IAP 2022: Advanced Optimization Session (Session 1)¶
Shuvomoy Das Gupta
Response for the advanced optimization session¶
- Convex programming (32%)
- Integer programming (28%)
- Nonconvex programming (28%)
- Semidefinite programming (5%)
- Other
Based on the responses, I will cover the following topic today.
Topics¶
$\textsf{Session 1: Convex Optimization and Extension}$¶
How to model an optimization problem in a tractable manner
Tractable optimization models
Convex optimization through
Convex.jlandJuMPModeling examples of common convex programs that shows up in OR
What to do when the problem is nonconvex
$\textsf{Session 2: Discrete Optimization: Basic and Advanced}$¶
Mixed Integer Linear Programs (MILP): basic
How MILPs are solved: Branch-and-Bound algorithm
How do we exploit structures to speed up MILPs
Solving Mixed Integer Quadratic Problems
Modeling an optimization problem¶
We have our research problem, that usually come from a practical problem rooted in reality.
While modeling the problem, we want to stay as close to reality as possible, but without making the model intractable.
This is a balance. Safety-critical constraints have to be modeled exactly, where soft constraints can be relaxed.
It is a good practice to be considerate during the modeling phase so we end up with a model that is practically tractable.
Some good resources on how to model optimization problems¶
Model building in mathematical programming by H Williams (Link)
- A very practical book for modeling LP and MILP
Optimization models by G Calafiore and L El Ghaoui (Link)
- Good book for modeling convex optimization problems, especially Chapter 9, 10, 11
Applications of optimization with Xpress-MP by C Guéret, C Prins, and M Sevaux (Link)
- Excellent for modeling integer optimization models, especially Chapter 3, with lot of shortcuts and hacks
Modeling an optimization problems¶
At present the following types of problems are practically tractable. Whenever we are modeling an optmization problem, we should try to ensure that our model is one of the following:
Linear programs (LP)
Quadratic convex programs (QCP)
Second order cone programs (SOCP)
Semidefinite programs (SDP)
Mixed-integer linear programs (MILP)
My modeling strategies¶
- Solve the smaller optimization problem first
Thomson's Rule for First-Time Telescope Makers: "It is faster to make a four-inch mirror then a six-inch mirror than to make a six-inch mirror."
I follow a modified version of Thomson's rule
It is faster to solve a smaller simpler optimization model and then the larger complicated optimization model than to solve a larger complicated optimization model.
- Do not optimize prematurely
"The real problem is that programmers have spent far too much time worrying about efficiency in the wrong places and at the wrong times; premature optimization is the root of all evil (or at least most of it) in programming.”
- Donald Knuth, The Art of Computer Programming
Milestones in optimization¶
1947: G. Dantzig, who works for US air-forces, presents the Simplex method for solving LP-problems
1948: J. Von Neumann establishes the theory of duality for LP-problems
1951: H.W. Kuhn and A.W. Tucker reinvent Karush's optimality conditions (known as KKT conditions)
1951: H. Markowitz presents his portfolio optimization theory => (1990 Nobel prize)
1954: L.R. Ford's and D.R. Fulkerson's research on network problems => start of combinatorial optimization
1960-1970: Many of the early works on first-order optimization algorithms are done (mostly developed in Soviet Union)
1983: Nesterov comes up with accelerated gradient descent
1984: N. Karmarkar's polynomial time algorithm for LP-problems begins a boom period for interior point methods
1990s: Semidefinite optimization theory
2015s: First-order methods become very hot again due to machine learning
General convex optimization problem¶
Most authoritative reference is Convex Optimization by Boyd and Vandenberghe (pdf).
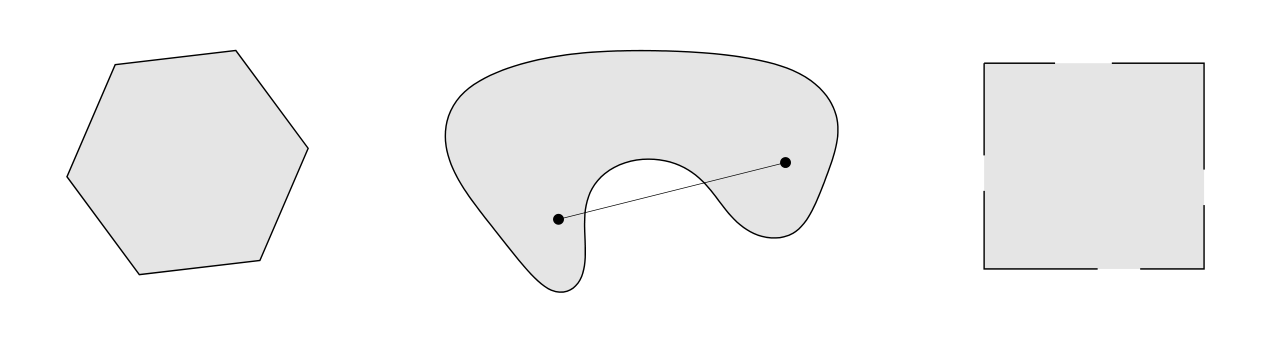
Convex optimization problems are defined through the notion of convex set.
Convex set
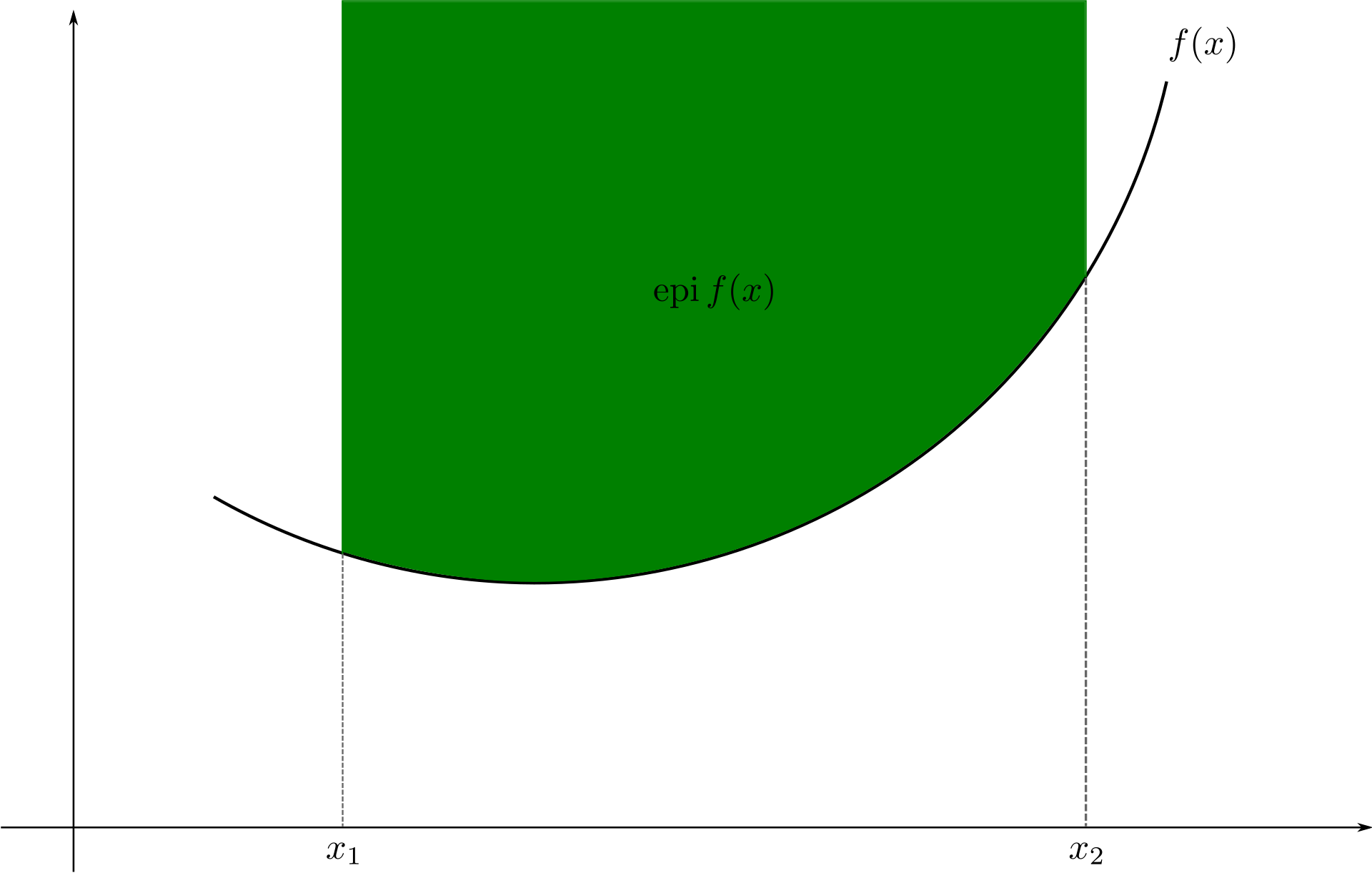
Convex function
A function is convex if and only if the region above its graph is a convex set.
