Data Values & Types, Variables, Std I/O, Computations¶
A value is one of the fundamental things -- like a letter or number -- that a program manipulates.
These values are classified into data types.
In Python, there're mainly two data types: numbers and strings - numbers can be integer or float
Boolean (True/False) is also supported type!
first program - hello world!¶
In [1]:
# First program
# This is a comment line...
# By Programmer info...
print('Hello world!')
# In python 2: print is a statement not a function
# print 'Hello World!'
Hello world!
comments¶
- Programming languages provide a way to write comment along with the codes
- Python uses # symbol to write a single line comment
- comments are for humans/programmers to convey/explain what the code is doing or supposed to do
- Python interpreter ignores the comments
data types¶
- built-in type() function can be used to know type of data
- functions will be covered in Chapter 04
In [2]:
type(100)
Out[2]:
int
In [3]:
type(1000.99)
Out[3]:
float
In [4]:
type('Hello World!')
Out[4]:
str
In [5]:
type('A')
Out[5]:
str
In [6]:
print hello
File "<ipython-input-6-2a20a4ba3335>", line 1 print hello ^ SyntaxError: Missing parentheses in call to 'print'. Did you mean print(hello)?
In [22]:
type("17")
Out[22]:
str
In [23]:
type("""Triple double quoted data""")
Out[23]:
str
In [24]:
type('''Type of Triple single quote data is''')
Out[24]:
str
type conversion/casting¶
- changing data from one type into another when possible
- use built-in function such as str(), int(), float(), etc. to convert data to that particular type
In [25]:
data = 'hello' # can't conver it to int or float types
In [26]:
data = '100'
type(data)
Out[26]:
str
In [27]:
num = int(data)
type(num)
Out[27]:
int
In [28]:
price = float('500.99')
type(price)
Out[28]:
float
In [29]:
num = 99.99
strNum = str(num)
type(strNum)
Out[29]:
str
standard output¶
- printing or writing output to common/standard output such as monitor
- way to display the results and interact with the users of your program
In [30]:
print('''"Oh no", she exclaimed, "Ben's bike is broken!"''')
"Oh no", she exclaimed, "Ben's bike is broken!"
In [31]:
print("What\'s up\n Shaq O\'Neal?")
What's up Shaq O'Neal?
In [32]:
type(True)
Out[32]:
bool
In [33]:
print(x)
--------------------------------------------------------------------------- NameError Traceback (most recent call last) <ipython-input-33-fc17d851ef81> in <module>() ----> 1 print(x) NameError: name 'x' is not defined
In [7]:
help(str)
Help on class str in module builtins:
class str(object)
| str(object='') -> str
| str(bytes_or_buffer[, encoding[, errors]]) -> str
|
| Create a new string object from the given object. If encoding or
| errors is specified, then the object must expose a data buffer
| that will be decoded using the given encoding and error handler.
| Otherwise, returns the result of object.__str__() (if defined)
| or repr(object).
| encoding defaults to sys.getdefaultencoding().
| errors defaults to 'strict'.
|
| Methods defined here:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __eq__(self, value, /)
| Return self==value.
|
| __format__(self, format_spec, /)
| Return a formatted version of the string as described by format_spec.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __getitem__(self, key, /)
| Return self[key].
|
| __getnewargs__(...)
|
| __gt__(self, value, /)
| Return self>value.
|
| __hash__(self, /)
| Return hash(self).
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self<value.
|
| __mod__(self, value, /)
| Return self%value.
|
| __mul__(self, value, /)
| Return self*value.
|
| __ne__(self, value, /)
| Return self!=value.
|
| __repr__(self, /)
| Return repr(self).
|
| __rmod__(self, value, /)
| Return value%self.
|
| __rmul__(self, value, /)
| Return value*self.
|
| __sizeof__(self, /)
| Return the size of the string in memory, in bytes.
|
| __str__(self, /)
| Return str(self).
|
| capitalize(self, /)
| Return a capitalized version of the string.
|
| More specifically, make the first character have upper case and the rest lower
| case.
