![]()
Arango AQL Tutorial¶
This is a tutorial on ArangoDB’s query language AQL, built around a small dataset of characters from the novel and fantasy drama television series Game of Thrones (as of season 1). It includes character traits in two languages, some family relations, and last but not least a small set of filming locations, which makes for an interesting mix of data to work with.
Although there are 2 mainstream Python client against ArangoDB:
this notebook only uses python-arango for the following reasons:
- python-arango is under arangodb GitHub organization which is the official Arango GitHub whereas pyArango is under ArangoDB-Community, a non-official community
- ArangoDB officially claims that python-arango to be the official ArangoDB driver
Setup¶
import json
import requests
import sys
import oasis # this is a local module "notebooks/arangodb/oasis.py"
import time
from IPython.display import JSON
Let's Create the temporary database:
Note: this notebook uses a temporary instance which will be autodeleted!
login = oasis.getTempCredentials(
tutorialName="AQLCrudTutorial",
credentialProvider='https://tutorials.arangodb.cloud:8529/_db/_system/tutorialDB/tutorialDB'
)
database = oasis.connect_python_arango(login)
aql = database.aql
print("https://{}:{}".format(login["hostname"], login["port"]))
print("Username: " + login["username"])
print("Password: " + login["password"])
print("Database: " + login["dbName"])
Reusing cached credentials. https://tutorials.arangodb.cloud:8529 Username: TUTp438ewtckve1azy38fm2db Password: TUTi72a655whasdowhjmv1ni Database: TUTlvl5ucvwsvmb8pnvqgk185
We should be able to see an URL, a Username, a Password, and a Database printed above. Feel free to click the URL which will take us to the ArangoDB UI. On the login page, use the Username and Password above as thelogin credential, then on the next page choose the printed Database as the selected database. The UI should look like the screenshot below:

Making Sure Database is Empty¶
This notebook supports consistency over mutiple top-to-bottom runs. It is, therefore, necessary to clear the database before each run. We do so by deleting all non-system collections:
for collection in database.collections():
if not collection["system"]:
database.delete_collection(collection["name"])
Creating Collections¶
Before we can insert documents (data) with AQL into database, we need a place to put them in - a Collection. Collections can be managed via the web interface, arangosh or a driver. It is not possible to do so with AQL however.
if not database.has_collection("Characters"):
database.create_collection("Characters")
print("We have 'Characters' collection now.")
We have 'Characters' collection now.
Creating and Reading Documents¶
The syntax for creating a new document is INSERT document INTO collectionName. The document is an object like we may know it from JavaScript or JSON, which is comprised of attribute key and value pairs. The quotes around the attribute keys are optional in AQL. Keys are always character sequences (strings), whereas attribute values can have different types:
- null
- boolean (true, false)
- number (integer and floating point)
- string
- array
- object
Name and surname of the character document we will be inserting are both string values. The alive state uses a boolean. Age is a numeric value. The traits are an array of strings. The entire document is an object.
check_query = f"""
FOR doc IN Characters
FILTER """
conditions = []
for key, value in {"name": "Ned", "surname": "Stark"}.items():
conditions.append(f"doc.{key} == '{value}'")
check_query += " AND ".join(conditions)
check_query += """
RETURN doc
"""
cursor = aql.execute(check_query)
if len(list(cursor)) <= 0:
insert_query = """
INSERT {
"name": "Ned",
"surname": "Stark",
"alive": true,
"age": 41,
"traits": ["A","H","C","N","P"]
} INTO Characters
"""
aql.execute(insert_query)
We can also execute all the queries on the ArangoDB Web UI:
Let's check whether the insert was sucessfull by querying the Characters collections. The syntax of the loop is FOR variableName IN collectionName.
all_characters = """
FOR character IN Characters
RETURN character
"""
query_result = aql.execute(all_characters)
for doc in query_result:
print(doc)
print()
{'_key': '266281975100', '_id': 'Characters/266281975100', '_rev': '_jNAZqFC---', 'name': 'Ned', 'surname': 'Stark', 'alive': True, 'age': 41, 'traits': ['A', 'H', 'C', 'N', 'P']}
For each document in the collection, character is assigned a document, which is then returned as per the loop body.
Each document features the 5 attributes we stored, plus 3 more added by the database system
- a unique
_key, which identifies it within a collection - an
_idwhich is a computed property - a concatenation of the collection name, a forward slash/and the document key. It uniquely identies a document within a database _rev, the revision ID managed by the system. Older revisions of a document cannot be accessed.
Document keys can be provided by the user upon document creation, or a unique value is assigned automatically. It can not be changed later. All 3 system attributes starting with an underscore _ are read-only.
Next, let us add some more characters. We use the LET keyword to define a named variable with an array of objects as value, so LET variableName = valueExpression and the expression being a literal array definition like [ {...}, {...}, ... ].
