Table Visualization¶
This section demonstrates visualization of tabular data using the Styler class. For information on visualization with charting please see Chart Visualization. This document is written as a Jupyter Notebook, and can be viewed or downloaded here.
Styler Object and Customising the Display¶
Styling and output display customisation should be performed after the data in a DataFrame has been processed. The Styler is not dynamically updated if further changes to the DataFrame are made. The DataFrame.style attribute is a property that returns a Styler object. It has a _repr_html_ method defined on it so it is rendered automatically in Jupyter Notebook.
The Styler, which can be used for large data but is primarily designed for small data, currently has the ability to output to these formats:
- HTML
- LaTeX
- String (and CSV by extension)
- Excel
- (JSON is not currently available)
The first three of these have display customisation methods designed to format and customise the output. These include:
- Formatting values, the index and columns headers, using .format() and .format_index(),
- Renaming the index or column header labels, using .relabel_index()
- Hiding certain columns, the index and/or column headers, or index names, using .hide()
- Concatenating similar DataFrames, using .concat()
import matplotlib.pyplot
# We have this here to trigger matplotlib's font cache stuff.
# This cell is hidden from the output
Formatting the Display¶
Formatting Values¶
The Styler distinguishes the display value from the actual value, in both data values and index or columns headers. To control the display value, the text is printed in each cell as a string, and we can use the .format() and .format_index() methods to manipulate this according to a format spec string or a callable that takes a single value and returns a string. It is possible to define this for the whole table, or index, or for individual columns, or MultiIndex levels. We can also overwrite index names.
Additionally, the format function has a precision argument to specifically help format floats, as well as decimal and thousands separators to support other locales, an na_rep argument to display missing data, and an escape and hyperlinks arguments to help displaying safe-HTML or safe-LaTeX. The default formatter is configured to adopt pandas' global options such as styler.format.precision option, controllable using with pd.option_context('format.precision', 2):
import pandas as pd
import numpy as np
import matplotlib as mpl
df = pd.DataFrame({
"strings": ["Adam", "Mike"],
"ints": [1, 3],
"floats": [1.123, 1000.23]
})
df.style \
.format(precision=3, thousands=".", decimal=",") \
.format_index(str.upper, axis=1) \
.relabel_index(["row 1", "row 2"], axis=0)
Using Styler to manipulate the display is a useful feature because maintaining the indexing and data values for other purposes gives greater control. You do not have to overwrite your DataFrame to display it how you like. Here is a more comprehensive example of using the formatting functions whilst still relying on the underlying data for indexing and calculations.
weather_df = pd.DataFrame(np.random.rand(10,2)*5,
index=pd.date_range(start="2021-01-01", periods=10),
columns=["Tokyo", "Beijing"])
def rain_condition(v):
if v < 1.75:
return "Dry"
elif v < 2.75:
return "Rain"
return "Heavy Rain"
def make_pretty(styler):
styler.set_caption("Weather Conditions")
styler.format(rain_condition)
styler.format_index(lambda v: v.strftime("%A"))
styler.background_gradient(axis=None, vmin=1, vmax=5, cmap="YlGnBu")
return styler
weather_df
weather_df.loc["2021-01-04":"2021-01-08"].style.pipe(make_pretty)
Hiding Data¶
The index and column headers can be completely hidden, as well subselecting rows or columns that one wishes to exclude. Both these options are performed using the same methods.
The index can be hidden from rendering by calling .hide() without any arguments, which might be useful if your index is integer based. Similarly column headers can be hidden by calling .hide(axis="columns") without any further arguments.
Specific rows or columns can be hidden from rendering by calling the same .hide() method and passing in a row/column label, a list-like or a slice of row/column labels to for the subset argument.
Hiding does not change the integer arrangement of CSS classes, e.g. hiding the first two columns of a DataFrame means the column class indexing will still start at col2, since col0 and col1 are simply ignored.
df = pd.DataFrame(np.random.randn(5, 5))
df.style \
.hide(subset=[0, 2, 4], axis=0) \
.hide(subset=[0, 2, 4], axis=1)
To invert the function to a show functionality it is best practice to compose a list of hidden items.
show = [0, 2, 4]
df.style \
.hide([row for row in df.index if row not in show], axis=0) \
.hide([col for col in df.columns if col not in show], axis=1)
Concatenating DataFrame Outputs¶
Two or more Stylers can be concatenated together provided they share the same columns. This is very useful for showing summary statistics for a DataFrame, and is often used in combination with DataFrame.agg.
Since the objects concatenated are Stylers they can independently be styled as will be shown below and their concatenation preserves those styles.
summary_styler = df.agg(["sum", "mean"]).style \
.format(precision=3) \
.relabel_index(["Sum", "Average"])
df.style.format(precision=1).concat(summary_styler)
Styler Object and HTML¶
The Styler was originally constructed to support the wide array of HTML formatting options. Its HTML output creates an HTML <table> and leverages CSS styling language to manipulate many parameters including colors, fonts, borders, background, etc. See here for more information on styling HTML tables. This allows a lot of flexibility out of the box, and even enables web developers to integrate DataFrames into their exiting user interface designs.