|
| casefold(self, /)
| Return a version of the string suitable for caseless comparisons.
|
| center(self, width, fillchar=' ', /)
| Return a centered string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| count(...)
| S.count(sub[, start[, end]]) -> int
|
| Return the number of non-overlapping occurrences of substring sub in
| string S[start:end]. Optional arguments start and end are
| interpreted as in slice notation.
|
| encode(self, /, encoding='utf-8', errors='strict')
| Encode the string using the codec registered for encoding.
|
| encoding
| The encoding in which to encode the string.
| errors
| The error handling scheme to use for encoding errors.
| The default is 'strict' meaning that encoding errors raise a
| UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
| 'xmlcharrefreplace' as well as any other name registered with
| codecs.register_error that can handle UnicodeEncodeErrors.
|
| endswith(...)
| S.endswith(suffix[, start[, end]]) -> bool
|
| Return True if S ends with the specified suffix, False otherwise.
| With optional start, test S beginning at that position.
| With optional end, stop comparing S at that position.
| suffix can also be a tuple of strings to try.
|
| expandtabs(self, /, tabsize=8)
| Return a copy where all tab characters are expanded using spaces.
|
| If tabsize is not given, a tab size of 8 characters is assumed.
|
| find(...)
| S.find(sub[, start[, end]]) -> int
|
| Return the lowest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Return -1 on failure.
|
| format(...)
| S.format(*args, **kwargs) -> str
|
| Return a formatted version of S, using substitutions from args and kwargs.
| The substitutions are identified by braces ('{' and '}').
|
| format_map(...)
| S.format_map(mapping) -> str
|
| Return a formatted version of S, using substitutions from mapping.
| The substitutions are identified by braces ('{' and '}').
|
| index(...)
| S.index(sub[, start[, end]]) -> int
|
| Return the lowest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Raises ValueError when the substring is not found.
|
| isalnum(self, /)
| Return True if the string is an alpha-numeric string, False otherwise.
|
| A string is alpha-numeric if all characters in the string are alpha-numeric and
| there is at least one character in the string.
|
| isalpha(self, /)
| Return True if the string is an alphabetic string, False otherwise.
|
| A string is alphabetic if all characters in the string are alphabetic and there
| is at least one character in the string.
|
| isascii(self, /)
| Return True if all characters in the string are ASCII, False otherwise.
|
| ASCII characters have code points in the range U+0000-U+007F.
| Empty string is ASCII too.
|
| isdecimal(self, /)
| Return True if the string is a decimal string, False otherwise.
|
| A string is a decimal string if all characters in the string are decimal and
| there is at least one character in the string.
|
| isdigit(self, /)
| Return True if the string is a digit string, False otherwise.
|
| A string is a digit string if all characters in the string are digits and there
| is at least one character in the string.
|
| isidentifier(self, /)
| Return True if the string is a valid Python identifier, False otherwise.
|
| Use keyword.iskeyword() to test for reserved identifiers such as "def" and
| "class".
|
| islower(self, /)
| Return True if the string is a lowercase string, False otherwise.
|
| A string is lowercase if all cased characters in the string are lowercase and
| there is at least one cased character in the string.
|
| isnumeric(self, /)
| Return True if the string is a numeric string, False otherwise.
|
| A string is numeric if all characters in the string are numeric and there is at
| least one character in the string.
|
| isprintable(self, /)
| Return True if the string is printable, False otherwise.
|
| A string is printable if all of its characters are considered printable in
| repr() or if it is empty.
|
| isspace(self, /)
| Return True if the string is a whitespace string, False otherwise.
|
| A string is whitespace if all characters in the string are whitespace and there
| is at least one character in the string.
|
| istitle(self, /)
| Return True if the string is a title-cased string, False otherwise.
|
| In a title-cased string, upper- and title-case characters may only
| follow uncased characters and lowercase characters only cased ones.
|
| isupper(self, /)
| Return True if the string is an uppercase string, False otherwise.
|
| A string is uppercase if all cased characters in the string are uppercase and
| there is at least one cased character in the string.