FOR variableName IN expression is used to iterate over each element of the data array. In each loop, one element is assigned to the variable d. This variable is then used in the INSERT statement instead of a literal object definition. What is does is basically:
insert_query = """
LET data = [
{ "name": "Robert", "surname": "Baratheon", "alive": false, "traits": ["A","H","C"] },
{ "name": "Jaime", "surname": "Lannister", "alive": true, "age": 36, "traits": ["A","F","B"] },
{ "name": "Catelyn", "surname": "Stark", "alive": false, "age": 40, "traits": ["D","H","C"] },
{ "name": "Cersei", "surname": "Lannister", "alive": true, "age": 36, "traits": ["H","E","F"] },
{ "name": "Daenerys", "surname": "Targaryen", "alive": true, "age": 16, "traits": ["D","H","C"] },
{ "name": "Jorah", "surname": "Mormont", "alive": false, "traits": ["A","B","C","F"] },
{ "name": "Petyr", "surname": "Baelish", "alive": false, "traits": ["E","G","F"] },
{ "name": "Viserys", "surname": "Targaryen", "alive": false, "traits": ["O","L","N"] },
{ "name": "Jon", "surname": "Snow", "alive": true, "age": 16, "traits": ["A","B","C","F"] },
{ "name": "Sansa", "surname": "Stark", "alive": true, "age": 13, "traits": ["D","I","J"] },
{ "name": "Arya", "surname": "Stark", "alive": true, "age": 11, "traits": ["C","K","L"] },
{ "name": "Robb", "surname": "Stark", "alive": false, "traits": ["A","B","C","K"] },
{ "name": "Theon", "surname": "Greyjoy", "alive": true, "age": 16, "traits": ["E","R","K"] },
{ "name": "Bran", "surname": "Stark", "alive": true, "age": 10, "traits": ["L","J"] },
{ "name": "Joffrey", "surname": "Baratheon", "alive": false, "age": 19, "traits": ["I","L","O"] },
{ "name": "Sandor", "surname": "Clegane", "alive": true, "traits": ["A","P","K","F"] },
{ "name": "Tyrion", "surname": "Lannister", "alive": true, "age": 32, "traits": ["F","K","M","N"] },
{ "name": "Khal", "surname": "Drogo", "alive": false, "traits": ["A","C","O","P"] },
{ "name": "Tywin", "surname": "Lannister", "alive": false, "traits": ["O","M","H","F"] },
{ "name": "Davos", "surname": "Seaworth", "alive": true, "age": 49, "traits": ["C","K","P","F"] },
{ "name": "Samwell", "surname": "Tarly", "alive": true, "age": 17, "traits": ["C","L","I"] },
{ "name": "Stannis", "surname": "Baratheon", "alive": false, "traits": ["H","O","P","M"] },
{ "name": "Melisandre", "alive": true, "traits": ["G","E","H"] },
{ "name": "Margaery", "surname": "Tyrell", "alive": false, "traits": ["M","D","B"] },
{ "name": "Jeor", "surname": "Mormont", "alive": false, "traits": ["C","H","M","P"] },
{ "name": "Bronn", "alive": true, "traits": ["K","E","C"] },
{ "name": "Varys", "alive": true, "traits": ["M","F","N","E"] },
{ "name": "Shae", "alive": false, "traits": ["M","D","G"] },
{ "name": "Talisa", "surname": "Maegyr", "alive": false, "traits": ["D","C","B"] },
{ "name": "Gendry", "alive": false, "traits": ["K","C","A"] },
{ "name": "Ygritte", "alive": false, "traits": ["A","P","K"] },
{ "name": "Tormund", "surname": "Giantsbane", "alive": true, "traits": ["C","P","A","I"] },
{ "name": "Gilly", "alive": true, "traits": ["L","J"] },
{ "name": "Brienne", "surname": "Tarth", "alive": true, "age": 32, "traits": ["P","C","A","K"] },
{ "name": "Ramsay", "surname": "Bolton", "alive": true, "traits": ["E","O","G","A"] },
{ "name": "Ellaria", "surname": "Sand", "alive": true, "traits": ["P","O","A","E"] },
{ "name": "Daario", "surname": "Naharis", "alive": true, "traits": ["K","P","A"] },
{ "name": "Missandei", "alive": true, "traits": ["D","L","C","M"] },
{ "name": "Tommen", "surname": "Baratheon", "alive": true, "traits": ["I","L","B"] },
{ "name": "Jaqen", "surname": "H'ghar", "alive": true, "traits": ["H","F","K"] },
{ "name": "Roose", "surname": "Bolton", "alive": true, "traits": ["H","E","F","A"] },
{ "name": "The High Sparrow", "alive": true, "traits": ["H","M","F","O"] }
]
FOR d IN data
INSERT d INTO Characters
"""
aql.execute(insert_query)
<Cursor>
As before let's check the Characters collection, but this time only return each characters name:
all_characters_names = """
FOR character IN Characters
RETURN character.name
"""
query_result = aql.execute(all_characters_names)
for doc in query_result:
print(doc)
print()
Ned Robert Jaime Catelyn Cersei Daenerys Jorah Petyr Viserys Jon Sansa Arya Robb Theon Bran Joffrey Sandor Tyrion Khal Tywin Davos Samwell Stannis Melisandre Margaery Jeor Bronn Varys Shae Talisa Gendry Ygritte Tormund Gilly Brienne Ramsay Ellaria Daario Missandei Tommen Jaqen Roose The High Sparrow
Updating Documents¶
Let's say we need to change the alive attribute of Ned. For this we first identify the _key attribute of Ned
find_ned_query = """
FOR character IN Characters
FILTER character.name == "Ned"
RETURN character._key
"""
neds_document_key = None
query_result = aql.execute(find_ned_query)
for doc in query_result:
print("_key: " + str(doc))
neds_document_key = doc
print()
_key: 266281975100
Using key we can update an existing document:
kill_ned = """
UPDATE @key
WITH { alive: false}
IN Characters
"""
bindVars = {'key': neds_document_key}
aql.execute(kill_ned, batch_size=1, bind_vars=bindVars)
find_ned_query = """
FOR character IN Characters
FILTER character.name == "Ned"
RETURN character
"""
query_result = aql.execute(find_ned_query)
for doc in query_result:
print(doc)
print()