Below we demonstrate the default output, which looks very similar to the standard DataFrame HTML representation. But the HTML here has already attached some CSS classes to each cell, even if we haven't yet created any styles. We can view these by calling the .to_html() method, which returns the raw HTML as string, which is useful for further processing or adding to a file - read on in More about CSS and HTML. This section will also provide a walkthrough for how to convert this default output to represent a DataFrame output that is more communicative. For example how we can build s:
df = pd.DataFrame([[38.0, 2.0, 18.0, 22.0, 21, np.nan],[19, 439, 6, 452, 226,232]],
index=pd.Index(['Tumour (Positive)', 'Non-Tumour (Negative)'], name='Actual Label:'),
columns=pd.MultiIndex.from_product([['Decision Tree', 'Regression', 'Random'],['Tumour', 'Non-Tumour']], names=['Model:', 'Predicted:']))
df.style
# Hidden cell to just create the below example: code is covered throughout the guide.
s = df.style\
.hide([('Random', 'Tumour'), ('Random', 'Non-Tumour')], axis='columns')\
.format('{:.0f}')\
.set_table_styles([{
'selector': '',
'props': 'border-collapse: separate;'
},{
'selector': 'caption',
'props': 'caption-side: bottom; font-size:1.3em;'
},{
'selector': '.index_name',
'props': 'font-style: italic; color: darkgrey; font-weight:normal;'
},{
'selector': 'th:not(.index_name)',
'props': 'background-color: #000066; color: white;'
},{
'selector': 'th.col_heading',
'props': 'text-align: center;'
},{
'selector': 'th.col_heading.level0',
'props': 'font-size: 1.5em;'
},{
'selector': 'th.col2',
'props': 'border-left: 1px solid white;'
},{
'selector': '.col2',
'props': 'border-left: 1px solid #000066;'
},{
'selector': 'td',
'props': 'text-align: center; font-weight:bold;'
},{
'selector': '.true',
'props': 'background-color: #e6ffe6;'
},{
'selector': '.false',
'props': 'background-color: #ffe6e6;'
},{
'selector': '.border-red',
'props': 'border: 2px dashed red;'
},{
'selector': '.border-green',
'props': 'border: 2px dashed green;'
},{
'selector': 'td:hover',
'props': 'background-color: #ffffb3;'
}])\
.set_td_classes(pd.DataFrame([['true border-green', 'false', 'true', 'false border-red', '', ''],
['false', 'true', 'false', 'true', '', '']],
index=df.index, columns=df.columns))\
.set_caption("Confusion matrix for multiple cancer prediction models.")\
.set_tooltips(pd.DataFrame([['This model has a very strong true positive rate', '', '', "This model's total number of false negatives is too high", '', ''],
['', '', '', '', '', '']],
index=df.index, columns=df.columns),
css_class='pd-tt', props=
'visibility: hidden; position: absolute; z-index: 1; border: 1px solid #000066;'
'background-color: white; color: #000066; font-size: 0.8em;'
'transform: translate(0px, -24px); padding: 0.6em; border-radius: 0.5em;')
s
The first step we have taken is the create the Styler object from the DataFrame and then select the range of interest by hiding unwanted columns with .hide().
s = df.style.format('{:.0f}').hide([('Random', 'Tumour'), ('Random', 'Non-Tumour')], axis="columns")
s
# Hidden cell to avoid CSS clashes and latter code upcoding previous formatting
s.set_uuid('after_hide')
Methods to Add Styles¶
There are 3 primary methods of adding custom CSS styles to Styler:
- Using .set_table_styles() to control broader areas of the table with specified internal CSS. Although table styles allow the flexibility to add CSS selectors and properties controlling all individual parts of the table, they are unwieldy for individual cell specifications. Also, note that table styles cannot be exported to Excel.
- Using .set_td_classes() to directly link either external CSS classes to your data cells or link the internal CSS classes created by .set_table_styles(). See here. These cannot be used on column header rows or indexes, and also won't export to Excel.
- Using the .apply() and .map() functions to add direct internal CSS to specific data cells. See here. As of v1.4.0 there are also methods that work directly on column header rows or indexes; .apply_index() and .map_index(). Note that only these methods add styles that will export to Excel. These methods work in a similar way to DataFrame.apply() and DataFrame.map().
Table Styles¶
Table styles are flexible enough to control all individual parts of the table, including column headers and indexes. However, they can be unwieldy to type for individual data cells or for any kind of conditional formatting, so we recommend that table styles are used for broad styling, such as entire rows or columns at a time.
Table styles are also used to control features which can apply to the whole table at once such as creating a generic hover functionality. The :hover pseudo-selector, as well as other pseudo-selectors, can only be used this way.
