Du traitement des données en table aux bases de données - CORRECTION¶
Sommaire
- Généralités
- 1.1 Historique
- 1.2 Organisation d'une table
- 1.3 Objectifs
- Construction d'une table et traitement de ses données
- 2.1 Construction
- 2.2 Traitement des données
 |
Cette activité est un préalable aux travaux pratiques sur les bases de données relationnelles. Le vocabulaire utilisé (attribut, enregistrement, requête, etc.) est celui employé lors de leur interrogation. A la fin de chaque exercice, la référence faite aux bases de données est identifiée par l'icône ci-contre. |
1. Généralités¶
1.1 Historique¶
L'organisation tabulaire des données est très répandue. Les tables documentées les plus anciennes sont des livres de comptes déjà présents dans l'Égypte des pharaons. Aujourd'hui, cette organisation est utilisée par les bulletins scolaires, les résultats de match ou les relevés d'un compte bancaire qui indiquent pour chaque opération, sa date, son montant et sa nature (débit ou crédit). En informatique, la manipulation de données en tables depuis un langage de programmation est utilisée dans de nombreux domaines : calcul scientifique, intelligence artificielle, programmation Web, bio-informatique, informatique financière, etc. |
 |
1.2 Organisation d'une table¶
Dans ce notebook, les tables représentent des collections d'éléments. Une ligne est un élément enregistré dans la collection ou enregistrement. Les colonnes sont les attributs d'un élément (également notées champs ou descripteurs). La première ligne est le schéma de la table.
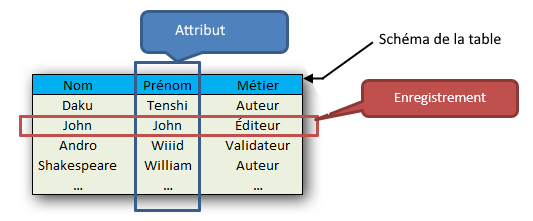
1.3 Objectifs¶
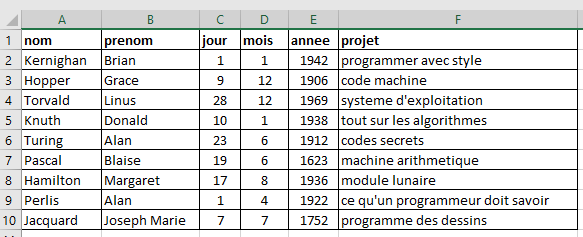
On veut construire la table de données ci-dessous à partir d'un fichier CSV et coder des requêtes en Python répondant à des interrogations telles que :
- Le prénom "Brian" est-il dans la table ?
- Quels scientifiques ont pour prénom Alan ?
- Quels sont le nom et le prénom des scientifiques nés entre 1900 et 1920,
etc.
2. Construction d'une table et traitement de ses données¶
2.1 Construction¶
La première opération concernant les données en table est le chargement des données. Celles-ci sont souvent chargées à partir d'un fichier au format CSV (Comma-Separated Values) relativement simple :
- les fichiers CSV sont des fichiers texte,
- chaque ligne du fichier correspond à une ligne de la table,
- chaque ligne est séparée en champs au moyen d'une virgule, d'un point-virgule ou d'une barre verticale,
- toutes les lignes du fichier ont le même nombre d'attributs,
- la première ligne peut représenter des noms d'attributs ou commencer directement avec les données,
- on peut utiliser des guillemets pour délimiter le contenu des attributs.
La bibliothèque standard Python propose un module csv contenant des fonctions pour lire et écrire des fichiers CSV.
