![]()
Top Python Libraries Used In Data Science¶
Let us understand what are the most important and useful python libraries that can be used in data science.¶

Data Science as you all know it is the process involved in studying the data. Yes, all you got to do is study the data and get new insights from the data. Here there is no need to focus on applying from scratch or learning new algorithms, all you need to know is learn how to approach the data and solve the problem. One of the key things that you need to know is using appropriate libraries to solve a data science problem. This article is all about providing the context to the important libraries used in Data Science. Before dwelling into the topic I would like to introduce the 5 primitive steps involved in solving a data science problem. Now I have sat down and designed these steps from scratch, so there is no right or wrong answer, the correct answer depends on how you approach the data.
The five important steps involved in Data Science is as shown below:¶
- Getting the data.
- Cleaning the data
- Exploring the data
- Building the data
- Presenting the data
Now, these steps are designed based on my experience, don't fall into the assumption that this is the universal answer, but when you sit down and think about the problem, then these steps will make a lot more sense.
1. Getting the data¶
This is one of the most important steps for solving a data science problem because you have to think of a problem and then eventually think of solving it. One of the best ways to get the data is scraping the data from the internet or download the data set from Kaggle. Now it depends on you how and where to get the data from. I found that Kaggle is one of the best ways to get the data from. Below is the link which leads you to the official website of Kaggle, I need you guys to spend some time in using Kaggle.
Alternatively, you can scrape the data from the websites, to scrape the data you need specific ways and tools to do so. Below is my article where I have shown how to scrape the data from the websites.
Some of the most important libraries that are used to get or scrape the data from the internet are as shown below:¶
- Beautiful Soup
- Requests
- Pandas
Beautiful Soup: It is a python library that is used to extract or get the data from HTML or the XML files. Below is the official documentation of the Beautiful Soup library, I recommend you to go through the link.
To manually install Beautiful Soup just type the command below, here I have given you how to manually install all the libraries too, and make sure first you have python installed, but I recommend you guys to use Google Colab to type and practice your code, because in google colab you don't need to install any libraries, you just have to just tell "import library_name" and the Colab will automatically import the library for you.
pip install beautifulsoup4
To use Beautiful Soup, you need to import it as shown below:
from bs4 import BeautifulSoup
Soup = BeautifulSoup(page_name.text, 'html.parser')
Requests: The Requests library in python is used to send HTTP requests in an easy and more friendly way. There are so many methods in request library one of the most commonly used methods is the request.get() which returns the status of the URL passed whether it is a success or failure. Below is the documentation of the requests library, I recommend you to go through the documentation for more details.
To manually install request type the following command:
pip install requests
To import the requests library you need to use:
import requests
paga_name = requests.get('url_name')
Pandas: Pandas is a high performance, easy-to-use and convenient data structure and an analysis tool for python programming language. Pandas provide us a data frame to store the data in a clear and concise way. Below is the official documentation of the panda's library.
To manually install pandas just type the code:
pip install pandas
To import pandas library all you have to do is:
import pandas as pd
2. Cleaning the data¶
Cleaning the data involves removing the duplicate rows, removing the outliers, finding the missing or null values, converting the object values into null values, and plotting them using graphs, these are some steps that are necessarily performed during cleaning the data. To read more about the cleaning process go through my article is shown below:
Some main libraries that are involved in the data cleaning process are as shown below:¶
- Pandas
- NumPy
Pandas: Yes we use pandas library everywhere in data science, Again I don't have to give insight about the panda's library, you can refer to the context in the above section.
NumPy: NumPy is a python library also known as Numeric python which can perform scientific computing. You all must know that python never provides an array data structure, only with the help of a numpy library you can create and perform manipulations on an array. To read the official documentation of numpy library please go through the website down below:
Also to download the numpy just run the following command on your command line (make sure you have python installed first):
python -m pip install --user numpy scipy matplotlib ipython jupyter pandas sympy nose
To import numpy in python all you have to do is just:
import numpy as np
3. Exploring the data¶
Exploratory Data Analysis or (EDA) is understanding the informational indexes by abridging their fundamental attributes regularly plotting them outwardly. In other words, you are exploring the data in a deeper and concise (clear) way. Through the procedure of EDA, we can request to characterize the issue proclamation or definition of our informational collection which is significant. To read more about the EDA process go through please my article showed down below:
Some main libraries that are used while performing EDA are as shown below:¶
- Pandas
- Seaborn
- Matplotlib.pyplot
Pandas: Like I said pandas library is very important we use this library throughout Data Science, for more details of the pandas library go through the first section above.