Standard form of a convex optimization problem¶
A general convex optimization problem has the following form: $$ \begin{array}{ll} \underset{x\in\mathbf{R}^{d}}{\mbox{minimize}} & f_{0}(x)\\ \mbox{subject to} & a_{i}^{\top}x=b_{i},\quad i=1,\ldots,p,\\ & f_{i}(x)\leq0,\quad i=1,\ldots,m. \end{array} $$ where the equality constraints are linear and the functions $f_{0},f_{1},\ldots,f_{m}$ are convex.
Convex optimization¶
a subclass of optimization problems that includes LP as special case
convex problems can look very difficult (nonlinear, even
nondifferentiable), but like LP can be solved very efficiently
convex problems come up more often than was once thought
many applications recently discovered in control, combinatorial
optimization, signal processing, communications, circuit design, machine learning, statistics, finance, . . .
General approaches to using convex optimization¶
Pretend/assume/hope $f_i$ are convex (around minimum) and proceed $\Rightarrow \textsf{Machine Learning in Practice}$
- easy on user (problem specifier)
- but lose many benefits of convex optimization
- risky to use in saftey-critical application domain
- an important example
Adam: one of the most heavily used solver for deep learning. (also see Link)
Verify problem is convex (around minimum) before attempting solution $\Rightarrow \textsf{Machine Learning Theory}$
- but verification for general problem description is hard
Model the problem in a way that results in a convex formulation $\Rightarrow \textsf{Operations Research}$
- user needs to follow a restricted set of rules and methods
- convexity verification is automatic
Each has its advantages, but we focus on 3rd approach.
How can you tell if a problem is convex?¶
- Need to check convexity of a function
Approaches:
- use basic definition, first or second order conditions, e.g., $\nabla^2 f(x) \succeq 0$
- via convex calculus: construct $f$ using
- library of basic examples or atoms that are convex
- calculus rules or transformations that preserve convexity
Basic convex functions (convex atoms)¶
$x^{p}$ for $p\geq1$ or $p\leq0$; $-x^{p}$ for $0\leq p\leq1$
$e^{x},$$-\log x$, $x\log x$
$a^{\top}x+b$
$x^{\top}x$; $x^{\top}x/y$ (for $y>0$); $\sqrt{x^{\top}x}$
$\|x\|$ (any norm)
$\max(x_{1},\ldots,x_{n})$
$\log(e^{x_{1}}+\ldots+e^{x_{n}})$
$\log\det X^{-1}$ (for $X\succ0$)
These are also called atoms because they are building block of much more complex convex functions. There are many such atoms, most convex programs in practice can be built from these atoms. A more complete list can be found here.
When modeling a problem, we aim to construct a model in such a way so that the building blocks of the functions are the atoms above.
Convex calculus rules¶
- nonnegative scaling: if $f$ is convex then $\alpha f$ is convex
if $\alpha\geq0$
sum: if $f$ and $g$ are convex, then so is $f+g$
affine composition: if $f$ is convex, then so is $f(Ax+b)$
pointwise maximum: if $f_{1},f_{2},\ldots,f_{m}$ are convex, then
so is $f(x)=\max_{i\in\{1,\ldots,m\}}f_{i}(x)$
pointwise supremum: if $f(x,y)$ is convex in $x$ for all $y \in S$, then $g(x) = \textrm{sup}_{y \in S}{f(x,y)}$ is convex
partial minimization: if $f(x,y)$ is convex in $(x,y)$ and $C$
is convex, then $g(x)=\min_{y\in C}f(x,y)$ is convex
- composition: if $h$ is convex and increasing and $f$ is convex,
then $g(x)=h(f(x))$ is convex
The function that may show up in your model can be much more complicated¶
Many complicated convex functions that we can use in the modeling phase can build from the atoms through convex calculus.
piecewise-linear function: $f(x)=\max_{i=1,\ldots,k}(a_{i}^{\top}x+b_{i})$
$\ell_{1}$-regularized least-squares cost: $\|Ax-b\|_{2}^{2}+\lambda\|x\|_{1}$
with $\lambda\geq0$
support-function of a set: $S_C(x)= \max_{y \in C}{x^\top y}$ where $C$ is any set
distance to convex set: $f(x)=\min_{y\in C}\|x-y\|_{2}$
Basic modeling steps¶
When modeling a problem we face many choices how to mathematically model a certain reality
During the modeling phase try to select your functions with their building blocks as convex atoms
When modeling some operation on a mathematical object try to use convex calculus rules
If you can follow the last two steps, you will have a convex problem
If you have a nonconvex problem (that is not mixed integer linear program), you can try one of the two things:
- Work with tightest convex approximation of the nonconvex problem (will see one example)
- Sequential convex programming, a local optimization method for nonconvex problems that leverages convex optimization (works suprisingly well in my experience)
Linear programs¶
$$ \begin{array}{ll} \underset{x\in\mathbf{R}^{d}}{\mbox{minimize}} & c^{\top}x\\ \mbox{subject to} & Ax=b,\\ & Cx\geq d. \end{array} $$Shows up when we are modeling system that can be completely described by linear equalities and inequalities.
Quadratic convex programs (QCP)¶
$$ \begin{array}{ll} \underset{x\in\mathbf{E}}{\mbox{minimize}} & c^{\top}x+x^{\top}\underbrace{Q_{0}}_{\succeq0}x\\ \mbox{subject to} & Ax=b,\\ & x^{\top}\underbrace{Q_{i}}_{\succeq0}x+q_{i}^{\top}x+r_{i}\leq0,\quad i=1,\ldots,p. \end{array} $$Where does it show up?¶
QCP mostly show up in data fitting problems such as least-squares and its variants.
Second order cone programs (SOCP)¶
$$ \begin{array}{ll} \underset{x\in\mathbf{R}^{d}}{\mbox{minimize}} & c^{\top}x\\ \mbox{subject to} & \|A_{i}x+b_{i}\|_{2}\leq q_{i}^{\top}x+d_{i},\quad i=1,\ldots,p,\\ & Cx\leq f. \end{array} $$- SOCP is a generalization of LP and QCP
- Allows for linear combinations of variables to be constrained inside a special convex set, called a second-order cone
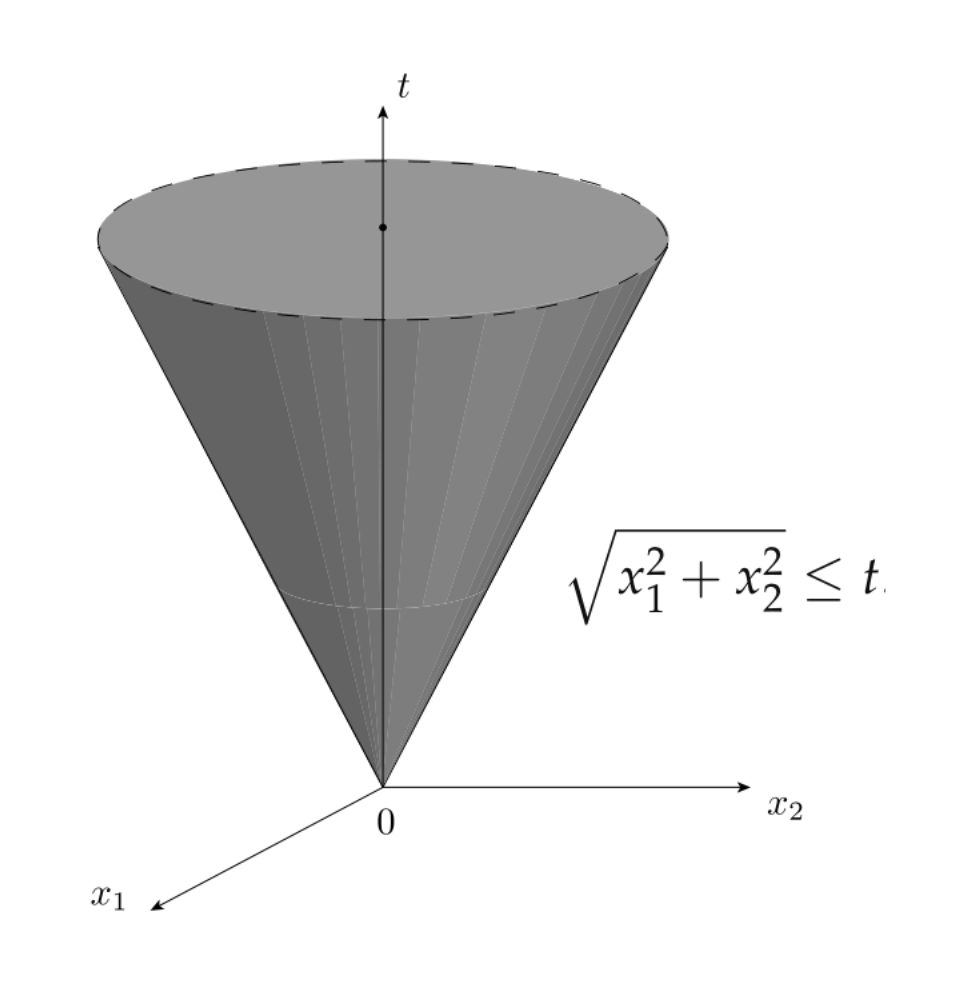
- Shows up in: geometry problems, approximation problems, chance-constrained linear optimization problems
Semidefinite programs (SDP)¶
Recall that LP in standard form is: $$ \begin{array}{ll} \underset{x\in\mathbf{R}^{d}}{\mbox{minimize}} & c^{\top}x\\ \mbox{subject to} & a_{i}^{\top}x=b_{i},\quad i=1,\ldots,m,\\ & x\succeq0. \end{array} $$ An SDP is a generalization of LPs. Standard form of an SDP is: $$ \begin{array}{ll} \underset{X\in\mathbf{R}^{d\times d}}{\mbox{minimize}} & \mathbf{tr}(CX)\\ \mbox{subject to} & \mathbf{tr}(A_{i}X)=b_{i},\quad i=1,\ldots,m,\\ & X\succeq0. \end{array} $$
- Among all convex models, SDP is the most useful in my opinion.