|
| join(self, iterable, /)
| Concatenate any number of strings.
|
| The string whose method is called is inserted in between each given string.
| The result is returned as a new string.
|
| Example: '.'.join(['ab', 'pq', 'rs']) -> 'ab.pq.rs'
|
| ljust(self, width, fillchar=' ', /)
| Return a left-justified string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| lower(self, /)
| Return a copy of the string converted to lowercase.
|
| lstrip(self, chars=None, /)
| Return a copy of the string with leading whitespace removed.
|
| If chars is given and not None, remove characters in chars instead.
|
| partition(self, sep, /)
| Partition the string into three parts using the given separator.
|
| This will search for the separator in the string. If the separator is found,
| returns a 3-tuple containing the part before the separator, the separator
| itself, and the part after it.
|
| If the separator is not found, returns a 3-tuple containing the original string
| and two empty strings.
|
| replace(self, old, new, count=-1, /)
| Return a copy with all occurrences of substring old replaced by new.
|
| count
| Maximum number of occurrences to replace.
| -1 (the default value) means replace all occurrences.
|
| If the optional argument count is given, only the first count occurrences are
| replaced.
|
| rfind(...)
| S.rfind(sub[, start[, end]]) -> int
|
| Return the highest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Return -1 on failure.
|
| rindex(...)
| S.rindex(sub[, start[, end]]) -> int
|
| Return the highest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Raises ValueError when the substring is not found.
|
| rjust(self, width, fillchar=' ', /)
| Return a right-justified string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| rpartition(self, sep, /)
| Partition the string into three parts using the given separator.
|
| This will search for the separator in the string, starting at the end. If
| the separator is found, returns a 3-tuple containing the part before the
| separator, the separator itself, and the part after it.
|
| If the separator is not found, returns a 3-tuple containing two empty strings
| and the original string.
|
| rsplit(self, /, sep=None, maxsplit=-1)
| Return a list of the words in the string, using sep as the delimiter string.
|
| sep
| The delimiter according which to split the string.
| None (the default value) means split according to any whitespace,
| and discard empty strings from the result.
| maxsplit
| Maximum number of splits to do.
| -1 (the default value) means no limit.
|
| Splits are done starting at the end of the string and working to the front.
|
| rstrip(self, chars=None, /)
| Return a copy of the string with trailing whitespace removed.
|
| If chars is given and not None, remove characters in chars instead.
|
| split(self, /, sep=None, maxsplit=-1)
| Return a list of the words in the string, using sep as the delimiter string.
|
| sep
| The delimiter according which to split the string.
| None (the default value) means split according to any whitespace,
| and discard empty strings from the result.
| maxsplit
| Maximum number of splits to do.
| -1 (the default value) means no limit.
|
| splitlines(self, /, keepends=False)
| Return a list of the lines in the string, breaking at line boundaries.
|
| Line breaks are not included in the resulting list unless keepends is given and
| true.
|
| startswith(...)
| S.startswith(prefix[, start[, end]]) -> bool
|
| Return True if S starts with the specified prefix, False otherwise.
| With optional start, test S beginning at that position.
| With optional end, stop comparing S at that position.
| prefix can also be a tuple of strings to try.
|
| strip(self, chars=None, /)
| Return a copy of the string with leading and trailing whitespace remove.
|
| If chars is given and not None, remove characters in chars instead.
|
| swapcase(self, /)
| Convert uppercase characters to lowercase and lowercase characters to uppercase.
|
| title(self, /)
| Return a version of the string where each word is titlecased.
|
| More specifically, words start with uppercased characters and all remaining
| cased characters have lower case.
|
| translate(self, table, /)
| Replace each character in the string using the given translation table.
|
| table
| Translation table, which must be a mapping of Unicode ordinals to
| Unicode ordinals, strings, or None.
|
| The table must implement lookup/indexing via __getitem__, for instance a
| dictionary or list. If this operation raises LookupError, the character is
| left untouched. Characters mapped to None are deleted.
|
| upper(self, /)
| Return a copy of the string converted to uppercase.