To replicate the normal format of CSS selectors and properties (attribute value pairs), e.g.
tr:hover {
background-color: #ffff99;
}
the necessary format to pass styles to .set_table_styles() is as a list of dicts, each with a CSS-selector tag and CSS-properties. Properties can either be a list of 2-tuples, or a regular CSS-string, for example:
cell_hover = { # for row hover use <tr> instead of <td>
'selector': 'td:hover',
'props': [('background-color', '#ffffb3')]
}
index_names = {
'selector': '.index_name',
'props': 'font-style: italic; color: darkgrey; font-weight:normal;'
}
headers = {
'selector': 'th:not(.index_name)',
'props': 'background-color: #000066; color: white;'
}
s.set_table_styles([cell_hover, index_names, headers])
# Hidden cell to avoid CSS clashes and latter code upcoding previous formatting
s.set_uuid('after_tab_styles1')
Next we just add a couple more styling artifacts targeting specific parts of the table. Be careful here, since we are chaining methods we need to explicitly instruct the method not to overwrite the existing styles.
s.set_table_styles([
{'selector': 'th.col_heading', 'props': 'text-align: center;'},
{'selector': 'th.col_heading.level0', 'props': 'font-size: 1.5em;'},
{'selector': 'td', 'props': 'text-align: center; font-weight: bold;'},
], overwrite=False)
# Hidden cell to avoid CSS clashes and latter code upcoding previous formatting
s.set_uuid('after_tab_styles2')
As a convenience method (since version 1.2.0) we can also pass a dict to .set_table_styles() which contains row or column keys. Behind the scenes Styler just indexes the keys and adds relevant .col<m> or .row<n> classes as necessary to the given CSS selectors.
s.set_table_styles({
('Regression', 'Tumour'): [{'selector': 'th', 'props': 'border-left: 1px solid white'},
{'selector': 'td', 'props': 'border-left: 1px solid #000066'}]
}, overwrite=False, axis=0)
# Hidden cell to avoid CSS clashes and latter code upcoding previous formatting
s.set_uuid('xyz01')
Setting Classes and Linking to External CSS¶
If you have designed a website then it is likely you will already have an external CSS file that controls the styling of table and cell objects within it. You may want to use these native files rather than duplicate all the CSS in python (and duplicate any maintenance work).
Table Attributes¶
It is very easy to add a class to the main <table> using .set_table_attributes(). This method can also attach inline styles - read more in CSS Hierarchies.
out = s.set_table_attributes('class="my-table-cls"').to_html()
print(out[out.find('<table'):][:109])
Data Cell CSS Classes¶
New in version 1.2.0
The .set_td_classes() method accepts a DataFrame with matching indices and columns to the underlying Styler's DataFrame. That DataFrame will contain strings as css-classes to add to individual data cells: the <td> elements of the <table>. Rather than use external CSS we will create our classes internally and add them to table style. We will save adding the borders until the section on tooltips.
s.set_table_styles([ # create internal CSS classes
{'selector': '.true', 'props': 'background-color: #e6ffe6;'},
{'selector': '.false', 'props': 'background-color: #ffe6e6;'},
], overwrite=False)
cell_color = pd.DataFrame([['true ', 'false ', 'true ', 'false '],
['false ', 'true ', 'false ', 'true ']],
index=df.index,
columns=df.columns[:4])
s.set_td_classes(cell_color)
# Hidden cell to avoid CSS clashes and latter code upcoding previous formatting
s.set_uuid('after_classes')
Styler Functions¶
Acting on Data¶
We use the following methods to pass your style functions. Both of those methods take a function (and some other keyword arguments) and apply it to the DataFrame in a certain way, rendering CSS styles.
- .map() (elementwise): accepts a function that takes a single value and returns a string with the CSS attribute-value pair.
- .apply() (column-/row-/table-wise): accepts a function that takes a Series or DataFrame and returns a Series, DataFrame, or numpy array with an identical shape where each element is a string with a CSS attribute-value pair. This method passes each column or row of your DataFrame one-at-a-time or the entire table at once, depending on the
axiskeyword argument. For columnwise useaxis=0, rowwise useaxis=1, and for the entire table at once useaxis=None.
This method is powerful for applying multiple, complex logic to data cells. We create a new DataFrame to demonstrate this.
np.random.seed(0)
df2 = pd.DataFrame(np.random.randn(10,4), columns=['A','B','C','D'])
df2.style
For example we can build a function that colors text if it is negative, and chain this with a function that partially fades cells of negligible value. Since this looks at each element in turn we use map.
def style_negative(v, props=''):
return props if v < 0 else None
s2 = df2.style.map(style_negative, props='color:red;')\
.map(lambda v: 'opacity: 20%;' if (v < 0.3) and (v > -0.3) else None)
s2
# Hidden cell to avoid CSS clashes and latter code upcoding previous formatting
s2.set_uuid('after_applymap')
We can also build a function that highlights the maximum value across rows, cols, and the DataFrame all at once. In this case we use apply. Below we highlight the maximum in a column.