{'_key': '266281975100', '_id': 'Characters/266281975100', '_rev': '_jNAZtBu--_', 'name': 'Ned', 'surname': 'Stark', 'alive': False, 'age': 41, 'traits': ['A', 'H', 'C', 'N', 'P']}
We could have also replaced the entire document content, using REPLACE instead of UPDATE:
kill_ned = """
REPLACE @key WITH {
name: "Ned",
surname: "Stark",
alive: false,
age: 41,
traits: ["A","H","C","N","P"]
} IN Characters
"""
bindVars = {'key': neds_document_key}
aql.execute(kill_ned, batch_size=1, bind_vars=bindVars)
find_ned_query = """
FOR character IN Characters
FILTER character.name == "Ned"
RETURN character
"""
query_result = aql.execute(find_ned_query)
for doc in query_result:
print(doc)
print()
{'_key': '266281975100', '_id': 'Characters/266281975100', '_rev': '_jNAZth---_', 'age': 41, 'alive': False, 'name': 'Ned', 'surname': 'Stark', 'traits': ['A', 'H', 'C', 'N', 'P']}
We could again use the FOR loop construct from before to update all characters:
season_query = """
FOR character IN Characters
UPDATE character WITH { season: 1 } IN Characters
"""
aql.execute(season_query)
all_characters_names_season = """
FOR character IN Characters
RETURN {"Name" : character.name, "Season" : character.season}
"""
query_result = aql.execute(all_characters_names_season)
for doc in query_result:
print(doc)
print()
{'Name': 'Ned', 'Season': 1}
{'Name': 'Robert', 'Season': 1}
{'Name': 'Jaime', 'Season': 1}
{'Name': 'Catelyn', 'Season': 1}
{'Name': 'Cersei', 'Season': 1}
{'Name': 'Daenerys', 'Season': 1}
{'Name': 'Jorah', 'Season': 1}
{'Name': 'Petyr', 'Season': 1}
{'Name': 'Viserys', 'Season': 1}
{'Name': 'Jon', 'Season': 1}
{'Name': 'Sansa', 'Season': 1}
{'Name': 'Arya', 'Season': 1}
{'Name': 'Robb', 'Season': 1}
{'Name': 'Theon', 'Season': 1}
{'Name': 'Bran', 'Season': 1}
{'Name': 'Joffrey', 'Season': 1}
{'Name': 'Sandor', 'Season': 1}
{'Name': 'Tyrion', 'Season': 1}
{'Name': 'Khal', 'Season': 1}
{'Name': 'Tywin', 'Season': 1}
{'Name': 'Davos', 'Season': 1}
{'Name': 'Samwell', 'Season': 1}
{'Name': 'Stannis', 'Season': 1}
{'Name': 'Melisandre', 'Season': 1}
{'Name': 'Margaery', 'Season': 1}
{'Name': 'Jeor', 'Season': 1}
{'Name': 'Bronn', 'Season': 1}
{'Name': 'Varys', 'Season': 1}
{'Name': 'Shae', 'Season': 1}
{'Name': 'Talisa', 'Season': 1}
{'Name': 'Gendry', 'Season': 1}
{'Name': 'Ygritte', 'Season': 1}
{'Name': 'Tormund', 'Season': 1}
{'Name': 'Gilly', 'Season': 1}
{'Name': 'Brienne', 'Season': 1}
{'Name': 'Ramsay', 'Season': 1}
{'Name': 'Ellaria', 'Season': 1}
{'Name': 'Daario', 'Season': 1}
{'Name': 'Missandei', 'Season': 1}
{'Name': 'Tommen', 'Season': 1}
{'Name': 'Jaqen', 'Season': 1}
{'Name': 'Roose', 'Season': 1}
{'Name': 'The High Sparrow', 'Season': 1}
Note, that here we customized the RETURN to return a json document consisting of name and season.
Filtering Documents¶
To find documents that fulfill certain criteria more complex than key equality, there is the FILTER operation in AQL, which enables us to formulate arbitrary conditions for documents to match.
We actually have used a filter condition before to find Ned:
find_ned_query = """
FOR character IN Characters
FILTER character.name == "Ned"
RETURN character
"""
query_result = aql.execute(find_ned_query)
for doc in query_result:
print(doc)
print()
{'_key': '266281975100', '_id': 'Characters/266281975100', '_rev': '_jNAZuGu---', 'age': 41, 'alive': False, 'name': 'Ned', 'surname': 'Stark', 'traits': ['A', 'H', 'C', 'N', 'P'], 'season': 1}
The filter condition reads like: “the attribute name of a character document must be equal to the string Ned”. If the condition applies, character document gets returned. This works with any attribute likewise:
find_ned_query = """
FOR character IN Characters
FILTER character.surname == "Stark"
RETURN character
"""
query_result = aql.execute(find_ned_query)
for doc in query_result:
print(doc)
print()
{'_key': '266281975100', '_id': 'Characters/266281975100', '_rev': '_jNAZuGu---', 'age': 41, 'alive': False, 'name': 'Ned', 'surname': 'Stark', 'traits': ['A', 'H', 'C', 'N', 'P'], 'season': 1}
{'_key': '266281975104', '_id': 'Characters/266281975104', '_rev': '_jNAZuGu--B', 'name': 'Catelyn', 'surname': 'Stark', 'alive': False, 'age': 40, 'traits': ['D', 'H', 'C'], 'season': 1}
{'_key': '266281975111', '_id': 'Characters/266281975111', '_rev': '_jNAZuGu--I', 'name': 'Sansa', 'surname': 'Stark', 'alive': True, 'age': 13, 'traits': ['D', 'I', 'J'], 'season': 1}
{'_key': '266281975112', '_id': 'Characters/266281975112', '_rev': '_jNAZuGu--J', 'name': 'Arya', 'surname': 'Stark', 'alive': True, 'age': 11, 'traits': ['C', 'K', 'L'], 'season': 1}
{'_key': '266281975113', '_id': 'Characters/266281975113', '_rev': '_jNAZuGu--K', 'name': 'Robb', 'surname': 'Stark', 'alive': False, 'traits': ['A', 'B', 'C', 'K'], 'season': 1}
{'_key': '266281975115', '_id': 'Characters/266281975115', '_rev': '_jNAZuGu--M', 'name': 'Bran', 'surname': 'Stark', 'alive': True, 'age': 10, 'traits': ['L', 'J'], 'season': 1}
Range Conditions¶
Strict equality is one possible condition we can state. There are plenty of other conditions we can formulate however. For example, we could ask for all young characters:
find_adults_query = """
FOR character IN Characters
FILTER character.age >= 13
RETURN character.name
"""
query_result = aql.execute(find_adults_query)
for doc in query_result:
print(doc)
print()
Ned Jaime Catelyn Cersei Daenerys Jon Sansa Theon Joffrey Tyrion Davos Samwell Brienne