# --------------------------- A FAIRE UNIQUEMENT dans GOOGLE COLABORATORY ------------------------------------------------
# Faites une copie de ce notebook dans votre drive et renommez-le : table_classe_nom_prénom.ipynb
# Pour télécharger le fichier "scientifiques.csv" sur le bureau de votre PC, utilisez le lien :
# https://webge.fr/doc/tnsi/tp/BDD/scientifiques.csv
# puis décommentez et exécutez les deux lignes ci-dessous pour importer "scientifiques.csv" dans le répertoire
# colab Notebooks de votre compte Google
# ------------------------------------------------------------------------------------------------------------------------
# from google.colab import files
# data_to_load = files.upload()
Le code suivant charge le contenu du fichier scientifiques.csv dans une variable nommée scientifiques. Exécutez-le.
import csv
with open('scientifiques.csv',encoding='utf-8') as fichier:
scientifiques = list(csv.DictReader(fichier, delimiter=";"))
print(scientifiques)
 |
La fonction DictReader renvoie des dictionnaires ordonnés que nous utiliserons comme des dictionnaires. La variable scientifiques contient donc un tableau de dictionnaires. On constate que le schéma de la table n'est pas stocké dans le tableau, mais a été utilisé pour créer les clés des dictionnaires. |
 |
DictReader charge les données dans la table sous la forme de chaînes de caractères. Si on veut les utiliser en tant que nombres, comme les attributs jour, mois et année, pour les comparer ou faire des opérations, il faut les convertir ( on dit aussi transtyper ).
|
def valide(enregistrement): # Validation des données : transtypage
nom = enregistrement['nom']
prenom = enregistrement["prenom"]
jour = int(enregistrement["jour"])
mois = int(enregistrement["mois"])
annee = int(enregistrement["annee"])
projet = enregistrement["projet"]
return{"nom": nom, "prenom": prenom, "jour": jour, "mois": mois, "annee": annee, "projet": projet}
scientifiques = [valide(enregistrement) for enregistrement in scientifiques]
print(scientifiques)
|
Vous noterez que les nombres situés dans la table scientifiques ne sont plus entourés par des guillemets ! |
2.2 Traitement des données¶
Une fois les données chargées dans une table, il devient possible de les traiter à l'aide des fonctions de manipulation de tableaux. On peut ainsi réaliser des opérations telles que :
- extraire des données de la table,
- tester la présence de certaines d'entre-elles,
- faire des statistiques.
|
Lorsque nous utiliserons une base de données et le langage SQL, ce type d'opération sera appelé REQUÊTE. |
Exercice 1. Un prénom est-il présent dans la table ?¶
On cherche à répondre à une question du type : "Y a t'il au moins une personne ayant pour prénom Brian dans la table ?"
Complétez la fonction *present(prenom, table)* dans le cadre ci-dessous pour qu'elle renvoie Vrai si le prénom passé en paramètre est présent dans la table et Faux sinon.
Exemples d'affichage attendus (=> indique le résultat renvoyé)
- Entrer un prénom : Brian
=> Il y a au moins un(e) Brian dans la table.- Entrer un prénom : Audrey
=> Aucun(e) Audrey n'est dans la table.
|
Python est un langage à typage dynamique, c'est-à-dire qu'il n'est pas nécessaire de préciser le type des données. Depuis la version 3.5, il est possible de fournir des indicateurs de type (str,bool, etc.) lors de la définition des fonctions. Cette possibilité est utilisée dans ce notebook pour faciliter la compréhension du code. |
# CORRECTION
def present(prenom: str, table: list) -> bool: # prenom est de type chaîne de caractères, table est de type liste,
# la fonction renvoie un booléen
for enregistrement in table: # Sélection des enregistrements dans la table
if enregistrement["prenom"].lower() == prenom.lower():
return True # si le prénom est celui passé en paramètre alors on renvoie Vrai
return False # sinon on renvoie Faux
# Affichage à compléter
prenom = input("Entrer un prénom : ")
if (present(prenom, scientifiques)):
print(f"Il y a au moins un(e) {prenom} dans la table.")
else:
print(f"Aucun(e) {prenom} n'est dans la table.")