def highlight_max(s, props=''):
return np.where(s == np.nanmax(s.values), props, '')
s2.apply(highlight_max, props='color:white;background-color:darkblue', axis=0)
# Hidden cell to avoid CSS clashes and latter code upcoding previous formatting
s2.set_uuid('after_apply')
We can use the same function across the different axes, highlighting here the DataFrame maximum in purple, and row maximums in pink.
s2.apply(highlight_max, props='color:white;background-color:pink;', axis=1)\
.apply(highlight_max, props='color:white;background-color:purple', axis=None)
# Hidden cell to avoid CSS clashes and latter code upcoding previous formatting
s2.set_uuid('after_apply_again')
This last example shows how some styles have been overwritten by others. In general the most recent style applied is active but you can read more in the section on CSS hierarchies. You can also apply these styles to more granular parts of the DataFrame - read more in section on subset slicing.
It is possible to replicate some of this functionality using just classes but it can be more cumbersome. See item 3) of Optimization
Debugging Tip: If you're having trouble writing your style function, try just passing it into DataFrame.apply. Internally, Styler.apply uses DataFrame.apply so the result should be the same, and with DataFrame.apply you will be able to inspect the CSS string output of your intended function in each cell.
Acting on the Index and Column Headers¶
Similar application is achieved for headers by using:
- .map_index() (elementwise): accepts a function that takes a single value and returns a string with the CSS attribute-value pair.
- .apply_index() (level-wise): accepts a function that takes a Series and returns a Series, or numpy array with an identical shape where each element is a string with a CSS attribute-value pair. This method passes each level of your Index one-at-a-time. To style the index use
axis=0and to style the column headers useaxis=1.
You can select a level of a MultiIndex but currently no similar subset application is available for these methods.
s2.map_index(lambda v: "color:pink;" if v>4 else "color:darkblue;", axis=0)
s2.apply_index(lambda s: np.where(s.isin(["A", "B"]), "color:pink;", "color:darkblue;"), axis=1)
Tooltips and Captions¶
Table captions can be added with the .set_caption() method. You can use table styles to control the CSS relevant to the caption.
s.set_caption("Confusion matrix for multiple cancer prediction models.")\
.set_table_styles([{
'selector': 'caption',
'props': 'caption-side: bottom; font-size:1.25em;'
}], overwrite=False)
# Hidden cell to avoid CSS clashes and latter code upcoding previous formatting
s.set_uuid('after_caption')
Adding tooltips (since version 1.3.0) can be done using the .set_tooltips() method in the same way you can add CSS classes to data cells by providing a string based DataFrame with intersecting indices and columns. You don't have to specify a css_class name or any css props for the tooltips, since there are standard defaults, but the option is there if you want more visual control.
tt = pd.DataFrame([['This model has a very strong true positive rate',
"This model's total number of false negatives is too high"]],
index=['Tumour (Positive)'], columns=df.columns[[0,3]])
s.set_tooltips(tt, props='visibility: hidden; position: absolute; z-index: 1; border: 1px solid #000066;'
'background-color: white; color: #000066; font-size: 0.8em;'
'transform: translate(0px, -24px); padding: 0.6em; border-radius: 0.5em;')
# Hidden cell to avoid CSS clashes and latter code upcoding previous formatting
s.set_uuid('after_tooltips')
The only thing left to do for our table is to add the highlighting borders to draw the audience attention to the tooltips. We will create internal CSS classes as before using table styles. Setting classes always overwrites so we need to make sure we add the previous classes.
s.set_table_styles([ # create internal CSS classes
{'selector': '.border-red', 'props': 'border: 2px dashed red;'},
{'selector': '.border-green', 'props': 'border: 2px dashed green;'},
], overwrite=False)
cell_border = pd.DataFrame([['border-green ', ' ', ' ', 'border-red '],
[' ', ' ', ' ', ' ']],
index=df.index,
columns=df.columns[:4])
s.set_td_classes(cell_color + cell_border)
# Hidden cell to avoid CSS clashes and latter code upcoding previous formatting
s.set_uuid('after_borders')
Finer Control with Slicing¶
The examples we have shown so far for the Styler.apply and Styler.map functions have not demonstrated the use of the subset argument. This is a useful argument which permits a lot of flexibility: it allows you to apply styles to specific rows or columns, without having to code that logic into your style function.