- Shows up in:
- sophisticated relaxations (approximations) of non-convex problems,
- in control design for linear dynamical systems,
- in system identification,
- in algebraic geometry, and
- in matrix completion problems.
Mixed-integer linear programs (MILP) (Session 2)¶
$$ \begin{array}{ll} \underset{x,y}{\mbox{minimize}} & c^{\top}x+d^{\top}y\\ \mbox{subject to} & Ax+By=b,\\ & Cx+Dy\geq f,\\ & x\succeq0,\\ & x\in\mathbf{R}^{d},\\ & y\in \mathbf{Z}^{n}. \end{array} $$- Nonconvex, but "practically tractable" in many situations
- MILP solvers have gained a speed-up factor of 2 trillion in the last 40 years!
- Wide modeling capability
- Usually shows up in situations where
- modeling do/don't do decisions
- logical conditions
- implications (if something happens do this)
- either/or
Modeling and solving common convex models in Julia¶
Example of QCP: portfolio optimization¶
Assume that we have a portfolio with $n$ assets at the beginning of time period $t$.
Given some forecasts on risks and expected returns we try to find the optimal portfolio that rebalances the portfolio to achieve a good balance between expected risk (variance) $x^\top \Sigma x$ and returns $\mu^\top x$.
In it's simplest form we want to solve: $$ \begin{array}{ll} \text{minimize} & \gamma (x^\top \Sigma x) -\mu^\top x \\ \text{subject to} & 1^\top x = d + 1^\top x^0 \\ & x \geq 0, \end{array} $$ with variable $x \in \mathbf{R}^n$, $\mu$ forecasted (expected) returns, $\gamma > 0 $ risk aversion parameter.
- $x^0_i$ represents the initial investment in asset $i$ and $d$ represents the cash reserve.
- The equality constraint tells us that the sum of the new allocation vector $x$ has to equal the initial allocation plus the cash reserve
- the covariance matrix of our risk model is given by $\Sigma \in \mathbf{S}_+^n$.
# Load the packages
using MosekTools, Mosek, Random, Convex, JuMP, Suppressor, Images, DelimitedFiles
# using COSMO, Random, Convex, JuMP, Suppressor, Images, DelimitedFiles
# Load the data
include("img//portfolio_data.jl");
Solving the problem using Convex.jl¶
To solve this problem, we will use Convex.jl, which is a specialized Julia package for solving convex optimization problem.
Declare the variable $x$.
x = Variable(n)
Variable size: (50, 1) sign: real vexity: affine id: 163…310
Let us now the define the objective $ \gamma (x^\top \Sigma x) -\mu^\top x $.
objective = γ*quadform(x,Σ) - dot(x,μ)
+ (convex; real)
├─ * (convex; positive)
│ ├─ 1.0
│ └─ * (convex; positive)
│ ├─ 1
│ └─ qol_elem (convex; positive)
│ ├─ …
│ └─ …
└─ - (affine; real)
└─ sum (affine; real)
└─ .* (affine; real)
├─ …
└─ …
Note, the list of all the functions Convex.jl can model directly is available at https://jump.dev/Convex.jl/stable/operations/#Linear-Program-Representable-Functions.
Add the constraint $1^\top x = d + 1^\top x^0$.
constraint_linear = ( sum(x) == d + sum(x0) )
== constraint (affine) ├─ sum (affine; real) │ └─ 50-element real variable (id: 163…310) └─ 1
Now add the positivity constraint.
constraint_pos = ( x >= 0 )
>= constraint (affine) ├─ 50-element real variable (id: 163…310) └─ 0
Next, combine everything in a problem.
problem = minimize(objective, [constraint_linear, constraint_pos])
minimize
└─ + (convex; real)
├─ * (convex; positive)
│ ├─ 1.0
│ └─ * (convex; positive)
│ ├─ …
│ └─ …
└─ - (affine; real)
└─ sum (affine; real)
└─ …
subject to
├─ == constraint (affine)
│ ├─ sum (affine; real)
│ │ └─ 50-element real variable (id: 163…310)
│ └─ 1
└─ >= constraint (affine)
├─ 50-element real variable (id: 163…310)
└─ 0
status: `solve!` not called yet
Now time to solve the problem!
solve!(problem, Mosek.Optimizer)
Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 107 Cones : 2 Scalar variables : 107 Matrix variables : 0 Integer variables : 0 Optimizer started. Presolve started. Linear dependency checker started. Linear dependency checker terminated. Eliminator started. Freed constraints in eliminator : 0 Eliminator terminated. Eliminator - tries : 1 time : 0.00 Lin. dep. - tries : 1 time : 0.00 Lin. dep. - number : 0 Presolve terminated. Time: 0.00 Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 107 Cones : 2 Scalar variables : 107 Matrix variables : 0 Integer variables : 0 Optimizer - threads : 48 Optimizer - solved problem : the primal Optimizer - Constraints : 53 Optimizer - Cones : 2 Optimizer - Scalar variables : 104 conic : 54 Optimizer - Semi-definite variables: 0 scalarized : 0 Factor - setup time : 0.00 dense det. time : 0.00 Factor - ML order time : 0.00 GP order time : 0.00 Factor - nonzeros before factor : 1379 after factor : 1380 Factor - dense dim. : 0 flops : 1.84e+05 ITE PFEAS DFEAS GFEAS PRSTATUS POBJ DOBJ MU TIME 0 1.0e+00 1.0e+00 2.0e+00 0.00e+00 0.000000000e+00 -1.000000000e+00 1.0e+00 0.00 1 2.9e-01 2.9e-01 1.3e-01 9.55e-01 -1.052337346e-01 -3.529023776e-01 2.9e-01 0.00 2 7.0e-02 7.0e-02 1.9e-02 3.28e+00 -3.462222178e-02 -4.832572741e-02 7.0e-02 0.00 3 1.3e-02 1.3e-02 1.3e-03 7.22e-01 2.043785564e-02 1.598816495e-02 1.3e-02 0.00 4 8.7e-04 8.7e-04 1.4e-05 9.90e-01 3.921134167e-02 3.878335008e-02 8.7e-04 0.00 5 1.4e-04 1.4e-04 9.0e-07 1.02e+00 4.058692192e-02 4.052022577e-02 1.4e-04 0.00 6 1.3e-07 1.3e-07 1.5e-11 1.00e+00 4.085428624e-02 4.085421395e-02 1.3e-07 0.00 7 1.3e-10 1.1e-10 1.4e-16 1.00e+00 4.085438091e-02 4.085438088e-02 7.2e-11 0.00 Optimizer terminated. Time: 0.00
Get the solution now.
x_sol = Convex.evaluate(x)
50-element Vector{Float64}:
0.027228140397089203
0.03226496898357304
0.040521154749669115
5.045416303584319e-12
0.021044660297784817
-1.904956297667087e-11
0.050557306144882554
0.05394663344893841
-1.408664747030976e-11
0.04398393358377368
0.019242404142878675
0.03770907944017934
0.03056528224454937
⋮
0.02068750776254753
0.06466324439231913
0.02198422135523888
0.004512499567966097
-1.9802434781250454e-11
0.024926436958510417
0.0301004341433809
0.01383265358539451
5.481331048553427e-11
0.02848213497329782
0.043080956668940386
-1.835093072354754e-11
Get the optimal value.