|
| zfill(self, width, /)
| Pad a numeric string with zeros on the left, to fill a field of the given width.
|
| The string is never truncated.
|
| ----------------------------------------------------------------------
| Static methods defined here:
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| maketrans(x, y=None, z=None, /)
| Return a translation table usable for str.translate().
|
| If there is only one argument, it must be a dictionary mapping Unicode
| ordinals (integers) or characters to Unicode ordinals, strings or None.
| Character keys will be then converted to ordinals.
| If there are two arguments, they must be strings of equal length, and
| in the resulting dictionary, each character in x will be mapped to the
| character at the same position in y. If there is a third argument, it
| must be a string, whose characters will be mapped to None in the result.
escape sequences¶
- some letters or sequence of letters have special meaning to Python
- single, double and tripple single or double quotes represent string data
- use backslash \ to represent these escape sequences, e.g.,
- \n - new line
- \ - back quote
- \t - tab
- \r - carriage return
- ' - single quote
- " - double quote
In [34]:
print('hello \there...\n how are you?')
hello here... how are you?
In [35]:
print('how many back slahses will be printeted? \\\\')
how many back slahses will be printeted? \\
In [36]:
print(r'how many back slahses will be printeted? \\\\')
how many back slahses will be printeted? \\\\
variables¶
- Variables are identifiers that are used to store values which can be then easily manipulated
- variables give names to data so the data can be easily referenced by their names over and again
- Rules and best practices for creating identifiers and variable names:
- can't be a keyword -- what are the built-in keywords?
- can start with only alphabets or underscore ( _ )
- can't have symbols such as $, %, &, white space, etc.
- can't start with a digit but digits can be used anywhere else in the name
- use camelCase names or use _ for_multi_word_names
- use concise yet meaningul and unambigous names for less typing and avoid typos
In [11]:
help('keywords')
Here is a list of the Python keywords. Enter any keyword to get more help. False class from or None continue global pass True def if raise and del import return as elif in try assert else is while async except lambda with await finally nonlocal yield break for not
In [12]:
help('True')
Help on bool object: class bool(int) | bool(x) -> bool | | Returns True when the argument x is true, False otherwise. | The builtins True and False are the only two instances of the class bool. | The class bool is a subclass of the class int, and cannot be subclassed. | | Method resolution order: | bool | int | object | | Methods defined here: | | __and__(self, value, /) | Return self&value. | | __or__(self, value, /) | Return self|value. | | __rand__(self, value, /) | Return value&self. | | __repr__(self, /) | Return repr(self). | | __ror__(self, value, /) | Return value|self. | | __rxor__(self, value, /) | Return value^self. | | __str__(self, /) | Return str(self). | | __xor__(self, value, /) | Return self^value. | | ---------------------------------------------------------------------- | Static methods defined here: | | __new__(*args, **kwargs) from builtins.type | Create and return a new object. See help(type) for accurate signature. | | ---------------------------------------------------------------------- | Methods inherited from int: | | __abs__(self, /) | abs(self) | | __add__(self, value, /) | Return self+value. | | __bool__(self, /) | self != 0 | | __ceil__(...) | Ceiling of an Integral returns itself. | | __divmod__(self, value, /) | Return divmod(self, value). | | __eq__(self, value, /) | Return self==value. | | __float__(self, /) | float(self) | | __floor__(...) | Flooring an Integral returns itself. | | __floordiv__(self, value, /) | Return self//value. | | __format__(self, format_spec, /) | Default object formatter. | | __ge__(self, value, /) | Return self>=value. | | __getattribute__(self, name, /) | Return getattr(self, name). | | __getnewargs__(self, /) | | __gt__(self, value, /) | Return self>value. | | __hash__(self, /) | Return hash(self). | | __index__(self, /) | Return self converted to an integer, if self is suitable for use as an index into a list. | | __int__(self, /) | int(self) | | __invert__(self, /) | ~self | | __le__(self, value, /) | Return self<=value. | | __lshift__(self, value, /) | Return self<<value. | | __lt__(self, value, /) | Return self<value. | | __mod__(self, value, /) | Return self%value. | | __mul__(self, value, /) | Return self*value. | | __ne__(self, value, /) | Return self!