The value passed to subset behaves similar to slicing a DataFrame;
- A scalar is treated as a column label
- A list (or Series or NumPy array) is treated as multiple column labels
- A tuple is treated as
(row_indexer, column_indexer)
Consider using pd.IndexSlice to construct the tuple for the last one. We will create a MultiIndexed DataFrame to demonstrate the functionality.
df3 = pd.DataFrame(np.random.randn(4,4),
pd.MultiIndex.from_product([['A', 'B'], ['r1', 'r2']]),
columns=['c1','c2','c3','c4'])
df3
We will use subset to highlight the maximum in the third and fourth columns with red text. We will highlight the subset sliced region in yellow.
slice_ = ['c3', 'c4']
df3.style.apply(highlight_max, props='color:red;', axis=0, subset=slice_)\
.set_properties(**{'background-color': '#ffffb3'}, subset=slice_)
If combined with the IndexSlice as suggested then it can index across both dimensions with greater flexibility.
idx = pd.IndexSlice
slice_ = idx[idx[:,'r1'], idx['c2':'c4']]
df3.style.apply(highlight_max, props='color:red;', axis=0, subset=slice_)\
.set_properties(**{'background-color': '#ffffb3'}, subset=slice_)
This also provides the flexibility to sub select rows when used with the axis=1.
slice_ = idx[idx[:,'r2'], :]
df3.style.apply(highlight_max, props='color:red;', axis=1, subset=slice_)\
.set_properties(**{'background-color': '#ffffb3'}, subset=slice_)
There is also scope to provide conditional filtering.
Suppose we want to highlight the maximum across columns 2 and 4 only in the case that the sum of columns 1 and 3 is less than -2.0 (essentially excluding rows (:,'r2')).
slice_ = idx[idx[(df3['c1'] + df3['c3']) < -2.0], ['c2', 'c4']]
df3.style.apply(highlight_max, props='color:red;', axis=1, subset=slice_)\
.set_properties(**{'background-color': '#ffffb3'}, subset=slice_)
Only label-based slicing is supported right now, not positional, and not callables.
If your style function uses a subset or axis keyword argument, consider wrapping your function in a functools.partial, partialing out that keyword.
my_func2 = functools.partial(my_func, subset=42)
Optimization¶
Generally, for smaller tables and most cases, the rendered HTML does not need to be optimized, and we don't really recommend it. There are two cases where it is worth considering:
- If you are rendering and styling a very large HTML table, certain browsers have performance issues.
- If you are using
Stylerto dynamically create part of online user interfaces and want to improve network performance.
Here we recommend the following steps to implement:
1. Remove UUID and cell_ids¶
Ignore the uuid and set cell_ids to False. This will prevent unnecessary HTML.
This is sub-optimal:
df4 = pd.DataFrame([[1,2],[3,4]])
s4 = df4.style
This is better:
from pandas.io.formats.style import Styler
s4 = Styler(df4, uuid_len=0, cell_ids=False)
2. Use table styles¶
Use table styles where possible (e.g. for all cells or rows or columns at a time) since the CSS is nearly always more efficient than other formats.
This is sub-optimal:
props = 'font-family: "Times New Roman", Times, serif; color: #e83e8c; font-size:1.3em;'
df4.style.map(lambda x: props, subset=[1])
This is better:
df4.style.set_table_styles([{'selector': 'td.col1', 'props': props}])
3. Set classes instead of using Styler functions¶
For large DataFrames where the same style is applied to many cells it can be more efficient to declare the styles as classes and then apply those classes to data cells, rather than directly applying styles to cells. It is, however, probably still easier to use the Styler function api when you are not concerned about optimization.
This is sub-optimal:
df2.style.apply(highlight_max, props='color:white;background-color:darkblue;', axis=0)\
.apply(highlight_max, props='color:white;background-color:pink;', axis=1)\
.apply(highlight_max, props='color:white;background-color:purple', axis=None)
This is better:
build = lambda x: pd.DataFrame(x, index=df2.index, columns=df2.columns)
cls1 = build(df2.apply(highlight_max, props='cls-1 ', axis=0))
cls2 = build(df2.apply(highlight_max, props='cls-2 ', axis=1, result_type='expand').values)
cls3 = build(highlight_max(df2, props='cls-3 '))
df2.style.set_table_styles([
{'selector': '.cls-1', 'props': 'color:white;background-color:darkblue;'},
{'selector': '.cls-2', 'props': 'color:white;background-color:pink;'},
{'selector': '.cls-3', 'props': 'color:white;background-color:purple;'}
]).set_td_classes(cls1 + cls2 + cls3)
4. Don't use tooltips¶
Tooltips require cell_ids to work and they generate extra HTML elements for every data cell.
my_css = {
"row_heading": "",
"col_heading": "",
"index_name": "",
"col": "c",
"row": "r",
"col_trim": "",
"row_trim": "",
"level": "l",
"data": "",
"blank": "",
}
html = Styler(df4, uuid_len=0, cell_ids=False)
html.set_table_styles([{'selector': 'td', 'props': props},
{'selector': '.c1', 'props': 'color:green;'},
{'selector': '.l0', 'props': 'color:blue;'}],
css_class_names=my_css)
print(html.to_html())
html
Builtin Styles¶
Some styling functions are common enough that we've "built them in" to the Styler, so you don't have to write them and apply them yourself. The current list of such functions is:
- .highlight_null: for use with identifying missing data.
- .highlight_min and .highlight_max: for use with identifying extremeties in data.
- .highlight_between and .highlight_quantile: for use with identifying classes within data.
- .background_gradient: a flexible method for highlighting cells based on their, or other, values on a numeric scale.
