Building an AWS® ML Pipeline with Workbench¶
This notebook uses the Workbench Science Workbench to quickly build an AWS® Machine Learning Pipeline with the AQSolDB public dataset. This dataset aggregates aqueous solubility data for a large set of compounds.
We're going to set up a full AWS Machine Learning Pipeline from start to finish. Since the Workbench Classes encapsulate, organize, and manage sets of AWS® Services, setting up our ML pipeline will be straight forward.
Workbench also provides visibility into AWS services for every step of the process so we know exactly what we've got and how to use it.
Data¶
AqSolDB: A curated reference set of aqueous solubility, created by the Autonomous Energy Materials Discovery [AMD] research group, consists of aqueous solubility values of 9,982 unique compounds curated from 9 different publicly available aqueous solubility datasets. AqSolDB also contains some relevant topological and physico-chemical 2D descriptors. Additionally, AqSolDB contains validated molecular representations of each of the compounds. This openly accessible dataset, which is the largest of its kind, and will not only serve as a useful reference source of measured and calculated solubility data, but also as a much improved and generalizable training data source for building data-driven models. (2019-04-10)
Main Reference: https://www.nature.com/articles/s41597-019-0151-1
Data Dowloaded from the Harvard DataVerse: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/OVHAW8
Workbench¶
Workbench is a medium granularity framework that manages and aggregates AWS® Services into classes and concepts. When you use Workbench you think about DataSources, FeatureSets, Models, and Endpoints. Underneath the hood those classes handle all the details around updating and
Notebook¶
This notebook uses the Workbench Science Workbench to quickly build an AWS® Machine Learning Pipeline.
We're going to set up a full AWS Machine Learning Pipeline from start to finish. Since the Workbench Classes encapsulate, organize, and manage sets of AWS® Services, setting up our ML pipeline will be straight forward.
Workbench also provides visibility into AWS services for every step of the process so we know exactly what we've got and how to use it.
® Amazon Web Services, AWS, the Powered by AWS logo, are trademarks of Amazon.com, Inc. or its affiliates.
# Okay first we get our data into Workbench as a DataSource
from workbench.api.data_source import DataSource
s3_path = 's3://workbench-public-data/comp_chem/aqsol_public_data.csv'
data_source = DataSource(s3_path, 'aqsol_data')
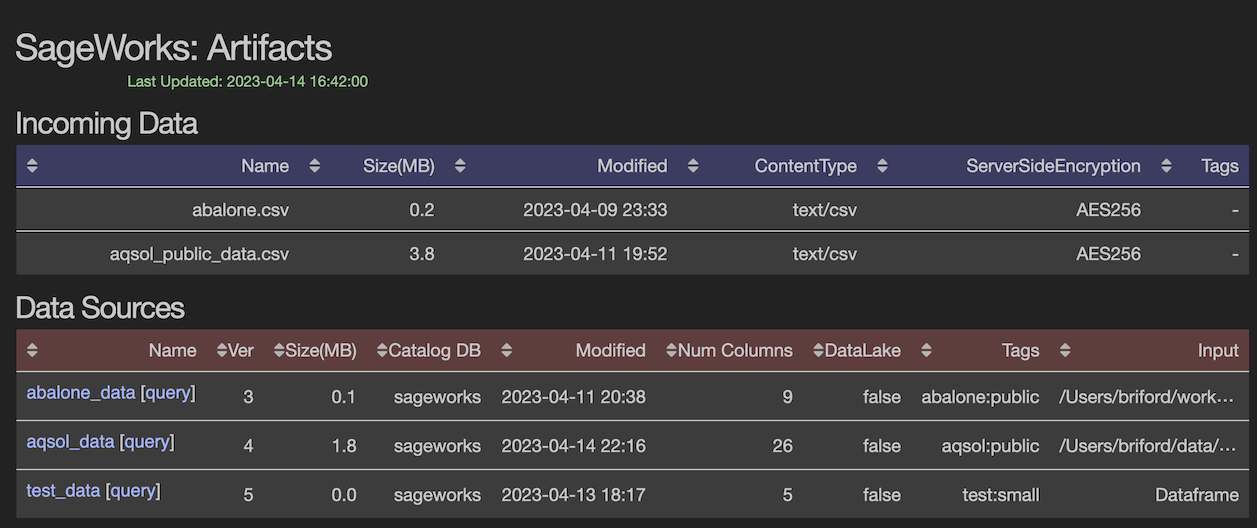
So what just happened?¶
Okay, so it was just a few lines of code but Workbench did the following for you:
- Transformed the CSV to a Parquet formatted dataset and stored it in AWS S3
- Created an AWS Data Catalog database/table with the columns names/types
- Athena Queries can now be done directly on this data in AWS Athena Console
The new 'DataSource' will show up in AWS and of course the Workbench AWS Dashboard. Anyone can see the data, get information on it, use AWS® Athena to query it, and of course use it as part of their analysis pipelines.