The operator >= stands for greater-or-equal, so every character of age 13 or older is returned (only their name in the example). We can return names and age of all characters younger than 13 by changing the operator to less-than and using the object syntax to define a subset of attributes to return:
find_young_query = """
FOR character IN Characters
FILTER character.age < 13
RETURN { name: character.name, age: character.age }
"""
query_result = aql.execute(find_young_query)
for doc in query_result:
print(doc)
print()
{'name': 'Robert', 'age': None}
{'name': 'Jorah', 'age': None}
{'name': 'Petyr', 'age': None}
{'name': 'Viserys', 'age': None}
{'name': 'Arya', 'age': 11}
{'name': 'Robb', 'age': None}
{'name': 'Bran', 'age': 10}
{'name': 'Sandor', 'age': None}
{'name': 'Khal', 'age': None}
{'name': 'Tywin', 'age': None}
{'name': 'Stannis', 'age': None}
{'name': 'Melisandre', 'age': None}
{'name': 'Margaery', 'age': None}
{'name': 'Jeor', 'age': None}
{'name': 'Bronn', 'age': None}
{'name': 'Varys', 'age': None}
{'name': 'Shae', 'age': None}
{'name': 'Talisa', 'age': None}
{'name': 'Gendry', 'age': None}
{'name': 'Ygritte', 'age': None}
{'name': 'Tormund', 'age': None}
{'name': 'Gilly', 'age': None}
{'name': 'Ramsay', 'age': None}
{'name': 'Ellaria', 'age': None}
{'name': 'Daario', 'age': None}
{'name': 'Missandei', 'age': None}
{'name': 'Tommen', 'age': None}
{'name': 'Jaqen', 'age': None}
{'name': 'Roose', 'age': None}
{'name': 'The High Sparrow', 'age': None}
We may notice that it returns name and age of 30 characters, most with an age of null. The reason is that null is the fallback value if an attribute is requested by the query, but no such attribute exists in the document, and the null is compares to numbers as lower (see Type and value order). Hence, it accidentally fulfills the age criterion character.age < 13 (null < 13). To not let documents pass the filter without an age attribute, we can add a second criterion:
find_young_query = """
FOR character IN Characters
FILTER character.age < 13
FILTER character.age != null
RETURN { name: character.name, age: character.age }
"""
query_result = aql.execute(find_young_query)
for doc in query_result:
print(doc)
print()
{'name': 'Arya', 'age': 11}
{'name': 'Bran', 'age': 10}
This could equally be written with a boolean AND operator as:
find_young_query = """
FOR character IN Characters
FILTER character.age < 13 AND character.age != null
RETURN { name: character.name, age: character.age }
"""
query_result = aql.execute(find_young_query)
for doc in query_result:
print(doc)
print()
{'name': 'Arya', 'age': 11}
{'name': 'Bran', 'age': 10}
If we want documents to fulfill one or another condition, possibly for different attributes as well, use OR:
find_joffrey_query = """
FOR character IN Characters
FILTER character.name == "Jon" OR character.name == "Joffrey"
RETURN { name: character.name, surname: character.surname }
"""
query_result = aql.execute(find_joffrey_query)
for doc in query_result:
print(doc)
print()
{'name': 'Jon', 'surname': 'Snow'}
{'name': 'Joffrey', 'surname': 'Baratheon'}
To learn more about Filter Operation check the documentation.
Sorting Documents¶
To return characters in a defined order, we can add a SORT() operation.
all_characters_names = """
FOR character IN Characters
SORT character.name
RETURN character.name
"""
query_result = aql.execute(all_characters_names)
for doc in query_result:
print(doc)
print()
Arya Bran Brienne Bronn Catelyn Cersei Daario Daenerys Davos Ellaria Gendry Gilly Jaime Jaqen Jeor Joffrey Jon Jorah Khal Margaery Melisandre Missandei Ned Petyr Ramsay Robb Robert Roose Samwell Sandor Sansa Shae Stannis Talisa The High Sparrow Theon Tommen Tormund Tyrion Tywin Varys Viserys Ygritte
We can reverse the sort order with DESC:
all_characters_names = """
FOR character IN Characters
SORT character.name DESC
RETURN character.name
"""
query_result = aql.execute(all_characters_names)
for doc in query_result:
print(doc)
print()
Ygritte Viserys Varys Tywin Tyrion Tormund Tommen Theon The High Sparrow Talisa Stannis Shae Sansa Sandor Samwell Roose Robert Robb Ramsay Petyr Ned Missandei Melisandre Margaery Khal Jorah Jon Joffrey Jeor Jaqen Jaime Gilly Gendry Ellaria Davos Daenerys Daario Cersei Catelyn Bronn Brienne Bran Arya
Sorting by Multiple Attributes¶
Assume we want to sort by surname. Many of the characters share a surname. The result order among characters with the same surname is then undefined. We can first sort by surname, then name to determine the order:
all_characters_names = """
FOR character IN Characters
FILTER character.surname
SORT character.surname, character.name
LIMIT 10
RETURN {
surname: character.surname,
name: character.name
}
"""
query_result = aql.execute(all_characters_names)
for doc in query_result:
print(doc)
print()
{'surname': 'Baelish', 'name': 'Petyr'}
{'surname': 'Baratheon', 'name': 'Joffrey'}
{'surname': 'Baratheon', 'name': 'Robert'}
{'surname': 'Baratheon', 'name': 'Stannis'}
{'surname': 'Baratheon', 'name': 'Tommen'}
{'surname': 'Bolton', 'name': 'Ramsay'}
{'surname': 'Bolton', 'name': 'Roose'}
{'surname': 'Clegane', 'name': 'Sandor'}
{'surname': 'Drogo', 'name': 'Khal'}
{'surname': 'Giantsbane', 'name': 'Tormund'}
Overall, the documents are sorted by last name. If the surname is the same for two characters, the name values are compared and the result sorted.