=value. | | __neg__(self, /) | -self | | __pos__(self, /) | +self | | __pow__(self, value, mod=None, /) | Return pow(self, value, mod). | | __radd__(self, value, /) | Return value+self. | | __rdivmod__(self, value, /) | Return divmod(value, self). | | __rfloordiv__(self, value, /) | Return value//self. | | __rlshift__(self, value, /) | Return value<<self. | | __rmod__(self, value, /) | Return value%self. | | __rmul__(self, value, /) | Return value*self. | | __round__(...) | Rounding an Integral returns itself. | Rounding with an ndigits argument also returns an integer. | | __rpow__(self, value, mod=None, /) | Return pow(value, self, mod). | | __rrshift__(self, value, /) | Return value>>self. | | __rshift__(self, value, /) | Return self>>value. | | __rsub__(self, value, /) | Return value-self. | | __rtruediv__(self, value, /) | Return value/self. | | __sizeof__(self, /) | Returns size in memory, in bytes. | | __sub__(self, value, /) | Return self-value. | | __truediv__(self, value, /) | Return self/value. | | __trunc__(...) | Truncating an Integral returns itself. | | bit_length(self, /) | Number of bits necessary to represent self in binary. | | >>> bin(37) | '0b100101' | >>> (37).bit_length() | 6 | | conjugate(...) | Returns self, the complex conjugate of any int. | | to_bytes(self, /, length, byteorder, *, signed=False) | Return an array of bytes representing an integer. | | length | Length of bytes object to use. An OverflowError is raised if the | integer is not representable with the given number of bytes. | byteorder | The byte order used to represent the integer. If byteorder is 'big', | the most significant byte is at the beginning of the byte array. If | byteorder is 'little', the most significant byte is at the end of the | byte array. To request the native byte order of the host system, use | `sys.byteorder' as the byte order value. | signed | Determines whether two's complement is used to represent the integer. | If signed is False and a negative integer is given, an OverflowError | is raised. | | ---------------------------------------------------------------------- | Class methods inherited from int: | | from_bytes(bytes, byteorder, *, signed=False) from builtins.type | Return the integer represented by the given array of bytes. | | bytes | Holds the array of bytes to convert. The argument must either | support the buffer protocol or be an iterable object producing bytes. | Bytes and bytearray are examples of built-in objects that support the | buffer protocol. | byteorder | The byte order used to represent the integer. If byteorder is 'big', | the most significant byte is at the beginning of the byte array. If | byteorder is 'little', the most significant byte is at the end of the | byte array. To request the native byte order of the host system, use | `sys.byteorder' as the byte order value. | signed | Indicates whether two's complement is used to represent the integer. | | ---------------------------------------------------------------------- | Data descriptors inherited from int: | | denominator | the denominator of a rational number in lowest terms | | imag | the imaginary part of a complex number | | numerator | the numerator of a rational number in lowest terms | | real | the real part of a complex number
In [13]:
# Define some variables to show the values stored in variables can be changed from one type to another
# Python is loosely typed
computation - operators and operands¶
- operators are special tokens/symbols that represent computations like addition, multiplication and division
- the values an operator uses are called operands
- some binary operators that take two operands
- addition: 10 + 20
- subtraction: 20 - 10
- true division: 10 / 3
- integer division: 10 // 3
- remainder: 10 % 2
- power: 2 ** 3
In [14]:
# play with some examples of various operators supported by Python
order of operations¶
depends on the rules of precedence: PEMDAS from high to low order
- Parenthesis
- Exponentiation
- Multiplication and Division (left to right)
- Addition and Subtraction (left to right)
In [15]:
# some examples
print(2 * 3 ** 2)
18
operations on string¶
- Chapter 08 covers more on string data type
In [16]:
help(str)
Help on class str in module builtins:
class str(object)
| str(object='') -> str
| str(bytes_or_buffer[, encoding[, errors]]) -> str
|
| Create a new string object from the given object. If encoding or
| errors is specified, then the object must expose a data buffer
| that will be decoded using the given encoding and error handler.