- .text_gradient: similar method for highlighting text based on their, or other, values on a numeric scale.
- .bar: to display mini-charts within cell backgrounds.
The individual documentation on each function often gives more examples of their arguments.
Highlight Null¶
df2.iloc[0,2] = np.nan
df2.iloc[4,3] = np.nan
df2.loc[:4].style.highlight_null(color='yellow')
Highlight Min or Max¶
df2.loc[:4].style.highlight_max(axis=1, props='color:white; font-weight:bold; background-color:darkblue;')
Highlight Between¶
This method accepts ranges as float, or NumPy arrays or Series provided the indexes match.
left = pd.Series([1.0, 0.0, 1.0], index=["A", "B", "D"])
df2.loc[:4].style.highlight_between(left=left, right=1.5, axis=1, props='color:white; background-color:purple;')
Highlight Quantile¶
Useful for detecting the highest or lowest percentile values
df2.loc[:4].style.highlight_quantile(q_left=0.85, axis=None, color='yellow')
Background Gradient and Text Gradient¶
You can create "heatmaps" with the background_gradient and text_gradient methods. These require matplotlib, and we'll use Seaborn to get a nice colormap.
import seaborn as sns
cm = sns.light_palette("green", as_cmap=True)
df2.style.background_gradient(cmap=cm)
df2.style.text_gradient(cmap=cm)
.background_gradient and .text_gradient have a number of keyword arguments to customise the gradients and colors. See the documentation.
Set properties¶
Use Styler.set_properties when the style doesn't actually depend on the values. This is just a simple wrapper for .map where the function returns the same properties for all cells.
df2.loc[:4].style.set_properties(**{'background-color': 'black',
'color': 'lawngreen',
'border-color': 'white'})
Bar charts¶
You can include "bar charts" in your DataFrame.
df2.style.bar(subset=['A', 'B'], color='#d65f5f')
Additional keyword arguments give more control on centering and positioning, and you can pass a list of [color_negative, color_positive] to highlight lower and higher values or a matplotlib colormap.
To showcase an example here's how you can change the above with the new align option, combined with setting vmin and vmax limits, the width of the figure, and underlying css props of cells, leaving space to display the text and the bars. We also use text_gradient to color the text the same as the bars using a matplotlib colormap (although in this case the visualization is probably better without this additional effect).
df2.style.format('{:.3f}', na_rep="")\
.bar(align=0, vmin=-2.5, vmax=2.5, cmap="bwr", height=50,
width=60, props="width: 120px; border-right: 1px solid black;")\
.text_gradient(cmap="bwr", vmin=-2.5, vmax=2.5)
The following example aims to give a highlight of the behavior of the new align options:
# Hide the construction of the display chart from the user
import pandas as pd
from IPython.display import HTML
# Test series
test1 = pd.Series([-100,-60,-30,-20], name='All Negative')
test2 = pd.Series([-10,-5,0,90], name='Both Pos and Neg')
test3 = pd.Series([10,20,50,100], name='All Positive')
test4 = pd.Series([100, 103, 101, 102], name='Large Positive')
head = """
<table>
<thead>
<th>Align</th>
<th>All Negative</th>
<th>Both Neg and Pos</th>
<th>All Positive</th>
<th>Large Positive</th>
</thead>
</tbody>
"""
aligns = ['left', 'right', 'zero', 'mid', 'mean', 99]
for align in aligns:
row = "<tr><th>{}</th>".format(align)
for series in [test1,test2,test3, test4]:
s = series.copy()
s.name=''
row += "<td>{}</td>".format(s.to_frame().style.hide(axis='index').bar(align=align,
color=['#d65f5f', '#5fba7d'],
width=100).to_html()) #testn['width']
row += '</tr>'
head += row
head+= """
</tbody>
</table>"""
HTML(head)
Sharing styles¶
Say you have a lovely style built up for a DataFrame, and now you want to apply the same style to a second DataFrame. Export the style with df1.style.export, and import it on the second DataFrame with df1.style.set
style1 = df2.style\
.map(style_negative, props='color:red;')\
.map(lambda v: 'opacity: 20%;' if (v < 0.3) and (v > -0.3) else None)\
.set_table_styles([{"selector": "th", "props": "color: blue;"}])\
.hide(axis="index")
style1
style2 = df3.style
style2.use(style1.export())
style2
Notice that you're able to share the styles even though they're data aware. The styles are re-evaluated on the new DataFrame they've been used upon.
Limitations¶
- DataFrame only (use
Series.to_frame().style) - The index and columns do not need to be unique, but certain styling functions can only work with unique indexes.
- No large repr, and construction performance isn't great; although we have some HTML optimizations
- You can only apply styles, you can't insert new HTML entities, except via subclassing.
Other Fun and Useful Stuff¶
Here are a few interesting examples.