|
La fonction present(prenom, table) peut être améliorée en renvoyant le nombre de fois qu'un même prénom est présent dans la table. Faites cette amélioration en complétant le code de la fonction presents(prenom, table) ci-dessous. |
# CORRECTION
def presents(prenom: str, table: list) -> int: # renvoie le nombre nb d'occurence du prénom dans la table
nb = 0
for enregistrement in table:
if (enregistrement["prenom"]).lower() == prenom.lower():
nb += 1
return nb
# Affichage à compléter
prenom = input("Entrer un prénom : ")
print(f"Il y a {presents(prenom,scientifiques)} {prenom} dans la table")
|
Dans le langage SQL la requête SELECT COUNT(attribut) FROM table WHERE attribut=valeur, appliquée à la table scientifiques (contenue dans une base de données), donnerait le même résultat. Exemple SELECT COUNT(prenom) FROM scientifiques WHERE prenom="Brian" renvoie 1. |
 |
Exercice 2. Sélection du(es) nom(s) correspondant à un prénom
On cherche à répondre à une question du type : "Quel est le nom du(es) scientifique(s) ayant pour prénom Brian ?"
Créez la fonction *nom(prenom, table)* qui renvoie la liste des noms des scientifiques ayant pour prénom celui passé en paramètre.
Exemples d'affichages attendus
- Entrer un prénom : Brian => ['Kernighan']
- Entrer un prénom : Alan => ['Turing', 'Perlis']
- Entrer un prénom : Audrey => []
# CORRECTION
def noms(prenom: str, table: list) -> list:
t = [] # tableau recevant le(s) nom(s) correspondant au prénom
for enregistrement in table:
if enregistrement["prenom"] == prenom:
t.append(enregistrement["nom"])
# [t.append(enregistrement["nom"]) for enregistrement in table if enregistrement["prenom"] == prenom]
return t
# Affichage à compléter
prenom = input("Entrer un prénom : ")
noms(prenom,scientifiques)
|
Dans le langage SQL la requête SELECT attribut1, attribut2, ..., attributn FROM table WHERE attribut=valeur, appliquée à la table scientifiques, donnerait le même résultat. Exemple SELECT nom FROM scientifiques WHERE prenom="Alan" renvoie Turing, Perlis. |
 |
|
La fonction nom(prenom, table) sélectionne l'attribut nom des personnes avec le même prénom. Dans le prochain exercice, vous allez généraliser ce cas particulier à tous les attributs de la table. |
Exercice 3. Sélection d'un attribut en fonction de la valeur d'un autre
On souhaite répondre aux questions suivantes en utilisant la même fonction :
- Quel est le prénom des scientifiques nés en juin ?
- Quel est le nom des scientifiques dont le prénom est Alan ?
- Quel est le nom des scientifiques nés le premier jour du mois ? etc.
Créez la fonction *selection(attribut1,table,attribut2,valeur)* qui renvoie la liste attribut1 pour laquelle attribut2 = valeur.
Exemples d'affichages attendus
- Prénom des scientifiques nés en juin => ['Alan', 'Blaise']
- Nom des scientifiques dont le prénom est Alan => ['Turing', 'Perlis']
- Nom des scientifiques nés le premier jour du mois => ['Kernighan', 'Perlis']
# CORRECTION
def selection(attribut1: str, table: list, attribut2: str, valeur) -> list:
t = [] # tableau contenant la ou les valeurs de attribut1 pour attribut2 = valeur
for enregistrement in table:
if enregistrement[attribut2] == valeur:
t.append(enregistrement[attribut1])
# [t.append(enregistrement[attribut1]) for enregistrement in table if enregistrement[attribut2] == valeur]
return t
# Affichage à compléter
# 1. Prénom des scientifiques nés en juin
print(selection("prenom", scientifiques, "mois", 6))
# 2. Nom des scientifiques dont le prénom est Alan
print(selection("nom",scientifiques,"prenom","Alan"))
# 3. Nom des scientifiques nés le premier jour du mois
print(selection("nom", scientifiques, "jour", 1))
|
Dans le langage SQL la requête SELECT attribut1, attribut2, ..., attributn FROM table WHERE attribut=valeur, appliquée à la table scientifiques, donnerait le même résultat. Exemple avec résultat partiel SELECT nom FROM scientifiques WHERE mois=6 renvoie Alan, Blaise, Tim. |
 |
|
La fonction selection(attribut1,table,attribut2,valeur) renvoie les données de la colonne attribut1 pour lesquelles attribut2=valeur. Il pourrait être intéressant de renvoyer des données situées dans plusieurs colonnes. C'est le travail demandé dans le prochain exercice. |
Exercice 4. Sélection de plusieurs attributs en fonction de la valeur d'un autre¶
On cherche à répondre à une question du type : "Quels sont le nom et le prénom des scientifiques nés le premier jour du mois ?"