Visibility and Easy to Use AWS Athena Queries¶
Since Workbench manages a broad range of AWS Services it means that you get visibility into exactly what data you have in AWS. It also means nice perks like hitting the 'Query' link in the Dashboard Web Interface and getting a direct Athena console on your dataset. With AWS Athena you can use typical SQL statements to inspect and investigate your data.
But that's not all!
Workbench also provides API to directly query DataSources and FeatureSets right from the API, so lets do that now.
data_source.query('SELECT * from aqsol_data limit 5')
Create a FeatureSet¶
Note: Normally this is where you'd do a deep dive on the data/features, look at data quality metrics, redudant features and engineer new features. For the purposes of this notebook we're simply going to take the features given to us in the AQSolDB data from the Harvard Dataverse, those features are:
data_source.column_details()
data_source.to_features("aqsol_features")
New FeatureSet shows up in Dashboard¶
Now we see our new feature set automatically pop up in our dashboard. FeatureSet creation involves the most complex set of AWS Services:
- New Entry in AWS Feature Store
- Specific Type and Field Requirements are handled
- Plus all the AWS Services associated with DataSources (see above)
The new 'FeatureSet' will show up in AWS and of course the Workbench AWS Dashboard. Anyone can see the feature set, get information on it, use AWS® Athena to query it, and of course use it as part of their analysis pipelines.

Important: All inputs are stored to track provenance on your data as it goes through the pipeline. We can see the last field in the FeatureSet shows the input DataSource.
Publishing our Model¶
Note: Normally this is where you'd do a deep dive on the feature set. For the purposes of this notebook we're simply going to take the features given to us and make a reference model that can track our baseline model performance for other to improve upon. :)
from workbench.api.feature_set import FeatureSet
from workbench.api.model import Model, ModelType
# Compute our features
feature_set = FeatureSet("aqsol_features")
feature_list = [
"sd",
"ocurrences",
"molwt",
"mollogp",
"molmr",
"heavyatomcount",
"numhacceptors",
"numhdonors",
"numheteroatoms",
"numrotatablebonds",
"numvalenceelectrons",
"numaromaticrings",
"numsaturatedrings",
"numaliphaticrings",
"ringcount",
"tpsa",
"labuteasa",
"balabanj",
"bertzct",
]
feature_set.to_model(
name="aqsol-regression",
model_type=ModelType.REGRESSOR,
target_column="solubility",
feature_list=feature_list,
description="AQSol Regression Model",
tags=["aqsol", "regression"],
)
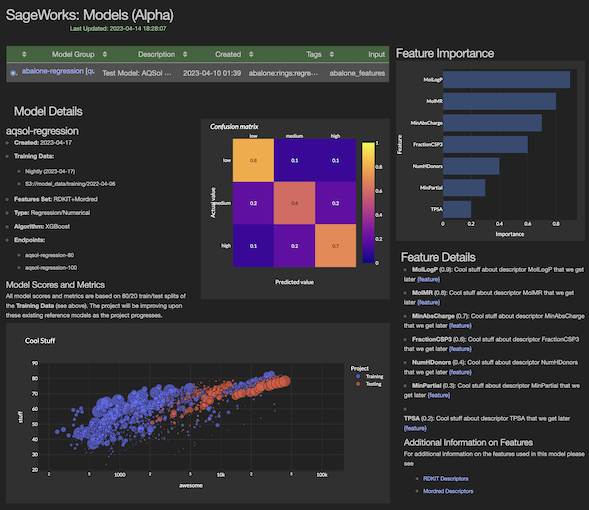
Model is trained and published¶
Okay we've clipped the output above to focus on the important bits. The Workbench model harness provides some simple model performance output
- FIT/TRAIN: (8056, 35)
- VALIDATiON: (1926, 35)
- RMSE: 1.175
- MAE: 0.784
- R2 Score: 0.760
The Workbench Dashboard also has a really spiffy model details page that gives a deeper dive on the feature importance and model performance metrics.