p_star = Convex.evaluate(objective)
0.040854380927766734
So, combining everything together, the code to solve the portfolio optimization problem using Convex.jl would be:
## Define the problem
x = Variable(n);
objective = γ*quadform(x,Σ) - dot(x,μ);
constraint_linear = ( sum(x) == d + sum(x0) );
constraint_pos = ( x >= 0 );
problem = minimize(objective, [constraint_linear, constraint_pos]);
## Solve the problem
solve!(problem, Mosek.Optimizer);
## Extract the solution
x_sol = Convex.evaluate(x);
p_star = Convex.evaluate(objective);
Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 107 Cones : 2 Scalar variables : 107 Matrix variables : 0 Integer variables : 0 Optimizer started. Presolve started. Linear dependency checker started. Linear dependency checker terminated. Eliminator started. Freed constraints in eliminator : 0 Eliminator terminated. Eliminator - tries : 1 time : 0.00 Lin. dep. - tries : 1 time : 0.00 Lin. dep. - number : 0 Presolve terminated. Time: 0.00 Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 107 Cones : 2 Scalar variables : 107 Matrix variables : 0 Integer variables : 0 Optimizer - threads : 48 Optimizer - solved problem : the primal Optimizer - Constraints : 53 Optimizer - Cones : 2 Optimizer - Scalar variables : 104 conic : 54 Optimizer - Semi-definite variables: 0 scalarized : 0 Factor - setup time : 0.00 dense det. time : 0.00 Factor - ML order time : 0.00 GP order time : 0.00 Factor - nonzeros before factor : 1379 after factor : 1380 Factor - dense dim. : 0 flops : 1.84e+05 ITE PFEAS DFEAS GFEAS PRSTATUS POBJ DOBJ MU TIME 0 1.0e+00 1.0e+00 2.0e+00 0.00e+00 0.000000000e+00 -1.000000000e+00 1.0e+00 0.00 1 2.9e-01 2.9e-01 1.3e-01 9.55e-01 -1.052337346e-01 -3.529023776e-01 2.9e-01 0.00 2 7.0e-02 7.0e-02 1.9e-02 3.28e+00 -3.462222178e-02 -4.832572741e-02 7.0e-02 0.00 3 1.3e-02 1.3e-02 1.3e-03 7.22e-01 2.043785564e-02 1.598816495e-02 1.3e-02 0.00 4 8.7e-04 8.7e-04 1.4e-05 9.90e-01 3.921134167e-02 3.878335008e-02 8.7e-04 0.00 5 1.4e-04 1.4e-04 9.0e-07 1.02e+00 4.058692192e-02 4.052022577e-02 1.4e-04 0.00 6 1.3e-07 1.3e-07 1.5e-11 1.00e+00 4.085428624e-02 4.085421395e-02 1.3e-07 0.00 7 1.3e-10 1.1e-10 1.4e-16 1.00e+00 4.085438091e-02 4.085438088e-02 7.2e-11 0.01 Optimizer terminated. Time: 0.01
Solving the problem using JuMP¶
There is nothing special solving a problem via Convex.jl over JuMP. We could solve the same problem using JuMP with the following code.
## Define the problem
using JuMP
model = Model(Mosek.Optimizer)
@variable(model, xs[1:n] >= 0)
@objective(model, Min, γ * xs'*Σ*xs - μ' * xs);
@constraint(model, sum(xs) .== d + sum(x0))
## Solve the problem
optimize!(model)
## Get the optimal solution
x_sol_JuMP = value.(xs)
p_star_JuMP = objective_value(model)
Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 53 Cones : 1 Scalar variables : 103 Matrix variables : 0 Integer variables : 0 Optimizer started. Presolve started. Linear dependency checker started. Linear dependency checker terminated. Eliminator started. Freed constraints in eliminator : 0 Eliminator terminated. Eliminator - tries : 1 time : 0.00 Lin. dep. - tries : 1 time : 0.00 Lin. dep. - number : 0 Presolve terminated. Time: 0.00 Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 53 Cones : 1 Scalar variables : 103 Matrix variables : 0 Integer variables : 0 Optimizer - threads : 48 Optimizer - solved problem : the primal Optimizer - Constraints : 50 Optimizer - Cones : 1 Optimizer - Scalar variables : 101 conic : 52 Optimizer - Semi-definite variables: 0 scalarized : 0 Factor - setup time : 0.00 dense det. time : 0.00 Factor - ML order time : 0.00 GP order time : 0.00 Factor - nonzeros before factor : 1275 after factor : 1275 Factor - dense dim. : 0 flops : 9.49e+04 ITE PFEAS DFEAS GFEAS PRSTATUS POBJ DOBJ MU TIME 0 1.0e+00 2.9e-01 2.4e+00 0.00e+00 7.071067812e-01 -7.071067812e-01 1.0e+00 0.00 1 2.9e-01 8.6e-02 1.5e-01 1.20e+00 -2.906081789e-02 -4.249358754e-01 2.9e-01 0.00 2 1.4e-01 4.0e-02 5.5e-02 4.49e+00 -2.640651336e-02 -6.905590568e-02 1.4e-01 0.00 3 3.0e-02 8.9e-03 5.9e-03 8.51e-01 7.377461763e-03 -4.116575695e-03 3.0e-02 0.00 4 4.7e-03 1.4e-03 2.2e-04 8.52e-01 3.494661566e-02 3.234045354e-02 4.7e-03 0.00 5 4.3e-04 1.3e-04 5.5e-06 1.03e+00 4.026643434e-02 4.002824506e-02 4.3e-04 0.00 6 5.1e-05 1.5e-05 2.3e-07 1.01e+00 4.077948136e-02 4.075136364e-02 5.1e-05 0.00 7 9.0e-10 2.1e-10 1.4e-14 1.00e+00 4.085438030e-02 4.085437979e-02 9.0e-10 0.00 Optimizer terminated. Time: 0.00
0.040854380289201415
Because we used the same solver, we hope to get the same optimal solution.
norm(x_sol - x_sol_JuMP)
2.184720444565889e-8
When to use JuMP vs Convex.jl?¶
- Usually
JuMP's model creation time is somewhat faster thanConvex.jl, so if you are working on a problem, where performance is key, then usingJuMPis a good idea. - If you are in the prototyping phase of your model and you feel that you are working with a lot of convex-ish functions, then working with
Convex.jlmight be a good idea.- For example, suppose, in the last problem you are interested in finding a sparse portfolio with the risk being less than some bound. Within convex optimization framework, one way doing this is by minimizing the $\ell_1$ norm of $x$, i.e., consider the modified objective $\mu^\top x + \gamma \| x\|_1$ and the additional constraint $x^\top \Sigma x \leq \delta$. If we want to do this modification via
JuMP, then the right approach is reformulate the $\ell_1$ norm via epigraph etc, butConvex.jlwill take this term as it is.