Créez la fonction *selection2(lstattrib,table,attribut,valeur)* qui renvoie les valeurs des attributs situés dans la liste lstattrib si attribut = valeur.
Exemples d'affichages attendus
- Nom et prénom des scientifiques nés le premier jour du mois => [['Kernighan', 'Brian'], ['Perlis', 'Alan']]
- Nom, prénom et projet des scientifiques nés en juin => [['Turing', 'Alan', 'codes secrets'], ['Pascal', 'Blaise', 'machine arithmétique']]
# A compléter
def selection2(lstattrib: list, table: list, attribut: str, valeur) -> list:
t = []
tt = []
for enregistrement in table:
if enregistrement[attribut] == valeur:
for atbut in lstattrib:
t.append(enregistrement[atbut])
tt.append(t.copy())
t.clear()
return tt
# Affichage à compléter
# 1. Nom des scientifiques dont le prénom est Alan
print(selection("nom",scientifiques,"prenom","Alan"))
# 2. Nom et prénom des scientifiques nés le premier jour du mois
t_attributs=["nom","prenom"]
print(selection2(t_attributs,scientifiques,"jour", 1))
# 3. Nom, prénom et projet des scientifiques nés en juin
t_attributs=["nom","prenom","projet"]
print(selection2(t_attributs,scientifiques,"mois", 6))
|
Dans le langage SQL la requête SELECT attribut1, attribut2, ..., attributn FROM table WHERE attribut=valeur, appliquée à la table scientifiques, nous permettrait d'obtenir le même résultat. Exemple SELECT nom, prenom FROM scientifiques WHERE jour=1 renvoie ['Kernighan', 'Brian'], ['Perlis', 'Alan']. |
 |
Exercice 5. Sélection d'attributs et comparaisons¶
On cherche à répondre à une question du type : "Quels sont le nom et le prénom des scientifiques nés avant 1900 ?"
Les comparaisons à prendre en compte sont : >, <, ==, >=, <= et seront notées respectivement 1, 2, 3, 4, et 5.
Créez la fonction *selection3(lstattrib,table,attribut,comparaison,valeur)* dans le cadre ci-dessous.
Exemples d'affichages attendus
- Nom et prénom des scientifiques nés avant 1900 => [['Pascal', 'Blaise'], ['Jacquard', 'Joseph Marie']]
- Nom et prénom des scientifiques nés après 1920 => [['Kernighan', 'Brian'], ['Torvald', 'Linus'], ['Knuth', 'Donald'], ['Hamilton', 'Margaret'], ['Perlis', 'Alan']]
- Nom, prénom et projet des scientifiques nés en juin => [['Turing', 'Alan', 'codes secrets'], ['Pascal', 'Blaise', 'machine arithmétique']]
# CORRECTION Version 1 partielle
def selection3(lstattrib: list, table: list, attribut: int, opcomparaison: int, valeur: int) -> list:
t = []
tt = []
for enregistrement in table:
if opcomparaison == 1: # supérieur
if enregistrement[attribut] > valeur:
for atbut in lstattrib:
t.append(enregistrement[atbut])
tt.append(t.copy())
t.clear()
elif opcomparaison == 2: # inférieur
if enregistrement[attribut] < valeur:
for atbut in lstattrib:
t.append(enregistrement[atbut])
tt.append(t.copy())
t.clear()
elif opcomparaison == 3: # égale
if enregistrement[attribut] == valeur:
for atbut in lstattrib:
t.append(enregistrement[atbut])
tt.append(t.copy())
t.clear()
