and automatic parallelization using apply_ufunc¶
Most of xarray’s built-in operations work on Dask arrays. If you want to use a function that isn’t wrapped by Xarray to work with Dask, one option is to extract Dask arrays from xarray objects (.data) and use Dask directly.
Another option is to use xarray’s apply_ufunc() function. xr.apply_ufunc() can automate embarrassingly parallel “map” type operations where a function written for processing NumPy arrays, but we want to apply it on our Xarray DataArray.
xr.apply_ufunc() give users capability to run custom-written functions such as parameter calculations in a parallel way. See the Xarray tutorial material on apply_ufunc for more.
In the example below, we calculate the saturation vapor pressure by using apply_ufunc() to apply this function to our Dask Array chunk by chunk.
import numpy as np
def sat_p(t):
"""Calculate saturation vapor pressure using Clausius-Clapeyron equation"""
return 0.611 * np.exp(17.67 * (t-273.15)*((t-29.65)**(-1)))
es = xr.apply_ufunc(sat_p, tref, dask="parallelized", output_dtypes=[float])
es
es.compute()
The data used for this tutorial is from one ensemble member. What if we want to use multiple ensemble members? So far, we only run on one machine, what if we run an HPC cluster? We will go over this in the next tutorial.
Dask + Xarray Good Practices¶
Summary of Dask + Xarray Good Practices
The good practices regarding Dask + Xarray is the same as the good practices for Dask only.
Similar to Dask DataFrames, it is more efficient to first do spatial and temporal indexing (e.g. .sel() or .isel()) and filter the dataset early in the pipeline, especially before calling resample() or groupby().
Chunk sizes should be small enough to fit into the memory at once but large enough to avoid the additional communication overhead. Good chunk size ~100 MB.
It is always better to chunk along the
timedimension.Avoid too many tasks since each task will introduce 1ms of overhead.
When possible, use
xr.apply_ufuncto apply an unvectorized function to the Xarray object.
Close you local Dask Cluster¶
It is always a good practice to close the Dask cluster you created.
client.shutdown()
Summary¶
In this notebook, we have learned about:
- Using Dask with Xarray
- Read/write netCDF files with Dask
- Dask backed Xarray objects and operations
- Extract Dask arrays from Xarray objects and use Dask array directly..
- Customized workflows using
apply_ufunc
Resources and references¶
Reference¶
- Dask Array Docs
- Dask Examples
- Dask Code
- Dask Blog
- Xarray Docs
- Xarray + Dask docs, particularly the best practices
- Xarray Tutorial material
Ask for help¶
dasktag on Stack Overflow, for usage questions- github discussions: dask for general, non-bug, discussion, and usage questions
- github issues: dask for bug reports and feature requests
- github discussions: xarray for general, non-bug, discussion, and usage questions
- github issues: xarray for bug reports and feature requests