- For example, suppose, in the last problem you are interested in finding a sparse portfolio with the risk being less than some bound. Within convex optimization framework, one way doing this is by minimizing the $\ell_1$ norm of $x$, i.e., consider the modified objective $\mu^\top x + \gamma \| x\|_1$ and the additional constraint $x^\top \Sigma x \leq \delta$. If we want to do this modification via
$\|x\|_1$ = norm(x,1)
$x^\top \Sigma x$ = quadform(x_sparse,Σ)
## Define the problem (student)
δ = 0.5
x_sparse = Variable(n)
objective_sparse = - dot(x_sparse,μ) + γ*norm(x_sparse,1)
constraint_linear = ( sum(x_sparse) == d + sum(x0) )
constraint_pos = ( x_sparse >= 0 )
constraint_additional = ( quadform(x_sparse,Σ) <= δ)
problem_sparse = minimize(objective_sparse, [constraint_linear, constraint_pos, constraint_additional])
## Solve the problem
solve!(problem_sparse, Mosek.Optimizer)
## Extract the solution
x_sol_sparse = Convex.evaluate(x_sparse)
p_star_sparse = Convex.evaluate(objective_sparse)
Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 208 Cones : 2 Scalar variables : 157 Matrix variables : 0 Integer variables : 0 Optimizer started. Presolve started. Linear dependency checker started. Linear dependency checker terminated. Eliminator started. Freed constraints in eliminator : 100 Eliminator terminated. Eliminator started. Freed constraints in eliminator : 0 Eliminator terminated. Eliminator - tries : 2 time : 0.00 Lin. dep. - tries : 1 time : 0.00 Lin. dep. - number : 0 Presolve terminated. Time: 0.00 Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 208 Cones : 2 Scalar variables : 157 Matrix variables : 0 Integer variables : 0 Optimizer - threads : 48 Optimizer - solved problem : the primal Optimizer - Constraints : 53 Optimizer - Cones : 2 Optimizer - Scalar variables : 104 conic : 54 Optimizer - Semi-definite variables: 0 scalarized : 0 Factor - setup time : 0.00 dense det. time : 0.00 Factor - ML order time : 0.00 GP order time : 0.00 Factor - nonzeros before factor : 1379 after factor : 1380 Factor - dense dim. : 0 flops : 1.84e+05 ITE PFEAS DFEAS GFEAS PRSTATUS POBJ DOBJ MU TIME 0 1.0e+00 1.0e+00 1.0e+00 0.00e+00 0.000000000e+00 0.000000000e+00 1.0e+00 0.00 1 3.2e-01 3.2e-01 7.7e-02 1.05e+00 7.366400887e-01 5.964125089e-01 3.2e-01 0.00 2 1.5e-01 1.5e-01 1.2e-02 2.97e+00 8.880375655e-01 8.573569888e-01 1.5e-01 0.00 3 6.2e-02 6.2e-02 3.0e-03 2.76e+00 9.122172687e-01 9.063434088e-01 6.2e-02 0.00 4 2.8e-02 2.8e-02 9.3e-04 1.29e+00 9.079463544e-01 9.054055890e-01 2.8e-02 0.00 5 6.1e-03 6.1e-03 8.9e-05 1.14e+00 9.062916966e-01 9.057747609e-01 6.1e-03 0.00 6 6.9e-04 6.9e-04 3.3e-06 1.05e+00 9.059876688e-01 9.059299167e-01 6.9e-04 0.01 7 5.5e-05 5.5e-05 7.0e-08 1.01e+00 9.059030996e-01 9.058983290e-01 5.5e-05 0.01 8 1.7e-06 1.7e-06 3.3e-10 1.00e+00 9.058978757e-01 9.058977217e-01 1.7e-06 0.01 9 7.2e-08 7.2e-08 2.8e-12 1.00e+00 9.058977525e-01 9.058977456e-01 7.2e-08 0.01 Optimizer terminated. Time: 0.01
0.9058977602024589
using Plots, Suppressor
gaston()
# inspectdr()
plot([1:n],[x_sol_JuMP x_sol_sparse], xlabel = "k", ylabel = "x[k]", label = [ "x original" "x sparse"])
┌ Warning: Gnuplot returned an error message: │ │ gnuplot> set term svg size 600,400 font 'sans-serif,16' background rgb '#00ffffff' fontscale 1.0 lw 1.0 dl 1.0 ps 1.0 │ ^ │ line 0: unrecognized terminal option │ └ @ Gaston /home/gridsan/sdgupta/.julia/packages/Gaston/ctAQy/src/gaston_llplot.jl:182
Example of SOCP: time series analysis¶
A time series is a sequence of data points, each associated with a time. In our example, we will work with a time series of daily temperatures in the city of Melbourne, Australia over a period of a few years. Let $\tau$ be the vector of the time series, and $\tau_i$ denote the temperature in Melbourne on day $i$. Here is a picture of the time series:
using DelimitedFiles
τ = readdlm("img//melbourne_temps.txt", ',')
n = size(τ, 1)
plot(1:n, τ[1:n], ylabel="Temperature (°C)", label="data", xlabel = "Time (days)", xticks=0:365:n)
┌ Warning: Gnuplot returned an error message: │ │ gnuplot> set term svg size 600,400 font 'sans-serif,16' background rgb '#00ffffff' fontscale 1.0 lw 1.0 dl 1.0 ps 1.0 │ ^ │ line 0: unrecognized terminal option │ └ @ Gaston /home/gridsan/sdgupta/.julia/packages/Gaston/ctAQy/src/gaston_llplot.jl:182
A simple way to model this time series would be to find a smooth curve that approximates the yearly ups and downs. We can represent this model as a vector $x$ where $x_i$ denotes the predicted temperature on the $i$-th day. To force this trend to repeat yearly, we simply want to impose the constraint
$$ x_i = x_{i + 365} $$for each applicable $i$.
We also want our model to have two more properties:
- The first is that the temperature on each day in our model should be relatively close to the actual temperature of that day and equal if possible.
- The second is that our model needs to be smooth, so the change in temperature from day to day should be relatively small. The following objective would capture both properties:
where $A$ is a matrix of size $(n-1)\times n$ with $A_{i,i}=-1,A_{i,i+1}=1$ for $i=1,\ldots,n-1$ and the rest of the elements being zero. So, the optimization problem we want to solve is:
$$ \begin{array}{ll} \underset{x\in\mathbf{R}^{d}}{\mbox{minimize}} & \|x-\tau\|_{1}+\lambda\|Ax\|_{2}\\ \mbox{subject to} & x_{i}=x_{i+365},\quad i=1,\ldots,n. \end{array} $$This is an SOCP, because it can be written as: $$ \begin{array}{ll} \underset{x,u,t}{\mbox{minimize}} & \sum_{i=1}^{n}u_{i}+\lambda t\\ \mbox{subject to} & x_{i}=x_{i+365},\quad i=1,\ldots,n, \\ & \|Ax\|_{2}\leq t,\\ & \vert x_{i}-\tau_{i}\vert\leq u_{i},\quad i=1,\ldots,n. \end{array} $$
Here, $\lambda$ is the smoothing parameter. The larger $\lambda$ is, the smoother our model will be.
We will solve this problem using Convex.jl, because it would allow us to input the problem directly without manually converting into the SOCP format.
## Solution using Convex.jl
x = Variable(n)
Variable size: (3648, 1) sign: real vexity: affine id: 121…269
eq_constraints = [ x[i] == x[i - 365] for i in 365 + 1 : n ];
λ = 100 # smoothing parameter
# Define the matrix A
A = zeros(n-1,n)
for i in 1:n-1
A[i,i] = -1
A[i,i+1] = 1
end
smooth_objective = norm(x-τ,1) + λ*norm(A*x,2)
+ (convex; positive)
├─ sum (convex; positive)
│ └─ abs (convex; positive)
│ └─ + (affine; real)
│ ├─ …
│ └─ …
└─ * (convex; positive)
├─ 100
└─ norm2 (convex; positive)
└─ * (affine; real)
├─ …
└─ …
smooth_problem = minimize(smooth_objective, eq_constraints);
solve!(smooth_problem, Mosek.Optimizer)
Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 14228 Cones : 1 Scalar variables : 10946 Matrix variables : 0 Integer variables : 0 Optimizer started. Presolve started. Linear dependency checker started. Linear dependency checker terminated. Eliminator started. Freed constraints in eliminator : 6931 Eliminator terminated. Eliminator started. Freed constraints in eliminator : 0 Eliminator terminated. Eliminator - tries : 2 time : 0.00 Lin. dep. - tries : 1 time : 0.00 Lin. dep. - number : 0 Presolve terminated. Time: 0.02 Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 14228 Cones : 1 Scalar variables : 10946 Matrix variables : 0 Integer variables : 0 Optimizer - threads : 48 Optimizer - solved problem : the dual Optimizer - Constraints : 365 Optimizer - Cones : 1 Optimizer - Scalar variables : 7129 conic : 3648 Optimizer - Semi-definite variables: 0 scalarized : 0 Factor - setup time : 0.00 dense det. time : 0.00 Factor - ML order time : 0.00 GP order time : 0.00 Factor - nonzeros before factor : 1095 after factor : 1458 Factor - dense dim. : 1 flops : 2.15e+04 ITE PFEAS DFEAS GFEAS PRSTATUS POBJ DOBJ MU TIME 0 1.1e+02 9.9e+01 1.0e+02 0.00e+00 1.560800000e+03 1.460800000e+03 1.0e+00 0.03 1 6.2e+01 5.9e+01 7.7e+01 -9.82e-01 2.730199769e+03 2.632087909e+03 5.9e-01 0.03 2 2.5e+01 2.3e+01 4.5e+01 -9.26e-01 6.736436307e+03 6.649247616e+03 2.3e-01 0.03 3 1.9e+01 1.8e+01 3.5e+01 -5.31e-01 7.737208735e+03 7.659354991e+03 1.8e-01 0.03 4 7.6e+00 7.1e+00 1.0e+01 -2.09e-01 1.012319530e+04 1.008440511e+04 7.2e-02 0.04 5 5.0e+00 4.7e+00 4.9e+00 9.67e-01 9.213769945e+03 9.189816268e+03 4.7e-02 0.04 6 1.6e+00 1.5e+00 7.9e-01 1.07e+00 8.455635415e+03 8.448656902e+03 1.5e-02 0.04 7 3.5e-01 3.3e-01 8.1e-02 1.05e+00 8.217712464e+03 8.216216265e+03 3.3e-03 0.04 8 8.6e-02 8.1e-02 1.0e-02 1.01e+00 8.174719566e+03 8.174348780e+03 8.2e-04 0.04 9 2.8e-02 2.7e-02 1.9e-03 1.00e+00 8.164215640e+03 8.164093597e+03 2.7e-04 0.04 10 6.5e-03 6.2e-03 2.2e-04 1.00e+00 8.159975775e+03 8.159947703e+03 6.2e-05 0.04 11 1.3e-03 1.2e-03 2.0e-05 1.00e+00 8.158895032e+03 8.158889346e+03 1.3e-05 0.05 12 1.6e-04 1.5e-04 8.4e-07 1.00e+00 8.158651808e+03 8.158651115e+03 1.5e-06 0.05 13 8.5e-06 8.0e-06 1.0e-08 1.00e+00 8.158619699e+03 8.158619662e+03 8.1e-08 0.05 14 7.6e-07 7.1e-07 2.7e-10 1.00e+00 8.158618093e+03 8.158618090e+03 7.2e-09 0.05 15 6.4e-08 6.1e-08 6.6e-12 1.00e+00 8.158617948e+03 8.158617948e+03 6.1e-10 0.05 Optimizer terminated. Time: 0.06
Let's plot our smoothed time estimate vs the original data.