Note: Model details is still WIP/Alpha version that we're working on :)
Deploying an AWS Endpoint¶
Okay now that are model has been published we can deploy an AWS Endpoint to serve inference requests for that model. Deploying an Endpoint allows a large set of servies/APIs to use our model in production.
m = Model("aqsol-regression")
m.to_endpoint(name="aqsol-regression-end", tags=["aqsol", "regression"])
Model Inference from the Endpoint¶
AWS Endpoints will bundle up a model as a service that responds to HTTP requests. The typical way to use an endpoint is to send a POST request with your features in CSV format. Workbench provides a nice DataFrame based interface that takes care of many details for you.
# Get the Endpoint
from workbench.api.endpoint import Endpoint
my_endpoint = Endpoint('aqsol-regression-end')
Model Provenance is locked into Workbench¶
We can now look at the model, see what FeatureSet was used to train it and even better see exactly which ROWS in that training set where used to create the model. We can make a query that returns the ROWS that were not used for training.
# Get a DataFrame of data (not used to train) and run predictions
table = feature_set.view("training").table
test_df = feature_set.query(f"SELECT * FROM {table} where training = FALSE")
test_df.head()
# Okay now use the Workbench Endpoint to make prediction on TEST data
prediction_df = my_endpoint.predict(test_df)
metrics = my_endpoint.regression_metrics('solubility', prediction_df)
print(metrics)
# Lets look at the predictions versus actual values
prediction_df[['id', 'solubility', 'prediction']]
plot_predictions(prediction_df)
Follow Up on Predictions¶
Looking at the prediction plot above we can see that many predictions were close to the actual value but about 10 of the predictions were WAY off. So at this point we'd use Workbench to investigate those predictions, map them back to our FeatureSet and DataSource and see if there were irregularities in the training data.
Wrap up: Building an AWS® ML Pipeline with Workbench¶

This notebook used the Workbench Science Toolkit to quickly build an AWS® Machine Learning Pipeline with the AQSolDB public dataset. We built a full AWS Machine Learning Pipeline from start to finish.
Workbench made it easy:
- Visibility into AWS services for every step of the process.
- Managed the complexity of organizing the data and populating the AWS services.
- Provided an easy to use API to perform Transformations and inspect Artifacts.
Using Workbench will minimizize the time and manpower needed to incorporate AWS ML into your organization. If your company would like to be a Workbench Alpha Tester, contact us at workbench@supercowpowers.com.
Helper Methods¶
# Helper to look at predictions vs target
from math import sqrt
import pandas as pd
def plot_predictions(df, line=True):
# Dataframe of the targets and predictions
target = 'Actual Solubility'
pred = 'Predicted Solubility'
df_plot = pd.DataFrame({target: df['solubility'], pred: df['prediction']})
# Compute Error per prediction
df_plot['RMSError'] = df_plot.apply(lambda x: sqrt((x[pred] - x[target])**2), axis=1)
#df_plot['error'] = df_plot.apply(lambda x: abs(x[pred] - x[target]), axis=1)
ax = df_plot.plot.scatter(x=target, y=pred, c='RMSError', cmap='coolwarm', sharex=False)
# Just a diagonal line
if line:
ax.axline((1, 1), slope=1, linewidth=2, c='black')
x_pad = (df_plot[target].max() - df_plot[target].min())/10.0
y_pad = (df_plot[pred].max() - df_plot[pred].min())/10.0
plt.xlim(df_plot[target].min()-x_pad, df_plot[target].max()+x_pad)
plt.ylim(df_plot[pred].min()-y_pad, df_plot[pred].max()+y_pad)
# Plotting defaults
%matplotlib inline
import matplotlib.pyplot as plt
#plt.style.use('seaborn-deep')
#plt.style.use('seaborn-dark')
plt.rcParams['font.size'] = 12.0
plt.rcParams['figure.figsize'] = 14.0, 7.0