# etc.
return tt
# Affichage
operation = {"sup": 1, "inf": 2, "egal": 3, "supegal": 4, "infegal": 5}
t_attributs = ["nom", "prenom"]
# 1. Nom et prénom des scientifiques nés avant 1900
print(selection3(t_attributs, scientifiques, "annee", operation["inf"], 1900))
# 2. Nom et prénom des scientifiques nés après 1920
print(selection3(t_attributs, scientifiques, "annee", operation["sup"], 1920))
# 3. Nom, prénom et projet des scientifiques nés en juin
t_attributs=["nom","prenom","projet"]
print(selection3(t_attributs,scientifiques,"mois", operation["egal"], 6))
|
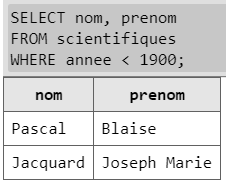
Dans le langage SQL la requête SELECT attribut1, attribut2, ..., attributn FROM table WHERE attribut opcomp valeur, appliquée à la table scientifiques, donnerait le même résultat. Exemple avec affichage partiel SELECT nom, prenom FROM scientifiques WHERE annee < 1900 renvoie ['Pascal', 'Blaise'], ['Jacquard', 'Joseph Marie'], ['Lovelace', 'Ada'], ['Babbage', 'Charles'], ['Boole', 'George']. |
 |
# Correction Version 2 !!!!
tt = [] # liste de listes contenant le résultat de la requête
def addenreg(enregistrement: dict, attribut: int, lstattrib: list) -> list:
t = [] # Une sélection prise dans un enregistrement satisfaisant la comparaison
# faite dans selection3
for atbut in lstattrib:
t.append(enregistrement[atbut])
tt.append(t.copy())
t.clear()
def selection3V2(lstattrib: list, table: list, attribut: int, opcomparaison: int, valeur: int) -> list:
tt.clear()
for enregistrement in table:
if opcomparaison == 1: # supérieur
if enregistrement[attribut] > valeur:
addenreg(enregistrement, attribut, lstattrib)
elif opcomparaison == 2: # inférieur
if enregistrement[attribut] < valeur:
addenreg(enregistrement, attribut, lstattrib)
elif opcomparaison == 3: # égal
if enregistrement[attribut] == valeur:
addenreg(enregistrement, attribut, lstattrib)
elif opcomparaison == 4: # supérieur ou égal
if enregistrement[attribut] >= valeur:
addenreg(enregistrement, attribut, lstattrib)
elif opcomparaison == 5: # inférieur ou égal
if enregistrement[attribut] <= valeur:
addenreg(enregistrement, attribut, lstattrib)
return tt
# Affichage
operation = {"sup": 1, "inf": 2, "egal": 3, "supegal": 4, "infegal": 5}
t_attributs = ["nom", "prenom"]
# 1. Nom et prénom des scientifiques nés avant 1900
print(selection3V2(t_attributs, scientifiques, "annee", operation["inf"], 1900))
# 2. Nom et prénom des scientifiques nés après 1920
print(selection3V2(t_attributs, scientifiques, "annee", operation["sup"], 1920))
# 3. Nom, prénom et projet des scientifiques nés en juin
t_attributs=["nom","prenom","projet"]
print(selection3V2(t_attributs,scientifiques,"mois", operation["egal"], 6))
Activité 6. Sélection d'attributs et encadrements¶
On souhaite répondre à une question du type : "Quels sont le nom et le prénom des scientifiques nés entre 1900 et 1920 ?"
Les comparaisons à prendre en compte sont : aucune, >, <, ==, >=, <= et seront notées respectivement 0, 1, 2, 3, 4, et 5.
Créez la fonction *selection4(lstattrib,table,attribut,opcomparaisoninf,opcomparaisonsup,valeurmin,valeurmax)* dans le cadre ci-dessous.
- opcomparaisoninf : opération de comparaison avec la borne inférieure.
- opcomparaisonsup : opération de comparaison avec la borne supérieure.