# Plot smooth fit
plot(1:n, τ[1:n], label="data")
plot!(1:n, Convex.evaluate(x)[1:n], linewidth=2, label="smooth fit", ylabel="Temperature (°C)", xticks=0:365:n, xlabel="Time (days)")
┌ Warning: Gnuplot returned an error message: │ │ gnuplot> set term svg size 600,400 font 'sans-serif,16' background rgb '#00ffffff' fontscale 1.0 lw 1.0 dl 1.0 ps 1.0 │ ^ │ line 0: unrecognized terminal option │ └ @ Gaston /home/gridsan/sdgupta/.julia/packages/Gaston/ctAQy/src/gaston_llplot.jl:182
Matrix completion problem: how to reconstruct a distorted image¶
Suppose we are given a noisy image, and we want to clean the image up. In countless movies and tv shows, we have seen our hero figuring out who the killer is by polishing a very noisy image in seconds. In reality, this takes a while, and usually is done by solving an SDP.
Let's take a look at an example. Suppose we are given this very noisy image. This image is the noisy version of a test image widely used in the field of image processing since 1973. See the wikipedia entry here for more information.
using Images
lenna = load("img//lena128missing.png")

A noisy image is basically a matrix, where lot of the pixels are not reliable. In a way, these unreliable pixels can be treated as missing entries of a matrix, because any $n\times n$ image is nothing but a $n \times n$ matrix.
First, we convert the $128\times128$ image into a matrix. Here, through some precalculation, I have already filled in the missing entries with zero (for the sake of illustration).
# convert to real matrices
Y = Float64.(lenna)
128×128 Matrix{Float64}:
0.0 0.0 0.635294 0.0 … 0.0 0.0 0.627451
0.627451 0.623529 0.0 0.611765 0.0 0.0 0.388235
0.611765 0.611765 0.0 0.0 0.403922 0.219608 0.0
0.0 0.0 0.611765 0.0 0.223529 0.176471 0.192157
0.611765 0.0 0.615686 0.615686 0.0 0.0 0.0
0.0 0.0 0.0 0.619608 … 0.0 0.0 0.2
0.607843 0.0 0.623529 0.0 0.176471 0.192157 0.0
0.0 0.0 0.623529 0.0 0.0 0.0 0.215686
0.619608 0.619608 0.0 0.0 0.2 0.0 0.207843
0.0 0.0 0.635294 0.635294 0.2 0.192157 0.188235
0.635294 0.0 0.0 0.0 … 0.192157 0.180392 0.0
0.631373 0.0 0.0 0.0 0.0 0.0 0.0
0.0 0.627451 0.635294 0.666667 0.172549 0.0 0.184314
⋮ ⋱ ⋮
0.0 0.129412 0.0 0.541176 0.0 0.286275 0.0
0.14902 0.129412 0.196078 0.537255 0.345098 0.0 0.0
0.215686 0.0 0.262745 0.0 0.301961 0.0 0.207843
0.345098 0.341176 0.356863 0.513725 0.0 0.0 0.231373
0.0 0.0 0.0 0.0 … 0.0 0.243137 0.258824
0.298039 0.415686 0.458824 0.0 0.0 0.0 0.258824
0.0 0.368627 0.4 0.0 0.0 0.0 0.235294
0.0 0.0 0.34902 0.0 0.0 0.239216 0.207843
0.219608 0.0 0.0 0.0 0.0 0.0 0.2
0.0 0.219608 0.235294 0.356863 … 0.0 0.0 0.0
0.196078 0.207843 0.211765 0.0 0.0 0.270588 0.345098
0.192157 0.0 0.196078 0.309804 0.266667 0.356863 0.0
Goal¶
Our goal is to find a the missing entries of this matrix $Y$ and thus reconstruct the image and hopefully figure out who this person is.
Constraint to impose¶
- Ofcourse, we want to ensure that in the reconstructed image, call it $X$, for the available pixels, both images agree, i.e., for any $(i,j)$ in the index set of observed entries, we have $X_{i,j} = Y_{i,j}$.
But how to fill in the rest of the entries?¶
One reasonable of way of doing it finding the simplest image that fits the observed entries. Simplicity of an image when traslated to a matrix can correspond to a matrix with low rank. In other words, we want to minimize the rank of the decision matrix $X$, but subject to $X_{i,j} = Y_{i,j}$ for the observed pixels.
\begin{array}{ll} \underset{X}{\mbox{minimize}} & \text{rank}(X)\\ \mbox{subject to} & X_{i,j}=Y_{i,j},\quad(i,j)\in\text{observed pixels of }Y \end{array}But this is a very hard problem and solving to certifiable global optimality is an active research area. As of now, problems beyond matrix size of $50\times 50$ cannot be solved in a tractable fashion. You can see Ryan's paper on how to solve low-rank problems to certifiable global optimality here.
The best convex approximation of the problem¶
To work around this issue, rather than minimizing $\textrm{rank}(X)$ we minimize the best convex approximation of the rank function, which is the nuclear norm of $X$, denoted by $\| X \|_\star$, which is equal to the sum of singular values of the matrix $X$. So, we solve:
\begin{array}{ll} \underset{X}{\mbox{minimize}} & \| X \|_\star \\ \mbox{subject to} & X_{i,j}=Y_{i,j},\quad(i,j)\in\text{observed pixels of }Y \end{array}The problem above can be formulated as an SDP.
Find the index set of the observed entries.
observed_entries_Y = findall(x->x!=0.0, Y)
8128-element Vector{CartesianIndex{2}}:
CartesianIndex(2, 1)
CartesianIndex(3, 1)
CartesianIndex(5, 1)
CartesianIndex(7, 1)
CartesianIndex(9, 1)
CartesianIndex(11, 1)
CartesianIndex(12, 1)
CartesianIndex(17, 1)
CartesianIndex(19, 1)
CartesianIndex(20, 1)
CartesianIndex(23, 1)
CartesianIndex(25, 1)
CartesianIndex(26, 1)
⋮
CartesianIndex(113, 128)
CartesianIndex(114, 128)
CartesianIndex(115, 128)
CartesianIndex(116, 128)
CartesianIndex(119, 128)
CartesianIndex(120, 128)
CartesianIndex(121, 128)
CartesianIndex(122, 128)
CartesianIndex(123, 128)
CartesianIndex(124, 128)
CartesianIndex(125, 128)
CartesianIndex(127, 128)
Find size of the matrix.
N, N = size(Y)
(128, 128)
Declare the variable $X$.
X = Variable(N,N)
Variable size: (128, 128) sign: real vexity: affine id: 867…105
Add the objective $\| X \|_\star$.
obj_SDP = nuclearnorm(X)
nuclearnorm (convex; positive) └─ 128×128 real variable (id: 867…105)
Now add the constraints $X_{i,j} = Y_{i,j}$ for all $(i,j) \in \texttt{observed_entries_Y}$.
constraints_SDP = Convex.Constraint[]
Constraint[]
for index_i_j in observed_entries_Y
i = index_i_j[1]
j = index_i_j[2]
push!(constraints_SDP, X[i,j] == Y[i,j])
end
Create the problem now!