More information about SORT can be found in its documentation
Pagination¶
It may not always be necessary to return all documents, that a FOR loop would normally return. In those cases, we can limit the amount of documents with a LIMIT() operation:
sample_chars_query = """
FOR character IN Characters
SORT character.name
LIMIT 5
RETURN character.name
"""
query_result = aql.execute(sample_chars_query)
for doc in query_result:
print(doc)
print()
Arya Bran Brienne Bronn Catelyn
When LIMIT is followed 2 numbers, however, the first number specifies the number of documents that are to be skipped and return the next second-number documents. This effectively achieves the pagination:
sample_chars_query = """
FOR character IN Characters
SORT character.name
LIMIT 2, 5
RETURN character.name
"""
query_result = aql.execute(sample_chars_query)
for doc in query_result:
print(doc)
print()
Brienne Bronn Catelyn Cersei Daario
More information about LIMIT can be found in its documentation
Putting Everying Together¶
Let's address a slightly complex business query - finds the 10 youngest characters:
sample_chars_query = """
FOR character IN Characters
FILTER character.age
SORT character.age
LIMIT 10
RETURN {
name: character.name,
age: character.age
}
"""
query_result = aql.execute(sample_chars_query)
for doc in query_result:
print(doc)
print()
{'name': 'Bran', 'age': 10}
{'name': 'Arya', 'age': 11}
{'name': 'Sansa', 'age': 13}
{'name': 'Daenerys', 'age': 16}
{'name': 'Jon', 'age': 16}
{'name': 'Theon', 'age': 16}
{'name': 'Samwell', 'age': 17}
{'name': 'Joffrey', 'age': 19}
{'name': 'Tyrion', 'age': 32}
{'name': 'Brienne', 'age': 32}
AQL Join¶
The character data we imported has an attribute traits for each character, which is an array of strings. It does not store character features directly however:
find_ned_query = """
FOR character IN Characters
FILTER character.name == "Ned"
RETURN {"Name": character.name, "Traits": character.traits}
"""
query_result = aql.execute(find_ned_query)
for doc in query_result:
print(doc)
print()
{'Name': 'Ned', 'Traits': ['A', 'H', 'C', 'N', 'P']}
Traits in this dataset are rather a list of letters without an apparent meaning. The idea here is that traits is supposed to store documents keys of another collection, which we can use to resolve the letters to labels such as “strong”. The benefit of using another collection for the actual traits is, that we can easily query for all existing traits later on and store labels in multiple languages for instance in a central place. If we would embed traits directly like this
{
"Name": "Ned",
"Traits": [
{
"de": "stark",
"en": "strong"
},
{
"de": "einflussreich",
"en": "powerful"
},
{
"de": "loyal",
"en": "loyal"
},
{
"de": "rational",
"en": "rational"
},
{
"de": "mutig",
"en": "brave"
}
]
}
it becomes really hard to maintain traits. If we were to rename or translate one of them, we would need to find all other character documents with the same trait and perform the changes there too. If we only refer to a trait in another collection, it is as easy as updating a single document.

Creating Traits Collection¶
Let's load our traits collection
if not database.has_collection("Traits"):
database.create_collection("Traits")
insert_query = """
LET data = [
{ "_key": "A", "en": "strong", "de": "stark" },
{ "_key": "B", "en": "polite", "de": "freundlich" },
{ "_key": "C", "en": "loyal", "de": "loyal" },
{ "_key": "D", "en": "beautiful", "de": "schön" },
{ "_key": "E", "en": "sneaky", "de": "hinterlistig" },
{ "_key": "F", "en": "experienced", "de": "erfahren" },
{ "_key": "G", "en": "corrupt", "de": "korrupt" },
{ "_key": "H", "en": "powerful", "de": "einflussreich" },
{ "_key": "I", "en": "naive", "de": "naiv" },
{ "_key": "J", "en": "unmarried", "de": "unverheiratet" },
{ "_key": "K", "en": "skillful", "de": "geschickt" },
{ "_key": "L", "en": "young", "de": "jung" },
{ "_key": "M", "en": "smart", "de": "klug" },
{ "_key": "N", "en": "rational", "de": "rational" },
{ "_key": "O", "en": "ruthless", "de": "skrupellos" },
{ "_key": "P", "en": "brave", "de": "mutig" },
{ "_key": "Q", "en": "mighty", "de": "mächtig" },
{ "_key": "R", "en": "weak", "de": "schwach" }
]
FOR d IN data
INSERT d INTO Traits
"""
aql.execute(insert_query)
all_traits = """
FOR trait IN Traits
RETURN trait
"""
query_result = aql.execute(all_traits)
for doc in query_result:
print(doc)
print()
{'_key': 'A', '_id': 'Traits/A', '_rev': '_jNAZz1S---', 'en': 'strong', 'de': 'stark'}
{'_key': 'B', '_id': 'Traits/B', '_rev': '_jNAZz1S--_', 'en': 'polite', 'de': 'freundlich'}
{'_key': 'C', '_id': 'Traits/C', '_rev': '_jNAZz1S--A', 'en': 'loyal', 'de': 'loyal'}
{'_key': 'D', '_id': 'Traits/D', '_rev': '_jNAZz1S--B', 'en': 'beautiful', 'de': 'schön'}
{'_key': 'E', '_id': 'Traits/E', '_rev': '_jNAZz1S--C', 'en': 'sneaky', 'de': 'hinterlistig'}
{'_key': 'F', '_id': 'Traits/F', '_rev': '_jNAZz1S--D', 'en': 'experienced', 'de': 'erfahren'}
{'_key': 'G', '_id': 'Traits/G', '_rev': '_jNAZz1S--E', 'en': 'corrupt', 'de': 'korrupt'}
{'_key': 'H', '_id': 'Traits/H', '_rev': '_jNAZz1S--F', 'en': 'powerful', 'de': 'einflussreich'}
{'_key': 'I', '_id': 'Traits/I', '_rev': '_jNAZz1S--G', 'en': 'naive', 'de': 'naiv'}
{'_key': 'J', '_id': 'Traits/J', '_rev': '_jNAZz1S--H', 'en': 'unmarried', 'de': 'unverheiratet'}
{'_key': 'K', '_id': 'Traits/K', '_rev': '_jNAZz1S--I', 'en': 'skillful', 'de': 'geschickt'}
{'_key': 'L', '_id': 'Traits/L', '_rev': '_jNAZz1S--J', 'en': 'young', 'de': 'jung'}
{'_key': 'M', '_id': 'Traits/M', '_rev': '_jNAZz1S--K', 'en': 'smart', 'de': 'klug'}
{'_key': 'N', '_id': 'Traits/N', '_rev': '_jNAZz1S--L', 'en': 'rational', 'de': 'rational'}
{'_key': 'O', '_id': 'Traits/O', '_rev': '_jNAZz1S--N', 'en': 'ruthless', 'de': 'skrupellos'}
{'_key': 'P', '_id': 'Traits/P', '_rev': '_jNAZz1S--O', 'en': 'brave', 'de': 'mutig'}
{'_key': 'Q', '_id': 'Traits/Q', '_rev': '_jNAZz1S--P', 'en': 'mighty', 'de': 'mächtig'}
{'_key': 'R', '_id': 'Traits/R', '_rev': '_jNAZz1S--Q', 'en': 'weak', 'de': 'schwach'}
Joining Traits¶
Now we can use the traits array together with the DOCUMENT() function to use the elements as document keys and look them up in the Traits collection. The DOCUMENT() function can be used to look up a single or multiple documents via document identifiers. In our example, we pass the collection name from which we want to fetch documents as the first argument ("Traits") and an array of document keys (_key attribute) as the second argument. In the RETURN statement we get an array of the full trait documents for each character.