Exemples d'affichage attendus
- Nom et prénom des scientifiques nés avant 1900 => [['Pascal', 'Blaise'], ['Jacquard', 'Joseph Marie']]
- Nom et prénom des scientifiques nés entre 1900 (inclus) et 1920 (inclus) => [['Hopper', 'Grace'], ['Turing', 'Alan']]
- Nom, prénom et date de naissance des scientifiques nés entre le premier (compris) et le 15 (exclus) du mois => [['Kernighan', 'Brian', 1, 1, 1942], ['Hopper', 'Grace', 9, 12, 1906], ['Knuth', 'Donald', 10, 1, 1938], ['Perlis', 'Alan', 1, 4, 1922], ['Jacquard', 'Joseph Marie', 7, 7, 1752]]
# CORRECTION
def selection4(lstattrib: list, table: list, attribut: int, opcomparaisoninf: int, opcomparaisonsup:int,
valeurmin: int, valeurmax: int) -> list:
tt.clear()
for enregistrement in table:
if opcomparaisoninf == 1 and opcomparaisonsup == 0: # supérieur & aucune
if enregistrement[attribut] > valeurmin:
addenreg(enregistrement, attribut, lstattrib)
elif opcomparaisoninf == 2 and opcomparaisonsup == 0: # inférieur & aucune
if enregistrement[attribut] < valeurmin:
addenreg(enregistrement, attribut, lstattrib)
elif opcomparaisoninf == 3 and opcomparaisonsup == 0: # égal & aucune
if enregistrement[attribut] == valeurmin:
addenreg(enregistrement, attribut, lstattrib)
elif opcomparaisoninf == 4 and opcomparaisonsup == 0: # supérieur ou égal & aucune
if enregistrement[attribut] >= valeurmin:
addenreg(enregistrement, attribut, lstattrib)
elif opcomparaisoninf == 5 and opcomparaisonsup == 0: # inférieur ou égal & aucune
if enregistrement[attribut] <= valeurmin:
addenreg(enregistrement, attribut, lstattrib)
elif opcomparaisoninf == 4 and opcomparaisonsup == 5: # supérieur ou égal & inférieur ou égal
if enregistrement[attribut] >= valeurmin and enregistrement[attribut] <= valeurmax:
addenreg(enregistrement, attribut, lstattrib)
elif opcomparaisoninf == 4 and opcomparaisonsup == 2: # supérieur ou égal & inférieur
if enregistrement[attribut] >= valeurmin and enregistrement[attribut] < valeurmax:
addenreg(enregistrement, attribut, lstattrib)
# etc.
return tt
# Affichage
operation = {"aucune": 0, "sup": 1, "inf": 2, "egal": 3, "supegal": 4, "infegal": 5}
t_attributs = ["nom", "prenom"]
# 1. Nom et prénom des scientifiques nés avant 1900
print(selection4(t_attributs, scientifiques, "annee", operation["inf"], operation["aucune"], 1900,0))
# 2. Nom et prénom des scientifiques nés après 1920
print(selection4(t_attributs, scientifiques, "annee", operation["sup"], operation["aucune"], 1920 , 0))
# 3. Nom et prénom des scientifiques nés entre 1900 et 1920
print(selection4(t_attributs, scientifiques, "annee", operation["supegal"], operation["infegal"], 1900 , 1920))
# 4. Nom, prénom et date de naissance des scientifiques nés entre le premier (compris) et le 15 (exclus) du mois
t_attributs = ["nom", "prenom","jour","mois","annee"]
print(selection4(t_attributs, scientifiques, "jour", operation["supegal"], operation["inf"], 1 , 15))
|
Dans le langage SQL la requête SELECT attribut1, attribut2, ..., attributn FROM table WHERE attribut opcomp1 valeur1 AND attribut opcomp2 valeur2 , appliquée à scientifiques2, donnerait le même résultat. Exemple avec affichage partiel SELECT nom, prenom FROM scientifiques2 WHERE annee >= 1900 AND annee <= 1920 renvoie ['Hopper', 'Grace'], ['Turing', 'Alan'], ['Shannon', 'Claude']. |
 |