problem_SDP = minimize(obj_SDP, constraints_SDP)
minimize └─ nuclearnorm (convex; positive) └─ 128×128 real variable (id: 867…105) subject to ├─ == constraint (affine) │ ├─ index (affine; real) │ │ └─ 128×128 real variable (id: 867…105) │ └─ 0.627451 ├─ == constraint (affine) │ ├─ index (affine; real) │ │ └─ 128×128 real variable (id: 867…105) │ └─ 0.611765 ├─ == constraint (affine) │ ├─ index (affine; real) │ │ └─ 128×128 real variable (id: 867…105) │ └─ 0.611765 ├─ == constraint (affine) │ ├─ index (affine; real) │ │ └─ 128×128 real variable (id: 867…105) │ └─ 0.607843 ├─ == constraint (affine) │ ├─ index (affine; real) │ │ └─ 128×128 real variable (id: 867…105) │ └─ 0.619608 ├─ == constraint (affine) │ ├─ index (affine; real) │ │ └─ 128×128 real variable (id: 867…105) │ └─ 0.635294 ├─ == constraint (affine) │ ├─ index (affine; real) │ │ └─ 128×128 real variable (id: 867…105) │ └─ 0.631373 ├─ == constraint (affine) │ ├─ index (affine; real) │ │ └─ 128×128 real variable (id: 867…105) │ └─ 0.662745 ├─ == constraint (affine) │ ├─ index (affine; real) │ │ └─ 128×128 real variable (id: 867…105) │ └─ 0.67451 ├─ == constraint (affine) │ ├─ index (affine; real) │ │ └─ 128×128 real variable (id: 867…105) │ └─ 0.647059 ├─ == constraint (affine) │ ├─ index (affine; real) │ │ └─ 128×128 real variable (id: 867…105) │ └─ 0.533333 ├─ == constraint (affine) │ ├─ index (affine; real) │ │ └─ 128×128 real variable (id: 867…105) │ └─ 0.360784 ├─ == constraint (affine) │ ├─ index (affine; real) │ │ └─ 128×128 real variable (id: 867…105) │ └─ 0.337255 ├─ == constraint (affine) │ ├─ index (affine; real) │ │ └─ 128×128 real variable (id: 867…105) │ └─ 0.337255 ├─ == constraint (affine) │ ├─ index (affine; real) │ │ └─ 128×128 real variable (id: 867…105) │ └─ 0.364706 ⋮ status: `solve!` not called yet
# [💀] Do not run on a laptop, I am solving this on MIT Supercloud
# This is a problem requiring lot of memory
# Constraints : 73665
# Scalar variables : 49153
solve!(problem_SDP, Mosek.Optimizer)
Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 73665 Cones : 0 Scalar variables : 49153 Matrix variables : 1 Integer variables : 0 Optimizer started. Presolve started. Linear dependency checker started. Linear dependency checker terminated. Eliminator started. Freed constraints in eliminator : 0 Eliminator terminated. Eliminator started. Freed constraints in eliminator : 0 Eliminator terminated. Eliminator - tries : 2 time : 0.00 Lin. dep. - tries : 1 time : 0.01 Lin. dep. - number : 0 Presolve terminated. Time: 0.05 Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 73665 Cones : 0 Scalar variables : 49153 Matrix variables : 1 Integer variables : 0 Optimizer - threads : 48 Optimizer - solved problem : the primal Optimizer - Constraints : 32896 Optimizer - Cones : 1 Optimizer - Scalar variables : 24769 conic : 24769 Optimizer - Semi-definite variables: 1 scalarized : 32896 Factor - setup time : 207.52 dense det. time : 0.00 Factor - ML order time : 177.58 GP order time : 0.00 Factor - nonzeros before factor : 5.41e+08 after factor : 5.41e+08 Factor - dense dim. : 2 flops : 1.19e+13 ITE PFEAS DFEAS GFEAS PRSTATUS POBJ DOBJ MU TIME 0 1.9e+00 1.0e+00 1.0e+00 0.00e+00 0.000000000e+00 0.000000000e+00 1.0e+00 207.63 1 6.8e-01 3.6e-01 5.9e-01 -9.71e-01 1.415377135e+02 1.431598397e+02 3.6e-01 257.51 2 5.7e-01 3.1e-01 3.4e-01 -3.34e-01 1.116403593e+02 1.121811844e+02 3.1e-01 303.22 3 9.9e-02 5.3e-02 1.1e-02 2.56e-01 1.532518635e+02 1.531753559e+02 5.3e-02 356.38 4 8.4e-03 4.5e-03 5.5e-04 1.07e+00 1.479916370e+02 1.479971145e+02 4.5e-03 408.76 5 1.9e-03 1.0e-03 5.8e-05 1.00e+00 1.481214349e+02 1.481225967e+02 1.0e-03 457.44 6 4.0e-05 2.2e-05 5.0e-08 1.00e+00 1.479726003e+02 1.479725623e+02 2.2e-05 513.78 7 6.6e-06 3.5e-06 1.2e-08 1.00e+00 1.479718423e+02 1.479718468e+02 3.5e-06 561.63 8 6.9e-07 3.7e-07 4.2e-10 1.00e+00 1.479711247e+02 1.479711253e+02 3.7e-07 615.21 9 1.5e-08 8.1e-09 5.1e-13 1.00e+00 1.479710833e+02 1.479710833e+02 8.1e-09 668.48 Optimizer terminated. Time: 668.58
X_sdp_sol = Convex.evaluate(X);
lenna_original = load("img//Lenna_(test_image).png")
# [lenna colorview(Gray, X_sdp_sol) lenna_original]
[lenna colorview(Gray, X_sdp_sol)]

lenna_original

Solving the same problem using JuMP¶
To model the same problem in JuMP, we need to convert it into a traditional SDP. To that goal, write
Use the result [Lemma 1 Fazel et. al. (2001)] (paper here) we have: $$ \left(\|X\|_{\star}\leq t\right)\Leftrightarrow\begin{bmatrix}U & X\\ X^{\top} & V \end{bmatrix}\succeq0,\mathbf{tr}(U)+\mathbf{tr}(V)\leq2t, $$ where the proof is nontrivial (to me).
$$ \left(\begin{array}{ll} \underset{X,t,U,V}{\mbox{minimize}} & t\\ \mbox{subject to} & X_{i,j}=Y_{i,j},\quad(i,j)\in\textrm{observed pixels of }Y,\\ & \begin{bmatrix}U & X\\ X^{\top} & V \end{bmatrix}\succeq0,\\ & \mathbf{tr}(U)+\mathbf{tr}(V)\leq2t. \end{array}\right) $$using JuMP, Mosek, MosekTools, LinearAlgebra
model_SDP_JuMP = Model(Mosek.Optimizer)
A JuMP Model Feasibility problem with: Variables: 0 Model mode: AUTOMATIC CachingOptimizer state: EMPTY_OPTIMIZER Solver name: Mosek
@variable(model_SDP_JuMP, X2[1:N, 1:N])
128×128 Matrix{VariableRef}:
X2[1,1] X2[1,2] X2[1,3] X2[1,4] … X2[1,127] X2[1,128]
X2[2,1] X2[2,2] X2[2,3] X2[2,4] X2[2,127] X2[2,128]
X2[3,1] X2[3,2] X2[3,3] X2[3,4] X2[3,127] X2[3,128]
X2[4,1] X2[4,2] X2[4,3] X2[4,4] X2[4,127] X2[4,128]
X2[5,1] X2[5,2] X2[5,3] X2[5,4] X2[5,127] X2[5,128]
X2[6,1] X2[6,2] X2[6,3] X2[6,4] … X2[6,127] X2[6,128]
X2[7,1] X2[7,2] X2[7,3] X2[7,4] X2[7,127] X2[7,128]
X2[8,1] X2[8,2] X2[8,3] X2[8,4] X2[8,127] X2[8,128]
X2[9,1] X2[9,2] X2[9,3] X2[9,4] X2[9,127] X2[9,128]
X2[10,1] X2[10,2] X2[10,3] X2[10,4] X2[10,127] X2[10,128]
X2[11,1] X2[11,2] X2[11,3] X2[11,4] … X2[11,127] X2[11,128]
X2[12,1] X2[12,2] X2[12,3] X2[12,4] X2[12,127] X2[12,128]
X2[13,1] X2[13,2] X2[13,3] X2[13,4] X2[13,127] X2[13,128]
⋮ ⋱
X2[117,1] X2[117,2] X2[117,3] X2[117,4] X2[117,127] X2[117,128]
X2[118,1] X2[118,2] X2[118,3] X2[118,4] X2[118,127] X2[118,128]
X2[119,1] X2[119,2] X2[119,3] X2[119,4] X2[119,127] X2[119,128]
X2[120,1] X2[120,2] X2[120,3] X2[120,4] X2[120,127] X2[120,128]
X2[121,1] X2[121,2] X2[121,3] X2[121,4] … X2[121,127] X2[121,128]
X2[122,1] X2[122,2] X2[122,3] X2[122,4] X2[122,127] X2[122,128]
X2[123,1] X2[123,2] X2[123,3] X2[123,4] X2[123,127] X2[123,128]
X2[124,1] X2[124,2] X2[124,3] X2[124,4] X2[124,127] X2[124,128]
X2[125,1] X2[125,2] X2[125,3] X2[125,4] X2[125,127] X2[125,128]
X2[126,1] X2[126,2] X2[126,3] X2[126,4] … X2[126,127] X2[126,128]
X2[127,1] X2[127,2] X2[127,3] X2[127,4] X2[127,127] X2[127,128]
X2[128,1] X2[128,2] X2[128,3] X2[128,4] X2[128,127] X2[128,128]