Widgets¶
Styler interacts pretty well with widgets. If you're viewing this online instead of running the notebook yourself, you're missing out on interactively adjusting the color palette.
from ipywidgets import widgets
@widgets.interact
def f(h_neg=(0, 359, 1), h_pos=(0, 359), s=(0., 99.9), l=(0., 99.9)):
return df2.style.background_gradient(
cmap=sns.palettes.diverging_palette(h_neg=h_neg, h_pos=h_pos, s=s, l=l,
as_cmap=True)
)
Magnify¶
def magnify():
return [dict(selector="th",
props=[("font-size", "4pt")]),
dict(selector="td",
props=[('padding', "0em 0em")]),
dict(selector="th:hover",
props=[("font-size", "12pt")]),
dict(selector="tr:hover td:hover",
props=[('max-width', '200px'),
('font-size', '12pt')])
]
np.random.seed(25)
cmap = cmap=sns.diverging_palette(5, 250, as_cmap=True)
bigdf = pd.DataFrame(np.random.randn(20, 25)).cumsum()
bigdf.style.background_gradient(cmap, axis=1)\
.set_properties(**{'max-width': '80px', 'font-size': '1pt'})\
.set_caption("Hover to magnify")\
.format(precision=2)\
.set_table_styles(magnify())
Sticky Headers¶
If you display a large matrix or DataFrame in a notebook, but you want to always see the column and row headers you can use the .set_sticky method which manipulates the table styles CSS.
bigdf = pd.DataFrame(np.random.randn(16, 100))
bigdf.style.set_sticky(axis="index")
It is also possible to stick MultiIndexes and even only specific levels.
bigdf.index = pd.MultiIndex.from_product([["A","B"],[0,1],[0,1,2,3]])
bigdf.style.set_sticky(axis="index", pixel_size=18, levels=[1,2])
HTML Escaping¶
Suppose you have to display HTML within HTML, that can be a bit of pain when the renderer can't distinguish. You can use the escape formatting option to handle this, and even use it within a formatter that contains HTML itself.
df4 = pd.DataFrame([['<div></div>', '"&other"', '<span></span>']])
df4.style
df4.style.format(escape="html")
df4.style.format('<a href="https://pandas.pydata.org" target="_blank">{}</a>', escape="html")
Export to Excel¶
Some support (since version 0.20.0) is available for exporting styled DataFrames to Excel worksheets using the OpenPyXL or XlsxWriter engines. CSS2.2 properties handled include:
background-colorborder-stylepropertiesborder-widthpropertiesborder-colorpropertiescolorfont-familyfont-stylefont-weighttext-aligntext-decorationvertical-alignwhite-space: nowrapShorthand and side-specific border properties are supported (e.g.
border-styleandborder-left-style) as well as thebordershorthands for all sides (border: 1px solid green) or specified sides (border-left: 1px solid green). Using abordershorthand will override any border properties set before it (See CSS Working Group for more details)Only CSS2 named colors and hex colors of the form
#rgbor#rrggbbare currently supported.The following pseudo CSS properties are also available to set Excel specific style properties:
number-formatborder-style(for Excel-specific styles: "hair", "mediumDashDot", "dashDotDot", "mediumDashDotDot", "dashDot", "slantDashDot", or "mediumDashed")
Table level styles, and data cell CSS-classes are not included in the export to Excel: individual cells must have their properties mapped by the Styler.apply and/or Styler.map methods.
df2.style.\
map(style_negative, props='color:red;').\
highlight_max(axis=0).\
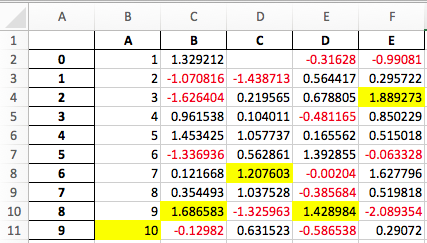
to_excel('styled.xlsx', engine='openpyxl')
A screenshot of the output:
More About CSS and HTML¶
Cascading Style Sheet (CSS) language, which is designed to influence how a browser renders HTML elements, has its own peculiarities. It never reports errors: it just silently ignores them and doesn't render your objects how you intend so can sometimes be frustrating. Here is a very brief primer on how Styler creates HTML and interacts with CSS, with advice on common pitfalls to avoid.
CSS Classes and Ids¶
The precise structure of the CSS class attached to each cell is as follows.
- Cells with Index and Column names include
index_nameandlevel<k>wherekis its level in a MultiIndex - Index label cells include
row_headinglevel<k>wherekis the level in a MultiIndexrow<m>wheremis the numeric position of the row
- Column label cells include
col_headinglevel<k>wherekis the level in a MultiIndexcol<n>wherenis the numeric position of the column
- Data cells include
datarow<m>, wheremis the numeric position of the cell.col<n>, wherenis the numeric position of the cell.
- Blank cells include
blank - Trimmed cells include
col_trimorrow_trim
The structure of the id is T_uuid_level<k>_row<m>_col<n> where level<k> is used only on headings, and headings will only have either row<m> or col<n> whichever is needed. By default we've also prepended each row/column identifier with a UUID unique to each DataFrame so that the style from one doesn't collide with the styling from another within the same notebook or page. You can read more about the use of UUIDs in Optimization.