all_characters_traits = """
FOR character IN Characters
LIMIT 5
RETURN DOCUMENT("Traits", character.traits)[*].en
"""
query_result = aql.execute(all_characters_traits)
for doc in query_result:
print(doc)
print()
['strong', 'powerful', 'loyal', 'rational', 'brave'] ['strong', 'powerful', 'loyal'] ['strong', 'experienced', 'polite'] ['beautiful', 'powerful', 'loyal'] ['powerful', 'sneaky', 'experienced']
Great, we resolved the letters to meaningful traits! But we also need to know to which character they belong. Thus, we need to merge both the character document and the data from the trait documents:
all_characters_traits = """
FOR character IN Characters
LIMIT 5
RETURN MERGE(character, { traits: DOCUMENT("Traits", character.traits)[*].en } )
"""
query_result = aql.execute(all_characters_traits)
for doc in query_result:
print(doc)
print()
{'_id': 'Characters/266281975100', '_key': '266281975100', '_rev': '_jNAZuGu---', 'age': 41, 'alive': False, 'name': 'Ned', 'season': 1, 'surname': 'Stark', 'traits': ['strong', 'powerful', 'loyal', 'rational', 'brave']}
{'_id': 'Characters/266281975102', '_key': '266281975102', '_rev': '_jNAZuGu--_', 'alive': False, 'name': 'Robert', 'season': 1, 'surname': 'Baratheon', 'traits': ['strong', 'powerful', 'loyal']}
{'_id': 'Characters/266281975103', '_key': '266281975103', '_rev': '_jNAZuGu--A', 'age': 36, 'alive': True, 'name': 'Jaime', 'season': 1, 'surname': 'Lannister', 'traits': ['strong', 'experienced', 'polite']}
{'_id': 'Characters/266281975104', '_key': '266281975104', '_rev': '_jNAZuGu--B', 'age': 40, 'alive': False, 'name': 'Catelyn', 'season': 1, 'surname': 'Stark', 'traits': ['beautiful', 'powerful', 'loyal']}
{'_id': 'Characters/266281975105', '_key': '266281975105', '_rev': '_jNAZuGu--C', 'age': 36, 'alive': True, 'name': 'Cersei', 'season': 1, 'surname': 'Lannister', 'traits': ['powerful', 'sneaky', 'experienced']}
The MERGE() function merges objects together. Because we used an object { traits: ... } which has the same attribute name traits as the original character attribute, the latter (original) got overwritten by the merge operation.
The DOCUMENT() function utilizes primary indices to look up documents quickly. It is limited to find documents via their identifiers however. For a use case like the one above it is sufficient to accomplish a simple join.
There is another, more flexible syntax for joins: nested FOR loops over multiple collections, with a FILTER condition to match up attributes. In case of the traits key array, there needs to be a third loop to iterate over the keys:
all_characters_traits = """
FOR character IN Characters
LIMIT 5
RETURN MERGE(character, {
traits: (
FOR key IN character.traits
FOR trait IN Traits
FILTER trait._key == key
RETURN trait.en
)
})
"""
query_result = aql.execute(all_characters_traits)
for doc in query_result:
print(doc)
print()
{'_id': 'Characters/266281975100', '_key': '266281975100', '_rev': '_jNAZuGu---', 'age': 41, 'alive': False, 'name': 'Ned', 'season': 1, 'surname': 'Stark', 'traits': ['strong', 'powerful', 'loyal', 'rational', 'brave']}
{'_id': 'Characters/266281975102', '_key': '266281975102', '_rev': '_jNAZuGu--_', 'alive': False, 'name': 'Robert', 'season': 1, 'surname': 'Baratheon', 'traits': ['strong', 'powerful', 'loyal']}
{'_id': 'Characters/266281975103', '_key': '266281975103', '_rev': '_jNAZuGu--A', 'age': 36, 'alive': True, 'name': 'Jaime', 'season': 1, 'surname': 'Lannister', 'traits': ['strong', 'experienced', 'polite']}
{'_id': 'Characters/266281975104', '_key': '266281975104', '_rev': '_jNAZuGu--B', 'age': 40, 'alive': False, 'name': 'Catelyn', 'season': 1, 'surname': 'Stark', 'traits': ['beautiful', 'powerful', 'loyal']}
{'_id': 'Characters/266281975105', '_key': '266281975105', '_rev': '_jNAZuGu--C', 'age': 36, 'alive': True, 'name': 'Cersei', 'season': 1, 'surname': 'Lannister', 'traits': ['powerful', 'sneaky', 'experienced']}
For each character, it loops over its traits attribute (e.g. ["D","H","C"]) and for each document reference in this array, it loops over the Traits collections. There is a condition to match the document key with the key reference. The inner FOR loop and the FILTER get transformed to a primary index lookup in this case instead of building up a Cartesian product only to filter away everything but a single match: Document keys within a collection are unique, thus there can only be one match.
Each written-out, English trait is returned and all the traits are then merged with the character document. The result is identical to the query using DOCUMENT(). However, this approach with a nested FOR loop and a FILTER is not limited to primary keys. We can do this with any other attribute as well. For an efficient lookup, make sure to add a hash index for this joined attribute. If its values are unique, then also set the index option to unique.
Graph Traversals¶
This is why ArangoDB is a multi-model database, because now er aremoving from a document data model to graphs
Relations such as between parents and children can be modeled as graph. In ArangoDB, two documents (a parent and a child character document) can be linked by an edge document. Edge documents are stored in edge collections and have two additional attributes: _from and _to. They reference any two documents by their document IDs (_id).
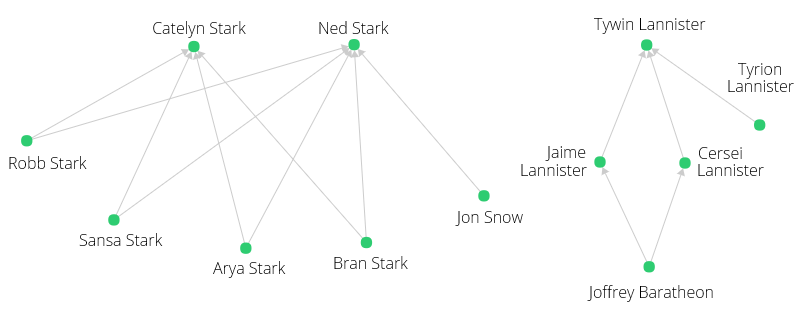
Our characters have the following relations between parents and children (first names only for a better overview):
| Child | Parent |
|---|---|
| Robb | Ned |
| Sansa | Ned |
| Arya | Ned |
| Bran | Ned |
| Jon | Ned |
| Robb | Catelyn |
| Sansa | Catelyn |
| Arya | Catelyn |
| Bran | Catelyn |
| Jaime | Tywin |
| Cersei | Tywin |
| Tyrion | Tywin |
| Joffrey | Jaime |
| Joffrey | Cersei |
We can visualize the same information in a graph, which often is easier to comprehend.