@variable(model_SDP_JuMP, U[1:N, 1:N]);
@variable(model_SDP_JuMP, V[1:N, 1:N]);
@variable(model_SDP_JuMP, t);
for index_i_j in observed_entries_Y
i = index_i_j[1]
j = index_i_j[2]
@constraint(model_SDP_JuMP, X2[i,j] == Y[i,j])
end
@constraint(model_SDP_JuMP, Symmetric([U X2; X2' V]) in PSDCone());
@constraint(model_SDP_JuMP, tr(U)+tr(V) <= 2*t);
@objective(model_SDP_JuMP, Min, t)
optimize!(model_SDP_JuMP)
Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 8129 Cones : 0 Scalar variables : 16257 Matrix variables : 1 Integer variables : 0 Optimizer started. Presolve started. Linear dependency checker started. Linear dependency checker terminated. Eliminator started. Freed constraints in eliminator : 0 Eliminator terminated. Eliminator started. Freed constraints in eliminator : 0 Eliminator terminated. Eliminator - tries : 2 time : 0.00 Lin. dep. - tries : 1 time : 0.00 Lin. dep. - number : 0 Presolve terminated. Time: 0.01 Problem Name : Objective sense : min Type : CONIC (conic optimization problem) Constraints : 8129 Cones : 0 Scalar variables : 16257 Matrix variables : 1 Integer variables : 0 Optimizer - threads : 48 Optimizer - solved problem : the primal Optimizer - Constraints : 8129 Optimizer - Cones : 1 Optimizer - Scalar variables : 2 conic : 2 Optimizer - Semi-definite variables: 1 scalarized : 32896 Factor - setup time : 2.49 dense det. time : 0.00 Factor - ML order time : 1.40 GP order time : 0.00 Factor - nonzeros before factor : 3.30e+07 after factor : 3.30e+07 Factor - dense dim. : 0 flops : 1.79e+11 ITE PFEAS DFEAS GFEAS PRSTATUS POBJ DOBJ MU TIME 0 6.4e+01 1.0e+00 1.0e+00 0.00e+00 0.000000000e+00 0.000000000e+00 1.0e+00 2.52 1 2.1e+01 3.3e-01 5.0e-01 -9.99e-01 1.470310185e+02 1.484363063e+02 3.3e-01 4.47 2 1.7e+01 2.6e-01 3.0e-01 -4.85e-01 1.350828267e+02 1.356788512e+02 2.6e-01 6.02 3 2.7e+00 4.3e-02 8.6e-03 3.14e-01 1.541097696e+02 1.540464927e+02 4.3e-02 7.69 4 2.5e-01 3.8e-03 4.6e-04 1.14e+00 1.483267313e+02 1.483322905e+02 3.8e-03 9.59 5 3.2e-02 5.0e-04 2.2e-05 1.01e+00 1.481427694e+02 1.481435481e+02 5.0e-04 11.43 6 4.3e-03 6.7e-05 1.2e-06 1.00e+00 1.479864515e+02 1.479866107e+02 6.7e-05 13.24 7 1.1e-03 1.8e-05 1.6e-07 1.00e+00 1.479754287e+02 1.479754705e+02 1.8e-05 14.96 8 1.5e-05 2.3e-07 8.9e-11 1.00e+00 1.479711267e+02 1.479711263e+02 2.3e-07 17.23 9 4.8e-07 7.7e-09 3.5e-13 1.00e+00 1.479710840e+02 1.479710840e+02 7.6e-09 19.47 10 4.0e-08 2.7e-09 1.2e-14 1.00e+00 1.479710825e+02 1.479710825e+02 6.3e-10 21.45 11 3.1e-09 2.0e-08 1.8e-16 1.00e+00 1.479710823e+02 1.479710823e+02 4.8e-11 23.68 Optimizer terminated. Time: 23.68
X_Lenna_JuMP = value.(X2)
128×128 Matrix{Float64}:
0.510133 0.541838 0.635294 0.522442 … 0.470371 0.422462 0.627451
0.627451 0.623529 0.621339 0.611765 0.404712 0.329829 0.388235
0.611765 0.611765 0.632581 0.598682 0.403922 0.219608 0.337453
0.585981 0.581618 0.611765 0.58344 0.223529 0.176471 0.192157
0.611765 0.581893 0.615686 0.615686 0.297408 0.27872 0.277459
0.557052 0.520124 0.570136 0.619608 … 0.387982 0.245395 0.2
0.607843 0.582899 0.623529 0.586153 0.176471 0.192157 0.197013
0.611249 0.637073 0.623529 0.591021 0.229532 0.192887 0.215686
0.619608 0.619608 0.596553 0.559789 0.2 0.151996 0.207843
0.617212 0.58893 0.635294 0.635294 0.2 0.192157 0.188235
0.635294 0.594272 0.62413 0.653188 … 0.192157 0.180392 0.206486
0.631373 0.592408 0.607137 0.675214 0.169149 0.224812 0.184314
0.588056 0.627451 0.635294 0.666667 0.172549 0.22933 0.184314
⋮ ⋱ ⋮
0.149178 0.129412 0.293731 0.541176 0.356051 0.286275 0.241796
0.14902 0.129412 0.196078 0.537255 0.345098 0.324363 0.265208
0.215686 0.222665 0.262745 0.507814 0.301961 0.337263 0.207843
0.345098 0.341176 0.356863 0.513725 0.294473 0.259783 0.231373
0.263513 0.334628 0.38577 0.46014 … 0.320677 0.243137 0.258824
0.298039 0.415686 0.458824 0.438061 0.354361 0.25763 0.258824
0.268498 0.368627 0.4 0.430556 0.279037 0.328952 0.235294
0.249179 0.289784 0.34902 0.431445 0.284626 0.239216 0.207843
0.219608 0.251989 0.311455 0.363335 0.335256 0.291726 0.2
0.229011 0.219608 0.235294 0.356863 … 0.268871 0.212628 0.203565
0.196078 0.207843 0.211765 0.351703 0.348219 0.270588 0.345098
0.192157 0.202599 0.196078 0.309804 0.266667 0.356863 0.304792
# [lenna colorview(Gray, X_Lenna_JuMP) lenna_original]
[lenna colorview(Gray, X_Lenna_JuMP)]

Time taken by JuMP is 25 s whereas time taken by Convex.jl is 415 s. The main reason behind the time difference is that, to use Convex.jl we could feed it the problem formulation rather than converting into an SDP form, so internally Convex.jl converts the model into an SDP programmatically. The converted SDP has the follwoing size:
The SDP size in Convex.jl (constructed internally Convex.jl)
#------------------------------------------
Constraints : 73665
Scalar variables : 49153
Whereas, we converted the problem ourselves into an SDP to feed it into JuMP. The final formulation was much tighter than what Convex.jl does automatically. Note that we invested some time here by researching into google scholar and finding the right paper. The SDP in JuMP has the following size:
The SDP size in JuMP
#-------------------------
Constraints : 8129
Scalar variables : 16257
Sequential convex programming¶
Solving a nonconvex problem using a local convex optimization method
Convex portions of a problem are handled "exactly" and efficiently
Sequential convex programming is a heuristic, it can fail
Success often depend on a good starting point
We consider the nonconvex problem:
where $f_{0}$ and $f_{i}$ are possibly nonconvex, $h_{i}$ are possibly non-affine.
Basic idea of Sequential convex programming¶
Maintain the current iterate $x^{(k)}$ and convex trust region $\mathcal{T}^{(k)}$
Form convex approximation $f_{i}^{\textrm{cvx}}$ of $f_{i}$ over
$\mathcal{T}^{(k)}$
- Form affine approximation $h_{i}^{\textrm{afn}}$ of $h_{i}$ over
$\mathcal{T}^{(k)}$
- Then update the iterate $x^{(k+1)}$ is the optimal point found by
solving the convex problem $$ \begin{array}{ll} \underset{x\in\mathbf{R}^{d}}{\mbox{minimize}} & f_{0}^{\textrm{cvx}}(x)\\ \mbox{subject to} & f_{i}^{\textrm{cvx}}(x)\leq0,\quad i=1,\ldots,m,\\ & h_{i}^{\textrm{afn}}(x)=0,\quad j=1,\ldots,p,\\ & x\in\mathcal{T}^{(k)}, \end{array} $$ which is a convex approximation of the original nonconvex problem.
How to compute the approximations¶
Trust region is computed using $\mathcal{T}^{(k)}=\{x\mid\|x-x^{(k)}\|\leq\rho\}$
$h_{i}^{\textrm{afn}}=h_{i}(x^{(k)})+\nabla h_{i}(x^{(k)})^{\top}(x-x^{(k)})$
$f_{i}^{\textrm{cvx}}=f_{i}(x^{(k)})+\nabla f_{i}(x^{(k)})^{\top}(x-x^{(k)})+\frac{1}{2}(x-x^{(k)})^{\top}P(x-x^{(k)})$
where $P=\left[\nabla^{2}f(x^{(k)})\right]_{+}$ which is the PSD part of Hessian