| Otherwise, returns the result of object.__str__() (if defined)
| or repr(object).
| encoding defaults to sys.getdefaultencoding().
| errors defaults to 'strict'.
|
| Methods defined here:
|
| __add__(self, value, /)
| Return self+value.
|
| __contains__(self, key, /)
| Return key in self.
|
| __eq__(self, value, /)
| Return self==value.
|
| __format__(self, format_spec, /)
| Return a formatted version of the string as described by format_spec.
|
| __ge__(self, value, /)
| Return self>=value.
|
| __getattribute__(self, name, /)
| Return getattr(self, name).
|
| __getitem__(self, key, /)
| Return self[key].
|
| __getnewargs__(...)
|
| __gt__(self, value, /)
| Return self>value.
|
| __hash__(self, /)
| Return hash(self).
|
| __iter__(self, /)
| Implement iter(self).
|
| __le__(self, value, /)
| Return self<=value.
|
| __len__(self, /)
| Return len(self).
|
| __lt__(self, value, /)
| Return self<value.
|
| __mod__(self, value, /)
| Return self%value.
|
| __mul__(self, value, /)
| Return self*value.
|
| __ne__(self, value, /)
| Return self!=value.
|
| __repr__(self, /)
| Return repr(self).
|
| __rmod__(self, value, /)
| Return value%self.
|
| __rmul__(self, value, /)
| Return value*self.
|
| __sizeof__(self, /)
| Return the size of the string in memory, in bytes.
|
| __str__(self, /)
| Return str(self).
|
| capitalize(self, /)
| Return a capitalized version of the string.
|
| More specifically, make the first character have upper case and the rest lower
| case.
|
| casefold(self, /)
| Return a version of the string suitable for caseless comparisons.
|
| center(self, width, fillchar=' ', /)
| Return a centered string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| count(...)
| S.count(sub[, start[, end]]) -> int
|
| Return the number of non-overlapping occurrences of substring sub in
| string S[start:end]. Optional arguments start and end are
| interpreted as in slice notation.
|
| encode(self, /, encoding='utf-8', errors='strict')
| Encode the string using the codec registered for encoding.
|
| encoding
| The encoding in which to encode the string.
| errors
| The error handling scheme to use for encoding errors.
| The default is 'strict' meaning that encoding errors raise a
| UnicodeEncodeError. Other possible values are 'ignore', 'replace' and
| 'xmlcharrefreplace' as well as any other name registered with
| codecs.register_error that can handle UnicodeEncodeErrors.
|
| endswith(...)
| S.endswith(suffix[, start[, end]]) -> bool
|
| Return True if S ends with the specified suffix, False otherwise.
| With optional start, test S beginning at that position.
| With optional end, stop comparing S at that position.
| suffix can also be a tuple of strings to try.
|
| expandtabs(self, /, tabsize=8)
| Return a copy where all tab characters are expanded using spaces.
|
| If tabsize is not given, a tab size of 8 characters is assumed.
|
| find(...)
| S.find(sub[, start[, end]]) -> int
|
| Return the lowest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Return -1 on failure.
|
| format(...)
| S.format(*args, **kwargs) -> str
|
| Return a formatted version of S, using substitutions from args and kwargs.
| The substitutions are identified by braces ('{' and '}').
|
| format_map(...)
| S.format_map(mapping) -> str
|
| Return a formatted version of S, using substitutions from mapping.
| The substitutions are identified by braces ('{' and '}').
|
| index(...)
| S.index(sub[, start[, end]]) -> int
|
| Return the lowest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Raises ValueError when the substring is not found.
|
| isalnum(self, /)
| Return True if the string is an alpha-numeric string, False otherwise.
|
| A string is alpha-numeric if all characters in the string are alpha-numeric and
| there is at least one character in the string.
|
| isalpha(self, /)
| Return True if the string is an alphabetic string, False otherwise.