We can see example of the HTML by calling the .to_html() method.
print(pd.DataFrame([[1,2],[3,4]], index=['i1', 'i2'], columns=['c1', 'c2']).style.to_html())
CSS Hierarchies¶
The examples have shown that when CSS styles overlap, the one that comes last in the HTML render, takes precedence. So the following yield different results:
df4 = pd.DataFrame([['text']])
df4.style.map(lambda x: 'color:green;')\
.map(lambda x: 'color:red;')
df4.style.map(lambda x: 'color:red;')\
.map(lambda x: 'color:green;')
This is only true for CSS rules that are equivalent in hierarchy, or importance. You can read more about CSS specificity here but for our purposes it suffices to summarize the key points:
A CSS importance score for each HTML element is derived by starting at zero and adding:
- 1000 for an inline style attribute
- 100 for each ID
- 10 for each attribute, class or pseudo-class
- 1 for each element name or pseudo-element
Let's use this to describe the action of the following configurations
df4.style.set_uuid('a_')\
.set_table_styles([{'selector': 'td', 'props': 'color:red;'}])\
.map(lambda x: 'color:green;')
This text is red because the generated selector #T_a_ td is worth 101 (ID plus element), whereas #T_a_row0_col0 is only worth 100 (ID), so is considered inferior even though in the HTML it comes after the previous.
df4.style.set_uuid('b_')\
.set_table_styles([{'selector': 'td', 'props': 'color:red;'},
{'selector': '.cls-1', 'props': 'color:blue;'}])\
.map(lambda x: 'color:green;')\
.set_td_classes(pd.DataFrame([['cls-1']]))
In the above case the text is blue because the selector #T_b_ .cls-1 is worth 110 (ID plus class), which takes precedence.
df4.style.set_uuid('c_')\
.set_table_styles([{'selector': 'td', 'props': 'color:red;'},
{'selector': '.cls-1', 'props': 'color:blue;'},
{'selector': 'td.data', 'props': 'color:yellow;'}])\
.map(lambda x: 'color:green;')\
.set_td_classes(pd.DataFrame([['cls-1']]))
Now we have created another table style this time the selector T_c_ td.data (ID plus element plus class) gets bumped up to 111.
If your style fails to be applied, and its really frustrating, try the !important trump card.
df4.style.set_uuid('d_')\
.set_table_styles([{'selector': 'td', 'props': 'color:red;'},
{'selector': '.cls-1', 'props': 'color:blue;'},
{'selector': 'td.data', 'props': 'color:yellow;'}])\
.map(lambda x: 'color:green !important;')\
.set_td_classes(pd.DataFrame([['cls-1']]))
Finally got that green text after all!
Extensibility¶
The core of pandas is, and will remain, its "high-performance, easy-to-use data structures".
With that in mind, we hope that DataFrame.style accomplishes two goals
- Provide an API that is pleasing to use interactively and is "good enough" for many tasks
- Provide the foundations for dedicated libraries to build on
If you build a great library on top of this, let us know and we'll link to it.
Subclassing¶
If the default template doesn't quite suit your needs, you can subclass Styler and extend or override the template. We'll show an example of extending the default template to insert a custom header before each table.
from jinja2 import Environment, ChoiceLoader, FileSystemLoader
from IPython.display import HTML
from pandas.io.formats.style import Styler
We'll use the following template:
with open("templates/myhtml.tpl") as f:
print(f.read())
Now that we've created a template, we need to set up a subclass of Styler that
knows about it.
class MyStyler(Styler):
env = Environment(
loader=ChoiceLoader([
FileSystemLoader("templates"), # contains ours
Styler.loader, # the default
])
)
template_html_table = env.get_template("myhtml.tpl")
Notice that we include the original loader in our environment's loader. That's because we extend the original template, so the Jinja environment needs to be able to find it.
Now we can use that custom styler. It's __init__ takes a DataFrame.
MyStyler(df3)
Our custom template accepts a table_title keyword. We can provide the value in the .to_html method.
HTML(MyStyler(df3).to_html(table_title="Extending Example"))
For convenience, we provide the Styler.from_custom_template method that does the same as the custom subclass.
EasyStyler = Styler.from_custom_template("templates", "myhtml.tpl")
HTML(EasyStyler(df3).to_html(table_title="Another Title"))
Template Structure¶
Here's the template structure for the both the style generation template and the table generation template:
Style template:
with open("templates/html_style_structure.html") as f:
style_structure = f.read()
HTML(style_structure)
Table template:
with open("templates/html_table_structure.html") as f:
table_structure = f.read()
HTML(table_structure)
See the template in the GitHub repo for more details.
# # Hack to get the same style in the notebook as the
# # main site. This is hidden in the docs.
# from IPython.display import HTML
# with open("themes/nature_with_gtoc/static/nature.css_t") as f:
# css = f.read()
# HTML('<style>{}</style>'.format(css))