Creating Edges¶
To create the required edge documents to store these relations in the database, we can run a query that combines joining and filtering to match up the right character documents, then use their _id attribute to insert an edge into an edge collection.
if not database.has_collection("ChildOf"):
database.create_collection("ChildOf", edge=True)
For creating the edges we face one challenge: The character documents don’t have user-defined keys. If they had, it would allow us to create the edges more easily like:
INSERT { _from: "Characters/robb", _to: "Characters/ned" } INTO ChildOf
However, creating the edges programmatically based on character names is a good exercise. Breakdown of the query:
create_edges_query = """
LET data = [
{
"parent": { "name": "Ned", "surname": "Stark" },
"child": { "name": "Robb", "surname": "Stark" }
}, {
"parent": { "name": "Ned", "surname": "Stark" },
"child": { "name": "Sansa", "surname": "Stark" }
}, {
"parent": { "name": "Ned", "surname": "Stark" },
"child": { "name": "Arya", "surname": "Stark" }
}, {
"parent": { "name": "Ned", "surname": "Stark" },
"child": { "name": "Bran", "surname": "Stark" }
}, {
"parent": { "name": "Catelyn", "surname": "Stark" },
"child": { "name": "Robb", "surname": "Stark" }
}, {
"parent": { "name": "Catelyn", "surname": "Stark" },
"child": { "name": "Sansa", "surname": "Stark" }
}, {
"parent": { "name": "Catelyn", "surname": "Stark" },
"child": { "name": "Arya", "surname": "Stark" }
}, {
"parent": { "name": "Catelyn", "surname": "Stark" },
"child": { "name": "Bran", "surname": "Stark" }
}, {
"parent": { "name": "Ned", "surname": "Stark" },
"child": { "name": "Jon", "surname": "Snow" }
}, {
"parent": { "name": "Tywin", "surname": "Lannister" },
"child": { "name": "Jaime", "surname": "Lannister" }
}, {
"parent": { "name": "Tywin", "surname": "Lannister" },
"child": { "name": "Cersei", "surname": "Lannister" }
}, {
"parent": { "name": "Tywin", "surname": "Lannister" },
"child": { "name": "Tyrion", "surname": "Lannister" }
}, {
"parent": { "name": "Cersei", "surname": "Lannister" },
"child": { "name": "Joffrey", "surname": "Baratheon" }
}, {
"parent": { "name": "Jaime", "surname": "Lannister" },
"child": { "name": "Joffrey", "surname": "Baratheon" }
}
]
FOR rel in data
LET parentId = FIRST(
FOR c IN Characters
FILTER c.name == rel.parent.name
FILTER c.surname == rel.parent.surname
LIMIT 1
RETURN c._id
)
LET childId = FIRST(
FOR c IN Characters
FILTER c.name == rel.child.name
FILTER c.surname == rel.child.surname
LIMIT 1
RETURN c._id
)
FILTER parentId != null AND childId != null
INSERT { _from: childId, _to: parentId } INTO ChildOf
RETURN NEW
"""
query_result = aql.execute(create_edges_query)
Graph Traversal¶
Now that edges link character documents (vertices), we have a graph we can query to find out who the parents are of another character – or in graph terms, we want to start at a vertex and follow the edges to other vertices in an AQL graph traversal:
sansa_parents_query = """
// First find the start node, i.e., sansa
FOR character IN Characters
FILTER character.name == "Sansa"
// Then start a Graph traversal from that start node
FOR parent IN 1..1 OUTBOUND character ChildOf
RETURN parent.name
"""
query_result = aql.execute(sansa_parents_query)
for doc in query_result:
print(doc)
print()
Catelyn Ned
We can traverse the Graph also in the reverse direction (i.e., INBOUND) to find someones children:
ned_children_query = """
// First find the start node, i.e., ned
FOR character IN Characters
FILTER character.name == "Ned"
// Then start a Graph traversal from that start node
FOR child IN 1..1 INBOUND character ChildOf
RETURN child.name
"""
query_result = aql.execute(ned_children_query)
for doc in query_result:
print(doc)
print()
Jon Bran Arya Sansa Robb
Variable Length Traversals and Grandchildren¶
One might have wondered about the IN 1..1 specification. This part actually specifies how many hops should be considered for the Traversal. For the Lannister family, we have relations that span from parent to grandchild. Let’s change the traversal depth to return grandchildren, which means to go exactly two steps:
tywin_grandchildren_query = """
// First find the start node, i.e., ned
FOR character IN Characters
FILTER character.name == "Tywin"
// Then start a Graph traversal from that start node
FOR grandchild IN 2..2 INBOUND character ChildOf
RETURN grandchild.name
"""
query_result = aql.execute(tywin_grandchildren_query)
for doc in query_result:
print(doc)
print()
Joffrey Joffrey
It might be a bit unexpected, that Joffrey is returned twice. However, if we look at the graph visualization, we can see that multiple paths lead from Joffrey (bottom right) to Tywin:
As a quick fix, change the last line of the query to RETURN DISTINCT grandchild.name to return each value only once. Keep in mind though, that there are traversal options to suppress duplicate vertices early on.
tywin_grandchildren_query = """
// First find the start node, i.e., ned
FOR character IN Characters
FILTER character.name == "Tywin"
// Then start a Graph traversal from that start node
FOR grandchild IN 2..2 INBOUND character ChildOf
RETURN DISTINCT grandchild.name
"""
query_result = aql.execute(tywin_grandchildren_query)
for doc in query_result:
print(doc)
print()
Joffrey
To return the parents and grandparents of Joffrey, we can walk edges in OUTBOUND direction and adjust the traversal depth to go at least 1 step, and 2 at most (i.e., IN 1..2):
joffrey_ancestors_query = """
FOR character IN Characters
FILTER character.name == "Joffrey"
FOR ancestor IN 1..2 OUTBOUND character ChildOf
RETURN DISTINCT ancestor.name
"""
query_result = aql.execute(joffrey_ancestors_query)
for doc in query_result:
print(doc)
print()
Jaime Tywin Cersei
With deeper family trees, it is only be a matter of changing the depth values to query for great-grandchildren and similar relations.