|
| A string is alphabetic if all characters in the string are alphabetic and there
| is at least one character in the string.
|
| isascii(self, /)
| Return True if all characters in the string are ASCII, False otherwise.
|
| ASCII characters have code points in the range U+0000-U+007F.
| Empty string is ASCII too.
|
| isdecimal(self, /)
| Return True if the string is a decimal string, False otherwise.
|
| A string is a decimal string if all characters in the string are decimal and
| there is at least one character in the string.
|
| isdigit(self, /)
| Return True if the string is a digit string, False otherwise.
|
| A string is a digit string if all characters in the string are digits and there
| is at least one character in the string.
|
| isidentifier(self, /)
| Return True if the string is a valid Python identifier, False otherwise.
|
| Use keyword.iskeyword() to test for reserved identifiers such as "def" and
| "class".
|
| islower(self, /)
| Return True if the string is a lowercase string, False otherwise.
|
| A string is lowercase if all cased characters in the string are lowercase and
| there is at least one cased character in the string.
|
| isnumeric(self, /)
| Return True if the string is a numeric string, False otherwise.
|
| A string is numeric if all characters in the string are numeric and there is at
| least one character in the string.
|
| isprintable(self, /)
| Return True if the string is printable, False otherwise.
|
| A string is printable if all of its characters are considered printable in
| repr() or if it is empty.
|
| isspace(self, /)
| Return True if the string is a whitespace string, False otherwise.
|
| A string is whitespace if all characters in the string are whitespace and there
| is at least one character in the string.
|
| istitle(self, /)
| Return True if the string is a title-cased string, False otherwise.
|
| In a title-cased string, upper- and title-case characters may only
| follow uncased characters and lowercase characters only cased ones.
|
| isupper(self, /)
| Return True if the string is an uppercase string, False otherwise.
|
| A string is uppercase if all cased characters in the string are uppercase and
| there is at least one cased character in the string.
|
| join(self, iterable, /)
| Concatenate any number of strings.
|
| The string whose method is called is inserted in between each given string.
| The result is returned as a new string.
|
| Example: '.'.join(['ab', 'pq', 'rs']) -> 'ab.pq.rs'
|
| ljust(self, width, fillchar=' ', /)
| Return a left-justified string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| lower(self, /)
| Return a copy of the string converted to lowercase.
|
| lstrip(self, chars=None, /)
| Return a copy of the string with leading whitespace removed.
|
| If chars is given and not None, remove characters in chars instead.
|
| partition(self, sep, /)
| Partition the string into three parts using the given separator.
|
| This will search for the separator in the string. If the separator is found,
| returns a 3-tuple containing the part before the separator, the separator
| itself, and the part after it.
|
| If the separator is not found, returns a 3-tuple containing the original string
| and two empty strings.
|
| replace(self, old, new, count=-1, /)
| Return a copy with all occurrences of substring old replaced by new.
|
| count
| Maximum number of occurrences to replace.
| -1 (the default value) means replace all occurrences.
|
| If the optional argument count is given, only the first count occurrences are
| replaced.
|
| rfind(...)
| S.rfind(sub[, start[, end]]) -> int
|
| Return the highest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Return -1 on failure.
|
| rindex(...)
| S.rindex(sub[, start[, end]]) -> int
|
| Return the highest index in S where substring sub is found,
| such that sub is contained within S[start:end]. Optional
| arguments start and end are interpreted as in slice notation.
|
| Raises ValueError when the substring is not found.
|
| rjust(self, width, fillchar=' ', /)
| Return a right-justified string of length width.
|
| Padding is done using the specified fill character (default is a space).
|
| rpartition(self, sep, /)
| Partition the string into three parts using the given separator.
|
| This will search for the separator in the string, starting at the end. If
| the separator is found, returns a 3-tuple containing the part before the
| separator, the separator itself, and the part after it.
|
| If the separator is not found, returns a 3-tuple containing two empty strings
| and the original string.
|
| rsplit(self, /, sep=None, maxsplit=-1)
| Return a list of the words in the string, using sep as the delimiter string.