Seaborn: Seaborn is a python data visualization library, which provides a high-level interface for drawing graphs with the statistical information. In order to install the latest version of seaborn use:
pip install seaborn
I recommend you to go through the official documentation of seaborn which is as shown below:
With the help of seaborn various plots such as bar plot, scatterplot, heat maps and many more can be plotted. To import the seaborn all you have to do is:
import seaborn as sns
Matplotlib.pyplot: Matplotlib is a 2D plotting python library, with which we can plot various plots in python across various environments. It is an alternate to seaborn, and seaborn is based on matplotlib. To install matplotlib all you have to do is:
python -m pip install -U matplotlib
To read the official documentation of matplot go through the link down below:
To import the matplotlib.pyplot library use the following code:
import matplotlib.pyplot as plt
4. Building the model¶
This is one of the most important steps in data science and this is step is significantly harder than the rest of the steps because in this step you will build a machine learning model based on your problem statement and your data. Now the problem statement is very important because it is where which leads you to define a problem and think about different solutions. Many of the dataset available on the internet is based on a problem so here your problem-solving skills are very important. Also, there is no one algorithm that fits the best for your solution, you gotta think whether your data falls under regression, classification, clustering or dimension reduction all there are different categories of algorithms. To know more about building a model please go through my article down below:
Most of the time it's a really confusing task to choose the best algorithm, so what I used the SciKit learn algorithms cheat sheet with the help of this you can trace down to see which algorithm fits the best. Below is the cheat sheet from Scikit learn.
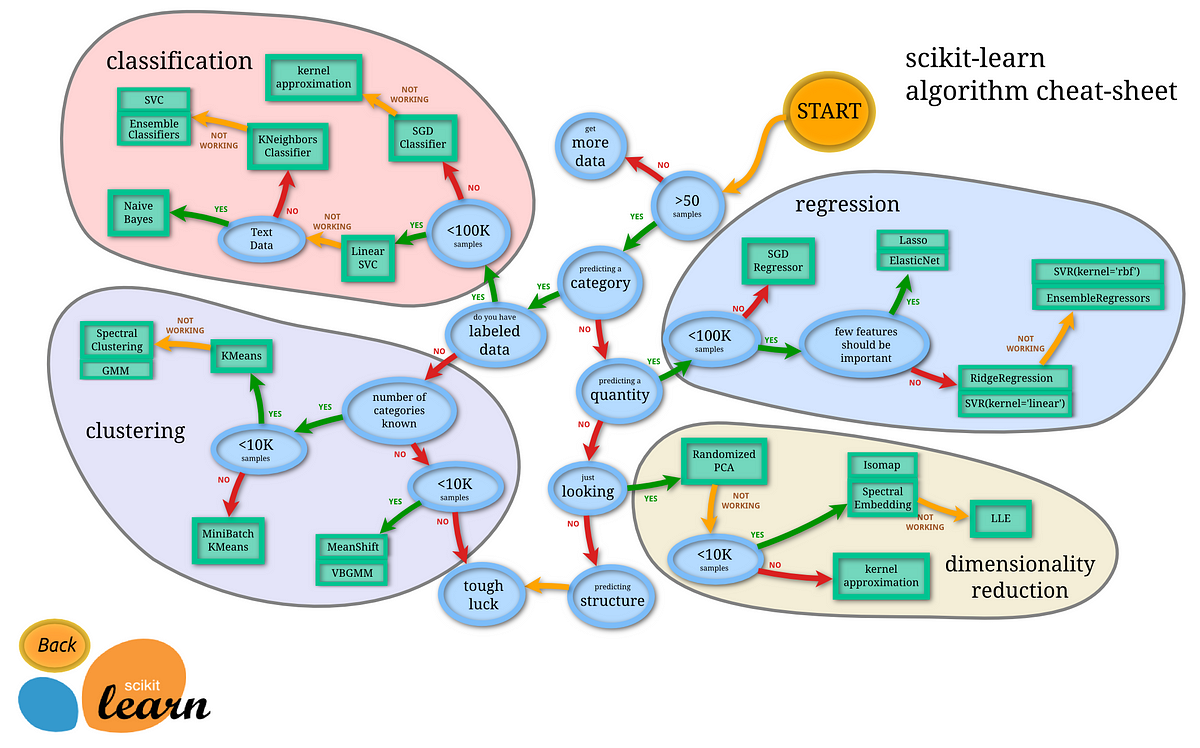
The important library that is used in building a model is obvious:¶
- SciKit learn
SciKit learn: It is an easy-to-use Python library that is used to build a machine learning model. It is built on NumPy, SciPy, and matplotlib. Below is the official documentation of scikit learn library.
In order to import scikit learn all you have to do is:
import sklearn
To manually install it use the following command:
pip install -U scikit-learn
5. Presenting the data¶
This is one of the last tasks that most of them don't want to do. This is because no one wants to publicly speak about their finding on their data. There is a way of presenting the data. This is vital because at the end of the day you should have the skill to explain your findings to people, make this really small because people are not interested in your algorithms, they are only interested in what is the outcome. So in order to do a presentation of your findings, you need to install Jupyter notebook as shown below:
And also install one more command which helps your notebook to enable a presentation option:
pip install RISE
More instructions on making your notebook into a completely amazing presentation can be found in the article down here. Make sure that you follow each and every line of the tutorial. Also, you can watch a YouTube video for how to do presentations on Jupyter notebooks:
So now we have reached the end of the article, you now know how, when and where to use python libraries in data science. That's pretty much it for this article, I have tried my level best to explain all the things from scratch. If you guys have any doubts then feel free to comment it down below. For more information about data science coding, tutorial please visit my GitHub repository. Thank you guys for reading my article, I hope you enjoyed it, if not let me know what needs to be improved, I'll correct it. Anyways see you, have a good day.