Geospatical AQL¶
Geospatial coordinates consisting of a latitude and longitude value can be stored either as two separate attributes, or as a single attribute in the form of an array with both numeric values. ArangoDB can index such coordinates for fast geospatial queries.
Let us create a collection with some filming locations for Games of Thrones.

if not database.has_collection("Locations"):
database.create_collection("Locations")
insert_query = """
LET places = [
{ "name": "Dragonstone", "coordinate": [ 55.167801, -6.815096 ] },
{ "name": "King's Landing", "coordinate": [ 42.639752, 18.110189 ] },
{ "name": "The Red Keep", "coordinate": [ 35.896447, 14.446442 ] },
{ "name": "Yunkai", "coordinate": [ 31.046642, -7.129532 ] },
{ "name": "Astapor", "coordinate": [ 31.50974, -9.774249 ] },
{ "name": "Winterfell", "coordinate": [ 54.368321, -5.581312 ] },
{ "name": "Vaes Dothrak", "coordinate": [ 54.16776, -6.096125 ] },
{ "name": "Beyond the wall", "coordinate": [ 64.265473, -21.094093 ] }
]
FOR place IN places
INSERT place INTO Locations
"""
aql.execute(insert_query)
all_locations_names = """
FOR p IN Locations
RETURN p.name
"""
query_result = aql.execute(all_locations_names)
for doc in query_result:
print(doc)
print()
Dragonstone King's Landing The Red Keep Yunkai Astapor Winterfell Vaes Dothrak Beyond the wall
To query based on coordinates, a geo index is required. It determines which fields contain the latitude and longitude values.
database.collection("Locations").add_index({"type": "geo", "fields": ["coordinate"]})
{'fields': ['coordinate'],
'geoJson': False,
'id': '716820272',
'inBackground': False,
'isNewlyCreated': True,
'legacyPolygons': False,
'name': 'idx_1823687090027626496',
'sparse': True,
'type': 'geo',
'unique': False}
Finding Nearby Locations¶
A FOR loop is used to iterate over the results of a function call to NEAR() to find the n closest coordinates to a reference point, and return the documents with the nearby locations. The default for n is 100, which means 100 documents are returned at most, the closest matches first.
In below example, the limit is set to 3. The origin (the reference point) is a coordinate somewhere downtown in Dublin, Ireland:
near_locations_names = """
FOR loc IN NEAR(Locations, 53.35, -6.26, 3)
RETURN {
name: loc.name,
latitude: loc.coordinate[0],
longitude: loc.coordinate[1]
}
"""
query_result = aql.execute(near_locations_names)
for doc in query_result:
print(doc)
print()
{'name': 'Vaes Dothrak', 'latitude': 54.16776, 'longitude': -6.096125}
{'name': 'Winterfell', 'latitude': 54.368321, 'longitude': -5.581312}
{'name': 'Dragonstone', 'latitude': 55.167801, 'longitude': -6.815096}
The query returns the location name, as well as the coordinate. The coordinate is returned as two separate attributes. We may use a simpler RETURN loc instead if we want.
Finding Locations within Radius¶
Instead of NEAR() we can also use WITHIN(), to search for locations within a given radius from a reference point. The syntax is the same as for NEAR(), except for the fourth parameter, which specifies the radius instead of a limit. The unit for the radius is meters. The example uses a radius of 200,000 meters (200 kilometers):
within_locations_names = """
FOR loc IN WITHIN(Locations, 53.35, -6.26, 200 * 1000)
RETURN {
name: loc.name,
latitude: loc.coordinate[0],
longitude: loc.coordinate[1]
}
"""
query_result = aql.execute(within_locations_names)
for doc in query_result:
print(doc)
print()
{'name': 'Vaes Dothrak', 'latitude': 54.16776, 'longitude': -6.096125}
{'name': 'Winterfell', 'latitude': 54.368321, 'longitude': -5.581312}
Calculating Distances¶
Both NEAR() and WITHIN() can return the distance to the reference point by adding an optional fifth parameter. It has to be a string, which will be used as attribute name for an additional attribute with the distance in meters:
near_locations_names = """
FOR loc IN NEAR(Locations, 53.35, -6.26, 3, "distance")
RETURN {
name: loc.name,
latitude: loc.coordinate[0],
longitude: loc.coordinate[1],
distance: loc.distance / 1000
}
"""
query_result = aql.execute(near_locations_names)
for doc in query_result:
print(doc)
print()
{'name': 'Vaes Dothrak', 'latitude': 54.16776, 'longitude': -6.096125, 'distance': 91.56658640314484}
{'name': 'Winterfell', 'latitude': 54.368321, 'longitude': -5.581312, 'distance': 121.66399816395003}
{'name': 'Dragonstone', 'latitude': 55.167801, 'longitude': -6.815096, 'distance': 205.31879386198273}
The extra attribute, here called distance, is returned as part of the loc variable, as if it was part of the location document. The value is divided by 1000 in the example query, to convert the unit to kilometers, simply to make it better readable.
Deleting Documents¶
To fully remove documents from a collection, there is the REMOVE operation. It works similar to the other modification operations, yet without a WITH clause:
remove_ned = """
REMOVE @key IN Characters
"""
bindVars = {'key': neds_document_key}
try:
aql.execute(remove_ned, bind_vars=bindVars)
except:
print("Ned already removed.")
find_ned_query = """
FOR character IN Characters
FILTER character.name == "Ned"
RETURN character
"""
query_result = aql.execute(find_ned_query, count=True)
if len(query_result) == 0 :
print("Ned not found.")
Ned not found.
As we might have already guessed we can again use a FOR loop if we want to perform this operation for the entire collection:
remove_all = """
FOR character IN Characters
REMOVE character IN Characters
"""
aql.execute(remove_all)
all_characters_names = """
FOR character IN Characters
RETURN character
"""
query_result = aql.execute(all_characters_names, count=True)
if len(query_result) == 0 :
print("No characters left.")
No characters left.