|
| sep
| The delimiter according which to split the string.
| None (the default value) means split according to any whitespace,
| and discard empty strings from the result.
| maxsplit
| Maximum number of splits to do.
| -1 (the default value) means no limit.
|
| Splits are done starting at the end of the string and working to the front.
|
| rstrip(self, chars=None, /)
| Return a copy of the string with trailing whitespace removed.
|
| If chars is given and not None, remove characters in chars instead.
|
| split(self, /, sep=None, maxsplit=-1)
| Return a list of the words in the string, using sep as the delimiter string.
|
| sep
| The delimiter according which to split the string.
| None (the default value) means split according to any whitespace,
| and discard empty strings from the result.
| maxsplit
| Maximum number of splits to do.
| -1 (the default value) means no limit.
|
| splitlines(self, /, keepends=False)
| Return a list of the lines in the string, breaking at line boundaries.
|
| Line breaks are not included in the resulting list unless keepends is given and
| true.
|
| startswith(...)
| S.startswith(prefix[, start[, end]]) -> bool
|
| Return True if S starts with the specified prefix, False otherwise.
| With optional start, test S beginning at that position.
| With optional end, stop comparing S at that position.
| prefix can also be a tuple of strings to try.
|
| strip(self, chars=None, /)
| Return a copy of the string with leading and trailing whitespace remove.
|
| If chars is given and not None, remove characters in chars instead.
|
| swapcase(self, /)
| Convert uppercase characters to lowercase and lowercase characters to uppercase.
|
| title(self, /)
| Return a version of the string where each word is titlecased.
|
| More specifically, words start with uppercased characters and all remaining
| cased characters have lower case.
|
| translate(self, table, /)
| Replace each character in the string using the given translation table.
|
| table
| Translation table, which must be a mapping of Unicode ordinals to
| Unicode ordinals, strings, or None.
|
| The table must implement lookup/indexing via __getitem__, for instance a
| dictionary or list. If this operation raises LookupError, the character is
| left untouched. Characters mapped to None are deleted.
|
| upper(self, /)
| Return a copy of the string converted to uppercase.
|
| zfill(self, width, /)
| Pad a numeric string with zeros on the left, to fill a field of the given width.
|
| The string is never truncated.
|
| ----------------------------------------------------------------------
| Static methods defined here:
|
| __new__(*args, **kwargs) from builtins.type
| Create and return a new object. See help(type) for accurate signature.
|
| maketrans(x, y=None, z=None, /)
| Return a translation table usable for str.translate().
|
| If there is only one argument, it must be a dictionary mapping Unicode
| ordinals (integers) or characters to Unicode ordinals, strings or None.
| Character keys will be then converted to ordinals.
| If there are two arguments, they must be strings of equal length, and
| in the resulting dictionary, each character in x will be mapped to the
| character at the same position in y. If there is a third argument, it
| must be a string, whose characters will be mapped to None in the result.
In [17]:
# some examples
name = "John"
print(name, 'islower', name.islower())
print(name, 'isalpha', name.isalpha())
print(name, 'upper', name.upper())
print(name.zfill(10))
print(name.swapcase())
print(name.startswith('j'))
print(' hello world'.split())
print('hello$world'.split('$'))
John islower False John isalpha True John upper JOHN 000000John jOHN False ['hello', 'world'] ['hello', 'world']
standard input¶
- read data from standard or common input such as keyboards
- allows your program to receive data during program execution facilitating user interactions
In [18]:
name = input('What is your name? ')
What is your name? John
In [19]:
num = input('Enter a number =>')
print('You entered: ', num)
Enter a number =>100 You entered: 100
composition¶
- break a problem into many smallers sub-problems or steps using high-level algorithms
- incrementally build the solution using the sub-problems or steps
exercise¶
write a program that finds area and perimeter of rectangle
In [20]:
# Demonstrate composition step by step
# Algorithm steps
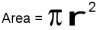
In [21]:
# Demonstrate composition step by step
# Algorithm steps